
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
TOP 10 PROGRAMMING BEST PRACTICES
#1 Start numbering from 0.
#10 Sort elements in lexicographic order for readability.
#2 Use consistent indentation.
#3 use Consistent Casing.
#4.000000000000001 Use floating-point arithmetic only where necessary.
#5 Not avoiding double negations is not smart.
#6 Not recommended is Yoda style.
#7 See rule #7.
#8 Avoid deadlocks.
#9 ISO-8859 is passé - Use UTF-8 if you ▯ Unicode.
#A Prefer base 10 for human-readable messages.
#10 See rule #7.
#10 Don't repeat yourself.12 -
Please do rename the "master" branch to "Führer". The umlaut will probably catch a bunch of applications that aren't UTF-8 ready.14
-
Wow, what a fucking mess this sunday was.
My boss wrote me an email that one route of a RESTful API we wrote for a customer was not working anymore and puking back a status 500 with some error mentioning invalid UTF-8 characters.
Not one single person has had touched nor changed the code on production in some 6 months, so what the fuck could it be?
Phpunit did not give any errors (running only locally), the code had no syntax errors and the DB dump did not contain any invalid bytes (tested with a hex editor).
WHAT THE FUCK?!
OK so I started to comment out lines (all tested directly on production of course) until the error vanished.
Guess what was the culprit?
.
.
.
.
.
.
In the code (PHP) we used strftime(...) to get nice time strings. Of course we set the correct locale on the server, thus having months and days formatted in German.
So, in Geman there is this one mysterious month called "März" which contains an umlaut character.
Calling strftime generated the date with März in it, but the server locale was de_CH.iso-8859-1 and not fucking de_CH.utf8, so the "ä" was returned as 0xE4 instead of 0xC3A4 (valid UTF-8), which json_encode(...) did not want to swallow but instead threw an exception.8 -
*wrestling commentator voice*
"In this weeks episode of encoding hell:
The iiiinnnfamous UTF-8 Byte Order Mark veeeersus PHP!"
For an online shop we developed, there is currently a CSV upload feature in review by our client. Before we developed this feature, we created together with the client a very precise specification, including the file format and encoding (UTF-8).
After the first test day, the client informed us, that there were invalid characters after processing the uploaded file.
We checked the code and compared the customer's file with our template.
The file was encoded in ISO-8859-1 and NOT as specified UTF-8.
But what ever, we had to add an encoding check, thus allowing both encodings from now on.
Well well well welly welly fucking well...
Test day 2: We receive an email from said client, that the CSV is not working, again.
This time: UTF-8 encoding, but some fields had more colums with different values than specified.
Fucking hell.
We tell the customer that.
(I was about to write a nice death threat novel to them, but my boss held me back)
Testing day 3, today:
"The uploading feature is not working with our file, please fix it."
I tried to debug it, but only got misleading errors. After about 30 minutes, at 20 stacks of hatered, I finally had an idea to check the file in a hex editor:
God fucking what!?!!?!11?!1!!!?2!!
The encoding was valid UTF-8, all columns and fields were correct, but this time the file contained somthing different.
Something the world does not need.
Something nearly as wasteful as driving a monster truck in first gear from NYC to LA.
It was the UTF-8 Byte Order Mark.
3 bytes of pure hell.
Fucking 0xEFBBBF.
The archenemy of PHP and sane people.
If the devil had sex with the ethernet port of a rusty Mac OS X Server, then 9 microseconds later a UTF-8 BOM would have been born.
OK, maybe if PHP would actually cope with these bytes of death without crashing, that would be great.3 -
Random thought coming through
Emojis are UTF-8 and there are a TON of them. Wouldn't a password made out of Emojis be way more secure than a normal one?28 -
Finally Spend two fucking days debugging shit until I figured it it. Freaking stupid shit encoding problems and old data combined isn't fun. Dafuq why can't everybody use UTF-8 or Unicode or something else but PLEASE stop using some old school IBM shit codepages.
Leckt mich doch am arsch mit diesem scheiß man -_-3 -
Was just thinking of building a command line tool's to ease development of some of my games assets (Just packing them all together) and seeing as I want to use gamemaker studio 2 thought that my obsession with JSON would be perfect for use with it's ds_map functions so lets start understanding the backend of these functions to tie them with my CL tool...
*See's ds_map_secure_save*
Oh this might be helpful, easily save a data structure with decent encryption...
*Looks at saved output and starts noticing some patterns*
Hmm, this looks kinda familiar... Hmmm using UTF-8, always ends with =, seems to always have 8 random numbers at the start.. almost like padding... Wait... this is just base64!
Now yoyogames, I understand encryption can be hard but calling base64 'secure' is like me flopping my knob on the table and calling it a subtle flirt...6 -
Screw MySQL/MariaDB. Who the fuck thought not to document that utf8 is only 3 bytes and not unicode capable. You have to use utf8mb4 for it to work. Fuck those idiots that don't want to admit they made a mistake and put this info in a footnote on a pricy documentation piece.5
-
What kind of rusty asshole develops an FTP client which seemingly treats uppercase and lowercase filenames as exactly the same and is not able to fucking understant UTF-8 filenames!?
OK or maybe it was the shitty ass server to which I had to deploy the website to.
I've never been so pissed in my life.
It's already an asshole torture to upload 2.3 giggle bytes of pixel jizz, but 5 hours later, when the site has been made public, you find out that 25% of these images' filenames were automatically renamed during the extraction because some asshole dev thought it was a great idea to not even inform the user about this behaviour.
Fixing filenames in production while your boss is really pissed next to you the hole time is not a great feeling. Especially when you accidentally purge the whole image cache and the PHP image transform task then blocks thus making the whole site not loading any more images for 40 minutes.
WHAT AN ASSRAPE!
Please don't comment. I'm still too pissed to read comments. Thanks.4 -
In my uni course "Algorithms and Data structures" we use Java. Fine. Definitely not my preferred language but it's not like I have a choice.
Anyway, our teacher uploads code files for us to use as reference/examples. The problem is, they look like this. Not only does she not indent the code, she also uses a charset that is not utf-8.
In the rare cases where she does indent the code, she uses THREE, yes THREE spaces...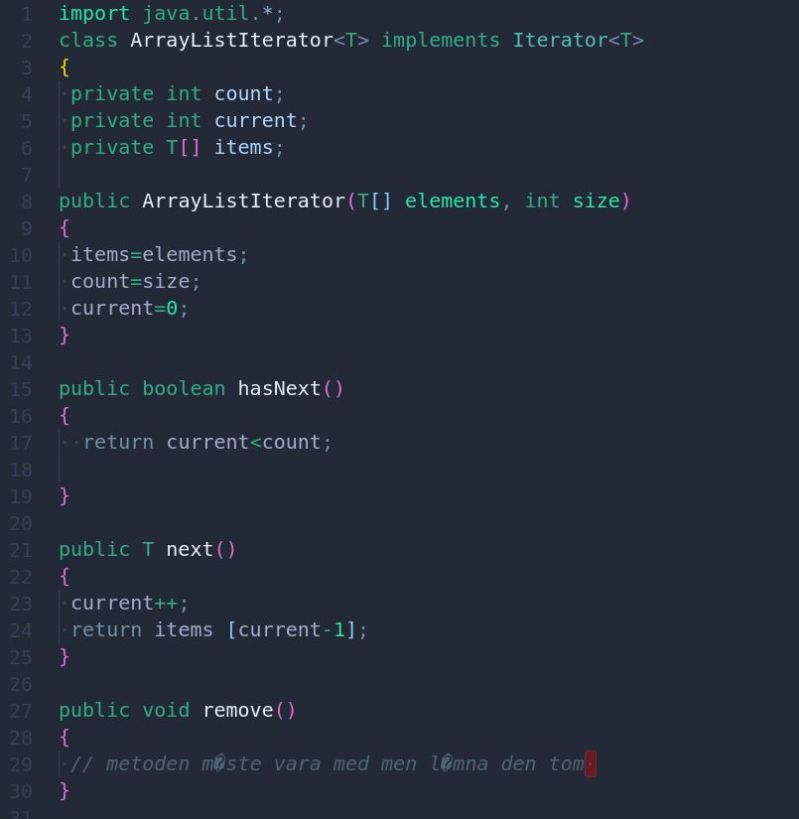 23
23 -
So... did I mention I sometimes hate banks?
But I'll start at the beginning.
In the beginning, the big bang created the universe and evolution created humans, penguins, polar bea... oh well, fuck it, a couple million years fast forward...
Your trusted, local flightless bird walks into a bank to open an account. This, on its own, was a mistake, but opening an online bank account as a minor (which I was before I turned 18, because that was how things worked) was not that easy at the time.
So, yours truly of course signs a contract, binding me to follow the BSI Grundschutz (A basic security standard in Germany, it's not a law, but part of some contracts. It contains basic security advice like "don't run unknown software, install antivirus/firewall, use strong passwords", so it's just a basic prototype for a security policy).
The copy provided with my contract states a minimum password length of 8 (somewhat reasonable if you don't limit yourself to alphanumeric, include the entire UTF 8 standard and so on).
The bank's online banking password length is limited to 5 characters. So... fuck the contract, huh?
Calling support, they claimed that it is a "technical neccessity" (I never state my job when calling a support line. The more skilled people on the other hand notice it sooner or later, the others - why bother telling them) and that it is "stored encrypted". Why they use a nonstandard way of storing and encrypting it and making it that easy to brute-force it... no idea.
However, after three login attempts, the account is blocked, so a brute force attack turns into a DOS attack.
And since the only way to unblock it is to physically appear in a branch, you just would need to hit a couple thousand accounts in a neighbourhood (not a lot if you use bots and know a thing or two about the syntax of IBAN numbers) and fill up all the branches with lots of potential hostages for your planned heist or terrorist attack. Quite useful.
So, after getting nowhere with the support - After suggesting to change my username to something cryptic and insisting that their homegrown, 2FA would prevent attacks. Unless someone would login (which worked without 2FA because the 2FA only is used when moving money), report the card missing, request a new one to a different address and log in with that. Which, you know, is quite likely to happen and be blamed on the customer.
So... I went to cancel my account there - seeing as I could not fulfill my contract as a customer. I've signed to use a minimum password length of 8. I can only use a password length of 5.
Contract void. Sometimes, I love dealing with idiots.
And these people are in charge of billions of money, stock and assets. I think I'll move to... idk, Antarctica?4 -
Yesterday a strange bug appeared in Chrome: In a small web app we have some umlaut characters like äöü. Strangely said characters were displayed as cyrillic, but only on my pc... On every other device it worked. I spent about 5 hours of checking encodings (everything was in UTF-8), reading posts in the almighty stackoverflow.
Finally i figured out, the font was broken. After reinstalling it, everything was peaceful again in my head. -
My favorite OpenSource project is Julia (www.julialang.org). As a physicist, I could never really befriend myself with OOP. With Julia I can write beautiful Code, which I also understand (with full UTF-8 support).
In Python you write pseudo code in Julia you write math.
In Addition, there is an optional package on Github for every fuck which can be handled by the integrated package manager (like using QML, Distributions, Databases, HTTP Server, and so on...)4 -
Last night, I had a nightmare. After I freshly installed Debian on my laptop, i run `ls` inside root dir, then i saw `node_modules` inside of it.
OMG 😱
face screaming in fear
Unicode: U+1F631, UTF-8: F0 9F 98 B11 -
TL:DR
Why do so shitty "API"s exist that are even harder to write than proper ones? D:
Trying to hack my venilation at home.
This API is so horrible D:
The API is only based on POST requests no matter if you want to write values or get values and the response only contains XML with cryptic values like:
<?xml version="1.0" encoding="UTF-8"?>
<PARAMETER>
<LANG>de</LANG>
<ID>v01306</ID>
<VA>00011100000000000000000010000001</VA>
<ID>v00024</ID>
<VA>0</VA>
<ID>v00033</ID>
<VA>2</VA>
<ID>v00037</ID>
<VA>0</VA>
Also there are multiple API routes like
POST /data/werte1.xml
POST /data/werte2.xml
POST /data/werte3.xml
POST /data/werte4.xml
And actually the real API route is only given in the request body and not in the path.
Why is this so shitty? D:<
Btw in terms of security this is also top notch. It just globally saves if one computer sends the login password.
I mean why even ask for a password then? D:
That made me end up with a cronjob to send a login request so I don't have to login on any device.
PS:
You see, great piece of German engineering.3 -
Fucking gnu gettext, fucking .po and .mo files and fuck the fucking poedit. Why in the fucking hell a damn i18n solution used by so many languages doesn't support correctly fucking utf 8 characters in strings inside the code, I mean, WHAT THE FUCK, this is my second day trying to make the fucking Python gettext module to translate the fucking word "está" because I've a fucking big code base programming in Spanish that need to be translated. This is the fucking 2016 and we still have problems with fucking special characters? I mean CMMON1
-
For fucks sake! It's 2018 and MS™ Excel™ is still not able to store a file in UTF-8...
And neither can you choose the separators when opening a CSV.
Go eat a bag of corporate dicks and greedily choke on it to an agonizing death.5 -
Me: *spends three days trying to format a string to replace two backslashes with one*
Python: Here you go!
str = bytes(str,"utf-8")
.decode("unicode_escape")7 -
Crazy... Hm, that could qualify for a *lot*.
Craziest. Probably misusage or rather "brain damaged" knowledge about HTTP.
I've seen a lot of wild things when devs start poking standards, but the tip of the iceberg was someone trying to use UTF-8 in headers...
You might have guessed it - German umlauts. :(
Coz yeah. Fucktard loved writing everything in german, so why not write custom header names in german.
The fun thing is: It *can* work, though the usual sane thing is to keep it in ASCII range for the obvious reason that using UTF-8 (or ISO-8859-1, which is *not* ASCII) is a gamble you gonna loose.
The fun game was that after putting in a much needed load balancer between services for monitoring / scaling etc suddenly *something* seemed off.
It took me 2 days and a lot of Wireshark hoola hooping to find out why, cause the header was used for device detection aka wether it's a bot or not. Or in the german term the dev used: "Geräte-Art".
As the fallback was to assume a bot, but only rate limit based on IP, only few managed to achieve the necessary rate limit to get blocked.
So when I say *something* seemed off, I really mean a spooky kind of "sometimes IP blocked for seemingly no reason at all".
Fun stuff. The dev btw germanized everything. Untangling the code base was a lot of non fun. -.-6 -
That one fucking time my text editor so damn high, that it choose to encode my file utf-8 BOM.
I was using Notepad++ because I thought it would just provide a good syntax highlighting, without stabbing me in the back
Seemingly nothing wrong with the code, but it took me, a friend and two teacher almost half an hour to figure out why the css simply wasn't work, even though it was clearly used and worker as intended when embeded in the file.
This was some years ago, so please don't judge me for my editor of choice at that time
Other than that, i simply suck at css and gladly use css frameworks 😅8 -
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from rant import depression as fuck
from WhiskeyBottle import *
import time
while bottle.contents > 0.0 and time.datetime():
fuck.rant()
Yeah ok, this will be one of a few, but I'll try to keep it short. Damn, whiskey is not helping. Nor various smokables.
So yeah, have you ever had a dream? I consider myself a gamer the whole life, always loved creative worlds, dynamics, mechanics, plots, stuff you could and couldn't do. To the point I promised myself I'd make a game - NAH - I'll be making games in the future. You know, good games, that you come back to. Like Doom. Or those porn games.
Never went to Uni or nothing. Was born in a poor European country with Internet more broken than my soul right now. Years later, after acquiring some good hardware, learning a bunch of languages, Unity, Unreal Engine 4 and experimenting for about 10 years now with small scripts, apps and mini-games I've come to this realization.
I only made one "full" "game" in my life, and that was when I was like 16 in Klik & Play (early Game Maker). And it was shit. It was horrible, horrible shit. It literally makes you want to cry when you play it. It's 16-bit brain cancer. And it's the best I've ever published.
Now I've been through countless prototypes, none of which I've developed any further. I had ideas, plans, even made some more advanced roadmaps and dev cycles. Estimated costs, time, mechanics, gameplay hooks.
I never finish anything.
I get bored. Frustrated sometimes. There's always an improvement, something that "if I'd finish that it would be it! Screw this thing I was working on now, THAT will be worth sacrificing it." It's tiresome. I'm getting old.
And honestly, I don't know how people do it anymore. Trying to compromise those side-projects (they take all my free time which is not much) and work is just... draining. I'm losing hope. Maybe I shouldn't be allowed into the gamedev world after all. Maybe I'll just pump half-assed pieces of crap everybody will hate.
Or worse, nobody will care.7 -
UTF-8, one of the biggest hack that we use everyday. First draft of UTF-8 was written on the back of the napkin.
https://cl.cam.ac.uk/~mgk25/ucs/...
https://youtube.com/watch/...3 -
How to write a proper Hello World program in Java:
public class ProperJavaProgram {
public static void main(String[] args) {
try {
// Write the hello world file
List<String> lines = Arrays.asList(
"#include <stdio.h>",
"int main() {",
"printf(\"Hello World!\\n\");",
"return 0;",
"}"
);
Path file = Paths.get("awesome-program.c");
Files.write(file, lines, Charset.forName("UTF-8"));
// Execute the file
executeCommand("cc awesome-c-program.c -o awesome-executable");
executeCommand("./awesome-executable");
} catch (IOException e) {
System.out.println("You're screwed, just use Java and get over it. " + e);
}
}
public static void executeCommand(String command) {
try {
Process p = Runtime.getRuntime().exec(command); // Run the process
BufferedReader stdInput = new BufferedReader(new InputStreamReader(p.getInputStream())); // Get the output
String s; // Print out the output
while ((s = stdInput.readLine()) != null) {
System.out.println(s);
}
} catch (IOException e) {
System.out.println("You're screwed, just use Java and get over it. " + e); // UR SCREWED
}
}
}2 -
Todays rant is about me trying to add some long text into my database. I tried it all day long, but the text was inserted partially all the time. I changed the collumns data type to BLOB, this felt false, but it seemed to work. The bad feeling triggered me to search further, so I rewrote my code and found the source of this behavior. I used utf8-decode-function on my text and that triggered some problems when inserting the text. I don't completely understand it, but I solved the mystery, that fucked up the day. I will sleep good now.
-
Whenever I want to type the shrug emoji, I copy it from a Google note ¯\_(ツ)_/¯
I can type emojis just fine, enjoy a 🍓, yet there is a clear lack of accessibility for ASCII-emojis input on any device.
How is this fair!?
PS: I do know that this shrug is actually utf8 and not ascii. But that's beside the point. Also try saying “utf8 emoji” three time in a row.8 -
Problem saving emojis to your database? MySQL’s utf8 only allows you to store 5.88% of all possible Unicode code points. https://mathiasbynens.be/notes/...1
-
My legacy is now indisputable in this company!
Utf-8 emojis for pipeline declarations will became a new era for pipes from now on. 1
1 -
So for those of you keeping track, I've become a bit of a data munger of late, something that is both interesting and somewhat frustrating.
I work with a variety of enterprise data sources. Those of you who have done enterprise work will know what I mean. Forget lovely Web APIs with proper authentication and JSON fed by well-known open source libraries. No, I've got the output from an AS/400 to deal with (For the youngsters amongst you, AS/400 is a 1980s IBM mainframe-ish operating system that oriiganlly ran on 48-bit computers). I've got EDIFACT to deal with (for the youngsters amongst you: EDIFACT is the 1980s precursor to XML. It's all cryptic codes, + delimited fields and ' delimited lines) and I've got legacy databases to massage into newer formats, all for what is laughably called my "data warehouse".
But of course, the one system that actually gives me serious problems is the most modern one. It's web-based, on internal servers. It's got all the late-naughties buzzowrds in web development, such as AJAX and JQuery. And it now has a "Web Service" interface at the request of the bosses, that I have to use.
The programmers of this system have based it on that very well-known database: Intersystems Caché. This is an Object Database, and doesn't have an SQL driver by default, so I'm basically required to use this "Web Service".
Let's put aside the poor security. I basically pass a hard-coded human readable string as password in a password field in the GET parameters. This is a step up from no security, to be fair, though not much.
It's the fact that the thing lies. All the files it spits out start with that fateful string: '<?xml version="1.0" encoding="ISO-8859-1"?>' and it lies.
It's all UTF-8, which has made some of my parsers choke, when they're expecting latin-1.
But no, the real lie is the fact that IT IS NOT WELL-FORMED XML. Let alone Valid.
THERE IS NO ROOT ELEMENT!
So now, I have to waste my time writing a proxy for this "web service" that rewrites the XML encoding string on these files, and adds a root element, just so I can spit it at an XML parser. This means added infrastructure for my data munging, and more potential bugs introduced or points of failure.
Let's just say that the developers of this system don't really cope with people wanting to integrate with them. It's amazing that they manage to integrate with third parties at all...2 -
So now I’m working with this code that is roughly documented because ”variable names are self-explanatory”.
Yeah, you just forgot that FORTRAN does not support utf-8 variable names...
Why utf-8? Because then if I see:
real :: 座標(3)
I would understand that you mean ”zahyō”, the usual 3D position array ”r(3)”, but no, I need to deal with:
real :: zah(3)
yeah...🙃🔫16 -
Working on a project with third party web developers who don't know multiple language support, difference between UTF-8 and Unicode.
Other than that, life's good4 -
Why tf people still use anything that is not UTF-8?? I could understand if you are from a language with most of its chars out of the first byte, but still, it is increadible the amount of things encoded using latin-1 and similar others... It is time to STOP!1
-
Seems like the poisoning of the internet is coming to a head. While searching earlier for a first principles reference to answer a question with, I came across an entirely obfuscated query.
"Codd's forms of normalization"
https://google.com/search/...
In the first four pages, there are 5 results that aren't ad farms, crappy pasta tutorial sites, brand building articles, poorly understood rote regurgitation of information, quora, or some combination of all of the above.
In 2005, the top 5 would likely have contained Bell Labs, UoI, Cambridge and Oracle. Mind you, I don't think the world is getting dumber, exactly, just that the signal to noise ratio in the information sphere is getting worse and the risk from that is the world becomes markedly "dumber". The only barrier to entry anymore is how well your SEO optimization competes.
I'm obviously getting old.
/rant6 -
Java 11 is amazing they said, Jigsaw will make things much easier they said, JavaFX is now just a simple Maven dependency they said...
Previous command to launch app in Java 8:
java -jar T10ReleaseFinal.jar
New command to launch app (not including the custom jlink command to produce the custom bundled JRE) in Java 11:
java --module-path "lib/javafx-fxml-11.0.1-win.jar;lib/javafx-web-11.0.1-win.jar;lib/javafx-controls-11.0.1-win.jar;lib/javafx-controls-11.0.1.jar;lib/javafx-media-11.0.1-win.jar;lib/javafx-media-11.0.1.jar;lib/javafx-swing-11.0.1-win.jar;lib/javafx-graphics-11.0.1-win.jar;lib/javafx-graphics-11.0.1.jar;lib/javafx-base-11.0.1-win.jar;lib/javafx-base-11.0.1.jar" -Dfile.encoding=UTF-8 -Dprism.dirtyopts=false -Dglass.accessible.force=false --add-modules javafx.base --add-modules javafx.controls --add-modules javafx.fxml --add-modules javafx.graphics --add-modules javafx.media --add-modules javafx.swing --add-exports javafx.graphics/com.sun.javafx.sg.prism=ALL-UNNAMED --add-exports javafx.graphics/com.sun.javafx.scene=ALL-UNNAMED --add-exports javafx.graphics/com.sun.javafx.util=ALL-UNNAMED --add-exports javafx.base/com.sun.javafx.logging=ALL-UNNAMED --add-exports javafx.graphics/com.sun.prism=ALL-UNNAMED --add-exports javafx.graphics/com.sun.glass.ui=ALL-UNNAMED --add-exports javafx.graphics/com.sun.javafx.geom.transform=ALL-UNNAMED --add-exports javafx.graphics/com.sun.javafx.tk=ALL-UNNAMED --add-exports javafx.graphics/com.sun.glass.utils=ALL-UNNAMED --add-exports javafx.graphics/com.sun.javafx.font=ALL-UNNAMED --add-exports javafx.graphics/com.sun.javafx.application=ALL-UNNAMED --add-exports javafx.controls/com.sun.javafx.scene.control=ALL-UNNAMED --add-exports javafx.graphics/com.sun.javafx.scene.input=ALL-UNNAMED --add-exports javafx.graphics/com.sun.javafx.geom=ALL-UNNAMED --add-exports javafx.graphics/com.sun.prism.paint=ALL-UNNAMED --add-exports javafx.graphics/com.sun.scenario.effect=ALL-UNNAMED --add-exports javafx.graphics/com.sun.javafx.text=ALL-UNNAMED --add-exports javafx.media/com.sun.media.jfxmedia.events=ALL-UNNAMED -jar T10ReleaseFinal.jar4 -
Writing hebrew in Latex using a template that doesn't support UTF-8 is the most archaic shit I've done lately. I feel like some sort of a caveman.
This fucking encoding inverts all letters so it can support right to left. 😓4 -
*laughing maniacally*
Okidoky you lil fucker where you've been hiding...
*streaming tcpdump via SSH to other box, feeding tshark with input filters*
Finally finding a request with an ominous dissector warning about headers...
Not finding anything with silversearcher / ag in the project...
*getting even more pissed causr I've been looking for lil fucker since 2 days*
*generating possible splits of the header name, piping to silversearcher*
*I/O looks like clusterfuck*
Common, it are just dozen gigabytes of text, don't choke just because you have to suck on all the sucking projects this company owns... Don't drown now, lil bukkake princess.
*half an hour later*
Oh... Interesting. Bukkake princess survived and even spilled the tea.
Someone was trying to be overly "eager" to avoid magic numbers...
They concatenated a header name out of several const vars which stem from a static class with like... 300? 400? vars of which I can make no fucking sense at all.
Class literally looks like the most braindamaged thing one could imagine.
And yes... Coming back to the network error I'm debugging since 2 days as it is occuring at erratic intervals and noone knew of course why...
One of the devs changed the const value of one of the variables to have UTF 8 characters. For "cleaner meaning".
Sometimes I just want to electrocute people ...
The reason this didn't pop up all the time was because the test system triggered one call with the header - whenever said dev pushed changes...
And yeah. Test failures can be ignored.
Why bother? Just continue meddling in shit.
I'm glad for the dev that I'm in home office... :@
TLDR: Dev changed const value without thinking, ignoring test failures and I had the fun of debunking for 2 days a mysterious HAProxy failure due to HTTP header validation... -
Funny how fucken emojis, which came into applications (web or even native) by completely overusing them on mobile, don't really work on mobile.1
-
Textexpander. Ggpu = git push upstream, gg. = git add ., and ggc = git commit -m "" ... I love that I don't have to type out my whole damn name, username, email and work email all the time. Just expanding my email address is enough of a win for me with that tool. Also Alfred + utf symbol workflow. And newest addition - vimium to easily pin tabs.2
-
Fuck you safari for automatically converting UTF-8 NFD characters to UTF-8 NFC characters. Cost us like an hour debugging!
-
Without a doubt it has to be the internal company search engine/file finding tool @thewamz and I wrote.
The company has a wide UNC network with files scattered all over the place and they need a way to keep track of where the files get moved to (they can and do get moved). The original tool was written in Java/Tomcat and didn't use any frameworks or utilities beyond custom written ones, no orms, and the SQL was just raw strings. The program didn't take into account that files might be moved or deleted so it never removed anything from the database, it just kept adding files and never removing them.
It however never stores files itself, just links to files elsewhere on the UNC network.
It took six months to get it into what might be a stable beta or release candidate state. The user interface is good, very simple and intuitive, the whole thing was rewritten in python/django, there were issues with utf 8 (and mysql not fully supporting utf 8 in its own utf 8 mode), we added a regex search mode (which was sorely lacking), the search used to take up to fifteen minutes however we sped it up to less than a minute (worst case when a user simply puts "^$" as the regex search). It has a multi threaded design which does some checks to ensure it doesn't spawn too many threads and get stuck in constant Gil switching. Still some bugs to fix, like moving the processing of results returned by the server in a web worker so that the content widget doesn't lock up processing millions of search results and moving the back end to use asynchronous python might gain a performance boost. But on the whole I think the system is ready to replace the older system that all the users are frustrated with and constantly complain about.
However the annoying bit is... How to actually get the new system online, while I am responsible for the development of tools and their maintenance, I am not responsible for their initial deployment and that means I have no idea when (or even if) my new tool will even ever be released :/ -
Microsoft certsrv is returning UTF-8 on the authorization error page but UTF-16 when logging in via basic auth...
Debugged this for 2 hours today to parse the response correctly. Thanks Microsoft -
Just getting a pizza, can't help but get annoyed by the jittery as fuck newsticker, they didn't even get the encoding right....
(Yes our POS software has 60fps jitterless hardware accelerated fully utf-8 encoded newstickers before anyone asks me to do a better job) 2
2 -
So the guy who i mentioned previously with his shitty csv made webservice which i needed to use.
It returned utf-8 encoded xml:
- in file the header contained central europe encoding
- the xml had more roots
- basically he only put his csv format inside xml tags
- csv contained html tags but there wasnt cdata
Now work with this lol
I neded to cut this shit with string functions and also some numeric data get with regexp from htm table td's
Whyyyyyyyyyyyy1 -
evil === true
Found this one after 4 hours of debugging... Want to screw with other teams? Shove some UTF-8 BOM characters into JSON responses consumed by Node (and other frameworks as well). Watch as they scramble to find why JSON.parse() fails on seemingly nothing.
Background: BOM markers are hidden characters that indicate text stream information to applications. They are not ignored by many JSON parsers and throw exceptions that don't appear to make sense.1 -
a lot of dev have a miss concept about Unicode/utf8 including me but I believe my understanding get Better and this my last version.
For a project i was developing a rest api for mobile app
when an ios dev asked me
"I send you Unicode string but it appears as ????? in admin web panel "
OMG!!!😨😨😨
Unicode is not an encoding nor an algorithm. it's a standerd which just map a glyph to a codepiont .
but utf8 is the encoding of Unicode and how it's stored or transferred ,
the string you send must be a utf-8 encoded string as the rest of the json you sent . -
Who, more than I, totally HATE emoji?
lol I hate emoji after it caused so much problems with Microsoft Outlook and email backups from said program combined with emoji in subjects.
Wrote an subject filter in exim4 (took 3 days to debug and get working propely) that totally eradicate anything that isnt ISO-8859-1 from the subject line, then converts the rest to UTF-8 (because said IMAP client isnt following standards).
it also converts ISO-8859-1 characters in subjects to UTF-8 even if the original subject is declared to be UTF-8, because obviously some software (especially newsletter software) are transmitting ISO-8859-1 subjects that are declared to be in UTF-8 (but the opposite isn't true).
And also cuts subject to 100 chars, because too long subjects are a problem too. Same with date headers, I replace them with the server date/time because some software are sending Date: 1970 Jan 01 00:00:00, because some of these erronous headers are put by some mailing list software, aswell as causing problem in OEM clients like Samsung Mail.
Problem solved, all IMAP clients happy on internal network.7 -
Ported proprietary Chinese dll for specific device hid control and my windows program around it to macOS using swift.
Yeah that's pretty much how I feel. -
Why aren't there more programming languages out there that aren't derived from English?
We're in the age of universal UTF-8 support, if it was meant to be then it should be happening now.
+ sarcasm
I mean, we should be more inclusive and allow other flavours of JavaScript that aren't based on English across browser, right? Otherwise that would mean that English is the master language of the web.
- sarcasm5 -
Implementing my own PHP library for Station Playlist Studio, mainly for grabbing the list of songs and requesting songs to be played.
Such a legacy connection... Bad command scheme...
Having it succesfully request songs when UTF-8 ain't even supported properly, is a pita.
Luckily there's been an update to SPL about 2 years later, and my code still works. (:
(Not my biggest accomplishment so far, but those are under RMA..) -
I wish eclipse would use an useful charset like UTF-8, instead of the windows-1252 charset. I feel like he only propose of this damm thing is to give germans a harder time coding
-
Utf-string encoding in windows has been constantly fucking me up... It's been 4 hours and I'm still in the office alone.
-
How many of you belief that devrant Search API supports utf-8 emojis?
Little confused whether this rant be classified as question or devrant!! -
Please, before exporting anything in whatever editor you use, check if it is in UTF-8. Today I didn't knew why my new font wasn't working in certain places and I later discovered that more than 9000 characters were replaced by the replacement character...
-
Fuck encoding and fuck PHP!!!
I'm programming a little vocab trainer to get used to php and MySQL. From an old VB vocab trainer I had ca. 2000 txt-files with words and converted them to sql-queries with a simple python script. When SELECTING words with special characters they become encoded properly. But if I UPDATE words their encoding is just fucked up... The table is utf-8 encoded all the columns are utf-8 encoded. The php mysqli connection is utf-8 encoded. My HTML header is utf-8... WTF? -
I was determined PHP advocate, always ready for debate with PHP criticizers. I am stacking with dozen other languages so I used to think I have all right to do just that. My code is fully OO, I used to scale FPM horizontally, eventually, with help of pthreds even vertically. With help of redis and chaching, I thought I was sorcerer, as I always find a way (or way around) to make things work, things that no one used to beleive it's possible. One day I started to work for language engineering company, when I suddenly realized how PHP often fails with it's come to localizations, translation, exotic charsets and over all multibyte operations. :( Whole this thing collapses. Wholes everywhere...3
-
When the business team promotes the robot: “programmed in Arm Assembly with support for all UTF-8 Character Sets”
(Seen in the info of my high school’s robotics team)
-
SCSS for my personal website:
@charset "UTF-8";
@import "C:///xampp/htdocs/...";
They both use a customised MDL and this way I can maintain code much easier.5 -
This is a question and a rant
I have to get temperature readings from an andriod app written in ionic angular to a webpage written apache wicket... No, I don't have any control over either stack.
The kicker is the wicket app isn't even run properly attached to a domain, it's just run from a box at the client and then the client machines connect through <server ip>:8080/appname
Which means I can't solve my problem by simply having the website and app on the same domain and then use local storage...
I have tried
Ionic
window.postMessage({ type: 'temperatureData', data: tempFormatted }, '*');
Test it from this page
<!-- index.html (web page) -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Web Page</title>
</head>
<body>
<h1>Temperature Data</h1>
<p id="temperatureData">Loading...</p>
<script>
// Listen for messages from the Ionic app
window.addEventListener('message', (event) => {
if (event.data.type === 'temperatureData') {
// Update the temperature data on the page
document.getElementById('temperatureData').textContent = event.data.data;
}
});
</script>
</body>
</html>
Which does not work, the page fails to pick the data.
So my rant is the situation. M question is does anyone have any ideas?7 -
Fastcsv is my knight in shining armour. After reliving the horrors of handling utf-8 csv files with the built in library of Python 2.7 it made my day to see everything work.1
-
when you find a single invisible character in each of your sql files in visual studio that causes a sql implosion saying
invalid syntax near ''
Sublime Text 3 and other tools didn't help. required manually finding this time, in 20 files..... with an overdue project.
I wanted to burn visual studio to the ground 4
4 -
Not exactly a rant but some annoyances
Whenever I copy paste code from kindle it does not space the code. Stack overflow says that kindle is using characters for space which are not present in UTF-8 which causes the issue and the find and replace option coes not work in vs code which the author is using. And if you copy from kindle whether you use the button or Ctrl + C it will add the book title and the author at the end. Who the fuck though this was a good idea.
Oh a table does not fit on the screen render whatever fits even if it is the top line of the table. This is probably not an issue and they cannot fix it and I shoild just deal with it.
The author introduces me to the language compiler and lists a command to what versions are available. I get an error which says the command is not found on windows. I dont find any solutions on google, so I go the next place and author says that he knows about it and shows a link to fix it and tells to folloe the instructions. But the link does not have any instructions and just has instructions to configure the compiler itself. The only releveant information was the path to the compiler which the author could have included there or said that was the only relevant information. The path was correct but I needed to install some stuff through Visual Studio2











































































Top Tags
Weekly Rant
View