
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
TL;DR
I accidentally surpassed(?) my user permissions and closed some of my classmates browsers and locked up a terminal for me
In school we have 2 primary operating systems: Windows and Ubuntu. Windows is hell in general and but not as hell as the firefox installation on Ubuntu.
"Just loaded this page. Now wait half a minute so that I can render it"
"Woah, woah, woah. Slow there. You just made an input event. Give me those 5 seconds to compute what you just did"
Executing "top" or "htop" shows you a long list of firefox processes with a cpu usage of 99.9%, since the whole school shares that linux environment.
Anyway, one day it was way more servere than normally and I way forced to kill my firefox instances. So I pressed CTRL+ALT+T for that terminal, waited 5 minutes until it accepted input typed "killall firefox" with a delay of half a minute per character and smahed that enter key.
At this very point in time I could hear confusion from every corner of the room. "What happened to firefox?"
Around 30% of the opened browsers where abruptly stopped. I looked back to my screen noticed I was logged out. I couldn't login from that terminal for the rest of that day.
Our network admin, which happened to be there, since the server is just next door, said that this was just convenience, but the timing was too perfect so I heighly doubt that.
I felt like a real hackerman even if it was by accident :)8 -
I just had the most surreal email discussion I think I've ever had...
I spent over two hours going back-and-forth over email with an enterprise DBA, trying to convince them I needed a primary key for a table. They created the table without a primary key (or any unique constraints... or indexes... but that's another discussion). I asked them to add one. Then had to justify why.
If you ever find yourself justifying why you need a primary key on a table in an RDBMS, that's the day you find yourself asking "is this real life?"
I want the last two hours of my life back. And a handful of Advil.1 -
I am very frustrated today and I do not know where to "scream" so I will post this here since I believe you will know how I feel.
Here's the case...
I am developing an e-commerce web application where we sell industrial parts. So my boss told me on March that when we are going to show these parts, we should not show Part Number to visitors because they will steal our information.
Ok, this makes sense but there was a problem.
The Primary Key for these products in our internal system is a string which is the Part Number itself.
I told him on March that we have to come up with another unique number for all the products that we are selling, so this unique number will be the primary key, not the Part Number. This will be best because I will be dependent from the original Part Number itself. And in every meeting he said "That is not priority". So I kept developing the part using the original Part Number as primary key and hid is from the web app. (But the Part Number still shows on URL or on search because this is how my boss designed the app.)
I built the app and is on a test server. Until one of out employees asked my boss: "There is no unique number or Part Number. How are the clients going to reference these parts? If a client buys 20 products and one of those has a problem, how is he going to tell us which products has a problem?"
My boss did not know what to say, and later said to me that I was right and primary key was priority.
I really hate when a guy that knows shit from developing does not listen to suggestions given by developers.
FUCK MY LIFE!
I'm sorry if you did not understand anything.5 -
First rant here, and it's going to be a query to the more professional and experienced members of society (most of you).
I am currently a Sys Admin for a major company, and I develop at night. My primary employment at the moment is the sys admin job (and I code for extra money at nights).
I wanted to start a development department at the company that I am working at, but it was turned turned down. It was stated that we are not branching in development, and that we should stick to our server implementation and support. This was a prompt to me wanting to start studying officially (I wanted to get qualified in JAVA, so that I had some paper behind my name when I looked for another job). HR and my directors outright denied me the ability to study through them (they pay for studies for employees) and I was more than fine with this.
I took a loan and paid for the studies myself. Can't crush a dream, you know?
The director caught wind of me studying, and now has demanded that I develop him a mobile application for the company. I told him that I am not a mobile developer, and that it didn't fall into my key performance areas.
Note, I do my coding on own time, on my own device, and never at work. It's fully my intellectual property. It also in no way interferes with my work during the day, and has NO conflict with my contract this side.
He sent an email yesterday, this is after two months. He is now stating that I WILL do the application, and he has CCd HR and two directors.
I don't want to do the app for this company, I spoke to HR previously about this, and she said that I should try and quote it under my own company name (which I did, but it was denied as it was "too expensive").
Now I am being forced to do something that is COMPLETELY out of my roles and responsibilities, something that this company has ABSOLUTELY no desire to go into further on, and he is basically letting me know that if I don't do it, he is going to start messing with my pay.
I really don't want to do this, and I cannot afford to make my secondary job my primary at the moment. The problem is, too, that I don't have the time during the day to develop AND do my sys admin tasks (I manage more than 300 servers, and 5000 devices).
What can I do in this instance? Or what would you guys recommend, in your experience?
Sorry for the noob question, but I don't know what to do.19 -
Everyone and their dog is making a game, so why can't I?
1. open world (check)
2. taking inspiration from metro and fallout (check)
3. on a map roughly the size of the u.s. (check)
So I thought what I'd do is pretend to be one of those deaf mutes. While also pretending to be a programmer. Sometimes you make believe
so hard that it comes true apparently.
For the main map I thought I'd automate laying down the base map before hand tweaking it. It's been a bit of a slog. Roughly 1 pixel per mile. (okay, 1973 by 1067). The u.s. is 3.1 million miles, this would work out to 2.1 million miles instead. Eh.
Wrote the script to filter out all the ocean pixels, based on the elevation map, and output the difference. Still had to edit around the shoreline but it sped things up a lot. Just attached the elevation map, because the actual one is an ugly cluster of death magenta to represent the ocean.
Consequence of filtering is, the shoreline is messy and not entirely representative of the u.s.
The preprocessing step also added a lot of in-land 'lakes' that don't exist in some areas, like death valley. Already expected that.
But the plus side is I now have map layers for both elevation and ecology biomes. Aligning them close enough so that the heightmap wasn't displaced, and didn't cut off the shoreline in the ecology layer (at export), was a royal pain, and as super finicky. But thankfully thats done.
Next step is to go through the ecology map, copy each key color, and write down the biome id, courtesy of the 2017 ecoregions project.
From there, I write down the primary landscape features (water, plants, trees, terrain roughness, etc), anything easy to convey.
Main thing I'm interested in is tree types, because those, as tiles, convey a lot more information about the hex terrain than anything else.
Once the biomes are marked, and the tree types are written, the next step is to assign a tile to each tree type, and each density level of mountains (flat, hills, mountains, snowcapped peaks, etc).
The reference ids, colors, and numbers on the map will simplify the process.
After that, I'll write an exporter with python, and dump to csv or another format.
Next steps are laying out the instances in the level editor, that'll act as the tiles in question.
Theres a few naive approaches:
Spawn all the relevant instances at startup, and load the corresponding tiles.
Or setup chunks of instances, enough to cover the camera, and a buffer surrounding the camera. As the camera moves, reconfigure the instances to match the streamed in tile data.
Instances here make sense, because if theres any simulation going on (and I'd like there to be), they can detect in event code, when they are in the invisible buffer around the camera but not yet visible, and be activated by the camera, or deactive themselves after leaving the camera and buffer's area.
The alternative is to let a global controller stream the data in, as a series of tile IDs, corresponding to the various tile sprites, and code global interaction like tile picking into a single event, which seems unwieldy and not at all manageable. I can see it turning into a giant switch case already.
So instances it is.
Actually, if I do 16^2 pixel chunks, it only works out to 124x68 chunks in all. A few thousand, mostly inactive chunks is pretty trivial, and simplifies spawning and serializing/deserializing.
All of this doesn't account for
* putting lakes back in that aren't present
* lots of islands and parts of shores that would typically have bays and parts that jut out, need reworked.
* great lakes need refinement and corrections
* elevation key map too blocky. Need a higher resolution one while reducing color count
This can be solved by introducing some noise into the elevations, varying say, within one standard div.
* mountains will still require refinement to individual state geography. Thats for later on
* shoreline is too smooth, and needs to be less straight-line and less blocky. less corners.
* rivers need added, not just large ones but smaller ones too
* available tree assets need to be matched, as best and fully as possible, to types of trees represented in biome data, so that even if I don't have an exact match, I can still place *something* thats native or looks close enough to what you would expect in a given biome.
Ponderosa pines vs white pines for example.
This also doesn't account for 1. major and minor roads, 2. artificial and natural attractions, 3. other major features people in any given state are familiar with. 4. named places, 5. infrastructure, 6. cities and buildings and towns.
Also I'm pretty sure I cut off part of florida.
Woops, sorry everglades.
Guess I'll just make it a death-zone from nuclear fallout.
Take that gators!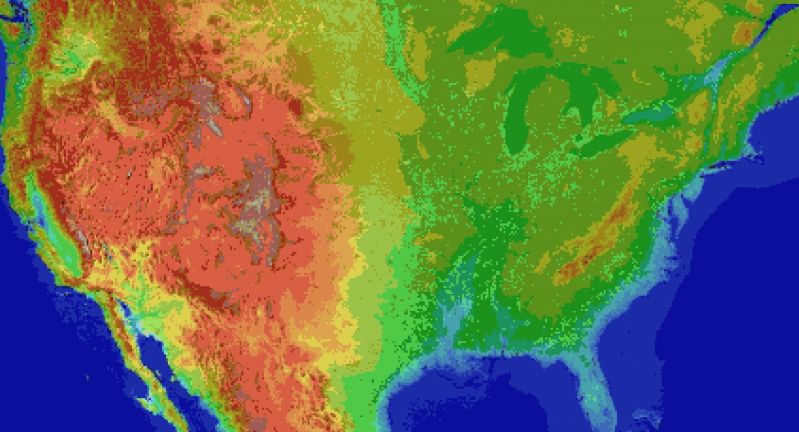 5
5 -
Ok now I'm gonna tell you about my "Databases 2" exam. This is gonna be long.
I'd like to know if DB designers actually have this workflow. I'm gonna "challenge" the reader, but I'm not playing smartass. The mistakes I point out here are MY mistakes.
So, in my uni there's this course, "Databases 2" ("Databases 1" is relational algebra and theoretical stuff), which consist in one exercise: design a SQL database.
We get the description of a system. Almost a two pages pdf. Of course it could be anything. Here I'm going to pretend the project is a YouTube clone (it's one of the practice exercises).
We start designing a ER diagram that describes the system. It must be fucking accurate: e.g. if we describe a "view" as a relationship between the entities User and Video, it MUST have at least another attribute, e.g. the datetime, even if the description doesn't say it. The official reason?
"The ER relationship describes a set of couples. You can not have two elements equal, thus if you don't put any attribute, it means that any user could watch a video only once. So you must put at least something else."
Do you get my point? In this phase we're not even talking about a "database", this is an analysis phase.
Then we describe the type dictionary. So far so good, we just have to specify the type of any attribute.
And now... Constraints.
Oh my god the constraints. We have to describe every fucking constraint of our system. In FIRST ORDER LOGIC. Every entity is a set, and Entity(e) means that an element e belongs to the set Entity. "A user must leave a feedback after he saw a video" becomes like
For all u,v,dv,df,f ( User(u) and Video(v) and View(u, v, dv) and feedback(u, v, f) ) ---> dv < df
provided that dv and df are the datetimes of the view and the feedback creation (it is clear in the exercise, here seems kinda cryptic)
Of course only some of the constraints are explicitly described. This one, for example, was not in the text. If you fail to mention any "hidden" constraint, you lose a lot of points. Same thing if you not describe it correctly.
Now it's time for use cases.
You start with the usual stickman diagram. So far so good.
Then you have to describe their main functions.
In first order logic. Yes.
So, if you got the point, you may think that the following is correct to get "the average amount of feedback values on a single video" (1 to 5, like the old YT).
(let's say that feedback is a relationship with attribute between User and Video
getAv(Video v): int
Let be F = { va | feedback(v, u, va) } for any User u
Let av = (sum forall f in F) / | F |
return av
But nope, there's an error here. Can you spot it (I didn't)?
F is a set. Sets do not have duplicates! So, the F set will lose some feedback values! I can not define that as a simple set!
It has to be a set of couples, like (v, u), where v is the value and u the user; this way we can have duplicate feedback values in our set.
This concludes the analysis phase. Now, the design.
Well we just refactor everything we have done until now. Is-a relations become relationships, many-to-many relationships get an "association entity" between them, nothing new.
We write down on paper every SQL statement to build any table, entity or not. We write down every possible primary key or foreign key. The constraint that are not natively satisfied by SQL and/or foreign keys become triggers, and so on.
This exam is considered the true nightmare at our department. I just love it.
Now my question is, do actually DB designers follow this workflow? Or is this just a bloody hard training in Pai Mei style?6 -
A time I (almost) screamed at co-worker?
Too many times to keep up with.
Majority of time its code like ..
try
{
using (var connection = new SqlConnection(connectionString))
{
// data access code that does stuff
}
catch (Exception e)
{
// Various ways of dealing with the error such as ..
Console.WriteLine("Here");
ShowMessage("An error occured.");
return false;
// or do nothing.
}
}
Range of excuses
- Users can't do anything about the error, so why do or show them anything?
- I'll fix the errors later
- Handling the errors were not in the end-user specification. If you want it, you'll have to perform a cost/benefit analysis, get the changes approved by the board in writing, placed in the project priority queue ...etc..etc
- I don't know.
- Users were tired of seeing database timeout errors, deadlocks, primary key violations, etc, so I fixed the problem.
On my tip of my tongue are rages of ..
"I'm going to trade you for a donkey, and shoot the donkey!"
or
"You are about as useful as a sack full of possum heads."
I haven't cast those stones (yet). I'll eventually run across my code that looks exactly like that.1 -
DataDevNerd (ofc down to hardware bits)
Briefly blending amoung holiday tech consumers at Micro Center waiting for key-holder assistance @SSDs.
Rando: "they finally have a sale on *X, rebranded, price++* for my *ref'd only by part names* setup! What are you getting?"
Me: "replacement SSD, laptop's finally failing"
Rando: "Yeah, I totally get you, I hate that. How old is it? Hopefully you got a couple years outta it?"
Me: "over 7yrs old."
Rando: "Wow! Mustve not used it too much, still that's pretty long."
Me: "Actually, it's been my primary device, heavily used, as I'm a dev. I just know what/when to use SSD vs the HDD."
Rando: "Duuude, that's awesome!...wait...why haven't you just bought a new laptop yet?"
Me: "I'm not for hardware abuse or burning money"
I was quickly reminded why I tend to avoid typical consumer tech stores. 2
2 -
(tldr: are foriegn keys good/bad? Can you give a simple example of a situation where foriegn keys were the only and/or best solution?)
i have been recently trying to make some apps and their databases , so i decided to give a deeper look to sql and its queries.
I am a little confused and wanted to know more about foreign keys , joins and this particular db designing technique i use.
Can anyone explain me about them in a simpler way?
Firstly i wanted to show you this not much unheard tecnique of making relations that i find very useful( i guess its called toxi technique) :
In this , we use an extra table for joining 2 tables . For eg, if we have a table of questions and we have a table of tags then we should also have a table of relation called relation which will be mapping the the tags with questions through their primary IDs this way we can search all the questions by using tag name and we can also show multiple tags for a question just like stackoverflow does.
Now am not sure which could be a possibile situation when i need a foriegn key. In this particular example, both questions and tags are joined via what i say as "soft link" and this makes it very scalable and both easy to add both questions and new tags.
From what i learned about foriegn keys, it marks a mandatory one directional relation between 2 tables (or as i say "hard a to b" link)
Firstly i don't understand how i could use foriegn key to map multiple tags with a question. Does that mean it will always going to make a 1to1 relationship between 2 tables( i have yet to understand what 11 1mant or many many relations arr, not sure if my terminology is correct)
Secondly it poses super difficulty and differences in logics for adding either a tag or question, don't you think?
Like one table (say question) is having a foreign key of tags ID then the the questions table is completely independent of tag entries.
Its insertion/updation/deletion/creation of entries doesn't affect the tags table. but for tag table we cannot modify a particular tag or delete a tag without making without causing harm to its associated question entries.
if we have to delete a particular tag then we have to delete all its associated questions with that this means this is rather a bad thing to use for making tables isn't it?
I m just so confused regarding foriegn keys , joins and this toxi approach. Maybe my example of stack overflow tag/questions is wrong wrt to foreign key. But then i would like to know an example where it is useful5 -
Buy Verified Cash App Account: Navigating the Digital Transaction Landscape
In an age dominated by digital transactions, the concept of purchasing a verified Cash App account has gained significant traction. This article aims to explore the nuances of buying a verified Cash App account, elucidating the advantages, potential risks, and offering a comprehensive guide for individuals considering this financial move.
Introduction
The Growing Trend of Buying Verified Cash App Accounts
As online transactions become more prevalent, the trend of purchasing verified Cash App accounts is on the rise. Users are increasingly recognizing the added benefits and security that come with having a verified account.
Understanding the Importance of Account Verification
Account verification is a crucial step in enhancing the security of digital transactions. A verified Cash App account provides users with an additional layer of protection, making their financial interactions more secure and reliable.
Advantages of Purchasing a Verified Cash App Account
Enhanced Security Features
One of the primary advantages of a verified Cash App account is the incorporation of advanced security features. These may include multi-factor authentication and additional verification steps, adding an extra layer of defense against unauthorized access.
Increased Transaction Limits
Verified accounts often come with substantially increased transaction limits. This proves beneficial for users engaged in larger financial transactions or those running businesses through the Cash App platform.
Access to Exclusive Cash App Features
Apart from heightened security and increased transaction limits, verified accounts may unlock exclusive features within the Cash App. This could range from priority customer support to early access to new features and promotions.
How to Safely Purchase a Verified Cash App Account
Researching Reputable Sellers
Before entering the purchasing process, it's crucial to research and identify reputable sellers. Reading reviews and testimonials can provide valuable insights into the credibility and reliability of a seller.
Authenticating Account Legitimacy
Ensuring the authenticity of the accounts offered by sellers is paramount. A legitimate verified account should have gone through the necessary verification steps outlined by Cash App.
Ensuring Transparency in Transactions
Transparency in transactions is vital. Buyers should choose sellers who provide clear information about the accounts, including their verification status and any associated features.
Risks and Precautions in Buying Verified Accounts
Common Scams in the Verified Account Market
The digital landscape is not without risks, and the market for verified Cash App accounts is no exception. Being aware of common scams, such as fake listings and phishing attempts, is essential.
Tips for a Secure Transaction Process
To mitigate the risk of falling victim to fraudulent transactions, following best practices such as using secure payment methods and verifying the seller's credentials is crucial.
Step-by-Step Guide to Verifying a Cash App Account
Understanding the Cash App Verification Process
Before attempting to verify a Cash App account, it is essential to understand the process thoroughly. Familiarizing oneself with the required documentation and steps ensures a smooth verification experience.
Submitting Required Information
During the verification process, users typically need to provide personal information, such as a valid ID and proof of address. Ensuring the accuracy and legitimacy of this information is key to a successful verification.
Navigating Potential Challenges
While the verification process is generally straightforward, users may encounter challenges. Being prepared to troubleshoot and address potential issues ensures a seamless verification experience.
Conclusion
Summarizing the Benefits and Risks
In conclusion, opting for a verified Cash App account offers users enhanced security, increased transaction limits, and exclusive access to platform features. While potential risks exist, informed decision-making and adherence to safety precautions can lead to a positive experience.
Encouraging Informed Decision-Making
As users consider the option of purchasing a verified Cash App account, it is crucial to approach the process with caution and awareness. Choosing sellers with proven credibility, staying informed about potential risks, and following best practices contribute to a secure and positive experience.









Top Tags
Weekly Rant
View