
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
A client called me today saying their custom website I built for them is down. It just shows a 403 error now. They said they just wanted to update the prices. I asked what changes they made before it crashed. She said, "I couldn't figure out how to change the prices, so I just installed Wordpress, and now it doesn't work!" They completely deleted the entire website using cPanel and replaced it with a partially installed Wordpress.🤦18
-
It's maddening how few people working with the internet don't know anything about the protocols that make it work. Web work, especially, I spend far too much time explaining how status codes, methods, content-types etc work, how they're used and basic fundamental shit about how to do the job of someone building internet applications and consumable services.
The following has played out at more than one company:
App: "Hey api, I need some data"
API: "200 (plain text response message, content-type application/json, 'internal server error')"
App: *blows the fuck up
*msg service team*
Me: "Getting a 200 with a plaintext response containing an internal server exception"
Team: "Yeah, what's the problem?"
Me: "...200 means success, the message suggests 500. Either way, it should be one of the error codes. We use the status code to determine how the application processes the request. What do the logs say?"
Team: "Log says that the user wasn't signed in. Can you not read the response message and make a decision?"
Me: "That status for that is 401. And no, that would require us to know every message you have verbatim, in this case, it doesn't even deserialize and causes an exception because it's not actually json."
Team: "Why 401?"
Me: "It's the code for unauthorized. It tells us to redirect the user to the sign in experience"
Team: "We can't authorize until the user signs in"
Me: *angermatopoeia* "Just, trust me. If a user isn't logged in, return 401, if they don't have permissions you send 403"
Team: *googles SO* "Internet says we can use 500"
Me: "That's server error, it says something blew up with an unhandled exception on your end. You've already established it was an auth issue in the logs."
Team: "But there's an error, why doesn't that work?"
Me: "It's generic. It's like me messaging you and saying, "your service is broken". It doesn't give us any insight into what went wrong or *how* we should attempt to troubleshoot the error or where it occurred. You already know what's wrong, so just tell me with the status code."
Team: "But it's ok, right, 500? It's an error?"
Me: "It puts all the troubleshooting responsibility on your consumer to investigate the error at every level. A precise error code could potentially prevent us from bothering you at all."
Team: "How so?"
Me: "Send 401, we know that it's a login issue, 403, something is wrong with the request, 404 we're hitting an endpoint that doesn't exist, 503 we know that the service can't be reached for some reason, 504 means the service exists, but timed out at the gateway or service. In the worst case we're able to triage who needs to be involved to solve the issue, make sense?"
Team: "Oh, sounds cool, so how do we do that?"
Me: "That's down to your technology, your team will need to implement it. Most frameworks handle it out of the box for many cases."
Team: "Ah, ok. We'll send a 500, that sound easiest"
Me: *..l.. -__- ..l..* "Ok, let's get into the other 5 problems with this situation..."
Moral of the story: If this is you: learn the protocol you're utilizing, provide metadata, and stop treating your customers like shit.21 -
I’m going through the book automate the boring stuff and I’m working on the chapter with web scraping right.
Well I wanted to just count all of the comic links that are in the xkcd archive as a small exercise to help me get used to and better learn web scraping.
I go through hell trying to do this but after more than a few hours later I finally have done it I returned every link of ONLY the comics, so it was time to start counting them.
I implemented the counting. The total number as of today is 2279 and it my code counted 2278, and I started to lose it.
So I go through this motherfucker manually to see where my loops count and the count on the tags start to differ. I found it, whoever made it went from 403 to 405. The euphoria I felt for this incredibly small task was incredible. (Still haven’t pieced it together yet)
I found the email of the guy who I assume owns the site and I started writing an email that basically said “hey the count of your comics is off by one and you made me rethink existence trying to figure out why, you skipped number 404-”
I look at the gap between 403 and 405 Then the words “Error 404 Not Found” popped into my head. I proceeded to scream for a second and stopped writing the email and now I’m trying to come to terms with this.
TL:DR the guy who runs xkcd comics trolled me with a simple error 404 joke4 -
Around 2 years ago, I had first discovered DevRant.
I was an intern in a startup then, and I was working on ElasticSearch. I remember making rants about it. The internship ended. So did my relationship with ElasticSearch.
This week, a new intern joined our organisation (a different organisation). He was assigned the task of deploying ElasticSearch, with me as his mentor. All was going good, we migrated data from MongoDB to ElasticSearch and all.
Back then, I used to curse the team lead (leading a team of interns mostly), for not helping me properly...
I wanted a publicly accessible dashboard, since we can't really see the Kibana dashboard with SSH :P... So, we implemented user authentication using X-Pack security. And here we are, stuck... Again... I'm unable to help the intern. The World has come to a full circle.
PS: I have to just guide him while doing my own User Stories.
https://stackoverflow.com/questions... -
In today's episode of kidding on SystemD, we have a surprise guest star appearance - Apache Foundation HTTPD server, or as we in the Debian ecosystem call it, the Apache webserver!
So, imagine a situation like this - Its friday afternoon, you have just migrated a bunch of web domains under a new, up to date, system. Everything works just fine, until... You try to generate SSL certificates from Lets Encrypt.
Such a mundane task, done more than a thousand times already... Yet... No matter what you do, nothing works. Apache just returns a HTTP status code 403 - Forbidden.
Of course, what many folk would think of first when it came to a 403 error is - Ooooh, a permission issue somewhere in the directory structure!
So you check it... And re-check it to make sure... And even switch over to the user the webserver runs under, yet... You can access the challenge just fine, what the hell!
So you go deeper... And enable the most verbose level of logging apache is capable of - Trace8. That tells you... Not a whole lot more... Apparently, the webserver was unable to find file specified? But... Its right there, you can see it!
So you go another step deeper and start tracing the process' system calls to see exactly where it calls stat/lstat on the file, and you see that it... Calls lstat and... It... Returns -1? What the hell#2!
So, you compile a custom binary that calls lstat on the first argument given and prints out everything it returns... And... It works fine!
Until now, I chose to omit one important detail that might have given away the issue to the more knowledgeable right away. Our webservers have the URL /.well-known/acme-challenge/, used for ACME challenges, aliased somewhere else on the filesystem - To /tmp/challenges.
See the issue already?
Some *bleep* over at the Debian Package Maintainer group decided that Apache could save very sensitive data into /tmp, so, it would be for the best if they changed something that worked for decades, and enabled a SystemD service unit option "PrivateTmp" for the webserver, by default.
What it does is that, anytime a process started with this option enabled writes to /tmp/*, the call gets hijacked or something, and actually makes the write to a private /tmp/something/tmp/ directory, where something... Appeared as a completely random name, with the "apache2.service" glued at the end.
That was also the only reason why I managed fix this issue - On the umpteenth time of checking the directory structure, I noticed a "systemd-private-foobarbas-apache2.service-cookie42" directory there... That contained nothing but a "tmp" directory with 777 as its permission, owned by the process' user and group.
Overriding that unit file option finally fixed the issue completely.
I have just one question - Why? Why change something that worked for decades? I understand that, in case you save something into /tmp, it may be read by 3rd parties or programs, but I am of the opinion that, if you did that, its only and only your fault if you wrote sensitive data into the temporary directory.
And as far as I am aware, by default, Apache does not actually write anything even remotely sensitive into /tmp, so...
Why. WHY!
I wasted 4 hours of my life debugging this! Only to find out its just another SystemD-enabled "feature" now!
And as much as I love kidding on SystemD, this time, I see it more as a fault of the package maintainers, because... I found no default apache2/httpd service file in the apache repo mirror... So...8 -
SO MAD. Hands are shaking after dealing with this awful API for too long. I just sent this to a contact at JP Morgan Chase.
-------------------
Hello [X],
1. I'm having absolutely no luck logging in to this account to check the Order Abstraction service settings. I was able to log in once earlier this morning, but ever since I've received this frustratingly vague "We are currently unable to complete your request" error message (attached). I even switched IP's via a VPN, and was able to get as far as entering the below Identification Code until I got the same message. Has this account been blocked? Password incorrect? What's the issue?
2. I've been researching the Order Abstraction API for hours as well, attempting to defuddle this gem of an API call response:
error=1&message=Authentication+failure....processing+stopped
NOWHERE in the documentation (last updated 14 months ago) is there any reference to this^^ error or any sort of standardized error-handling description whatsoever - unless you count the detailed error codes outlined for the Hosted Payment responses, which this Order Abstraction service completely ignores. Finally, the HTTP response status code from the Abstraction API is "200 OK", signaling that everything is fine and dandy, which is incorrect. The error message indicates there should be a 400-level status code response, such as 401 Unauthorized, 403 Forbidden or at least 400 Bad Request.
Frankly, I am extremely frustrated and tired of working with poorly documented, poorly designed and poorly maintained developer services which fail to follow basic methodology standardized decades ago. Error messages should be clear and descriptive, including HTTP status codes and a parseable response - preferably JSON or XML.
-----
This whole piece of garbage is junk. If you're big enough to own a bank, you're big enough to provide useful error messages to the developers kind enough to attempt to work with you. 2
2 -
Has any of you reached a point that you want to resign from work because of a client?
We are dealing with a client at work that uses the app for prototyping instead of making designers create wireframe, imagine the amount of code to write,edit, remove, write it again and yet there is always something isn't right from the client point of view.
What is even worse backend guys screw the server and I am the one to be blamed for errors: 5xx
I even get blamed for error 400 (bad request) when that request passes tests but out of a sudden server returns 400, when you hit refresh the exact same moment of error and server decides to return data and stop throwing error 400.
I also get blamed for server fails to return data from a search endpoint, and if server throws 403 for a public endpoint.
This isn't a rant or getting out of my system but I need opinions, I've been working on this project for a year, with complete mess from either client or backend team, if any of you is instead of me, what would you do?
I'm not a complete guy either, but that situation is just beyond my abilities to handle.6 -
just found out a vulnerability in the website of the 3rd best high school in my country.
TL;DR: they had burried in some folders a c99 shell.
i am a begginer html/sql/php guy and really was looking into learning a bit here and there about them because i really like problem solving and found out ctfs mainly focus on this part of programming. i am a c++ programmer which does school contest like programming problems and i really enjoy them.
now back on topic.
with this urge to learn more web programming i said to myself what other method to learn better than real life sites! so i did just that. i first checked my school site. right click. inspect element. it seemed the site was made with wordpress. after looking more into the html code for the site i concluded all the images and files i could see on the site were from a folder on the server named 'wp-content/uploads'. i checked the folder. and here it got interesting. i did a get request on the site. saw the details. then i checked the site. bingo! there are 3 folders named '2017', '2018', '2019'. i said to myself: 'i am god.'
i could literally see all the announcements they have made from 2017-2019. and they were organised by month!!! my curiosity to see everything got me to the final destination.
with this adrenaline i thought about another site. in my city i have the 3rd most acclaimed high school in the country. what about checking their security?
so i typed the web address. looked around. again, right click, inspect element and looked around the source code. this time i was more lucky. this site is handmade!!! i was soooo happy because with my school's site i was restricted with what they have made with wordpress and i don't have much experience with it.
amd so i began looking what request the site made for the logos and other links. it seemed all the other links on the site were with this format: www.site.com/index.php?home. and i was very confused and still am. is this referencing some part of the site in the index.php file? is the whole site written inside the index.php file and with the question mark you just get to a part of the site? i don't really get it.
so nothing interesting inside the networking tab, just some stylesheets for the site's design i guess. i switched to the debugger tab and holy moly!! yes, it had that tree structure. very familiar. just like a project inside codeblocks or something familiar with it. and then it clicked me. there was the index.php file! and there was another folder from which i've seen nothing from the network tab. i finally got a lead!! i returned in the network tab, did a request to see the spgm folder and boooom a site appeared and i saw some files and folders from 2016. there was a spgm.js file and a spgm.php file. there was a contrib, flavors, gal and lang folders. then it once again clicked me! the lang folder was las updated this year in february. so i checked the folder and there were some files named lang with the extension named after their language and these files were last updated in 2016 so i left them alone. but there was this little snitch, this little 650K file named after the name of the school's site with the extension '.php' aaaaand it was last modified this year!!!! i was so excited! i thought i found a secret and different design of the site or something completely else! i clicked it and at first i was scared there was this black/red theme going on my screen and something was a little odd. there were no school announcements or event, nononoooo. this was still a tree structured view. at the top of the site it's written '!c99Shell v. 1.0...'
this was a big nono. i saw i could acces all kinds of folders. then i switched to the normal school website and tried to access a folder i have seen named userfiles and got a 403 forbidden error. wopsie. i then switched to the c99 shell website and tried to access the userfiles folder and my boy showed all of its contents. it was nakeeed naked. like very naked. and in the userfiles folder there were all, but i mean ALL files and folders they have on the server. there were a file with the salary of each job available in the school. some announcements. there was a list with all the students which failed classes. there were folders for contests they held. it was an absolute mess and i couldn't believe it.
i stopped and looked at the monitor. what have i done? just to learn some web programming i just leaked the server of the 3rd most famous high school in my country. image a black hat which would have seriously caused more damage. currently i am writing an email to the school to updrage their security because it is reaaaaly bad.
and the journy didn't end here. i 'hacked' the site 2 days ago and just now i thought about writing an email to the school. after i found i could access the WHOLE server i searched for the real attacker so if you want to knkw how this one went let me know in the comments.
sorry for the long post, but couldn't held it anymore13 -
This is going to be fun. We are switching our phone system to use Zoom and the turn on date is sometime in October (couple of weeks away). I have a feature I'm working on (automated phone calls) that the salesman said was fully functional (jump through a hoop, stand on your head, turn around three times, type of functional). Tried the steps they gave me, got to #3 and there is no virtual agent API call I can find to hand off/transfer the call. Send our contact at Zoom some questions, responds "That is a feature we might put in a future product. Can't do that right now." WTF?!
Other developers are running into similar "How do we get there from here?" issues that features promised, either don't exist or don't work.
One feature in particular I'm receiving a 403 permission denied error.
K: "Feature X needs to be enabled."
Me: "It is."
<send a screenshot showing the feature enabled>
K: "Your account doesn't have permissions. Have the sysadmin elevate you authentication level."
Me: "I'm an admin"
<send a screenshot showing my admin status>
K: "I'll have to get back with you."
Its been 3 days and no update on my ticket. *sigh*2 -
1337 haxxor here! jk, but its fun to analyze the sourcecode of a streaming site to find the video source giving a 403 error on direct download unless i force the beforeload-adress as a referrer. quite the feeling like my first ftp-download album back in the days.
i know i am childish.1 -
A common walkthrough with Laravel deployment:
1.) Error 403
2.) Internal server error 🤔
3.) bad require paths in index.php....
4.) Whooops something went wrong.. What?.... Look at log file with 2MB size
5.) View not found1 -
While working with Django Rest Framework, the Post and Delete requests were giving me 403 error. With no help from stack overflow, I decided in vain to check it with Firefox browser instead of Chrome.
IT FUCKING WORKS ON FIREFOX!! HOW THE FUCK??
Things like this are responsible for my mid life crisis.12 -
2 days hard thinking why my prepared statement not saved to the database, until I found this
...
ADDDATA
...
And I only put the parameter with ADDATA
...
How beautiful my life. Thanks ADDDDDDDDDSDDDDSSDDSDDDDDDSDDDDDDATA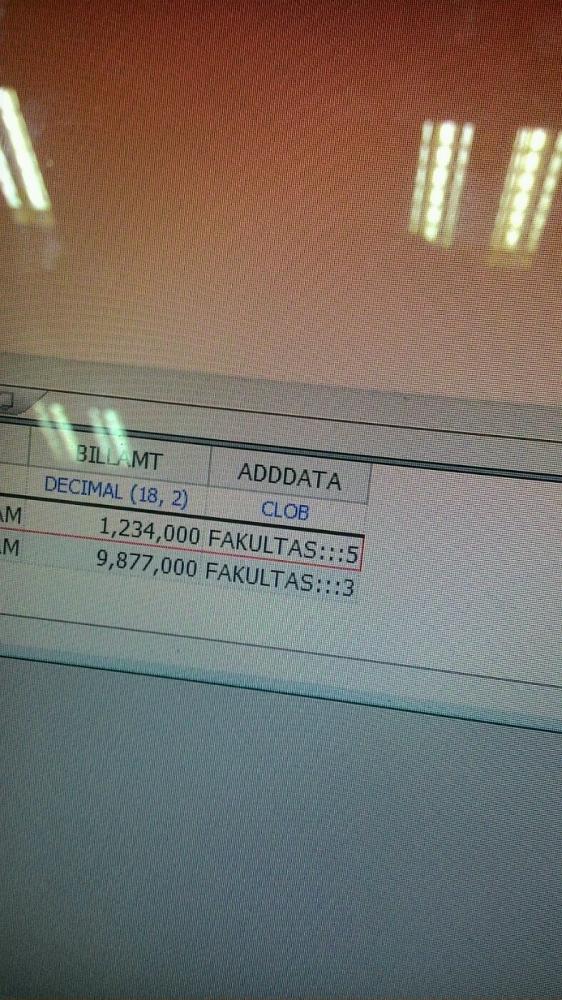 1
1















Top Tags
Weekly Rant
View