
Ranter

Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
Comments
-
 ltlian21115y"Okay, then we have a great opportunity where any user can take down our database"
ltlian21115y"Okay, then we have a great opportunity where any user can take down our database"
Actual quote from the office. -
@ltlian
How does a database takedown opportunity happen - now that prepared statements killed all the injection opportunities? -
ltlian21115y@Oktokolo Just a poorly formulated query that could lead to a timeout, which lead to an internal retry, which made the next query more likely to time out, repeat. We were all aware of it but had some trouble convincing the higher ups that it needs fixing when it "works".
"It works, but it's a big problem. This is not okay", "We can't just talk about problems all day. Are there any opportunities here?", "Yes, an opporrunity for anyone to bring down the whole system".
Luckily it was all in jest and we got the point across. Pretty sure we spent more time justifying the time needed to fix it than the less-than-a-day someone spent fixing it. -
@Oktokolo One non-injection exploit example is a Regex Dos -- If a database supports regex and the backend uses a regex to either find or validate a record somewhere, it can crash the DB daemon.
Lets say for example we want to either find certain subsequences in a field containing a DNA sequence, or add a check constraint so only certain types of sequences can be added.
Take the underlying pattern, which matches an A and a G, with any combination of Cs and Gs in-between. So ACCG, ATTG, ACTTTCTG are all valid, but ATTCTA is not because it goes back to A instead of G.
It works quite well for finding all matches globally even on a somewhat large string.
But one specific short malicious string causes even the Regex101 website to call it quits.
I've used this to bring down PostGres systems which used a regex check constraint on the email field.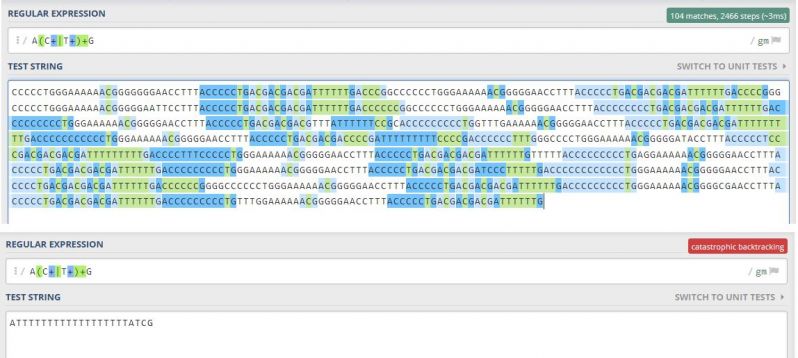
-
@bittersweet
Never let users provide regular expressions (except the user is a dev and could as well just go to the DB directly).
And of course: Use expressions describing a regular language - so no fancy assertion features also supported by todays "regex" engines. -
@bittersweet
Edit: That expression in your post looks pretty innocent. I am surprised about it killing the demon. -
@Oktokolo Yeah but the DoS exploit/bug works in reverse: The user doesn't provide the regex, they provide the string. Regex is basically a language on its own, and the above example is a string which triggers a nasty nested loop with some exponentially growing time complexity depending on the amount of "T" characters.
The bug often occurs non-maliciously when writing validation algorithms for things which aren't easily regexable, like email or URL validation. -
@bittersweet
I always had the impression, that it's enough to keep the regex strictly regular to prevent that sort of exponential time or memory complexity. -
@Oktokolo
A regex is a non-deterministic finite automaton, which has to be transformed into a deterministic finite automaton by its engine. This transformation can require NP time.
"^(xx+)$" means: Match one x, and then another 1-or-more x's. In practice, that means it matches xx, xxx, xxxx, xxxxx, etc.
Now try: "^(xx+?)\1+$". That means we're matching the above group of 2, 3, 4, 5, 6, etc x's, but now 2-or-more times.
Boom, you've got a prime number sieve. (More accurate would be ^x?$|^(xx+?)\1+$ to account for 1 as a non-prime). -
@bittersweet
I wouldn't expect "^(xx+)$" to have complexity explosion potential.
I always assumed strictly regular patterns like that to be safe.
But "^(xx+?)\1+$" is using a back reference and therefore isn't defining a regular language anymore.
Complexity explosions in non-regular languages aren't surprising. -
@Oktokolo
Back references aren't necessary for a regex to have high degrees of time complexity.
Take ^(a+)+$.
It takes 6 steps to see that ax doesn't match, 12 for aax, 24 for aaax -- In other words, 3 * 2^n, or O(2^n), with n being the amount of "a" characters before it finds the x.
This happens because for aaaax it tries
(aaaa)x
(aaa)(a)x
(aa)(aa)x
(a)(aaa)x
(a)(aa)(a)x
(a)(a)(aa)x
(aa)(a)(a)x
(a)(a)(a)(a)x
8 possible groupings, 6 steps per grouping = 48 steps total.
But yes, this weakness exists specifically to accommodate for references, even when the references are UNUSED in the regular expression.
On the other hand, the complexity in a regex without groups, like for ^a+$ is just a linear 2+n, or O(n).
Many languages actually also have the concept of atomic non-capturing groups to avoid DoS vulnerability: ^(?>a+)+$ is also a regex with linear time complexity. -
-
@bittersweet
Thanks. I will definitely be more carefull evaluating regexp patterns in the future.
Anything else to look for when keeping patterns strictly regular, avoiding ambigous groups and not using variable count of groups of variable-length content? -
@Oktokolo The main trick to avoiding evil regexes is that whenever you combine a + or * quantifier INSIDE of a group with a quantifier applied TO the group, see if you can make the group atomic (?>x).
-
@Oktokolo
It's also quite funny how often large documentation sources get this wrong, especially regarding email validation.
For example, w3resource will tell you to use this in Javascript:
^\w+([\.-]?\w+)*@\w+([\.-]?\w+)*(\.\w{2,3})+$
If I test "aaaaaaaaaaaaaaaaaaaaaa@gmail.poop" on the above, it will just hang the tab and max out a core on my CPU.
Imagine using that on some autoscaling NodeJS cluster.
If I replace it with this:
^\w+(?>[\.-]?\w+)*@\w+(?>[\.-]?\w+)*(?>\.\w{2,3})+$
It's still a very bad regex for actually matching email addresses correctly, but at least it's not vulnerable anymore. -
@bittersweet
Oh yeah - email verification.
It is like parsing HTML with regexps. Email addresses are pretty overcomplicated even when not supporting comments...
I ended with just making sure that it contains an @ and that the link from the verification email gets clicked.
Thanks for the insights into how regular expressions work in practice.
Most of the DoS opportunities looked odd to me before (like having +/* quantfiers inside a group and on the group itself or using non-regular features).
But i really didn't know, that making sure to actually parse a regular language isn't enough in practice.




Related Rants


 WHEN YOU DON’T LISTEN TO THE PROGRAMMER...
WHEN YOU DON’T LISTEN TO THE PROGRAMMER...
 The transition from developer to manager.
The transition from developer to manager.
they're not bugs, they are
"problem-solving opportunities"
rant
management