
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
A more experienced friend told me
"don't be a pussy, test in production"
I'm the one fixing the bugs, not him 8
8 -
USER: I can't see any data in the page...!
ME: ok, I'll do a check
ME: API calls get no data back. Boss, did you change anything and put it in production?
BOSS: Absolutely not, I just modified the name of what was the "Family" parameter in "Type".
ME: Seems legit. Totally agree. I'm going to lunch. Can you check in the meanwhile why calling the API with "Family" does return nothing? Thanks.3 -
Today is April 1, 2017. Saturday.
Okay, checking emails.
...
WTF errors in production??
Checking...
Oh...
throw new \Exception('April fools!')
-___-2 -
Tested on local work perfectly,
Push to production
Restart service
CPU went up to 100%, process alive but all services down.
Panic.
Try to think of what would be the cause.
With no hope, i restarted the service again.
Everything works as expected.
I still dont know what happened. :/7 -
My code passed the review today. It is now being pushed to production. I can't express my happiness 😅17
-
When you're a junior sysadmin but still have to maintain ALL the production server:
How it looks:
$ sudo apt-get update
How it feels:
& sudo [ $[ $RANDOM % 6 ] == 0 ] && rm -rf / || echo *Click*7 -
🎶 Fixing production issues 🎶
🎶 Fixing production issues 🎶
🎶 In other people’s code! 🎶
Seriously, how am I still in a good mood when I have to deal with this?14 -
Every company has a test environment. Some are lucky enough, to also have a production environment3
-
My computer science teacher won't stop developing on the production server 😭 he switches the branch on the production machine to dev all the time and merges broken code into master. Kill me4
-
My boss last week backed me up with a client. I was working in a production enviorment and the client refused to test the changes made when I told them. So we things started to go wrong and they called to my boss complaning.
He said:
Well you are right. The things are broken but he (me) stayed last night waiting for your response and you didn't gave one. So he is going to work only in the afternoon and you will have to wait.
I must buy a beer for my boss.2 -
We had issues with lack of disk space on our production SQL server. Another developer decided to delete the databases he thought weren't in use to clear some space.
Ever think about checking first?!
Production chaos!7 -
Product Owner: "Our definition of done is putting it on production. So you are only done if it's on production. Otherwise our sprint goal is failed."
So we put it on production.
After deploy, some content manager appears: "Why is the system doing things? I was told this should not happen today."
"Erm, we have put the feature on production as we are only done if it's on production."
"Well, yes. But it should not be live yet!"
Oh well. Communication, or the lack thereof, does never fail to amaze me ¯\_(ツ)_/¯4 -
Every so often I remember that the code I wrote is running in production and real customers are using it and I feel a little bit sick2
-
*production is down*
Ops: At 5pm? On a Friday? *checks deploy history* God! Who did the deploy
Dev: It was a small patch, a tiny patch. It shouldn't have....
Ops: Deploy on a Friday evening?
Colleague: I didn't think it would...
Ops (on the outside) : *takes a deep breath* Its okay Dev, we can fix this. Don't worry
Me(in my mind) : for fuck sakes! Are you fucking kidding me?*** **** *** god damn it! *****9 -
Friend: I just love the adrenaline rush caused by bungee jumping
Me: I just love the adrenaline rush caused by deploying untested code to production server on a Friday night5 -
So we hired an intern and his first task was to change a few things in email layout for our client, which is an investment bank.
I told to one of my developers to make his local database dump and setup the project for an intern. When intern completed the task, my developer thought that title "Dow Jones index crashed" was pretty funny title for a test.
What he didn't thought through enough, is that he forgot to configure fake SMTP server and he had production database dump with real email addresses.
I had really awkward 20 minutes conversation with our client. Fuck my life.4 -
A few days after deploying a big important Website into production, I wanted to copy the whole thing including DB back onto our test server for future testing/bug fixing if something comes up. (Last changes were done on production server before going live)
So I opened SSH, removed everything on the test sever aaaaand then I realized I was connected to production...
Took about an hour to get everything up and running again. We didn't tell the client and hoped it would not be noticed.2 -
[3:18 AM] Me: Heya team, I fixed X, tested it and pushed to production. Lemme know what you think when you wake up.
[6:30 AM] Me: Yo, I just checked X and everything is peachy. Let me know if it works on your end.
[9:14] Colleague A: Whoop! Yeah! Awesome!
[9:15] Boss: Nice.
[9:30] A: X doesn't work for me.
Me: OK, did you do M as I told you.
A: yes
Me: *checks logs and database, finds no trace of M*
Me: A, you sure you did M on production? Send me a sreenshot plz.
A: yeah, I'm sure it's on production.
Me: *opens sreenshot, gets slapped in the face by https://staging.app.xyz*
Me: A, that's staging, you need to test it on production.
A: right, OK.
[10:46] A: works, yeah! Awesome, whoop!
[10:47] Boss: Nice.
Me: Ok! A, thanks for testing...
Me: *... and wasting my time*.
[10:47:23] Boss: Yo, did you fix Y?
Courageous/snarky me: *Hey boss, see, I knew you'd ask this right after I fixed X knowing that I could not have done anything else while troubleshooting A's testing snafu since you said 'Nice' twice. So, yesterday, I cloned myself and put me to work in parallel on Y on order fulfill your unreasonable expectations come morning.*
Real me: No, that's planned for tomorrow. -
If you ever feel bad about letting non-functional code through to production, just remember that it even happens to companies like Google (My screenshot from a few months back)
 1
1 -
The One thing every Dev should know about:
Never Push to production on Friday.
Coworker pushed to production yesterday.
Customer saw it and likes the new features.
Customer also saw a shitpile of Bugs.
Customer is angry and my weekend is runined -
"Everybody has a testing environment. Some people are lucky enough to have a totally seperate environment to run production in."
-Unknown1 -
So how is your Friday?
Well let me tell ya, fixed a production issue and I'm totally exhausted and to top it off my girlfriend broke up with me.
I need a fucking drink!5 -
That paranoia when you deploy for production and you keep checking if it isn't down every 10 minutes.2
-
STOP. TESTING. IN. PRODUCTION.
STOP. TESTING. IN. PRODUCTION.
STOP. TESTING. IN. PRODUCTION.
STOP. TESTING. IN. PRODUCTION.17 -
Getting ready for production.
Search: console.log
Replace: //console.log
Search: ////console.log
Replace: //console.log
...
Aaaaaand we're good.8 -
Today is Friday. People are generally happy on Friday because it's the weekend.
I have a production upgrade tonight, which potentially can go through the weekend.
This is my second production upgrade support in a week. I'm sleep deprived and getting disinterested and seemingly in the want for a holiday.15 -
My worst devSin was testing in production once because I was too lazy to set up the dev environment locally.
Never will I do that mistake again!4 -
Today users weren't able to sign up on our website in production.
The guilty code :
int ttl = 5256005760;
The first who find why will have a candy.10 -
That moment that you get some kind of pretty critical error/bug/crash in an application in production and you can't reproduce it anymore and you're just sitting there praying that it won't happen again 😥4
-
Just got this notification. I see virgin active UK likes to test in production. I too like to live dangerously.
 1
1 -
I messed up carelessly in production. Learnt how SQL queries bite you in the ass when it knows you are under pressure.
Was hosting an online quiz kinda thing during my college techfest. Tens of thousands of people participating.
Using MySQL as database and thousands of queries were being executed. Everyone were pretty excited as the event just opened up.
None of the teams could solve one particular level. Turns out the solution was wrong and was asked by the organisers to change the solution for that particular level. Usual stuff, right?
Was too lazy to open up the web UI for the back office and so, straight ahead logged in to the MySQL server and ran the UPDATE query on the table consisting of the solutions.
It had been a couple of hours and the organisers came to me with a weird problem. There were no changes in the scoreboard for the last two hours. Everyone were stuck wherever they were. Weird, right?
I then realized.
Fk.
In that dreaded query, I had only run
UPDATE 'qa' SET answer = 'something'
leaving out the where clause, specifying the question to update, like
WHERE qno=13
As a result, solutions to all the questions were updated to the same answer. After hastily fixing everything back, I had the dreaded conversation.
Org: What was the problem?
Me: It was the cache.
Org: Damn thing. Always messes up.
Me: *sheepishly* yeah
Probably the most embarrassing moment in my life, wrt coding 😑4 -
A few days ago I had to replace one of the application modules on the production server ...
For about 20 minutes, over 200 banks (and a huge number of stores) in the country could not give loans to clients.
Applause!6 -
Somebody at Samsung is testing something in production 🤭
It's "Find my mobile" which is preinstalled by default on Samsung devices 8
8 -
That moment when you realise you just pushed a major bug whilst fixing another to the production website that launched earlier today.
Rolled back to working version, all within 30 seconds.
10 seconds later, client on phone... I just tried to load a page, why is my website broken?
They had to be loading it in that 30 seconds didn't they...?3 -
When you test your backend code thoroughly before pushing to production, but a fatal exception with the much larger production userbase causes one of your vital threads to die with a NullPointerException.
 6
6 -
Pressing that “deploy to production” button when it usually consists of multiple projects and databases updating at once.
Maybe I should look at separating them one year. -
Before production deployment: Everything is running well, all bugs are fixed, serenity sets in.
Production deployment day: Fire everywhere
goddamit we don't get a fucking break2 -
Adding a feature to webapp...
Webapp relies on database in production server...
*adds feature to production webapp directly*
Every page: ERROR 500
Manager: what did you do???!!!! You MESSED UP the production, FIX IT NOW
*Use ctrl-z because manager doesn't like Version Control*5 -
it was 12am when we are ready to launch our new web design which requires a lot of hardwork and routing processes. my team lead was the one who pushes the button to production using "cap production deploy" command. everyone in the room (including PM) was like counting down like launching a rocket to space. the feeling is great knowing that everyone was sleepy at that time. im glad it went smooth and everyone congratulates each other.3
-
I was finally moved to a production project after 2 months in my internship.
Almost had a heart attack after seeing the source code. Thousands of lines of code. So many files. So many things to understand.
I hope I don't lose my brain before getting a stress ball :(5 -
Oh man.
I imagine the face of the guy who deleted Gitlab production database when he realized what he had done.6 -
Fuuuuck this corporate bullshit. I'm basically sitting around twiddling my thumbs waiting for some jackass to grant me access to the server that my boss moved my code over to. Why the hell did you put my app on a production server that runs every 30 minutes...THAT I DON'T HAVE ACCESS TO?? Now there's a critical bug and a $50K order in limbo because I can't push any fixes. Fuck me. The worst part will be in the next hour or so when dozens of people are calling, emailing, and attacking my cubicle like rabid animals about why orders aren't moving and I'll have to explain that production is a train wreck because reasons. Just end me.2
-
There’s a bug in production, where a user account is vulnerable to simple bruteforcing 15 minutes after signing up. I’m the only one who knows. To fix or not to fix 🤔6
-
I used to work on a production management team, whose job was, among other things, safeguarding access to production. Dev teams would send us requests all the time to, "run a quick SQL script."
Invariably, the SQL would include, "SELECT * FROM db_config."
We would push the tickets back, and the devs would call us, enraged. I learned pretty quickly that they didn't have any real interest in dev, test, or staging environments, and just wanted to do everything in prod, and see if it works.
But they would give up their protests pretty fast when I offered to let them speak to a manager when they were upset I wouldn't run their SQL.2 -
When you forgot to remove this personal Toast in android code and publish the code to production
Next day around 100 people were confused what does this message means because it's written in English but not an English word.
BTW it means "It's closed" :) 4
4 -
So this just happened...don't test on production kids (....sometimes you have no choice BUT DON'T F**KING DO IT OK!?)
 6
6 -
Don't you just love it when something works in your development environment, your staging environment and then randomly breaks on production? :^)6
-
I'm currently removing hard-coded DB creds in our modules which is in production. I've thought, this format is the worst:
db_dsn = 'db_dsn_conn_1'
conn = pyodbc.connect('DSN=%s'%(db_dsn))
Behold!!
conn = pyodbc.connect('DSN=db_dsn_conn_1') -
Unknown notification error.
devRant unofficial
@JS96 @dfox
too bad... I'm sure @dfox didn't tested in production (joking... don't be too serious guys...) 4
4 -
Well it finally happened… I deleted the production DB 🤦🏼♂️
Rollback successful but lost over 3 hours of production data6 -
My co-worker, still studying but working as a "senior dev", just decided that we don't need a test/staging environment anymore. We just "validate" (we also don't use the word "test" anymore) newly created features in production.
Makes absolutely sense...
Thank god I have a new job from february on!1 -
Killed the backend production db of my app with a dev ops guy for 20 hours.
The emails I received were not the nicest of all time.1 -
The WTF moment when I realized that the main production DB server was configured with **dynamic** private IP. After maintenance upgrade and reboot the rest of environment stopped. When I explained to sys admin what caused the production breakdown hi still did not get that :/3
-
Borrowed from Reddit and Twitter:
Everybody has a testing environment. Some people are lucky enough enough to have a totally separate environment to run production in.3 -
I just auto charged myself because I forgot I tested my 7 day trial in production last week
🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡🤦♂️🤡3 -
So this week we had another team come to us and say they need to go into production...only issue...they have nothing...sorry that's wrong they have something...a vbs script to do their installation which doesn't work...

-
Do I want to continue?
Y -> vacation lost (Production server is down).
N -> Ok, I will gather more packages for you to update next time.
😭😭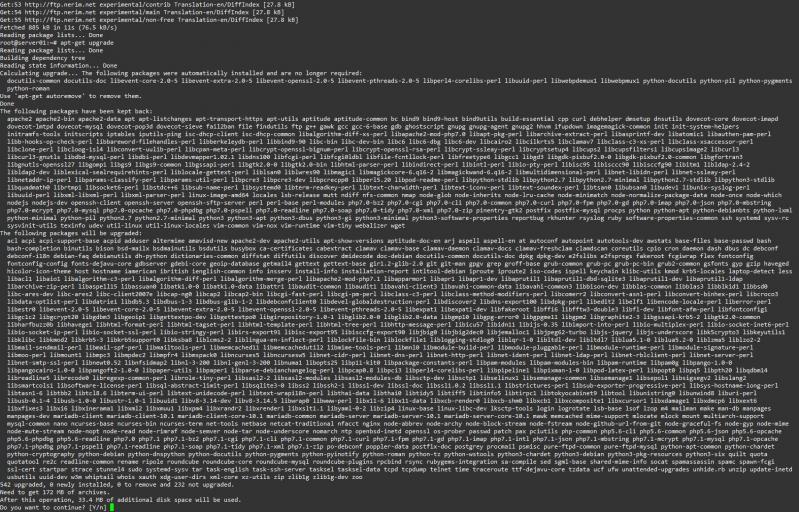 3
3 -
Forgot to change code in my api for rate limiting, after development. No unit tests.. because who really needs that right? 🤦♂️🙅♂️🤷♂️lolololol
Long story short, API went to production eventually, and stopped working almost immediately. Rate limiting was set for 2000 requests in a 1 hour time period. Not my finest moment.. fml 🤦♂️ -
>site is production ready
>client requests new feature by end of week
>add feature and then site breaks on last day of week
>client freaks out even though we warned this is what happens when you add new features DURING LAUNCH WEEK1 -
"This needs to go into production NOW"
Five hours later...
"That fix is on production now"
"Thanks, did you fix that other bug on production? We need it fixed now" -
// Delivery manager rant part #2
When one of your many stakeholders asks "why isn't feature X built yet?"
Response: have you seen the state of production lately???? Do you really think your item is top of our priority list right now?
-
I know politics is not allowed here, but I have to share this gem with you.
One day before the election for the European parliament the website of the German city Bochum showed a wrong bar diagram with false results of the election for a few seconds.
Everyone was loling. But I was like WTF? They were testing in production. And also they included data were the party AFD had about 50% of the votes. Are they retarded or so?4 -
Production: "Do you have [device]?"
Me: "Yes. I'm implementing the software that controls [device]."
Production: "Ok, that's the only [device] in the building, and I need to ship it to meet a deliverable."
Me: "... Does he want it to do anything?"
Production: "We'll build you another one."
Me: "When?"
Production: "... Eventually."
Software Development: The art of spinning straw into gold when you don't have any straw. -
That feeling when you're working with production data and you get a cold feeling running down your spine, telling yourself: you could really fuck up now.3
-
It's 1 AM and I've just finished deployment on production. I should go to sleep but what I do, yes scroll through devRant.6
-
BANE OF MY FUCKING EXISTENCE. STOP POLLUTING MY PRODUCTION CODE WITH TEST CODE, YOU FUCKING CRETINS.
-
someone: Who are you ?
me: Programmer
someone: What do programmers do ?
me: We push shitty hacks into production2 -
Me: *asks boss for the id of his test store so I can apply experimental schema changes to test out a new dashboard app*
Boss: *gives me production store id and doesn't say anything*
Fate: … "You got lucky this time."
This is the CEO of the company btw. Startups. *sigh*1 -
Hi guys! Im jr dev and i had a great week! My girlfriend letf my house :'( but my project it's working very well on production. It's not a prank!
#TrueStory7 -
Pushed to production with a debug message left in. Whoops, debug message includes the private key. Ummmm...2
-
When coworkers have a var dump on a page in production.-_-
I aint saying shit because everytime I mention something they do wrong I get assigned with fixing it. -_- -
Remember to always setup and test your production setup!
Seem like a local college forgot to do some QA 😂
-
Today marks the day that i finally get to do stuff on a production server.
Its just installing the elasticsearch cluster. But i still feel honored by the trust im given even tho im still an apprentice.6 -
Have you ever been interrupted because a marketing workmate had a friend on the phone who needed advice on a WordPress hosting, and wanted your advice right now?
Because I have.
When we had a massive server failure and our production environment was down.
Seriously, what the fuck is wrong with people nowadays.6 -
Lets fix this bug in production on a Friday afternoon. (did that three times on the same project). Never went wrong :)3
-
That moment when you realize that the iOS dev uploaded to ITunes Store an app pointing to the devel IP and not the production one Omg! (i'm an android dev)2
-
Imagine accidentally deleting the entire production database today and people thought you were joking.
-
Developing in your local environment? A few bugs here and there. Deploying it to production in a completely different environment? The whole app is a bug...3
-
Ever have a bug that *only* occurs in your production environment? How do you test potential fixes? 😜5
-
So we are preparing to deploy the changes onto production and some fucker decides to play with the fire alarm.
-
I have a first date tonight, but production is smoldering and about to catch fire, and it was my doing. I get 5 people coming to my desk every minute asking when's it gonna be fixed. my supervisors think I'm enjoying this because It's delaying a feature. I'm not. I feel like crying, and it shows.3
-
I want a Mac so bad but I’m a poor starving student so I can’t buy one but I’m so fucking sick of windows
I’m considering installing a Linux distro but I don’t think my music production software works on Linux??
Anyone using native instruments software (specifically maschine?) using Linux?9 -
Bad: Delete your production database
Good: Have a backup
Bad: Can't reimport it because your backup procedure uses scheme that are no longer supported for import by your cloud provider
Good: Backup are plaintext and somehow easy to parse
Bad: Spending the rest of the day writing scripts to reinsert everything.
End of the story: everything is up and running, 8hours of efforts1 -
I always hate that part of the project where you finish all the coding and start trying to deploy into production for the first time.6
-
*Finished the deploy*
*Dusts collar*
"Easy pesy"
Few hours later
*slack tone*
Production inaccessible! Blackbox crawler failed with message 5xx.
And that was the day little Charlie learnt dev-ops is not fun and thrilling. -
wk142: geekiest non-dev activity
Definitely music production. Especially when using real instruments and capture their audio, so everything is quantized (i.e. fixed to time grid) and very tightly recorded. I make metal, 'tis a precise genre. For one riff it sometimes take 20 takes, since I record 4 times my guitar.
I've learned for the past 10 years how to compose, mix, masterize, but also learned how to sing, learned how to play the guitar, learned how to compose drums and using my keyboard to play drums (people are often surprised I can play double kicks @ 230 bpm) so that I can have a basic drum layer to further edit
Pretty geeky, not a common subject I talk to people about :D2 -
When you catch developers rolling out untested changes to production that have a huge impact on your clients workflow... And they don't tell anyone so you find out because your clients are yelling on the phone about some change affecting their work flow.

-
When you decide it's not worth of your time to go through lengthy code documentation and just run that stackoverflow snippet straight on production.. 🤠

-
So glad to be staying a new job next week. Today a junior colleague asked me what the best way to test something would be as it won't work locally. Knowing this has a good chance of taking down the server, I suggest he sounds up a server on his AWS account. My manager comes in, oh no I don't want him doing it on AWS use the production server instead. By the time stuff States hitting the fan I will be gone.1
-
So it's Friday afternoon just before a bank holiday weekend here I'm the UK, perfect time for our production database to go TITSUP (total inability to support usual performance), life sucks then you die folks....2
-
Thursday afternoon. Client gives us the go to deploy the latest release to production.
Friday late afternoon; my colleague - "wait, did we ever deploy"? Me - "uh, nope".
"Alright have a good weekend" -
When your company expects you to manually change information in the production db by saying "hey, client Billy wants his stuff moved back to where it was"3
-
I'm doomed.
My first production worker script is making multiple active attribute of a user. My script should be able to deactive the old attributes if there is new one.
Months ago, this issue occured. My teammate from team A take over the script to investigate since I am busy working with team B.
Yesterday, I found out that I, myself, overwrite the fix my teammate made for that because of a new feature.
I have to clean up the affected records on production on Monday..and i have to explain to my manager. T.T
LPT: ALWAYS PULL REPO before developing new feature... -
I deployed to production in the middle of a zoom meeting with a client.
It was just a tiny change in the settings of a field that I 99% sure wouldn't produce any other major problem but we really wanted this client and we distracted them while the code was building.
Nerves racin all the way1 -
Works in production?
Yes: Copy changes to dev and test.
No: Start humming and walk away from the computer. -
Free advise to to all the goal keepers at the Russia world cup2018; don't commit too soon!, remember, you're in production...
-
Supporting a production upgrade on a Friday night without extra allowances because I screwed up the one on Tuesday night! Yay!6
-
I left on vacation only to realize I pushed an old build to production. It now throws NPEs.
I don't have a computer, just my phone.
I'm regretting not going to bed earlier yesterday.1 -
Since I have seen a lot of people uploading this kind of stuff lately, here is Xiaomi's test in production, back in 2017 November...
 1
1 -
Never! Deploy! To production! On Thursday! *banging my head against the wall*
Now I need to revert some things manually on production ON MY DAY OFF 🤦♂️🤦♂️7 -
When you find this in production code and git blames you for this. Luckily no one can every see this log output, because the next statement closes the frame.

-
I just had the most embarrassing moment in programming... I am writing an administration / client / invoice webapp and I was testing an export function that worked locally, because everything that was being exported was inside the folder.
So I exported the files in test production, but some invoices didn't exist. So when they don't exist, the system creates a new invoice.
Because I was running on the test production (with client data) the system emailed the created invoices to the clients.. now I have to contact some clients and tell them the invoices were sent accidentally.2 -
What is more disaster
Than manager thinking to assign a production deployment to non technical person.1 -
So, we are having a SaaS service for people where they can build X stuff. It is all fine as long as you are using basic things there, no complex cases and so on. Even on some complex - it does work just fine.
Here's the rant itself:
The production server throws us errors every 5-10 minutes that something broke and fails to do job X. At first we were all hands on deck fixing it ASAP to make it stable to later realise that most of these cases were users doing stupid shit. Then we began to fix the core issues rather than chasing every single issue there is (costs are important you know) - funny enough, we get few support requests a week and our 1h response time + 24h fix time usually buys us that customer and allows t o leave a great impression.
So all in all, bugles production is good but great support - is way better. Users can deal with issues especially if they are experimenting there but when they need answers - you'd better give it to them.1 -
On this Saturday my first full project is going to production and I am unable to resolve one fucking critical bug without db hit. Well still trying..3
-
Did you ever had to integrate a fucking "API" that is done via mail bodies?
Fuck this shit! Who need responses about success or failure?! Guess this will take a long time to test this fucking piece of garbage... We don't get a test system, we need to test this with the production system of the other company. I hope their retarded application crashes when receiving malicious mails.
Not speaking about security, I bet everyone can send a mail to their stupid mail address and modify their data 🙈
And inside of this crap mail you also have to send the name, street and email of their company. Why do you fucking need this information?!1 -
Fuck I forgot to make a database export before I executed delete statements on a production database...
All went fine though. Nothing broke.5 -
TGIF & remember..
DO NO FUCKING PUSH TO PRODUCTION TODAY!
DO NOT FUCKING RELEASE A NEW VERSION OF THE CLIENT APP!
FUCK!!
have a nice weekend partners 🤗1 -
As you grow older, both professinally as a dev and as a team player, you realise that a complete rewrite is rarely the better answer to the problem at hand.
With that being said, I'm rewriting the glorified-mass-of-infernal-human-feces-with-corn-bits-masquerading-as-mere-shit out of a production service right now. Wish me luck.2 -
Ok so some of you have probably seen my previous rants about my computer science teacher and our project but I'm just going to summarize all of them and share with you more of my pain.
1. He edits in the production environment. Its a laravel project and he is creating test database migrations IN THE PRODUCTION ENVIRONMENT AND SWITCHING BACK AND FORTH FROM MASTER AND DEV.
2. He edits in vim and doesn't follow codestyle even though I printed him off a piece of paper and emailed it to him.
3. He doesn't have any ethic when it comes to more complex things like laravel homestead.
4. He doesnt want me to release features even though he takes really long to do them.
While I love vim and it is my editor of choice, some things should be done in an ide. This is really annoying me and I'm really just considering handing him the project if he can't follow basic outline.3 -
Debugging a task, that's sending emails to too many customers.
Supervisor: "Never mind, just test in production, there is a dry run flag for the tasks."
Just in case I test locally...
Flags tried:
--dryrun="TRUE" => Error, failed to send mail.
--dryrun=TRUE => Error, failed to send mail.
--dryrun="true" => Not trying to send mail.
If it's THIS PICKY a little more documentation would be nice.
And by a little more I mean: more than the task base class in a giant php monstrosity without phpdocs expecting its code to be self-documenting. -
I just basically performed emergency surgery on production while in a cab on my way to a class where I'll be unreachable for an hour and brought it back to life in the nick of time. I've never felt more alive.
-
How do you guys push changes to you server. ?
I am currently pushing changes to my git repo then pulling those changes on server where I am running the application in production.
I am planning to set up a simple server, to which I will push the changes and it push the changes to the server's running in production.
Or better would be to write a script and run on production servers that will check github for changes3 -
A developer couldn't get a application performance monitoring (APM) tool to trace his application. They claimed that their libraries and their configurations were alright and that the APM tool was non-performant.
The developer then argues with sysadmin that the APM tool can't trace the application and that there's nothing wrong with the application or the configurations. When sysadmin questions whether the developer got the tool to work anywhere, they say, "No" and head off to make it work at least in one place. They come back saying that it works on their development environment (which is their local machine). Sysadmin claims that the system configurations on the server instances cannot be matched by the development environment and there could be a lot more factors to be considered for the problem. The sysadmin asks to prove it on a server instance on one of the test environments and then they'd agree that it is a problem with the tool. They also argue that this is not the only application that uses the APM tool and the tool happily traces other applications with no issues.
The developer tries the same configuration on a staging instance and fails. In order to make it work, they silently uninstall the existing version of the APM tool and then compiles an unstable branch of the tool. It finally works with this version.
They go back to the sysadmin and show that it works on the staging environment, but does not on production. After banging their head on the wall for a while, the sysadmin figure that the tool had been swapped out for the unstable branch that was manually compiled. When questioned, the developer responds, "It works with this version on staging, so deploy the same version on production"
WTF? You don't deploy an unstable branch to production. Just because you can't make it work on the stable branch doesn't mean that it is the problem with the tool itself. There's a big difference between a stable branch and a non-stable branch. How would you feel if the sysadmin retorted by asking you to deploy the staging branch of your application to production? -
Quickly delete a double record in the production database with a script, just forgot the where statement...2
-
Production goes down because there's a memory leak due to scale.
When you say it in one sentence, it sounds too easy. Being developers we know how it all goes. It starts with an alert ping, then one server instance goes down, then the next. First you start debugging from your code, then the application servers, then the web servers and by that time, you're already on the tips of your toes. Then you realize that the application and application servers have been gradually losing memory over a period of time. If the application is one that don't get re-deployed ever so often, the complexity grows faster. No anomaly / change detection monitor can detect a gradual decrease of memory over a period of months.2 -
beware of font choices in chat apps; a coworker joked in the room that "well, sure, of course it's okay to update in production in the middle of the day" and for some reason, the other coworker didn't see the quotes because of the weird font they use, and also didn't stop to think, and went ahead and ran the deployment script. In production. In the middle of the day. With active users.
The good news is that those folks who logged back in got to use the new version a whole lot earlier than anyone was expecting. :\2 -
Just pushed to production an untested feature implemented using code from StackOverflow.
Let's see how this goes1 -
That feature that needed to be taken live asap. Who's priority was set the highest. For which i had to stop the code i was developing, to work on that.
Post going to production, one month's passed and the feature still awaits there in its lonely world to be used by someone, anyone.
Please use it.1 -
Me: So we're deploying this today on prod.
Junior: Can you record the deployment steps for us so that we can deploy whenever you're unavailable?
Me: Seriously?
I liked their enthusiasm though.
Maybe it's just too early as these chaps don't even know the basic commands right now.
What y'all have on this?10 -
Had been trying to get the latest build rolled out for the past 3 days. Every morning, I wake up around 6am, drink a nice cup of coffee, while listening to Ariana Grande (I don't know why, but for some reason, she randomly started coming on my playlist a lot) and start rolling out, and sure enough new errors start spiking, ultimately rollback.
Conclusion: don't listen to Ariana Grande when rolling out to production! 🤔 -
do you do any rituals to make it psychologically easier to deploy your code into production / replace an existing working system?3
-
So, today we had our first production release of our web app. Last week we changed a big part of our UI. This week we changed the design, rewrote the complete API documentation, implemented mobile support. While the release the administration center of our cloud was unreachable. Shortly after the release we made a bug fix and deployed it directly to production.
So today was a very normal prod release 😂1 -
How is it, that features goes thru the entire mill of dev, staging, preview.
Then when deployed to production, things blow up..
Turns out, columns are nullable only in production DB and of course, those happen to be null in there.
If I had a dime for every time I’ve seen shit like this…
(╯°□°)╯︵ ┻━┻5 -
My boss that push the code on production without versioning it.
I deleted all the changes, and the fault was mine, of course.1 -
I am currently in the works of designing, building and extending an CRM/MRP system for production lines.
But for some reason I cant seem to find ANY modern sources, papers, books, forums, threads for context on this topic. It’s as if this topic doesn’t exist.
(One thing to point out is that there are sources for business wise analytics but am looking design wise)
I am starting to think that i am not googling it correctly (what a boomer).
Do you have any magic sources, captains of devrant?10 -
Working on production issue,
Kind of nervous checking logs and so on...
Ops manager and PO who were looking over my shoulder this whole time start shooting the breeze.
I know what they were trying to do. They are trying to create a relaxed environment.
But the issue is that the talk is very distracting. If you want to shoot the breeze please go somewhere else.
Anyway just did that, asked them to leave. They weren't happy about it. But I really needed the silence. -
Ops teams that are "assuring" stability of production by being the only ones who can click to deploy to Prod add no value.1
-
Sometimes, certain features don't work in my app if it's uploaded to the production track in Google Play.
It works in debug mode.
It works in release mode.
It works in the internal testing track.
...but it won't work in the production track? Y'know, the one that actually matters? Theoretically, there shouldn't really be a difference if the same exact APK was uploaded to the internal testing and production track, but... idk dude.
As a result, I implemented a secret way to test a feature in the production build (it's an app to remotely control OBS Studio): if the first connection you added is named "yayeet_" and you open the disclaimer, it tests the feature. Luckily, I got some of the stuff figured out, but I just thought the way I had to test it in production was dumb.1 -
Pushing a project in production without as much problems as expected is a very, very good feeling.
Have a great Friday, fellow developers.1 -
Since this has been trending recently, here's my six word horror story -
"I accidentally deleted the production database"2 -
Stupidly tested some sql on development to return results for an admin (see the whole results) and stupidly didn't test the where clause for generic users (only see a subset of data)
To find out on production the where clause was being run because it wasn't a where, it was an 'and' and 'where' was not being used before so made the whole users get the entire results.
My own fault for not testing all use cases. Horrible though.2 -
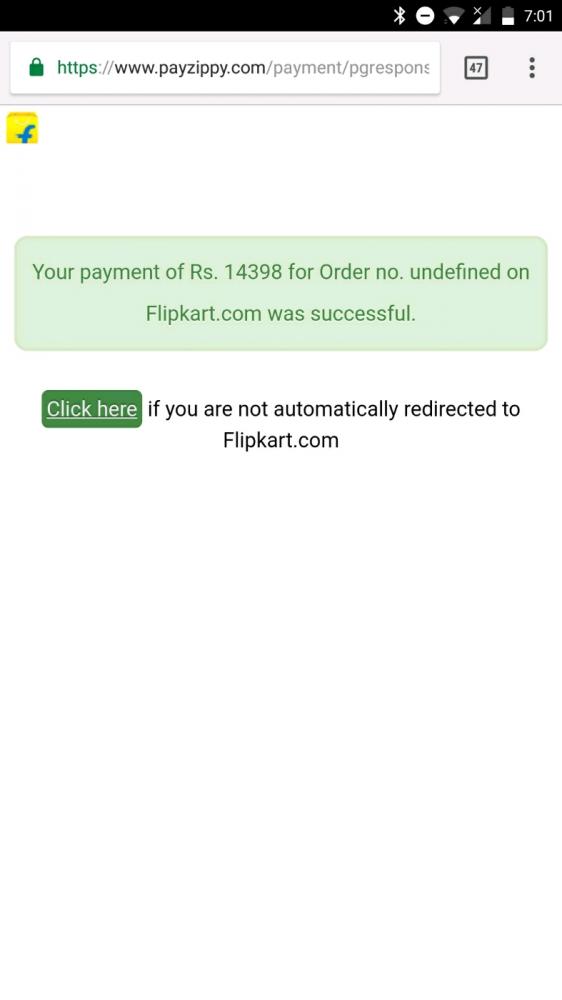
Not sure how this made it to production..
Looks like Time Warner Cable updated their site to use rems with a replace all on 'px'.
https://registration.timewarnercable.com/... . -
Just found out our pre-production environment is the qa for another team.
Infra team has recommended to ignore the nomenclature. It's just a name they said. -
After solving that production issue which people debugged the entire night.. feels like..
I am the eggman
I am the walrus
Teams like..
Goo goo goo job.. 1
1 -
Do any of you wonderful devRanters know of good links that cover the topic of best practises when deploying a React/Redux (or any modern web app) to production?
I’m pretty sure I have found all the boxes to check through personal experience but maybe there are tips out there I am unaware of.
🍻 -
Currently debugging a project that was written over 4 years ago...
At first all was well in the world, besides the ever present issue off our goddamn legacy framework. This framework was written 7 years ago on top of an existing open source one, because the existing one was 'lacking some features' & 'did not feel right'.
Now those might be perfectly fine reasons to write a layer on top of a framework, but please, for all future devs sanities, write fucking documentation and maintain it if you're going to use said framework in all major projects!!
Anyhow back to the situation at hand, I'm getting familiar with the project, sighing at the use of our stupid legacy framework, attempting to recreate the reported bugs...
Turns out I can't, well I get other bugs & errors, but not the reported ones. I go to the production server, where I suddenly do can reproduce them...
Already thinking, fuck my life, and scared for the results... I try a 'git status' on the production server....
And yep, there it is, lo and behold, fucking changes on production, that are not in git, fuck you previous dev who worked on this and your stupid lazy ass modifcations on production!
Bleh, already feeling royally pissed, there's only 1 thing I can do, push changes back to git in a seperate branch, and pray I can merge them back in master on my dev environment without to much issues...
Only I first have to get our sysadmi. to allow pushing from a production server back to our git server...
Sigh, going to put on my headphones, retreat to my me space and try to sort out this shitpile now... -
Boss: this can't ever be the production version of the server
Emp: actually, it can be
Boss: that's what I mean, this will literally be the production version -
Who else is frustrated/burnout at building products that never gets into production?
When I work for a company I always tend to do everything with good practices, spend a lot of time thinking on the best ways to build x feature, and then the company falls into the infinite loop of adding stupid features, and then I've been working for 2 years and 0 paid customers. Funny that we've Sentry, GA, Hotjar sitting there doing nothing.
I'm honestly hating the startup environment rn. Good thing is that I've learnt a lot and salary is good. But also I lost all motivation.
Any recommendations for a tired dev?7 -
Just discovered that my webpack bundle beeing modified manually (via notepad) by Devops when Deployed to production :/1
-
As part of a technical test, I've been asked to test and report bugs in the production application of the company. Is that normal? Or are they making me do free work for them?.
So far I've only seen challenges like this to be done on a custom application for test.7 -
My first production support release is next week and its from midnight till 5am and be at work at 8:00am. If something goes wrong with any of the other developers from our team goes wrong I have to figure it out. And this image is exactly how I picture it goes, if any tickets fail. (🤘🏽 bring it on! )

-
In the beginning I created a CLI script to manage some production tests of our embedded product. Then they wanted a GUI with a single textbox and button. Then they wanted a shortcut on the desktop to that GUI.
Now one guy I know in 'production' insists that I keep adding to the documentation for things outside the scope of the software and more towards what will be sent to other production workers. Some of which includes 'ensure the cables are plugged in'. He says that he and other production workers are dumb and need a bulletproof guide. Fair enough, I say...maybe get a brain also?1 -
I've been using Docker for almost two years now, I've to say it's a super powerful tool and allow easy environments deploys, but I keep questioning why people use Docker in production? Even in the place I work they do and they can't explain it very well
I mean, you are creating a container that hosts services in a computer that already have services running, being one of these services the Docker daemon, all this shit doesn't add a lot of overhead to the application?
I mean, it's not better to just install python in Ubuntu instead installing Docker in Ubuntu, run the Docker daemon, start a container with other services and now I run python?
Just saying6 -
The biggest mistake my colleague done is -
update query for admin_reports table without where clause in mysql in production db. Right after that no admin reports. More than 1000 rows affected.
Glad we luckily we have some data in staging machine.. I don't know Why TF our devops team not taking backup. Hope they will from now.
Nom I'm using python to dump the data from staging and save it local file and then export to production.
#HisLifeSucks
#HeartBeatsFast -
I once executed a rm -rf * on a production server. What was your most fckd up or fireable instance at job?1
-
Have you deployed ElasticSearch to production? If so, I got couple of questions for you.
How much complexity did ES add to the project overall from a developers perspective?
How much did this differ in price from other solutions you used? In production loads that is.
✌🏼7 -
So after the CIO pretty much does a table flip to the division about causing near daily customer impact we now have seven business day cool period for Changes and 13 cross functional teams stood up with 1, 15, 30, 60, and 90 day deliverables to an executive audience.
Guess what my team did today?
Offline a major Production database during the middle of the day, thinking they were in Development. Didn’t notice for 40 minutes. -
Doing production release on Wednesday is kind of pointless. Someone is going to override the world a day after due to Last Thrusdayism - https://letmegooglethat.com//...1
-
I'm a junior, now getting used to the idea of having to finish something in the same day if it's urgent for production and therefore having to clock in extra hours.
It's depressing, in a way.. I'm hoping to avoid this as much as I can and just get work done within the usual 7.5 hours.2 -
So this is really a thing. I'm used to have yarn build/dist/watch and serve commands but my collage is used to laravel mix, and we working with static URLs like client.local. I'm used to localhost:xxxx which is better because you can use hmr. So what do you guys name your development build command and the one for production?? convention
-
We've got a non minified jQuery in production for months now. Not only do people throw it at every little problem, but some of them don't even use the minified version... 😑
-
Handling null like null is to be handled in production. And in current times null is good news (The app is of one of the most important german newspapers)

-
From the guy that practices bash in the production server, here's the same guy who also practices SQL queries in the production's PostgreSQL!
I swear these happen by accident. I'm having to do some data corruption control by some bug, but I forget to close the panel when I'm finished. Then I go on with my tasks and I think it's my own computer I'm writing these commands to.3 -
I have a headache and I have to write a fix in production in less than 2 hours. What can I do? does chocolate help? I will get chocolate2
-
Anyone know how to use a proxy for a web crawler written in native Java for Android. I have a bug in an app in production that only surfaced after being used for a couple of days and I urgently need to fix it.
HELP!!! -
A young new dev was working on his first ticket, about a bug during parsing of an uploaded excel file. Our issue was that if the file contained an empty line, all remaining rows were ignored. So the task included extending our tests to cover this case. After 2 weeks (!), his merge request comes in. His idea (without ever asking for help) was to parse the whole file (in some cases huge) in the production code a second time, just to count the rows (!!) and save the count in a public static int field, which was verified in his new test.2
-
Struggling to optimize and to scale the infrastructure of our production environement dealing with people who don't bother themselves to write scalable code.
-
Today (Thursday) I have an interview and exam today, but won't be able to attend because somebody broke the production code and we need to fix THOSE Bugs ASAP.
-
Egoboo: Your Premier Audio Studio and Post Production Studio in Dublin, Ireland
Located at Basement, 22 Fitzwilliam Street Upper, Dublin, D02 X6W8, Ireland, Egoboo is a top-tier audio studio and audio post production facility offering comprehensive services for all your audio needs. Whether you’re looking for high-quality audio post production in Dublin or professional sound engineering, Egoboo is your trusted partner for delivering impeccable audio results.
Why Choose Egoboo as Your Audio Studio and Post Production Partner?
At Egoboo, we provide a seamless, professional experience for all types of audio post production. Our team is equipped with the latest technology and has years of experience in delivering outstanding audio services. Here's why Egoboo stands out as your go-to audio post production studio Dublin:
State-of-the-Art Audio Studio in Dublin
Our audio studio in Dublin is designed with the latest in audio technology to provide superior sound quality. Whether you’re working on a film, commercial, podcast, or video game, we ensure your project sounds flawless.
Advanced Audio Equipment: We use top-tier microphones, mixing boards, and soundproofing techniques to capture every detail with precision and clarity. From the initial recording to the final mix, our studio is designed to deliver optimal results.
Skilled Engineers: Our experienced sound engineers have a deep understanding of both the creative and technical aspects of audio. They work with you throughout the entire process, ensuring your vision comes to life with a perfect sound.
Tailored to Your Needs: Our audio studio is flexible and adaptable, catering to various types of audio projects, from voiceovers to music production and everything in between.
Expert Audio Post Production Services in Dublin
At Egoboo, we specialize in audio post production that enhances the sound quality and ensures your project is production-ready. Our audio post production studio offers a range of services designed to fine-tune every aspect of your sound:
Sound Editing and Cleaning: Our engineers meticulously edit audio tracks to remove unwanted noise, clicks, and pops, ensuring a clean, professional recording. Whether it’s for a podcast or a film, we’ll make sure your audio is pristine.
Sound Design and Effects: We bring your audio to life with custom sound effects and designs that enhance the storytelling process. Whether you're creating a film, video game, or commercial, our audio post production studio can provide the creative edge that brings your project to life.
Mixing and Mastering: Our mixing and mastering services ensure your audio is balanced and polished. We adjust sound levels, balance dialogue, and create a cohesive sound experience, so your project sounds seamless and engaging, whether it's for broadcast, streaming, or cinema.
Foley and ADR: We provide specialized services such as Foley (the reproduction of everyday sound effects) and ADR (Automated Dialogue Replacement), ensuring that your audio matches the visual elements perfectly. This is crucial for film, TV, and video game production.
Comprehensive Audio Post Production Studio Services
Whether you're working on a commercial, TV show, film, podcast, or any other project that requires expert sound engineering, Egoboo offers the full range of audio post production services to make sure your audio is perfect.
Film and TV Audio Post Production: We work closely with film and television producers to ensure that every sound – from dialogue to ambient noise – complements the visual storytelling. Our audio post production services help to create an immersive sound experience for viewers.
Commercial Audio Post Production: For advertisers, we provide expert audio post production services for radio and TV commercials. Our team ensures your ad has the right sound mix and message delivery to grab attention and engage your audience.
Podcast Production: As podcasting continues to grow in popularity, Egoboo offers professional services for editing, mixing, and mastering your podcast episodes. We’ll help you sound professional, clear, and engaging.
Video Games and Animation: Our audio team brings video game soundtracks, character voices, and sound effects to life. Whether you’re working on an indie game or a major production, we ensure your sound design is top-notch. 1
1



















































































































































































































































































































Top Tags
Weekly Rant
View