
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
I'm struggling to write a function that finds a subsequence in a sequence. I made a fucking programming language and String::find is where I get stuck. Fucking fuck.
Impostor syndrome hitting hard today27 -
I spent hours trying to support \n, \r and \r\n in my algorithms to convert between utf16 line/col and utf8 absolute indices to comply with the LSP, before realizing that
- Orchid itself doesn't support \r
- There is no established user base
so I'm in the best position to reject all files that contain \r and offer to convert them instead.10 -
Thanks, that smiley is direly needed to cope with the bizarre language that is the ABI stable subset of Rust.
 3
3 -
Today in Rust I defined a function that takes Any and returns Any specifically so that parametric types turned into trait objects of this trait can still receive commands without having to know their concrete type.
Bridging static and dynamic typing is one hell of an exercise.6 -
Oh dang, now that the individual components of Orchid are nearly complete, I should probably improve this ratio.
 22
22 -
Orchid syntax highlighting
I gotta say, I really like the text image of my new language ^_^ This is something I was worried about, although that's part of the reason why the entire syntax is defined natively and can be modified on a whim 16
16 -
VSCode is doing really strange things to my language server, in such variety that I'm starting to suspect that it's simply incorrect because it's very unlikely that I'd misunderstand so many distinct things at once.
- The trace level is verbose, yet VSCode absolutely spams the LS with trace: off requests
- the capability update request I used to set file watchers never gets a response even though the standard clearly states that all requests must get responses or progress reports quickly, and I'm not getting file updates even after vscode responds to a file system change. By the way, if file watching is a capability, why can't I set it in the protocol handshake with all the other capabilities?
- my semantic token provider (used for syntax highlighting) is simply ignored, no requests, no errors
- the debug console is spamming editor internal errors2 -
Orchid runs!
It's very far from done, but now I'm motivated to get shit done! My optimizations can now have measurable impact! The hypothetical examples no longer have to be hypothetical!!! 10
10 -
I think I'm beginning to hate my language and I'm struggling to find the motivation to work on it.
So, I started playing with SonicPi because it uses Ruby which I both hate more and can't fix, and it does something I want to eventually use Orchid for.
A therapist would probably have a field day with my self-motivation techniques.8 -
I literally spent a week fighting scope creep instinctively introduced by myself on a submodule with the nominal role *Read all files the compiler needs to read using the fewest possible additional steps*
I have to keep reminding myself that there's no such thing as a scope too narrow. If its purpose can be described without spelling out the implementation, it can be encapsulated. -
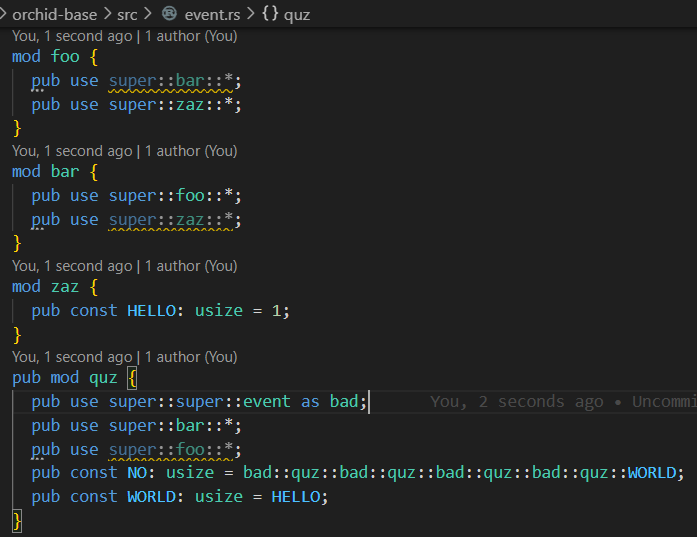
So it turns out that Rust's import resolution is Really Fucking Complicated
https://devrant.molodetz.nl/Screens...
It supports glob re-exports and circular glob imports, conflicts are valid if you don't use them or if they ultimately point at the same name, paths may pass the same module multiple times. It's very convenient to use, I never needed to fight with it, but it's borderline impossible to correctly implement.4 -
I keep forgetting what a massive pain in the ass it is to use dynamic libraries in anything other than C. I'm genuinely contemplating defining a serialization-based API and talking to plugins with a blob->blob function pair.5
-
Okay, my initial revulsion for ABI has receded. All things considered, my options aren't that bad. I just had to change my perspective from "huge downgrade from static linkage" to "huge upgrade from a message channel".
Just like a web API, I have to draw a continuous line through the program that separates specific concerns of interest that must fall on one side or another, and which can only cross through things with specific properties.
There are several crates shipping a number of different binary-compatible types, even generic types. Not everything can cross, sure, but maybe not everything should cross either. Maybe a DLL should receive an opaque handle for certain things, such as interpreter internal code representations. Maybe having these separated is important enough to justify having a translation layer.
I'm sure there's much woe ahead, but I'm learning to stop worrying and love the ABI. -
I think I understand now why people dislike continuation passing style for side effects. The continuations passed to the action can be called in any pattern, there's no inherent guarantee that an error handler cannot be called just because the corresponding success handler had already been called. In this regard they act like jump points in assembly more than functions in an equation.
I don't think this is such a massive problem. The entire imperative world is built on such things. I definitely think though that this model does not mix with autocurry. -
I just had to drill an error reporter through the entire Orchid codebase for multiple fatal error reporting. The caller constructs a reporter and passes it into the interpreter, various internal interpreter functions put errors into it and return meaningless but valid substitute values, then the caller checks the reporter for recorded errors and avoids using the return value if there were any.
I have recreated ERRNO in a high level language. -
Lessons from a really big project I will almost certainly finish:
When specifying a program, a lot of inputs become valid which have few to no real use cases, simply because they logically follow from the requirements.
When implementing a specification, some narrow use cases become unexpectedly difficult to handle.
It's important to recognize the intersection and reject it. -
So fun fact about message-passing plugin APIs, everything becomes a parallel programming problem. My lexer (the part of an interpreter that recognizes fundamental syntax elements) spawns a callback thread with request and reply channels, and then messages a plugin which is able to either talk to the callback thread or message the original thread with a successfully parsed token or an abort.
It has just occurred to me that plugins are under no obligation to sequence their requests to the callback thread, which means that having one channel for requests and one for responses no longer suffices; the requests need to each contain their response channel. -
do you ever separate the structure of a collection from the values held within to allow queries about the structure to be deferred arbitrarily without keeping the values alive through that reference, or is my project just terminally fucked?4
-
Currently the only 3rd party tokenization VSCode supports is a massive pile of RegEx. There's a whole discussion about how procedural tokenization could be supported without running extension code in the UI thread. The central argument against delegating this to an external worker is that if the reply doesn't arrive fast enough it might interfere with characters typed later.
1. Any computer that can run VSCode can execute somewhere in the order of a _billion_ instructions per second. To a program, the delay between keystrokes is an eternity. The only way to run out of time here is if either the dev isn't aware that the request is time sensitive, or the framework communicates to the OS that the task isn't urgent and an arbitrary amount of work is scheduled before it.
2. Chromium is the pinnacle of cybersecurity and its primary job is to sandbox untrusted user code. You don't need another thread to do it.
3. This use case fits squarely in the original design objectives of Webassembly.2 -
oh hey, if it isn't the same architectural mistake in the fourth fucking iteration that I keep forgetting to do right first time whenever I rewrite the code to fix unrelated problems.
canonicalize input as early as you can so that representational distinctions don't have to be drilled through business logic1 -
Adding opportunistic move to a large recursive tree processor is not a fun exercise, I would advise anyone who intends to dabble in interpreters to design with opportunistic move from the get go.2
-
Make good progress on Orchid, my pet project, the functional programming language that has no syntax apart from what the macros define. A type system, an interpreter and provisions for a compiler would be nice for a start.
Finish my bachelor's degree on some unspecified part of Orchid, at the current pace that would most likely be just the Hindley-Milner algorithm.
Don't get fired from the gem of a job I have, and move to London because I'm a city rat and the only way I can sleep well apparently is with a tram or drunken people screaming under my window.2 -
I was really teasing myself about it a week ago, but I definitely think now that building a language server before I try to get people to try Orchid is the right call.
There is a ceiling to the quality of error reporting without editor support, and because I'm not happy with the best I could've possibly gotten, I didn't really put that much effort into it. Before I got started on the language server, the interpreter would fail with the first error.
Because with LSP the new theoretical limit of DX is the lack of type information which still isn't great but it's a problem I already live with, I'm compelled to meet that limit by perfecting error detection.
It also helps that the interpreter's startup time is 2ms so I can simply run it in thread on every keystroke to generate truly live, basically instantaneous feedback.17 -
I need to finish something presentable by May so I decided to make Orchid an untyped language, and the simplicity of all tasks all of a sudden breaks my heart. Static analysis is my guiding principle, the one feature which I always held to be good. Deprioritizing it in _my own programming language_ feels like sacrilege.9
-
I'm not managing Orchid in terms of performance milestones so these posts and their order are probably incredibly bizarre.
Anyway; demo for lexer plugins, foreign code provided constant resolution, foreign function dispatch, and clean shutdown. 7
7 -
The number of concurrent transformations impacting more than half of the codebase in Orchid surpassed 4, so instead of walking the reference graph for each of these I'm updating the whole codebase, from lexer to runtime, in a single pass.
In this process, I also got to reread a lot of code from a year ago. This is the project I learned Rust with. It's incredible, not just how much better I've gotten at this language, but also how much better I've gotten at structuring code on general.
Interestingly though my problem-solving ability seems to be the same. I can tell this by looking at the utilities I made to solve specific well-defined abstract problems. I may have superficial issues with how the code is spelled out in text, but the logic itself is as good as anything I could come up with today.2 -
Yet another unusual take for the Orchid STL: Unicode codepoints aren't a part of the string library.
For the purposes of a high level language, the unit of text is a grapheme. Strings can be converted between Unicode and binary blobs. In a binary, indices address bytes. In text, indices address graphemes. For example, searching a string for a substring that consists of a single letter implies the added constraint that the letter must not have accents or other modifiers.
For storage and transfer optimization it's possible to discover the byte length of a string without converting it to binary2 -
I started a rice after 3 years of happily using KDE, and apparently everything uses CSS for styling now? I'm not complaining, Polybar offered like 4 options and we just played around with glyph fonts, compared to that this is a joyride.
Also, Eww is brilliant. I've seen people make full fucking UIs and custom notification centers and shit with it. I don't have that much time on my hands, but the option is there. All this with janky Lisp and Sass.
Eww also confirmed a suspicion of mine regarding Orchid; language adoption is a matter of convenience. I can get people to learn my language by offering cool trinkets and useful tools to people who have a predisposition to learning. Yuck is an aptly named language but it's not totally unusable, and because I had to learn it to make my status bar I'm now more inclined to write the corresponding scripts in it as well and I'm actually quite disappointed that I have to use Bash for that. -
Orchid lesson #many:
Church tuples exist only to demonstrate how general substitution is. Just like Church numerals, they aren't meant to be used for real computation and cause a lot of problems. Few type systems and fewer optimizers can deal with them, they're a pain to pass through FFI boundaries, and they're much slower in an interpreted context than a native smart array. And in a lazy language the tuple is almost always lighter than the code that generates it, so you want to generate the tuple eagerly and thunk the actual elements, if thunk you must.
I'll go write a vector based tuple and end this madness tomorrow. New version soon, probably.
With dynamic dispatch.7 -
The tokenization of Orchid files depends on the exports of imported files, but in a way that never influences their exports or imports, so Orchid allows circular references.
I sometimes feel like my subconscious and conscious mind use the scope of my projects to annoy each other.2 -
I made a very obvious realization since the last time I rewrote Orchid; the 3 year project that has now become an eloquent documentation of my learning process; Types aren't free. Sure they're free at runtime, in fact the more you have the less the language has to work to separate values, but they generate significant cognitive load.
Oftentimes it's better to have one enum with 12 variants 3 of which are specific to a narrow case to be able to define operations for this enum once, than it is to have 3 distinct enums of 10, 11 and 8 variants respectively, and to have to define common operations (or the dispatch part anyway) thrice.
As for my previous observations about catchall abort acting like the new type abort, I still think that, and I still think that this is only justifiable if the number of invalid variants is low enough in every case that you can list all of them before the abort.4 -
Can the error types of my library depend on a custom library context object to be printable or otherwise meaningful? Pretty much everything else depends on this context, but until now the errors were an exception (no pun intended) because I wanted them to be printable by any handler that bumps into them, without scoping concerns. Now I tried removing them and like a third of my library has suddenly become context-free, because it only used the context to fully resolve everything before error reporting.1
-
I'm working on an internal overhaul for Orchid phasing out the last bits of code from May's crunch and making the loading pipeline much more transparent and easier to optimize, but I'm starting to get really tired of high theory and tree walking algorithms.
What are some light hearted projects that can benefit from a scripting language? I don't mind if existing scripting languages would be an objectively better choice, I don't want to build something perfect here, I just wanna have fun with this project again. -
What's the message passing IPC with the least RTT for messages that are in the 16-32 byte range? It's gonna run approximately once per command in an interpreter.5


{kind=link}
Top Tags
Weekly Rant
View