
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
TOP 10 PROGRAMMING BEST PRACTICES
#1 Start numbering from 0.
#10 Sort elements in lexicographic order for readability.
#2 Use consistent indentation.
#3 use Consistent Casing.
#4.000000000000001 Use floating-point arithmetic only where necessary.
#5 Not avoiding double negations is not smart.
#6 Not recommended is Yoda style.
#7 See rule #7.
#8 Avoid deadlocks.
#9 ISO-8859 is passé - Use UTF-8 if you ▯ Unicode.
#A Prefer base 10 for human-readable messages.
#10 See rule #7.
#10 Don't repeat yourself.12 -
So a friend of Mine asked me to check their Mail server because some emails got lost. Or had a funny signature.
Mails were sent from outlook so ok let's do this.
I go create a dummy account, and send/receive a few emails. All were coming in except one and some had a link appended. The link was randomly generated and was always some kind of referral.
Ok this this let's check the Mail Server.
Nothing.
Let's check the mail header. Nothing.
Face -> wall
Fml I want to cry.
Now I want to search for a pattern and write a script which sends a bunch of mails on my laptop.
Fuck this : no WLAN and no LAN Ports available. Fine let's hotspot the phone and send a few fucking mails.
Guess what? Fucking cockmagic, no funny mails appear!
At that moment I went out and was like chainsmoking 5 cigarettes.
BAM!
It hit me! A feeling like a unicorn vomiting rainbows all over my face.
I go check their firewall. Shit redirected all email ports from within the network to another server.
Yay nobody got credentials because nobody new it existed. Damn boy.
Hook on to the hostmachine power down the vm, start and hack yourself a root account before shit boots. Luckily I just forgot the credentials to a testvm some time ago so I know that shit. Lesson learned: fucking learn from your mistakes, might be useful sometimes!
Ok fucker what in the world are you doing.
Do some terminal magic and see that it listens on the email ports.
Holy cockriders of the galaxy.
Turns out their former it guy made a script which caught all mails from the server and injected all kind of bullshit and then sent them to real Webserver. And the reason why some mails weren't received was said guy was too dumb to implement Unicode and some mails just broke his script.
That fucker even implented an API to pull all those bullshit refs.
I know your name "Matthias" and I know where you live and what you've done... And to fuck you back for that misery I took your accounts and since you used the same fucking password for everything I took your mail, Facebook and steam account too.
Git gut shithead! You better get a lawyer15 -
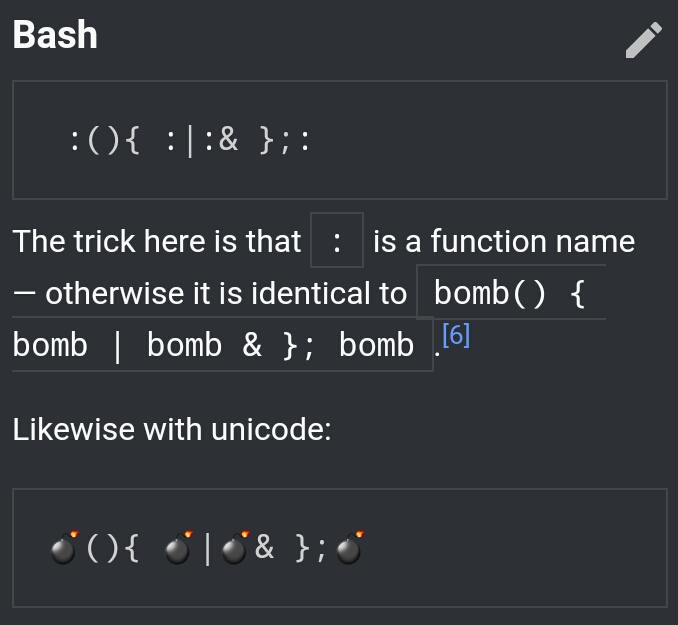
The thing about UNICODE is the ability to make it hard to parse what humans automatically see as ASCII9
-
When we found out MySQL utf8 isn't actually utf8..... it's a proprietary subset of utf8 that only includes up to Unicode 255..... and there is a separate "utf8mtb4" that is actual utf8.4
-
this.title = "gg Microsoft"
this.metadata = {
rant: true,
long: true,
super_long: true,
has_summary: true
}
// Also:
let microsoft = "dead" // please?
tl;dr: Windows' MAX_PATH is the devil, and it basically does not allow you to copy files with paths that exceed this length. No matter what. Even with official fixes and workarounds.
Long story:
So, I haven't had actual gainful employ in quite awhile. I've been earning just enough to get behind on bills and go without all but basic groceries. Because of this, our electronics have been ... in need of upgrading for quite awhile. In particular, we've needed new drives. (We've been down a server for two years now because its drive died!)
Anyway, I originally bought my external drive just for backup, but due to the above, I eventually began using it for everyday things. including Steam. over USB. Terrible, right? So, I decided to mount it as an internal drive to lower the read/write times. Finding SATA cables was difficult, the motherboard's SATA plugs are in a terrible spot, and my tiny case (and 2yo) made everything soo much worse. It was a miserable experience, but I finally got it installed.
However! It turns out the Seagate external drives use some custom drive header, or custom driver to access the drive, so Windows couldn't read the bare drive. ffs. So, I took it out again (joy) and put it back in the enclosure, and began copying the files off.
The drive I'm copying it to is smaller, so I enabled compression to allow storing a bit more of the data, and excluded a couple of directories so I could copy those elsewhere. I (barely) managed to fit everything with some pretty tight shuffling.
but. that external drive is connected via USB, remember? and for some reason, even over USB3, I was only getting ~20mb/s transfer rate, so the process took 20some hours! In the interim, I worked on some projects, watched netflix, etc., then locked my computer, and went to bed. (I also made sure to turn my monitors and keyboard light off so it wouldn't be enticing to my 2yo.) Cue dramatic music ~
Come morning, I go to check on the progress... and find that the computer is off! What the hell! I turn it on and check the logs... and found that it lost power around 9:16am. aslkjdfhaslkjashdasfjhasd. My 2yo had apparently been playing with the power strip and its enticing glowing red on/off switch. So. It didn't finish copying.
aslkjdfhaslkjashdasfjhasd x2
Anyway, finding the missing files was easy, but what about any that didn't finish? Filesizes don't match, so writing a script to check doesn't work. and using a visual utility like windirstat won't work either because of the excluded folders. Friggin' hell.
Also -- and rather the point of this rant:
It turns out that some of the files (70 in total, as I eventually found out) have paths exceeding Windows' MAX_PATH length (260 chars). So I couldn't copy those.
After some research, I learned that there's a Microsoft hotfix that patches this specific issue! for my specific version! woo! It's like. totally perfect. So, I installed that, restarted as per its wishes... tried again (via both drag and `copy`)... and Lo! It did not work.
After installing the hotfix. to fix this specific issue. on my specific os. the issue remained. gg Microsoft?
Further research.
I then learned (well, learned more about) the unicode path prefix `\\?\`, which bypasses Windows kernel's path parsing, and passes the path directly to ntfslib, thereby indirectly allowing ~32k path lengths. I tried this with the native `copy` command; no luck. I tried this with `robocopy` and cygwin's `cp`; they likewise failed. I tried it with cygwin's `rsync`, but it sees `\\?\` as denoting a remote path, and therefore fails.
However, `dir \\?\C:\` works just fine?
So, apparently, Microsoft's own workaround for long pathnames doesn't work with its own utilities. unless the paths are shorter than MAX_PATH? gg Microsoft.
At this point, I was sorely tempted to write my own copy utility that calls the internal Windows APIs that support unicode paths. but as I lack a C compiler, and haven't coded in C in like 15 years, I figured I'd try a few last desperate ideas first.
For the hell of it, I tried making an archive of the offending files with winRAR. Unsurprisingly, it failed to access the files.
... and for completeness's sake -- mostly to say I tried it -- I did the same with 7zip. I took one of the offending files and made a 7z archive of it in the destination folder -- and, much to my surprise, it worked perfectly! I could even extract the file! Hell, I could even work with paths >340 characters!
So... I'm going through all of the 70 missing files and copying them. with 7zip. because it's the only bloody thing that works. ffs
Third-party utilities work better than Microsoft's official fixes. gg.
...
On a related note, I totally feel like that person from http://xkcd.com/763 right now ;;21 -
I inserted a unicode 'reverse text' character into the registration form of our energy provider and see what we got today 😁🤣
 9
9 -
I have no idea why the server does this, but everytime I Ctrl+C a process it prints a unicode heart out.
 11
11 -
WTF is up with open-source projects using emojis in their commit messages... FUCKING emojis..
I get it, programming is fun and a hobby to many, but can we also keep at least a minimum level of professionalism here.
WTF is a wheelchair or bento emoji at the beginning of a commit message supposed to mean? Why the hell even bother to use it in the first place? There is no fucking reason for this retarded shit.
Is this what happens when activist developers get out of their way to make programming "inclusive"?
It is your personal project and so if you want to use emojis it is OK, I respect that (not really) but I can't trust your code, your commitment, or the quality of your work if I see those dumb Unicode characters there.
Git commit messages are not a game. Be playful with comments in code or your readme.md file but git messages should be a clear reflection of the changes not what a teenager's phone vomited on the keyboard.31 -
Very specific and annoying situation here:
- Working on a machine learning project with other people
- I'm on Linux, they use Windows
- We code in python
- We generally use vscode for development, and its python extension
I implement some basic neural networks with tensorflow, and add a bunch of logging for it. I test it on my machine and it works fine.
But, my group mates report that "after a few seconds the entire client hangs".
Apparently it only happens on Windows?
We start debugging the hell out of the code I implemented, added 20 log messages and sat there for a solid hour.
Until I make one very odd realization: the issue doesn't happen when I run the script in my terminal, instead of vscode with the debugger. So I try different debug settings, using an external terminal instead of vscode's built in debug console seems to fix it too.
And I make another observation: In the debug console, some messages don't seem to appear at all, while the external terminal shows them just fine.
So, turns out, that printing an epsilon character: “ε” (U+03B5), causes the entire thing to hang up.
It's the year 2020 and somehow we still can't do unicode.
I'm so done, what on earth.6 -
I-I totally did n-not spend half an hour on this...
(here's a gist for you: https://gist.github.com/moriczgergo...) 5
5 -
Unicode has some really odd characters:
↯⇝ↈ⅟ⅆ⅏ÞĦſƑɐɰ‖‴⁑⁆⁋⅌∰√≂∿≍≜≓⊎≹⌛⌧⍜⎈⎉⎗⎶␖␥⒳⓾┗╫▁▨☶⛮⟗⟁⠫⨈⩶⩸⪔⫸⨊⸎⸨⺶⿆̡̢̛̲̻̺̪̙̥̓̌ͬͧͧͮͥ͂̈̏̆̀〠〾ゅザㄆ㈌︘﹫~🄹🈁🕠🦀
Some I can understand, but some are just crazy.
And don't forget good old right-to-left override (202e)!7 -
Oh boy do I hate when news stations say that Apple is introducing new emojis in their next update. R.I.P. Unicode Consortium.6
-
Finally Spend two fucking days debugging shit until I figured it it. Freaking stupid shit encoding problems and old data combined isn't fun. Dafuq why can't everybody use UTF-8 or Unicode or something else but PLEASE stop using some old school IBM shit codepages.
Leckt mich doch am arsch mit diesem scheiß man -_-3 -
Screw MySQL/MariaDB. Who the fuck thought not to document that utf8 is only 3 bytes and not unicode capable. You have to use utf8mb4 for it to work. Fuck those idiots that don't want to admit they made a mistake and put this info in a footnote on a pricy documentation piece.5
-
Not exactly dev stuff, but LaTeX low-key makes me nervous.
In writing my thesis it seems that through some keyboard-fuckery I managed to slip in some weird unicode bullshit character somewhere, so that it doesn't compile. Alright, I just do \DeclareUnicodeCharacter{0301}{ASDF} so that it gets replaced by ASDF. Searching for ASDF in the output pdf file does not yield results, so I can't even find the location of the fuckery in the text. It seems that unicode character is somewhere in my .bib-file and I guess my citation style doesn't even render the part of the data that character is in after all. So the above hack works, but still there is some weird-ass character in my bibliography file that I can't find.
On another note: I get that modularity is cool and all, but who thought that it is a good idea to give people zero transparency over what macro stems from which included package? No namespaces etc. I end up including a whole lot of packages that are needed for exactly one macro. That bloats up the file and you have no way to trace back which macro came from which of the quazillion included packages.
...then again maybe I'm just a lazy piece of shit whose google searches end before success and all of the above has some easy fix.9 -
Ladies and gentleman, I've done it.
Remove your hacker game trophies from your wall.
That nasty bug you fixed a couple of nights ago? Meh.
Your top devRant post? You'll delete it after reading this.
Every awesome accomplishment you can think of: it all means shit now.
>> I have SUCCESSFULLY changed my business Microsoft account password into something I can remember AND Microsoft accepted it in under an hour of trying!!!!! <<
I want to say a big FUCK YOU to MICROSOFT for WASTING MY BLOODY TIME.
FUCK YOU for giving me a max of 16 characters. DASB&(*(&G*HH*& for telling me every time my password is 100% strength and then after every submit tell me I have to change it AGAIN because it should be harder to guess. WUT?! It was 16 characters including a (capital) letter, number and multiple special characters, WHAT ELSE DO YOU WANT FROM ME?! UNICODE EMOJI'S???!!! ALLOW ME TO USE MORE CHARACTERS SO I WILL MAKE IT HARDER TO GUESS IT, IT'S 2018 FFS.
I don't even understand why my new password is accepted compared to the other one, but fuck it I can access my account again.
Now I might have to find a new job before the company password policy kicks in again.
/me drops everything and walks out of the office to get wasted (not sure if celebrating or just really pissed off)7 -
Last night, I had a nightmare. After I freshly installed Debian on my laptop, i run `ls` inside root dir, then i saw `node_modules` inside of it.
OMG 😱
face screaming in fear
Unicode: U+1F631, UTF-8: F0 9F 98 B11 -
Unicode domains is the shittiest feature introduced in web recently.
People who came up with this idea must be fucking dumb or have ties with internet scammers.12 -
As someone who started with MSDOS 6.2, the idea that I can now put emojis in my directory names in Google Drive fascinates me way more than it should. I've never been able to find my files faster than now.2
-
Unicode I love you!
Who the hell invented the unicode character 'ZERO WIDTH SPACE'
https://fileformat.info/info/... 6
6 -
Unicode support pl0x.
So I had an Windows account with AzureAD, and my real name has "ő" and "ó" in it, and software that did not support Unicde started flipping the fuck out.
I was intially going with junctioning every bullshit corrupted user folder name that showed up in the ENOENTs to my real user folder, but that didn't solve it for a couple of software.
I was trying to share my drives with Docker, but the same shit occurred. No error message, it just didn't work. I ended up creating a new user account for Docker to share the drive with.
I was trying to use the Travis CLI to set up releases, etc., but it replaced the "ő" with "?". Y U DO THAT?! Common knowledge is that "?" and other special characters cannot be in entity names. SO WHY DO YOU REPLACE THE UNKNOWN CHARACTER IN A PATH WITH THAT? And it wasn't a character not found character either! It was just a straight question mark.
I ended up creating a new user account because I couldn't change the name of the current one because fuck AzureAD, and Windows just decided to FUCKING TRASH MY ACCOUNT. I went over to the new one, copied over some files from the old one, tried to go back to the old one to copy env variables, but I noticed that the account has been purged from the registry... At least the files haven't been deleted.
I ended up reinstalling Windows.
After all my frustration, I recommend all companies with a CLI to visit the following website: http://uplz.skiilaa.me/
Thanks.1 -
Staring at a CSV file full of data looking for that one extra comma or stray double quote or some out of place Unicode character that might exist but you don't know which of the hundreds it could be feels like staring into a pit of despair.7
-
FUCK THE WINDOWS TEXT EDITOR FOR USING UNICODE WITHOUT TELLING ME. I SPEND HALF AN OUR FIGURING OUT WHY "1" COULDN'T BE PARSED INTO AN INTEGER.
-
>Gets assigned to this private Game server's project
>Boss wants me to improve the anti advertisement chat
> k
> Looks at old code
> Code is replacing unicode characters to latin ones that look similar which are being used for advertising
> lol'd who tf developed this
> regex101, building a regex query with endless of possibilities (would look something like this) /((L|\|_|I_)(O|0|\[\]|\(\))(L|\|_|_))/gi to detect lol
> Adds alot of similar looking unicode characters to assure that it will find something
> Works really well in the dev version
> Server open hour
> 30 players
> All chat at the same time
> CPU 100%
> BOSS NEVER TOLD ME TO MAKE IT EFFICIENT1 -
Random thought:
I rarely see emojis on devrant and most of the time I see them, they are used in a rather cringe-full way. There are some posts however, which use emojis in a way I like, for example to replace the client's name.
But my favorite emoji is still the shrug emoji, not the Unicode shrug emoji, but the *real* shrug emoji. ¯\_( ツ)_/¯10 -
u+200b.
Who made that shit? and whhhyyyyy?
I spent 20 minutes trying to figure out why the code file, a mac using co-worker sent me, does not compile.
Intlij did not help, np++ did not help, textmate did not help!
Only hex editing the file worked!
kill it with fire!5 -
This makes me laugh a lot. I changed my online ledger app to use a unicode character in the URL, which I should probably just use a rewrite rule to accomplish, but for now just to see if it works I tried it out. After confirming that it does, I commited it.

-
Problem saving emojis to your database? MySQL’s utf8 only allows you to store 5.88% of all possible Unicode code points. https://mathiasbynens.be/notes/...1
-
Working on a project with third party web developers who don't know multiple language support, difference between UTF-8 and Unicode.
Other than that, life's good4 -
Unicode's biggest problem is that it isn't a streamable format. Given a section of a Unicode string, it's impossible to assert that the next character won't be an accent or zwj or other modifier. This means that it's impossible to convert stdin into an iterator over canonicalized Unicode graphemes.12
-
Recently installed SonarQube and its been amazing to see the level of code quality (or lack thereof)
Some projects have 30 to 60 days of technical debt and I found a few files with a cyclomatic complexity over 100. I’m still learning what the “good” numbers should be.
Yesterday, couple of devs were very proud they were going to start reducing the numbers, they started with one of my solutions that had 5 minutes of technical debt. Yes, 5 minutes.
DevA: “OMG…look at this…it has a cyclomatic complexity of 11…that’s terrible. I thought we were supposed to be professional developers.”
DevB: “And take a look at this, he used the double-slash instead of a triple slash for comments. How does any of code even compile?!”
Me: “Maybe we should tweak some of those SonarQube rules so they make more sense to our code base. We’re never going to use unicode, so all those string culture warnings should go away and code comment formatting? Who cares? Be happy we have comments. I think we should also focus on the bigger fish in that pond. The CRM project is one of the biggest and has a lot of improvement opportunities.”
DevB: “There you go again, don’t bring me problems, bring me solutions..ha ha”
DevA: “Yea, no kidding …hey…did you see the logger? OMG…the whole class is over 25 lines…we gotta split that up into smaller projects so it’s more manageable.”
It’s a good thing our revenue stream isn’t dependent on people getting work done.3 -
Which misanthropic, terrible, perverse excuse for a dogfucker decided that damned non breaking spaces (SPACES!) return false on isWhitespace? It's in the name, space, it's white, it's a fucking white space, a whitespace if you will so who do I have to kill for wasting two damned hours of my life trying to parse away those bastards?3
-
it FUCKING annoys me like hell that in the year of 2017 powershell cannot display more than 16 colors and output unicode symbols properly!
i mean.. fuck that shit!4 -
!rant from a support guy
I was tasked to migrate an Exchange 2003 server (yes, those are still used) for an upcoming Office 365 deployment. There are no direct upgrade path from one another, as far as we know
My task was to export PSTs from mailboxes. Great, a native tool exist for that in 2003 (exmerge). But only for less than 2 GB mailboxes because ANSI/Unicode! Half of our mailbox busts that limit. Oh, it seems Exchange 2007 has a PowerShell command for exporting to PST as well! But pre-SP3, that command relies on a local installation of Outlook on the server (DAFUQ), and has been superseded by another "standalone" powershell command. So I install a bogus Windows 2012 server only for that purpose, with Exchange Management Tools (which, by the way, is bundled with the Exchange installation setup and REQUIRES to have IIS installed on the target machine. Also, if you install ONLY the Exchange 2007 Management Tools and wish to uninstall them afterwards, you can't because the uninstaller wants me to select an Exchange Role to remove, which are all unchecked in my tools-only setup). Never worked, and Google-fu says that the newer Exchange 2007 New-MailboxExportRequest command seems to have removed Exchange 2003 support.
So i'm back to installing a pre-SP3 Exchange 2007. Then the older Export-Mailbox powershell command whines about 64bits and 32bit incompatiblity-- actually I ***HAVE*** to have the whole OS/software stack 32bit ONLY. Don't ask me why!
Some article I found says I could fire up an XP virtual machine for that, I go for Win 7 x86. "Sorry, Microsoft Exchange won't be installed on a workstation environment because reasons." All right then, let's go for an old Windows Server 2003 x86. Have you tried to boot this up in an Hyper-V environment where mouse and keyboard support for Windows Server 2003 are apparently optional? No keyboard AND mouse events sent to the guest machine at all.
* Sigh *, let's use a Windows Server 2008, but WATCH OUT! Microsoft has discontinued x86 support on their W2008 R2 release, so non-R2 for me. Even then, mouse event wasn't sent until I installed guest additions.
After all, export-mailbox ended up working, but that costed me two days of banging my head against the wall. (Oh, and I take internal calls inbetween as well...)
And that's why I aspire to be a programmer. Thank you for nothing, Microsoft!4 -
I must be some kind of retard to think that a fallback font would actually handle the characters not handled by the previous fonts.
I hate configuring fonts so fucking much4 -
i'm lost as fuck in my physics class my teacher decided to use the unicode smile ☺︎︎ instead of x in the equations instead of helping me??
the fuck?5 -
Discussion Question for Web Devs and Server Admins.
Should we use unicode (Non-English/Latin) text in URL?
Eg: unicode blog title converted to use as permalink13 -
Spent two hours debugging my filter for truncated tweets (ending with "...") Only to find out that Twitter uses a fucking ellipsis Unicode character
*Bangs head against wall* -
This regular expression documentation thing is coming along. Added capture groups and backreferences. Think I just need to tackle Unicode property escapes and control characters.
But now I feel like I should have implemented it differently. Like, maybe instead of “‘a’ followed by ‘b’ followed by ‘c’, I should have just done ‘abc’.
*sigh*1 -
FUCK YOU EMOJIS! FUCK YOU AND YOUR EVER FUCKING GOD DAMN SPECIAL WAY OF BEING HANDLED.
Now that I have that part out...
I really fucking hate emoji at this time. Currently I'm working on one of my projects that has markdown support. One of the things I'm extendending the parser with is github style emoji (eg. :smile:) now this part works great. The problem however is getting that short code into a unicode char for HTML. And at the same time I have to take any unicode emoji inserted into the text box by phones and stuff and convert them into the shortcode (My database does support emoji but it's much nicer to store all emoji with the same standard)
All of this has taken 5 hours of research (needed a database of unicode -> short names) and several hours of converting the data from someone elses json into something I can use. (AKA Shrinking the damn file to only what I need) and now I've spent 5 more hours working on the actual code. And I still don't have it working properly.3 -
ok hear me out: local unicode
by that i mean, unicode designates a character that is designated to show up differently for each person
for example, 👤, and your operating system replaces it with you profile picture
or maybe some unused character could be your favorite color and you'd set it in your operating system settings10 -
Hmm... I need to save generated on site rsa key in browser... O there is a npm module for that! This should be fast
4 hours later
Fuuuuuck:
http://fileformat.info/info/... -
TLDR;
Side project update.
Made simple nlp library in python and published it’s first version to open source.
Now I can feed it with parsed pdf text.
See rant https://devrant.com/rants/2192388/...
Why ?
Cause during reading book about nltk I couldn’t find simple extendible way to provide support for polish language and I wanted to abstract stemming, word normalization, tokenizer etc. so I can provide ex. different conditions for separate text files and don’t write much code what is an asset when you work solo.
It’s about 12GB of pdf public accessible law data I am trying to handle ( at first ) which is about 35000 files from last 90 years.
So far I automated downloading web pages and pdf documents from them. Extracting data from web pages and saving it to database. Extracting text from pdf files. I have about 5-6 projects to do all of it above maybe at the end I will put it to some workflow manager like Luigi or just run it by cronjob.
First thing for website version 1.0 part is find correlation between all documents inside law text using nlp library by building custom conditions. Then just generate directory structure and html files with links between documents.
Website version 2.0 is already in my mind but it will be creepy to make it and will take at least 1-2 months and I want to publish fast.
I have some pdfs with only images instead of text and tesseract worked quite good with them so maybe I will try to process them when everything go live.
Learned a lot about pdf as now I know that font in pdf is not always providing unicode characters ( stupid form of obfuscation) so when you extract text you need to build glyph vector to text map for every font.
Pdf is full vector representation - just like svg - what is logic if you think a bit and know that some printers are running using postscript.
Let’s hope next update will be about flutter mobile app which started all of shit above. It’s almost ready ( except getting data from api I am trying to do and logo for release version ). It’s last piece of puzzle.3 -
I'm back from the dead to rant again. This time it's punycode.
My job has to do with processing the commoncrawl web archives, and for some reason one in 20.000.000 archived webpages crashed my program. After some debugging I found this issue that seems to be the reason my code crashes https://github.com/servo/rust-url/...
To summarize the issue: Since punycode unicode characters can be encoded into domain names. But not every character is allowed. Not only do these invalid domains get registered, I need an in-depth knowledge about unicode to understand what is wrong here.
How did we turn domain names into something so complicated?3 -
a lot of dev have a miss concept about Unicode/utf8 including me but I believe my understanding get Better and this my last version.
For a project i was developing a rest api for mobile app
when an ios dev asked me
"I send you Unicode string but it appears as ????? in admin web panel "
OMG!!!😨😨😨
Unicode is not an encoding nor an algorithm. it's a standerd which just map a glyph to a codepiont .
but utf8 is the encoding of Unicode and how it's stored or transferred ,
the string you send must be a utf-8 encoded string as the rest of the json you sent . -
I've just learned that some unicode codepoints (like 𘀀) are wider than 1 cell in a normal monospace terminal
Yay, i hecking love unicode
(i want to die)1 -
I love unicode-table.com for what it does, but this does not seem right...
https://unicode-table.com/de/1F98A/ 2
2 -
!rant Spent days reading Unicode docs, trying to make sense of what codepoints were included in every Unicode property escape in JavaScript and awk’ing the heck out of the different text files associated with them.
Then at around midnight the other night, it came to me. I was an idiot.
I could literally just create an array including every Unicode codepoint and write a program to iterate through the array and test if it matched against a Unicode property escape.
Unicode array: https://gist.github.com/AmyShackles...
Program to compare against Unicode property escape: https://gist.github.com/AmyShackles...
So. Much. Easier.
Happy 2024, friends. -
I don't know what the devs at ProShow are smoking but I want some. Their product, specifically ProShow Production, is garbo. Don't get me wrong, the stuff is great for making slideshow with effects and stuff but good GOD.
+ If your image's name or the full path to the image contains anything that is not (I think) ASCII, the program will refuse to work with it.
+ If you're using non-English characters for eg. caption ("ẫ" for example) even on a Unicode font that supports that char, it will render a box. You know which box it is. You have to specifically use a font family to have it rendered correctly at the exchange of ugly-ass fonts that has been overused.
+ A majority of keyboard shortcuts are not supported while editing a slide (Ctrl + A, Ctrl + Z being my two favorite).
The best part? I'm forced to use this thing because of time constraints. I'd rather fry my puny 4GB RAM stick and crappy Intel HD Graphics 550 working with Premiere/After Effects than using ProShow. But nooope. ProShow. Fuck you. -
It took me five hours to find a Byte Order Mark added at the beginning of a configuration file of a php application.
Everything was working but every downloaded file was corrupted (the bom sequence was prepended to the content). -
So this rant:
https://devrant.com/rants/3969110/...
introduced me to the unicode's "zero width space". Lately I've been using it to cheat on "required" fields in forms. Hahaha thanks!4 -
Question for Droid gurus here.
Is there any way to use different fonts in android for different languages ?
I have changed ttf to add urdu fonts but then I'm seeing boxes instead of emoji and symbols. Can I add it to urdu only.
On web we have CSS unicode-range in @font-face which sets a boundary for different fonts to be used for different unicode characters/ranges.
Can this be done in android system some way ?
I'm not talking about using it in an app but in whole droid. 1
1 -
From a little bit heated discussion I want to extract this: One big pain in the ass is the human to computer interface. Maybe it's the natural vs. formal language divide, but there's a mismatch deeper than between object and relational models that no ORM can failingly fix.
The whole point of the discussion was on such a point where some wanted an interface more human friendly and I stubbornly insisted on the way it is simple for the computer system. Like not too much human messiness should invade machine. One argument sounded as if human words were like unicode code points which meaning doesn't depend on its representation.
That's raising red flags to me: Nonono, natural language is too messy, keep it out. This poor machine could have been so clean and well designed and we already stacked up so much entropy we still dare to call OS,..
Dunno, what's your stance? Still hoping that your shell one day will be able to process our poor standard English? Or do you think, like me, all those failed attempts show there's a gap you should not even touch?5 -
"Indicates triumph, not anger"
You know something went wrong when you have to explicitly say that. Besides, I only see people using this emoji to indicate anger. 2
2 -
i had a project in a networking class where the provided code was meant to act as a proxy (aka just passing bytes around), but because of the implementation, every byte had to be a valid unicode character
anyway lotta people were frustrated so we asked the course staff and their response was basically "we wanted to support python 2 and 3"
...1 -
Fuck those weird encoding issues with Python! I've read the HowTo Unicode 10 or 20 times and I still got those 'ordinal not in range error'!!!2
-
Before Unicode was ruined by millennials
Most systems didn't support it and
Old school expressions were in ascii
See
: - ) ())===========>. 0 - :
Oh the universal experience so many of you people are remembering right now
Merry Christmas5 -
I was determined PHP advocate, always ready for debate with PHP criticizers. I am stacking with dozen other languages so I used to think I have all right to do just that. My code is fully OO, I used to scale FPM horizontally, eventually, with help of pthreds even vertically. With help of redis and chaching, I thought I was sorcerer, as I always find a way (or way around) to make things work, things that no one used to beleive it's possible. One day I started to work for language engineering company, when I suddenly realized how PHP often fails with it's come to localizations, translation, exotic charsets and over all multibyte operations. :( Whole this thing collapses. Wholes everywhere...3
-
OK, so I've been working on processing a Japanese dictionary file and things are going smoothly for the most part. Out of ~185,000 entries, I've got 35 that are still causing problems.
The error I'm getting is "Incorrect string value '\xF0\xA4\xAD\xAF' for column...". I've checked all of my encoding and collation settings, and I'm pretty sure I've got it set to properly implement all of Unicode (as well as it does, anyway), as shown in the image attached. My suspicion is the problem characters are likely among the JIS X 0213 character set; in either case we're clearly dealing with a 4-byte character encoding issue here.
If needed I can attach a flag in the database and base64 encode these particular entries so the data isn't lost, but I'd like to just get it to handle the data properly in the first place if possible.
Anyone have any ideas on other items I can check to resolve the error? 10
10 -
Oh look, the code points each script_extension matches when using Unicode property escapes in JavaScript regular expressions.
https://gist.github.com/AmyShackles...
Annnnnd apropos of nothing, I’m trying to learn Hungarian on the side for fun because I made a Hungarian friend. Forgot how hard language learning was!1 -
I'm creating a bitmap font right now and wanted to automatically generate a image with some text so I can track my progress how it looks. gnome-font-viewer displays it fine, but it'd nothing compared to some real text. Well, how hard can it be?
First attempt: Use ImageMagick to create an image and draw some text. I found a forum post in the ImageMagick forums from 2017 claiming incorrect rendering of BDF fonts, which was promised to be fixed. Yet convert does exactly nothing besides saying “couldn't read font”.
Looking around, there is exactly one tool for the job I'm looking to get done: pbmtext. It works, but doesn't support Unicode. Egh.
Maybe I could write a short script to do it, then? Python's Pillow can import Bitmap fonts (cairo can't). Halfway done I notice it can't deal with anything outside of the character range 0..256.
Using FreeFont directly is out of the question as that seems to be equally much work as creating the font in the first place. I briefly tried SDL, but the font formats it understands are limited.
So how about converting the font then, you ask? Everyone seems to be only concerned about the other way (like OTF to BDF). I tried loading the font into FontForge and exporting an OTF or TTF but couldn't get anything out of it that ImageMagick recognizes as a font.
It seems fucking impossible to render text to an image with an Unicode BDF font in some automated way.
To add insult to injury, my searches containing “bdf” are always interpreted as with “pdf”. I'm not even a Franconian, I can distinguish B and P!4 -
Was that a good idea to use unicode symbols in a terminal UI application?
I thought that it'd be okay since TUI library is using unicode for drawing borders. But I'm not sure.
What do you guys say?8 -
The one thing I need, a "LATIN SMALL LETTER REVERSED C WITH DIAERESIS" doesn't seem to exist but "LATIN SMALL LETTER C WITH DIAERESIS" the one thing that I don't need, does D:
Like there's a god dang sideways u with an umlaut (or diaeresis I guess) but not a reversed c̈? pls4 -
Yet another unusual take for the Orchid STL: Unicode codepoints aren't a part of the string library.
For the purposes of a high level language, the unit of text is a grapheme. Strings can be converted between Unicode and binary blobs. In a binary, indices address bytes. In text, indices address graphemes. For example, searching a string for a substring that consists of a single letter implies the added constraint that the letter must not have accents or other modifiers.
For storage and transfer optimization it's possible to discover the byte length of a string without converting it to binary2 -
For some reason I always have a hard time mentally mapping "asc/desc" to dates. I think of stairs and mentally map the dates to unicode timestamps. Am I the only one? Sort descending by date is newest first, btw6
-
Ever copied code from somewhere and had to deal with searching and fixing the stupid undefined Unicode character error for an hour (¬_¬)3
-
"If you think it would be cute to align all of the equals signs in your code, if you spend time configuring your window manager or editor, if put unicode check marks in your test runner, if you add unnecessary hierarchies in your code directories, if you are doing anything beyond just solving the problem - you don't understand how fucked the whole thing is. No one gives a fuck about the glib object model.
The only thing that matters in software is the experience of the user."
— Ryan Dahl (https://tinyclouds.org/rant.html)6 -
GWT... And you know what is worse than that... SmartGWT.
Combine it with a client in government sector in French speaking African country who has an iPhone for 'his testing' and wants site to show french text on IE6 and newer because it's a government project and that's where shit must run.
Those who created it, I appreciate their intentions. But, you write things in Java, compile it and then separate the UI part and backend part. And if something breaks, which happens in most of the cases, no you can't just right click and 'inspect element'. Because it is IE 7! Now you try it out again, compile it, place it separately and wish your luck, which also sucks most of the time.
...and yeah, don't forget to clean cache in browser. I remember the time when to refresh content on Facebook, I used to clean cache and then refresh.
I'm a backend developer now, shit still sucks, but at least a lot of things are logical. I have a very high respect for UI developer, I really do, especially those who develop for Internet explorer. -
Which keyboard do you use on phone? I got curious because lot is people are using Unicode character, so looking for some support other than copy paste from Unicode app or web page.4
-
Can we zip some unicode files using Windows 'Send To'? I have been unsuccessful in doing it. Any thoughts?
P.S- Don't want to use any third party software.1








































































































Top Tags
Weekly Rant
View