
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
TODOs top 5
[x] create README.md with TODOs
[ ] add tests
[ ] write documentation
[ ] automate deployment
[ ] improve security5 -
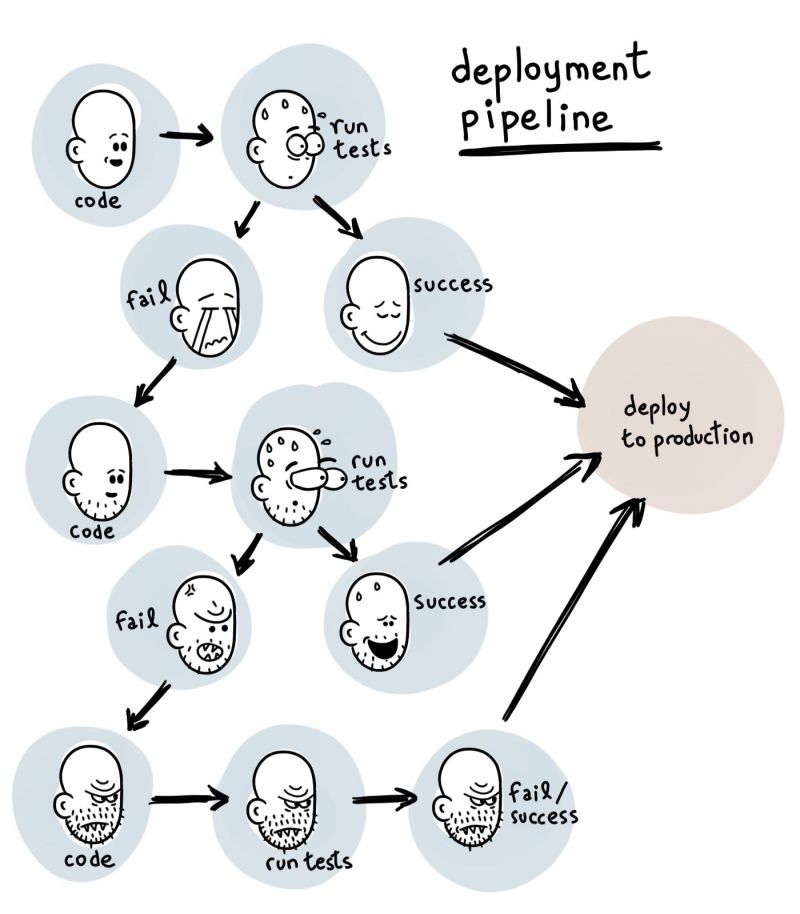
So i heard that docker is now a thing and decided to put my servers into containers as well (see image)...but somehow I still don't understand how is this supposed to simplify deployment, vertical scaling and so on...? :D
 6
6 -
Morning Deployment.
Me: Let's add this application to this server.
Deployer: Alright.
...
D: Done. Please verify.
Me: I'm seeing errors. Send me the logs.
D: Sure. I also updated the framework to a version that wasn't tested.
M: Yeah, that won't work. Roll it back.
D: Fine.
...
D: Done. Please verify.
M: All the applications on the box are broken. Please revert to the snapshot before the Deployment.
D: Oops, I didn't make one.
🙁😟😢😭😤1 -
MOTHER FUCKER IDIOTS!!!
SO I HAVE TO ROLLBACK OUR PROD DEPLOYMENT BECAUSE IM THE ONLY FUCKER WHO UNDERSTANDS THE SIMPLE CONCEPT OF "DONT PUSH UNFINISHED CHANGES"?!?
DAMN!!!! FUCK YOU ALL...10 -
FUCK THE WORDPRESS ECOSYSTEM AND FUCK THE FUCKING ONE CLICK DEPLOYMENT LIES OH YES WITH WITH BITNAMI OFFERS YOU SHIT AND FUCK YOU FUCKK YOUUUU SERIOUSLY FUCK YOU MADE ME AN ANGRY AND SICK FUCK.6
-
PM (on slack): "we’re about to deploy to production".
Me: "ok"
… I keep on working on a task / remain available for any post deployment issues …
PM (5 minutes later on slack): "deployment broke production! We need to handle this NOW!"
My dev colleague has already called it a day, but I’m still online
Me: "ok I don’t have access to prod, can you describe what’s going on? I can’t reproduce on any other environment"
PM: …
10 minutes go by
Me: "anybody there?"
PM: …
45 minutes later, I realize PM is offline
The following day:
PM: "ok we got prod running again" (turns out it was client’s fault for not updating a config we as devs can’t access)
PM: "but we’re REALLY UPSET! You guys need to be available to intervene for any issues following deployment to production! At least one of you should be available!"
Me: "but, but…" 🫠14 -
#!/bin/sh
# Application X deployment script
## some code ##
function sudo_remove {
directory=$1
filename=$2
sudo /bin/rm -rf $directry/$filename
}
### some more code using function above ##
>400 servers completely corrupted. Twice in one week.
Who can spot it? :)9 -
Spending my 23rd birthday in a server room 700 km away from home, discussing the requirements for app deployment. Yep. Every dev's dream.15
-
M - "Hey... 👀 where's the boss?"
P - "He's gone to get lunch 🍱"
M - "😮 WE'RE IN THE MIDDLE OF A DEPLOYMENT!"
🙃🙃🙃🙃🙃5 -
That moment when you make a bug fix on your local dev deployment and keep refreshing PROD web page hoping to reflect the change.1
-
I knew this guy was pure evil.
Deployment on friday night !
And that too before Christmas.
Thank god Santa doesnt use Tesla 5
5 -
Rs 500 and 1000 notes are banned in India in order to curb black money.
Bankers will now get to know what is 1 day development and deployment along with support from the next day.
#ITprofessionals.😂😂 -
"Server deployment is automated from git, so dont merge things into the master branch without permission"
Oh ok
>i create new branch
>push unfinished code because i gotta hurry
>server breaks
Well golly gee seems like you did a shit job at automating7 -
4 o'clock on a Friday and daughters birthday party tonight...
Not this time deployment... you're gonna have to wait until Monday.2 -
Product name: K.I.D.
Product version: v2
Project duration: 9 months
Deployment to LIFE ETA: within next 24 hours
Tests' status: GREEN
uuhhhh soooo exciting! Hopefully this time deployment tools do not fail, like they did when releasing v1. Thanks God it still ended well.7 -
Yay, it's Monday!
And as Monday's go, there's a prod deployment, cool beans! 30 min later it's done!
So why the rant?
Because I'm on FUCKING ANNUAL LEAVE YOU BITCHES!!!!!
Fuck it, it's done, I'm going back to bed.1 -
Rant: THAT FUCKING CREATIVE AGENCY, THAT USES A FUCKING HOSTING PROVIDER, THAT DOESN'T OFFER SSH! GUESS WHO'S CURRENTLY UPLOADING 4000 FILES? BEST OF ALL EVERY 200-ISCH FILES THE CONNECTION GET'S REFUSED, TELLING, THERE ARE TO MANY REQUESTS (FileZilla is set to max 2 simultanious uploads, still the same)
FUCK YOU, YOU FUCKING FUCK OF A CRAPPY DEPLOYMENT PROCESS.6 -
today I experienced real-time bug fixing and deployment..
The phone was attached to the debugger, the client is using the app, me catching the logs.
Client: oh here is wrong behavior.
Me: *tapping on keyboard, then* ok try now please..
😅2 -
Before production deployment: Everything is running well, all bugs are fixed, serenity sets in.
Production deployment day: Fire everywhere
goddamit we don't get a fucking break2 -
Alright boys, let me tell you how someone fucked up so hard they got their deployment schedule delayed "indefinitely".
Being security, we get to oversee most deployments, and we especially get to oversee all deployments that are on IT-managed tech. Knowing fullwell about this fact, some dumb motherfuckers woke up and thought to themselves "You know what would be good fun? To piss on security's asshole and then try and ream them up the backside before they notice the piss!"
Well let me tell you, we noticed. And our boss noticed. And his boss noticed. And the CIO noticed. Thus it came down the chain that this particular group of lie-spurting, baseless accusation-leveling group of developers would have their deployments put on hold. How long? "A while."
I have never quite heard my higher-ups this mad before, but damn if i dont share in their enthusiasm to stick it to entitled cunts.15 -
We do quantum development at work. Hence no testing nobody knows if the application is working after the deployment. 😶3
-
brace yourselves!!! we are deploying this weekend... (expect more rants to follow as the deployment continues (or fucks up) )3
-
Quick reminder: don't deploy to production on you last working day before holidays :)
Wish you all happy new year)
GG!5 -
Lack of documentation on internal deployment process/tool we are forced to use, but can't migrate because the process owner won't approve it because it doesn't meet their unposted ever changing guidelines.

-
So we are deploying our hip new react-native app on the playstore and all is fine and happy, being in the playstore gives you a warm fuzzy feeling that your app finally has been set out in the world....
Then comes the iOS store... you monster, you have let your app into a minefield, there is no warm caring environment, there are only white sterile walls around him and at the slightest misstep your app gets marked and send to a correctional facility, tortured and interrogated until it falls in line..waiting for the next misstep hoping the overseers will not notice his untied shoelaces....2 -
[First rant] When you commit the wrong code to the deployment branch.
This happened to me yesterday 😅 Reverted it but everyone knows what I did by seeing the commit history 5
5 -
You lousy fucking test class of an ass wipe,
TLDR; it fails and it passes all at the same time.
So during a deployment, one of the pre-deployment test classes fails, not something anyone has worked on so figured I run it manually to see what’s going on, but no the shit of a thing passed second time around.
Now because we can’t deploy without 100% of the test classes passing so I have to organise another deployment which it fails again. Fuck this,
Unprotects master
Git checkout master
Git merge dev
Git push master -f
Protects master
Skrew this!
Well would you look at that, it works now 😰 -
I'm preparing a major deployment & what do I see?
SOMEONE MANUALLY EDITED PROD AGAIN
IMO they deserve to be hit on their hands with a stick every time they even think of fucking with it.10 -
1. IDE connected to your brain that does the coding according to your thoughts.
2. Compiling and deployment for your applications take little to no time.
3. Not having to wipe your ass 50 times to make sure it's all clean.3 -
Customer: We wanna add this thing to that feature. It has to go live with the next deployment (1 1/2 weeks to go)
Me estimating developmenttime, and informing the Management
management: this will take approx. 12h to implement, but we need these informations: [long list of not answered questions]
1 week later (1/2 week left till deployment
customer: okay, lets do it
management: we dont have much time left, what about the questions i sent you?
1 Day no response, 1 1/2 days left until deployment
customer: here you have a few answers. couldnt get the others. ill Send them tomorrow
damn... wtf? guys! i need this shit to Stay in time! cant wait another day! hell no! -
My matryoshka keeping me company, because of course when you are alone testing a last hour deployment. shit will happen
 5
5 -
After many teeth clenching failed deployment to production attempts and finally realizing I forgot didn't add ssh keys

-
In horror movies. Characters do things that they them-self know it could kill them. Like getting in basement.
As a developer we all know to never deploy code on Friday. Here we are taking the wrong turn.2 -
Yesterday: Deloyment will be delayed untill further notice.
Today: we have 20 minutes to ready everything for deployment.
Wonderful1 -
It's 1 AM and I've just finished deployment on production. I should go to sleep but what I do, yes scroll through devRant.6
-
Don't you just love it when you're in the middle of an agreed content freeze and a marketing drone demands an immediate content deployment to production because they made a blog post and it's "super urgent" that it goes live right now.
-
When testing and deployment are not two different things for the computer centre department of my college(This is the website to authenticate college students to let them use the internet)
 5
5 -
Craft CMS deployment on shared server, PHP5, Apache takes 10 - 30 seconds to load.
Craft CMS deployment on virtual shared server, PHP7, Nginx takes 1 - 2 seconds to load. 1
1 -
I'm so sick of microservice architecture... in theory it was going to make scaling elastic and deployment easier. In reality it seems to slow productivity to a 🐌 pace.
Anyone have any brilliant suggestions on how to herd these cats in production?10 -
Taking a 4 month Software Engineering course in University. Spent the last 2 months making Traceability Matrix, Component Diagrams, Deployment Diagrams, Sequence Diagram and not a single line of code was written.
Is this how it works in Industry as well? Lol.12 -
Editing java files on server for deployment.
Deployed. Found major issue.
Don't have time. Editing source code on server changed if else
Rebuild and deploy.
Now push from server to repo and pull locally...
Pure sin. -
Not quite a rant, but it'll devolve in heated debate anyway 😂.
So I was discussing deployment methods with a client's CTO today.
He was fervent on using git for deployment (as in, checkout/pull directly on target host).
I was leaning more on, build npm and web bullshit on the runner, rsync to target host.
Ideally, build shit in the runner, publish to an artifact/package manager, pull that in the target host.
Of course, there are many variables and pros/cons on each side, but would like to hear your opinion.13 -
Developing in your local environment? A few bugs here and there. Deploying it to production in a completely different environment? The whole app is a bug...3
-
Deploying on stage.
Testing on stage.
Why does the issue persist on stage?
Testing on local. It is fixed!
Wtf?
Wtf!?
WTF???
Oh.
I did not merge my branch and deployed a new version on stage without any changes 🤦
It's Friday. I should go home.2 -
bad nightmare: getting a bug on the day of deployment..
worst nightmare: getting more than 100 comments on a Rant with no ++1 -
Deployment can be a reason for heartache...
I deployed a website yesterday and it was a damn hustle. After changing into goodmode and typing random stuff into the console, I broke another of my websites on the same server.
Now I had two sites to deploy / repair. Damn.
After a few hours I managed to make both work. But damn, that adrenaline rush that gave me. Fuck!3 -
Holy fuckin shit. Fuck java updates.
Today we deployed to production with a java app. For whatever reason it didn't work, just throwing SSL errors left and right.
Same app works on dev and qa
There's only one tiiiiny difference: Java 8 141 on dev/qa, Java 8 171 on prod
Guess what happened in 171 ... they updated the CA
rip 4h debuggin5 -
When I can see actual clients using my software, and can get real feedback from them.
I usually work on backstage projects and my job never really affected "real, normal users". When I have something pushed and can really see user feedback and smiles, that means I've made it.
Of course, if that's on a decent job, with a decent team and decent pay. Which is where I am at now.
Soon, the app will be released - if the external infrastructure guy stop sucking. So, I'm hoping to feel I've made it soon, real soon :) -
A coworker changed the application deployment process. He told all three of the other developers who need deployments, but not me. We sit six feet away from each other and I've run/managed deployments for a year longer than him.
His new process doesn't work and he's blaming the dev ops team for not following it. The new process clearly doesn't fit their workflow and never could have.
The lack of deployments have caused production issues and he still won't ping dev ops to remind them about the deployment because "it's not in the new workflow".
He's been painting dev ops as incompetent at the last three retrospectives without having ever personally reminded the deployment guy.
Ugggh. -
Deployment to production last night, and the whole thing is halted because the DBA didn't find it necessary to show up. 2 hours of calling everyone possible and nothing. Thanks DBA, for your prompt and timely handling of the deployment... 😑
-
Trying to automate gitlab deployment with Ansible. It runs but freaking keeps failing on task. Reconfigure the gitlab server. Without helpful output!
After 2 days bashing and commenting line after line the answer reveals.
True != true Fuuucc...1 -
PM schedules deployment on a Friday... I address my concern about deploying on Fridays, I am assured it won't happen again since it is a special occasion. Next week's Friday... "Guys we need the remaining tasks on jira by today, client wants the app on production by today". smh1
-
When the client wants to deploy a patch to their app that is hosted on the cloud, but wants to do it onsite.
Oh well, might as well visit the data center of the cloud provider -
2 in 1 Rant: When your deployment process isn't automated and consists of copying and pasting between servers (1) and the "implementer" of this "deployment" STILL messes up the copying and pasting (2). How?!2
-
I always hate that part of the project where you finish all the coding and start trying to deploy into production for the first time.6
-
Colleague asks for help setting up deployment job. Tells me he has tried everything. Has no less than 5 typos.
-
Worked on project that has multiple forms. After deployment colleague asks me if I made the Chrome in-build autofill form function. He really liked and loved the option. Colleague calls himself front-end developer. True story!1
-
So it's Monday and its holiday in my country. But I have a deployment to do. Anyway I have this buddy accompany me which is nice.
 6
6 -
I love Heroku. It's so simple to use with all the add-ons, the deployment options and the fact that it's free for most of my projects. Heroku FTW.1
-
When your boss says "no we don't need you present for the deployment on Saturday at 4:00 am." And your PM chimes in and says, yeah you can log in remotely." FML
-
They say "Don't deploy on friday".
That's why we, the part time student team, deploy on saturdays.1 -
Never! Deploy! To production! On Thursday! *banging my head against the wall*
Now I need to revert some things manually on production ON MY DAY OFF 🤦♂️🤦♂️7 -
Doing the deployment to production, and towards the end one of the support guys looks over at me;
"So, the website in prod is throwing some errors"
Followed by another guy:
"Yeah I'm getting the same, SQL exceptions on the page"
I stare at them panicked for a moment, when one of them goes "just kidding!". Like dude, my heart just skipped several beats!
Any one here ever had something cruel happen to them during a deployment?3 -
lets just wait till the day before deploy to finally authorize api testing for users outside of the network - and then get super upset when we aren't adjusted, prepared, and tested in time for next-day deployment
-
Live deployment next week Monday but Product Owner really need this new fix in.
Can you code, push to test, test it, push to acceptance test, UAT it before Friday...
It's Wednesday today 😐
Project manager says ok 😱1 -
It's only Monday. Why do i feel so tired. T_T
Today's work:
- 3hrs check point meeting on Project A
- quick API fix, testing and dev assistance on Project A
- prelive deployment of Module B
- code review and enhancements for Script C
- prelive deployment and testing for Script C4 -
Yesterday you made fun of my code and told me to discard it, today you want to use it for project deployment?
N I C E
#intern_life -
Just launched a successful deployment today. Took 4 months to build everything. It's probably not a big deal but I'm just really happy today that everything worked right away, and almost no deployment hiccups at all.
Only one issue popped up, but come to find out it's a particular thing about the Prod environment and nothing to do with my code.
Gonna go celebrate now, before more work comes in. (hey, can you refactor this for me?) 4
4 -
Does anyone here uses Docker for all the environments (dev, qual, prod)?
If yes, how do you feel about it? How it is?8 -
when two sets of development team from different parts of the world don't talk or don't update each other... disaster is waiting to happen a day before deployment1
-
Just spent 3h setupping a Ruby on Rails deployment system with Capistrano.
Was intense but God's sake it's satisfying when it works flawlessly ! -
Deployed to production on Sat evening while drunk, surprisingly everything went smoothly. I think this was the first and last time I'll be releasing like this, lol.
Similar stupid experiences anyone?3 -
When you are new to a technology and language, but have to make full use of its feature.
You know, make tests, implement production code, planning deployment, build a CI. All by myself.
No regrets, though. Challenge accepted!1 -
Why does VC++ deployment have to be so painful? So many flavors of MSVRC, so little time. And don't get me started on the D3DCompile_*.DLL mess.
-
5am now and trying to do a production deployment. It just failed because boss loves making un-approved changes to prod that change entire database schemas. Argh!!
-
The mission was to develop an Android application for configure some devices(who goes 4000m under the water) before and after their deployment by Bluetooth.
It was pretty cool! -
in the hospital with surgery and our deployment goes wrong, so glad I work with really good people!3
-
What a disastrous deployment: instead of deploying one thing, 50.000 unexpected other things had to be done before. When the "official" deployment was done inside our own network, nothing worked as expected, servers had to be reconfigured, errors everywhere. Mind you it was tested multiple times by multiple people in a testing env. Difference between test and prod, classic.
When it was finally deployed, other errors started emerging, things that weren't considered before came to surface.
On top only the main dev knows the ins-and-outs, no substitute in case anything happens.
Deployment was rolled back in the end.1 -
What is more disaster
Than manager thinking to assign a production deployment to non technical person.1 -
Are you using an automated deployment solution for web development? If so, what would you recommend?6
-
My Stunt of the day:
People say avoid deployment on Fridays.
I strictly followed it and being a nocturnal creature, just pushed my code to Prod and it's Saturday early morning.
Deployment taking forever. Gonna sleep now.
I hope nothing goes down.2 -
So my company is preparing to do a deployment now... It's Friday 4pm...
And it's just yesterday that the build system was upgraded to a way newer version...
Luckily I'm not responsible of things go sideways 😅2 -
On my last deployment for the musician client I encountered a really nasty bug.
I configured all the settings in my Nginx. Theoretically everything should work, but it did not. Somehow I always ended up landing on my default Nginx page.
After hours of trying to find the typo, turning it off and on again and praying to all gods I ever heard of, I finally analysed my default Nginx config file. Somehow the server config I posted on the clients conf-file got posted beneath the default configs. WTF?
After deleting those everything worked. 🙄2 -
beware of font choices in chat apps; a coworker joked in the room that "well, sure, of course it's okay to update in production in the middle of the day" and for some reason, the other coworker didn't see the quotes because of the weird font they use, and also didn't stop to think, and went ahead and ran the deployment script. In production. In the middle of the day. With active users.
The good news is that those folks who logged back in got to use the new version a whole lot earlier than anyone was expecting. :\2 -
Today is the day when we rip out our old deployment system and get some new blood running through the CI/CD pipelines. Wish me good luck! Please...2
-
Me: finally we have automated deployment to production
Team Lead: No production deployment still requires manual approval
Me: ok how do you want to handle it slack, webhook, what do you suggest
Team Lead: let's do a proof of concept (POC) for this
Me: Ahh... Poc for this ?
Team Lead: you don't know sh*t ?
Me: well I know you're are creating that here
Next day team change... -
Hotswapping/replacing classes on the production server
We call it "russian deployment" .. No offense -
Never got scheduled for night deployment shift. Once i did, everything suddenly catches fire.
Well, twice. In a row.1 -
About two weeks ago, at my workplace, I learnt about Django deployment in Nginx server with Docker and Kubernetes on Google Cloud Console.1
-
Waiting 3 min for our deployment pipeline's "build step" to finish downloading all 1.08GB of source code because business won't prioritise tech led tickets (to use shallow cloning in this case) 😞
Feeling so apathetic rn 😝6 -
Deployed first time on Azure and it really hard to deploy lots of changes/setting need to done before publishing website.2
-
I hate when I have to add other people's code into a commit as they haven't made their module available on packagist so I couldn't use composer and it makes my deployment fail

-
A common walkthrough with Laravel deployment:
1.) Error 403
2.) Internal server error 🤔
3.) bad require paths in index.php....
4.) Whooops something went wrong.. What?.... Look at log file with 2MB size
5.) View not found1 -
Life would be a lot better if the client's requirements won't change abruptly on the last minute of deployment
-
For all the effort it takes to setup CI/CD it's totally worth it. My god this is marvellous I've wasted over 40 build minutes already just to see a spinner spin until it turns green :-D2
-
!Rant
Tldr: great spike to solve deployment problem may be a wasted effort.
Deployments of an ancient electron application need to be done in CodeDeploy to deploy the latest build. Customer hour restrictions cause this to be done only after midnight, and manually checked.
The whole team knows this is the wrong method of deployment and that there are many other operational problems with the project.
A few other senior team members get together and decide to spike out a way to use electron auto-deployment to accomplish this without using code-deploy at all.
After a shallow dive into this subject, we all get pulled aside to handle a change in another part of the software ecosystem. It happens. We leave the spike behind.
A junior-intermediate developer on the team pics the project up and gets a good spike going in a day and a half! We are all high fives and beers. This is Friday.
By Monday there is a pull request in for code review and it looks solid. Seems like it will make deployments a lot better.
Preparing the last deployment (hopefully) with CodeDeploy ever...
Marketing team members inform us that they are running an add system on the customer devices and to do it they are using Linux.
The current application being deployed is using Windows 10 (yeah, another problem).
They say they have made plans to move our application over to Linux. This means we may not be able to launch the junior devs great spike and the old deployment method may stay for the time being.
Meetings soon to find out how all of this will hash out.
End of rant. I hope I'm doing this right -
Kong API Gateway in Kubernetes is a load of balls. Spent half a day trying to stabilise the deployment after I bumped its pod resource requests.1
-
!rant, but story
Update: I now work as a 1st lvl support
After 5 to 11 months I'll work in deployment and after that in development.14 -
Someone broke our Microsoft deployment toolkit at work and won't own up to it. The whole thing needs nuked and rebuilt. So, I'm stuck with 7 laptops at home to manually build over the weekend.
-
do you do any rituals to make it psychologically easier to deploy your code into production / replace an existing working system?3
-
It usually starts with a project, a CI pipeline, unit tests, deployment guidelines, and wait - oh crap - what am I building again?
-
When the big guy at the top for vanity sake changes the name of a git team, breaking every auto deployment and local repo needing updating for every fucking one. console.log("fucking shit balls")
-
Today I had to fix a bug and it took me about 2 hours to find out that it related to a bug in a component which doesn't belong to the bugs component. In development everything where fine. But after deployment the bug occured. Found out that when running Vue webpack projects in dev it handles errors different, kind of a global try catch block. After deployment the application breaks.
This teached me again that we should not ignore any red error line in console. -
Hello all,
Just asking for some advice.
Vultr vs Linode vs DigitalOcean
for a website that contains streaming and high traffic which is best for dev start and then maybe deployment?15 -
Today was my first day in OPS room.
Fucking felt weird!
Literally only 1% understood I guess.
Luckily seniors were there with me.
I hope, soon will understand more ;) -
Created whole UAM System in Product for client. After the deployment client asked me
"In which table should I run the query to create a new user." -
11:30 working hours logged for today. Went against the #NoDeploymentFriday rule. Fingers crossed 🤞 for the weekend
-
JBoss deployments, because nothing ever works if you dont completely restructure your project for every single version and my company cant decide on which version to use.
This is pretty much the main reason I dislike backend developement. -
Hmm. I've been wondering how I'll deploy an api based on a microservice style the smartest way... The general plan was to use salt to setup the base server and install dependencies and add the configuration.. Doing updates would be a git pull and pm2 restart api. I would love to know how you deploy your software ?1
-
Ok peeps!
A newbie to nodejs and linux VPS (ubuntu) would appreciate any tips you could throw my way on how to push locally developed nodejs webapp to prod in vps server 😊
Thanks!5 -
PM: Could you make a deployment platform to only roll out to specific users, and make a script that changes the code so that you can tailor tasks to each user.
Me: Excuse me? ... -
At my work we still deploy web files the old-fashioned way, copying newer versions over from dev to test and test to prod. For comparing and copying changed files we use WinMerge. Although our workflow sucks, WinMerge itself is actually a nifty little tool for comparing any sort of text files. But today it pissed me off in a way it never has before. I copied a diff from left to right and then meant to save it with Ctrl + S, but accidentally pressed Ctrl + D. Guess what happened? To my horror, both sides went completely blank! It looked as if the file contents had been deleted, and undo had no effect. To my relief, the files were intact when opening them in VS Code. Thinking this was a glitch in WinMerge, I restarted it but still, all files were blank. No contents displayed! Then I thought, perhaps pressing Ctrl + D again would bring the file contents back into view. And it did! So the bottom line is: Pressing Ctrl + D makes the compared files appear as empty. Now, who would want that to happen? What a nice feature, you've got here WinMerge! (I'm being sarcastic in case you missed that)6
-
!rant
Quiet day in the office today. So I decided to optimise certain aspects of our software deployment. Success!2 -
I was looking into replicate and the likes (cloud ML model deployment) but these idiots only allow signup through GitHub.
What kind of dicksucking dev uses GitHub? It's fucking Microsoft. How hard is it to implement normal email signup, what the shit?1 -
Having a meeting with an old client of our company's today, guiding him through the deployment process for his front and backend, because he thought that we were withholding information, and at one point in the call he asks me if the './' at the beginning of the deployment script was a special security measure put in place by us... 😂
-
Ah yes. Make changes on that deprecated repo. Thanks. Now I have to merge them and remove all the branches code too in that repo. I guess an empty master and a broken deployment script isn't a big enough flag for you.1
-
I logged in a Remote Server, where Bi-Directional was disabled.Didn't allowed copy-paste and needed to upload a new Web app release.
Hack: just inserted usb flash drive in my computer and remote server recognised that as external.
Deployment completed!4 -
Hell will break loose even if you deploy your shit on monday morning and noone has anything else to do.
-
Here's a leak of our Prometheus dashboard during our last Friday deployment of our campus site
https://streamable.com/bfgtz1 -
The CTO of the company which released Websphere has the audacity of talking about simplifying deployment ecosystem.
-
Best: finding Laravel and how well works out with production deployment with GitLab
Worst: didnt implement this right from the beginning. Had to copy paste from the dev folder to production folder FOR 3 MONTHS when i wanted to update the website. -
Finally finished the model deployment and it fuckin works!!!
belle bouteille viens ici que j’te caresse ~~~ -
To ensure everything goes well on prod, the chief QA set an env called 'stable' after prod deployment to stimulate true prod situation. Then we found that some apis on 'stable' crashed more often then those on prod.
-
* coughing *
* singing mode on *
For the first time in deployment
There'll be magic, there'll be fun!
For the first time in production
I could notice there's an exception
And I know it is totally crazy
OK Bye -
What percentage of your time is spent actuslly coding?
In a week, I spend not more than 1 full working day writing codes. The rest is spent doing PoCs, designing (LLD and rarely HLD), solutioning and deployment.1 -
Just discovered that my webpack bundle beeing modified manually (via notepad) by Devops when Deployed to production :/1
-
Custom software deployment for a big conference in Berlin worked perfectly. Almost didn't need to open visual studio the whole trip.
That almost never happens.
Bye bye Berlin, until next time. -
2nd day of deployment!
Till now its going smooth; server configured + tables migration is ON!
PS: Migrating old site to new ;)1 -
Today I read some words about ash deployment. Because I'm a dumbass I until now still deploye via FTP. So I read about flightplan.js and it was just awesome. I saw a video of some guy using it and I switched to girly-mode and started whining. Why didn't I use that earlier???? It's so much easier!!! And faster!!!
But then I read it's not the tool of choice on windows machines. So here's my question: what do I use for deployment on windows? Are there similar tools like flightplan.js?5 -
The integration of technologies project I have this year. Not yet finished but I already learned a lot of very cool stuff.
First, I learned a new programming language + framework (Ruby on Rails)
Second, for the first time, I implemented a continuous deployment pipeline with Capistrano and Travis ci.
Third, first time I programmed a Restful API.
And more cool stuff coming up ! :D
I freaking love learning ! -
I've having issues trying to form a proper branching strategy for my mean stack app deployment.
Heroku creates staging and prod branches for my web app so I'm a bit confused if I need my own staging branch?
Currently I have this: feature -> dev -> staging -> heroku staging (the staging branch seems useless)
Also, Heroku allows you to promote heroku staging to heroku prod, so there's no point in making master push to heroku prod.
I'm thinking of making my strategy to the following, but wasn't sure of any pitfalls or anything I'm overlooking long term.
feature -> dev -> master -> heroku staging -> manual promote to heroku prod.
Any suggestions?5 -
My company has been pressing for "engineering excellence" for a few years now... So why is the internal build/deployment tool still so slow?
You'd think they'd get this fix ASAP right? Or is this the tour of excellence they are expecting?3 -
I just realized i didnt push my BREAKING api changes for at least 2 Weeks, tomorrow is the initial deployment and either my code or the teams code is not gonna work, still deciding which is more important <.<
-
Auto Login feature enables itself when a certain config flag is present - the app will login as an admin without requiring username or password.
I pray to the Continuous Deployment monsters that the config setting never gets copied to production by mistake.2 -
I'm done. Fuck you TFS. If you provide me with an option to run scripts on deployment targets then please show me these sweet errors that somehow must occur as my script is not executed at all..2
-
That feel when you have a deadline for a website project which requires content from someone in the team and after months of asking for the content they give it to you a few days before a demo day and guess what?
They freaking forgot to send you everything needed so some of the images are blank and hidden and one of the pages has dummy text.
Even the higher ups chasing him, didn't help.4 -
Made a pull request..review tonight... Deployment tomorrow night.. or morning according to new york time... Hope I don't wake up to pissed off comments in the request.
-
For 2 weeks or more testing our app .. everything is perfect.
Deployment date .. hell break loose 😒😣😫😫😫😫 -
Your most nerve wrecking / riskiest deployment?
I once made a deployment during a meeting of my boss and the client, while they were using said a live chatting feature, in order to fix a bug in said chat.
This was essentially also testing rolling deployments and and state handoff at the same time.
My boss and the client didn't notice the deployment (My boss was in on it btw).
Epic win3 -
Any of you experienced Devs have any recommendations book wise for backend development (framework, unit testing, vcs, server deployment...) For java.
FYI I do have a LITTLE experience with MVCs6 -
A typical situation in some badly-configured projects...:
1) Having to restart an entire webserver every time you make any change to the code. Hot reload? Unheard of. lol. Then there's also no time to research things because it's push push push.
2) Other ugliness: frameworks so proprietary and locked that you can't hook into anything, so you have to debug using println() everywhere.
I don't suffer from 2) but sadly still from 1).
We live in a world where things are better than this. Come on.3 -
Docker deployment
Wondering how you guys are doing docker deployment (angular, php, whatever) on self hosted servers from a private gitlab instance ?
Also most recent gitlab release seems Very promisssing on this.
There's a lot info on deploying to aws or google but not on this case (at least clear)
Would like to hear from you about your setups1 -
In the middle of a deployment call and the dev wants to "add a feature" on the fly (what could go wrong right!?). Next thing I here on our phone call is the client saying "great idea let's add that feature now! I'll wait to test!" Wait... WHAT THE FUCK is the client doing on this deployment call?!1
-
so the deployment from my side went through ok... but a "SYSTEM" defect almost prohibited my changes from being signed off... explained it to the person responsible... and then they sign it off knowing well that it was a "SYSTEM" defect that was outside of scope...
-
When Codeship shits itself right after bollocksing up the production deployment of a minor preventive fix.
-
Is it possible to get through a work week without hearing about a surprise requirement when the deployment is supposed to be one week from now?
Bonus points: One week from now, deployment is delayed due to more whatever shit they forgot to take care of in the biz side1 -
Deploying an app on heroku when using ruby and rails on the backend and AngularJS on the front end is just a pain 😭
Just thought I'd share my feeling about it!!! -
Yesterday 14h work, today‘s day started earlier at 7am.
Live deployment is not going great.
WE SAID WE NEED TO TEST IT BEFORE GOING LIVE1 -
What's the simplest way to deploy a small node project to a private root server, possibly dockerized?
I feel like there are thousands of possibilities nowadays, like Ansible and so on. But is there something more in the the KISS way? Apart from just hacking a bash script together of course, it should be portable (and work on windows too).1 -
!rant Question: How reasonable is it to expect payment before deployment of code to the live instance, even if the project launch was significantly delayed?7
-
Lately been working in deployment, automation, and optimization. (Web) im very open to hearing how people are doing this with various technology stacks.2
-
Testing new server deployment in test env all works, then production it all breaks down. Network didn't allowed the right traffic. Took me whole week to find that out. Until some networking engineer said, you know there is a firewall between those networks?
-
Release team was recently disbanded, they handed off release management to the Dev scrum masters. The other day we had a weekly release for a product that uses a network service that is shared with other products. The devs didn’t know how to set up the build correctly. They had a purge setting on that removed the network service for products that weren’t being touched in the release. The end result was that the other products were inaccessible for an hour and a half! They eventually found their mistake, but we were lucky that it was outside of core business hours.
These devs need to learn how to work the build tools! Or maybe we should rethink getting rid of the release team. -
Me: Code checked in, CI and tests passed, deployment kicked off. Huh maybe I won't have to stay late after all!
Production Web Server:
-
What is the best approach for Continuous Integration / Continuous Delivery/Deployment? I'm using SVN as code repository and I need to identify the files that goes to Test/QA env. and the ones that goes do Prod env. (by Commit message or something else) via sFTP.
Any help would be appreciated. Already tested Jenkins, GoCD and Jetbrains Teamcity.1 -
So we have this cycle of releases once every month for the products I work on at my company. Yesterday we started deploying a new version of one of our products on azure. Surprisingly it seems like none of the new features are working, and after two days of tweaking the code, deleting, moving, and re-publishing azure web jobs, rechecking the test environments, making sure every queue was used by the right webjobs… It turns out someone had published said webjob in 15 instances on a resource that we barely use and so the azure queue was being used by these outdated webjob instances…
Motherfucker, two days wasted for that :( -
The struggle when you're just starting with Ansible and you are tasked to orchestrate the deployment of a giant monolith on a fully customised AWS infrastructure in two weeks

-
Colleague put this up on their team's channel today :
" I'll be working from home today, ad hoc task is in review, will be opening a PR for backend changes [ ... ], yesterday was mainly spent on setting up gcp on my local and fixes towards gcp deployment. "
Wait, what? did you just set up the entire GCP on your local [machine]? I wouldn't mind giving you a whole week off if you needed it; if I were your manager.3 -
How much of a fucking faff is it trying to deploy a rails app to ElasticBeanstalk?!
Brand new instance and it's got no fucking clue what Bundler is, installing gems (looking at you, Nokogiri,) is about as difficult as pissing stones and don't get me fucking started on Webpacker and asset pre-compilation.
DEPLOYMENT SHOULD NOT BE DIFFICULT.2 -
I’m enjoying leetcode nowadays.
To the detriment of my graphql deployment progress.
Ashamed to say, but my DSA are beyond terrible. Better late than never I suppose!
Anyone else enjoys it?1 -
As if development problems weren't enough, there's also bullshit deployment problems to deal with first. Sigh.
-
Our security group is so tight that they won't give the credentials for deployment. They just created a role "attached" that role to our deployment server. How does that even work????4
-
Minimise (or if possible, eliminate) free-text interaction in deployment scripts. You *will* type in the wrong value.
-
Received 'Thank you' e-mail after Test Deployment and UAT !!
Usually i receive that e-mail after production and some issue findings! -
Anybody had experience with Hashicorp Nomad for smaller deployments (personal in this case)? Thinking of using it after having done it too many times with complex Kubernetes and Docker... 😅 Also don't wanna run this thing bare bones as i have a whole bunch of services to deploy together.
-
Manager: No deployment during the code freeze
Dev: Yes, sure
(Manager goes on vacation)
Dev: Got a weird smile1 -
Working on an automated deployment process as an aged programmer is tough! So I go outside feed the pigs, have a chat with them.
Back in, advice on board and I roll - solution solved! -
Why the fzck do you release new features in your engine and change how port-mapping works but don't make your deployment tool compatible? I look at you docker!
-
Interruptions from production team because of a tiny issue that’s already been fixed waiting for deployment
-
!rant
I've been following and finished a course about MVC 5. On the deployment side he showed how to deploy the Release on the filesystem through the vs 2017 publish Wizard GUI and after that he suggest to deploy that folder on the IIS server. Now I looked around on the web and I've not found a way\guide on how to self host that project on my PC and expose the project to internet (which I do mostly by using no-ip.org). Someone have any clue or can point to a step by step guide? -
I am the only Backend developer in my team, so I have to do sysAdmin tasks, deployment and configurations myself....
I HATE it! -
The project I'm currently working on: developing a new rootless container deployment to host some legacy Python applications (zope/plone). The initial plan was to just host those on VMs with all the legacy software, I at least convinced everybody to develop a new container deployment for it, which could be re-used for other things. However, it's a lot more work, and working with Puppet goes at a meandering pace.
-
That second when you scan the stack trace, spot the line in error and just think to yourself "wtf just happened"
-
Ok. Wtf?!?
Our platform architect gives a damn about continuous delivery.
Today I asked the architects for help, because bamboo is not able to trigger a deployment plan by changes in repository branch pattern release/x.x.x.
He cancelled my question with the statement "if we have the Kubernetes environment, we have more valuable things to work on".
Generally CD is no rocket-science and it is achievable with reasonable effort! -
Is leadership's willingness to accept shoddy code and a shoddy deployment process, as long as you can develop shoddy features early, a common theme among startups?
I really get a "not my problem when I sell this business" vibe from this attitude.5 -
I have a meeting in 1 hour that should be about the deployment of a product. This morning I got 2 emails from the client about some not so small changes.
Not sure how I can explain that I'm not a wizard. -
So at my last job we had an AM deployment and a PM deployment. We had code reviews, QA, a slow roll process (deployed to three servers), monitoring process, and once everything checked out we fast rolled to the other servers.
At my current job we have a QA process, and we deploy once every three weeks.
My first job I deployed as needed, with no QA at all (I was the only web dev there).
I'm currently at a major e-commerce site, my last job was more of a click-bait site (though it still made millions in revenue each year).
So my question is: is there a "normal" as far as deployment schedules? I realize that each business type is going to have their own needs, but what's the "average" time between deployments?













































































































































































































































































Top Tags
Weekly Rant
View