
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Worst thing you've seen another dev do? Long one, but has a happy ending.
Classic 'Dev deploys to production at 5:00PM on a Friday, and goes home.' story.
The web department was managed under the the Marketing department, so they were not required to adhere to any type of coding standards and for months we fought with them on logging. Pre-Splunk, we rolled our own logging/alerting solution and they hated being the #1 reason for phone calls/texts/emails every night.
Wanting to "get it done", 'Tony' decided to bypass the default logging and send himself an email if an exception occurred in his code.
At 5:00PM on a Friday, deploys, goes home.
Around 11:00AM on Sunday (a lot folks are still in church at this time), the VP of IS gets a call from the CEO (who does not go to church) about unable to log into his email. VP has to leave church..drive home and find out he cannot remote access the exchange server. He starts making other phone calls..forcing the entire networking department to drive in and get email back up (you can imagine not a group of happy people)
After some network-admin voodoo, by 12:00, they discover/fix the issue (know it was Tony's email that was the problem)
We find out Monday that not only did Tony deploy at 5:00 on a Friday, the deployment wasn't approved, had features no one asked for, wasn't checked into version control, and the exception during checkout cost the company over $50,000 in lost sales.
Was Tony fired? Noooo. The web is our cash cow and Tony was considered a top web developer (and he knew that), Tony decided to blame logging. While in the discovery meeting, Tony told the bosses that it wasn't his fault logging was so buggy and caused so many phone calls/texts/emails every night, if he had been trained properly, this problem could have been avoided.
Well, since I was responsible for logging, I was next in the hot seat.
For almost 30 minutes I listened to every terrible thing I had done to Tony ever since he started. I was a terrible mentor, I was mean, I was degrading, etc..etc.
Me: "Where is this coming from? I barely know Tony. We're not even in the same building. I met him once when he started, maybe saw him a couple of times in meetings."
Andrew: "Aren't you responsible for this logging fiasco?"
Me: "Good Lord no, why am I here?"
Andrew: "I'll rephrase so you'll understand, aren't you are responsible for the proper training of how developers log errors in their code? This disaster is clearly a consequence of your failure. What do you have to say for yourself?"
Me: "Nothing. Developers are responsible for their own choices. Tony made the choice to bypass our logging and send errors to himself, causing Exchange to lockup and losing sales."
Andrew: "A choice he made because he was not properly informed of the consequences? Again, that is a failure in the proper use of logging, and why you are here."
Me: "I'm done with this. Does John know I'm in here? How about you get John and you talk to him like that."
'John' was the department head at the time.
Andrew:"John, have you spoken to Tony?"
John: "Yes, and I'm very sorry and very disappointed. This won't happen again."
Me: "Um...What?"
John: "You know what. Did you even fucking talk to Tony? You just sit in your ivory tower and think your actions don't matter?"
Me: "Whoa!! What are you talking about!? My responsibility for logging stops with the work instructions. After that if Tony decides to do something else, that is on him."
John: "That is not how Tony tells it. He said he's been struggling with your logging system everyday since he's started and you've done nothing to help. This behavior ends today. We're a fucking team. Get off your damn high horse and help the little guy every once in a while."
Me: "I don't know what Tony has been telling you, but I barely know the guy. If he has been having trouble with the one line of code to log, this is the first I've heard of it."
John: "Like I said, this ends today. You are going to come up with a proper training class and learn to get out and talk to other people."
Over the next couple of weeks I become a powerpoint wizard and 'train' anyone/everyone on the proper use of logging. The one line of code to log. One line of code.
A friend 'Scott' sits close to Tony (I mean I do get out and know people) told me that Tony poured out the crocodile tears. Like cried and cried, apologizing, calling me everything but a kitchen sink,...etc. It was so bad, his manager 'Sally' was crying, her boss 'Andrew', was red in the face, when 'John' heard 'Sally' was crying, you can imagine the high levels of alpha-male 'gotta look like I'm protecting the females' hormones flowing.
Took almost another year, Tony released a change on a Friday, went home, web site crashed (losses were in the thousands of $ per minute this time), and Tony was not let back into the building on Monday (one of the best days of my life).10 -
Worst dev team failure I've experienced?
One of several.
Around 2012, a team of devs were tasked to convert a ASPX service to WCF that had one responsibility, returning product data (description, price, availability, etc...simple stuff)
No complex searching, just pass the ID, you get the response.
I was the original developer of the ASPX service, which API was an XML request and returned an XML response. The 'powers-that-be' decided anything XML was evil and had to be purged from the planet. If this thought bubble popped up over your head "Wait a sec...doesn't WCF transmit everything via SOAP, which is XML?", yes, but in their minds SOAP wasn't XML. That's not the worst WTF of this story.
The team, 3 developers, 2 DBAs, network administrators, several web developers, worked on the conversion for about 9 months using the Waterfall method (3~5 months was mostly in meetings and very basic prototyping) and using a test-first approach (their own flavor of TDD). The 'go live' day was to occur at 3:00AM and mandatory that nearly the entire department be on-sight (including the department VP) and available to help troubleshoot any system issues.
3:00AM - Teams start their deployments
3:05AM - Thousands and thousands of errors from all kinds of sources (web exceptions, database exceptions, server exceptions, etc), site goes down, teams roll everything back.
3:30AM - The primary developer remembered he made a last minute change to a stored procedure parameter that hadn't been pushed to production, which caused a side-affect across several layers of their stack.
4:00AM - The developer found his bug, but the manager decided it would be better if everyone went home and get a fresh look at the problem at 8:00AM (yes, he expected everyone to be back in the office at 8:00AM).
About a month later, the team scheduled another 3:00AM deployment (VP was present again), confident that introducing mocking into their testing pipeline would fix any database related errors.
3:00AM - Team starts their deployments.
3:30AM - No major errors, things seem to be going well. High fives, cheers..manager tells everyone to head home.
3:35AM - Site crashes, like white page, no response from the servers kind of crash. Resetting IIS on the servers works, but only for around 10 minutes or so.
4:00AM - Team rolls back, manager is clearly pissed at this point, "Nobody is going fucking home until we figure this out!!"
6:00AM - Diagnostics found the WCF client was causing the server to run out of resources, with a mix of clogging up server bandwidth, and a sprinkle of N+1 scaling problem. Manager lets everyone go home, but be back in the office at 8:00AM to develop a plan so this *never* happens again.
About 2 months later, a 'real' development+integration environment (previously, any+all integration tests were on the developer's machine) and the team scheduled a 6:00AM deployment, but at a much, much smaller scale with just the 3 development team members.
Why? Because the manager 'froze' changes to the ASPX service, the web team still needed various enhancements, so they bypassed the service (not using the ASPX service at all) and wrote their own SQL scripts that hit the database directly and utilized AppFabric/Velocity caching to allow the site to scale. There were only a couple client application using the ASPX service that needed to be converted, so deploying at 6:00AM gave everyone a couple of hours before users got into the office. Service deployed, worked like a champ.
A week later the VP schedules a celebration for the successful migration to WCF. Pizza, cake, the works. The 3 team members received awards (and a envelope, which probably equaled some $$$) and the entire team received a custom Benchmade pocket knife to remember this project's success. Myself and several others just stared at each other, not knowing what to say.
Later, my manager pulls several of us into a conference room
Me: "What the hell? This is one of the biggest failures I've been apart of. We got rewarded for thousands and thousands of dollars of wasted time."
<others expressed the same and expletive sediments>
Mgr: "I know..I know...but that's the story we have to stick with. If the company realizes what a fucking mess this is, we could all be fired."
Me: "What?!! All of us?!"
Mgr: "Well, shit rolls downhill. Dept-Mgr-John is ready to fire anyone he felt could make him look bad, which is why I pulled you guys in here. The other sheep out there will go along with anything he says and more than happy to throw you under the bus. Keep your head down until this blows over. Say nothing."11 -
Worst hack/attack I had to deal with?
Worst, or funniest. A partnership with a Canadian company got turned upside down and our company decided to 'part ways' by simply not returning his phone calls/emails, etc. A big 'jerk move' IMO, but all I was responsible for was a web portal into our system (submitting orders, inventory, etc).
After the separation, I removed the login permissions, but the ex-partner system was set up to 'ping' our site for various updates and we were logging the failed login attempts, maybe 5 a day or so. Our network admin got tired of seeing that error in his logs and reached out to the VP (responsible for the 'break up') and requested he tell the partner their system is still trying to login and stop it. Couple of days later, we were getting random 300, 500, 1000 failed login attempts (causing automated emails to notify that there was a problem). The partner knew that we were likely getting alerted, and kept up the barage. When alerts get high enough, they are sent to the IT-VP, which gets a whole bunch of people involved.
VP-Marketing: "Why are you allowing them into our system?! Cut them off, NOW!"
Me: "I'm not letting them in, I'm stopping them, hence the login error."
VP-Marketing: "That jackass said he will keep trying to get into our system unless we pay him $10,000. Just turn those machines off!"
VP-IT : "We can't. They serve our other international partners."
<slams hand on table>
VP-Marketing: "I don't fucking believe this! How the fuck did you let this happen!?"
VP-IT: "Yes, you shouldn't have allowed the partner into our system to begin with. What are you going to do to fix this situation?"
Me: "Um, we've been testing for months already went live some time ago. I didn't know you defaulted on the contract until last week. 'Jake' is likely running a script. He'll get bored of doing that and in a couple of weeks, he'll stop. I say lets ignore him. This really a network problem, not a coding problem."
IT-MGR: "Now..now...lets not make excuses and point fingers. It's time to fix your code."
IT-VP: "I agree. We're not going to let anyone blackmail us. Make it happen."
So I figure out the partner's IP address, and hard-code the value in my service so it doesn't log the login failure (if IP = '10.50.etc and so on' major hack job). That worked for a couple of days, then (I suspect) the ISP re-assigned a new IP and the errors started up again.
After a few angry emails from the 'powers-that-be', our network admin stops by my desk.
D: "Dude, I'm sorry, I've been so busy. I just heard and I wished they had told me what was going on. I'm going to block his entire domain and send a request to the ISP to shut him down. This was my problem to fix, you should have never been involved."
After 'D' worked his mojo, the errors stopped.
Month later, 'D' gave me an update. He was still logging the traffic from the partner's system (the ISP wanted extensive logs to prove the customer was abusing their service) and like magic one day, it all stopped. ~2 weeks after the 'break up'.8 -
I've found and fixed any kind of "bad bug" I can think of over my career from allowing negative financial transfers to weird platform specific behaviour, here are a few of the more interesting ones that come to mind...
#1 - Most expensive lesson learned
Almost 10 years ago (while learning to code) I wrote a loyalty card system that ended up going national. Fast forward 2 years and by some miracle the system still worked and had services running on 500+ POS servers in large retail stores uploading thousands of transactions each second - due to this increased traffic to stay ahead of any trouble we decided to add a loadbalancer to our backend.
This was simply a matter of re-assigning the IP and would cause 10-15 minutes of downtime (for the first time ever), we made the switch and everything seemed perfect. Too perfect...
After 10 minutes every phone in the office started going beserk - calls where coming in about store servers irreparably crashing all over the country taking all the tills offline and forcing them to close doors midday. It was bad and we couldn't conceive how it could possibly be us or our software to blame.
Turns out we made the local service write any web service errors to a log file upon failure for debugging purposes before retrying - a perfectly sensible thing to do if I hadn't forgotten to check the size of or clear the log file. In about 15 minutes of downtime each stores error log proceeded to grow and consume every available byte of HD space before crashing windows.
#2 - Hardest to find
This was a true "Nessie" bug.. We had a single codebase powering a few hundred sites. Every now and then at some point the web server would spontaneously die and vommit a bunch of sql statements and sensitive data back to the user causing huge concern but I could never remotely replicate the behaviour - until 4 years later it happened to one of our support staff and I could pull out their network & session info.
Turns out years back when the server was first setup each domain was added as an individual "Site" on IIS but shared the same root directory and hence the same session path. It would have remained unnoticed if we had not grown but as our traffic increased ever so often 2 users of different sites would end up sharing a session id causing the server to promptly implode on itself.
#3 - Most elegant fix
Same bastard IIS server as #2. Codebase was the most unsecure unstable travesty I've ever worked with - sql injection vuns in EVERY URL, sql statements stored in COOKIES... this thing was irreparably fucked up but had to stay online until it could be replaced. Basically every other day it got hit by bots ended up sending bluepill spam or mining shitcoin and I would simply delete the instance and recreate it in a semi un-compromised state which was an acceptable solution for the business for uptime... until we we're DDOS'ed for 5 days straight.
My hands were tied and there was no way to mitigate it except for stopping individual sites as they came under attack and starting them after it subsided... (for some reason they seemed to be targeting by domain instead of ip). After 3 days of doing this manually I was given the go ahead to use any resources necessary to make it stop and especially since it was IIS6 I had no fucking clue where to start.
So I stuck to what I knew and deployed a $5 vm running an Nginx reverse proxy with heavy caching and rate limiting linked to a custom fail2ban plugin in in front of the insecure server. The attacks died instantly, the server sped up 10x and was never compromised by bots again (presumably since they got back a linux user agent). To this day I marvel at this miracle $5 fix.1 -
Update to my "I broke prod" rant:
- I managed to unfuck it on the same evening.
- Worked fine for one day
- Crashed today morning
- Can't fix it because I had surgery yesterday and am on sick leave currently
=> Probably gonna result in me VPNing into the comp network and RDPing into the prod instance to analyse the failure
Yep, ladies and gents, more open heart surgery on the menu!8 -
Fucking facebook researcher that make underfitted neural nets and fuck Mark that it's a marketing genius, the only idiot that can make news from a failure. The CEO of Tesla knows it and said Mark is not an AI expert. Bug not feature, it's only a poorly trained and poorly designed neural network having a bad representation of concepts, not a new language and not the fucking apocalypse. Google faced and solved the same issue when start ed using neural nets for zero-shot translations without using english as a translation bridge.
-
We should not tolerate censorship.
Beyond all the u.s. hype over elections
(and the division in the west in general), the real story is all the censorship on both sides.
Reasonable voices are quickly banned, while violent voices and loud angry people are amplified.
I broke out of the left-right illusion when
I realized what this was all about. Why
so much fighting in the street was allowed, both
justified and unjustified. Why so much hate
and division and slander, and back and forth
was allowed to be spread.
It's problem, reaction, solution.
The old order of liberal democracy, represented
in the u.s. by the facade of the GOP and DNC,
doesn't know how to handle the free *distributed*
flow of information.
That free-flow of information has caused us to
transition to a *participatory* democracy, where
*networks* are the lever of power, rather than
top down institutions.
Consequently, the power in the *new era* is
to decide, not what the *narrative* is, but
who can even *participate*, in spreading,
ideating, and sharing their opinions on that
narrative, and more broadly, who is even allowed
to participate in society itself.
The u.s. and west wants the chinese model of
control in america. you are part of a network, a
collective, through services and software, and
you can be shut off from *society* itself at
the drop of a pin.
The only way they get that is by creating a crisis,
outright fighting in the streets. Thats why
people keep being released after committing serious
fucking crimes. It's why the DOJ and FBI are
intent on letting both sides people walk.
They want them at each others literal throat,
calling for each other's blood. All so they
can step back and then step in the middle when
the chorus for change cries out loud enough.
And the answer will be
1. regulated tech
2. an end to television media as we know it
3. the ability to shut someone off from any service on a dime
4. new hatespeech laws that will bite *all* sides in the ass.
5. the ability to shape the narrative of society by simply 'pruning' networks as they see fit, limiting the reach of individuals on all sides, who are problematic to
the collective direction.
I was so caught up in the illusion of us-vs-them I didn't
see it before now. This is a monstrous power grab.
And instead of focusing on a farce of election, where the party *organizations* involved are institutional facades for industrialists, we should be focusing on the real issue:
* Failure of law to do its job online, especially failures of slander and libel laws, failures of laws against conspiracy to commit crime or assault
* New laws that offer injunctive relief against censorship, now that tech really is the commons. Because whats worse than someone online whipping up a mob on either side, is
someone who is innocent being *silenced* for disagreeing with something someone in authority said, or for questioning a politician, party, or corporation.
* Very serious felony level laws against doxxing and harassment on all sides, with retroactive application of said laws because theres a lot of people on all sides who won't be satisfied with the outcome until people who are guilty are brought to justice.16 -
*laughing maniacally*
Okidoky you lil fucker where you've been hiding...
*streaming tcpdump via SSH to other box, feeding tshark with input filters*
Finally finding a request with an ominous dissector warning about headers...
Not finding anything with silversearcher / ag in the project...
*getting even more pissed causr I've been looking for lil fucker since 2 days*
*generating possible splits of the header name, piping to silversearcher*
*I/O looks like clusterfuck*
Common, it are just dozen gigabytes of text, don't choke just because you have to suck on all the sucking projects this company owns... Don't drown now, lil bukkake princess.
*half an hour later*
Oh... Interesting. Bukkake princess survived and even spilled the tea.
Someone was trying to be overly "eager" to avoid magic numbers...
They concatenated a header name out of several const vars which stem from a static class with like... 300? 400? vars of which I can make no fucking sense at all.
Class literally looks like the most braindamaged thing one could imagine.
And yes... Coming back to the network error I'm debugging since 2 days as it is occuring at erratic intervals and noone knew of course why...
One of the devs changed the const value of one of the variables to have UTF 8 characters. For "cleaner meaning".
Sometimes I just want to electrocute people ...
The reason this didn't pop up all the time was because the test system triggered one call with the header - whenever said dev pushed changes...
And yeah. Test failures can be ignored.
Why bother? Just continue meddling in shit.
I'm glad for the dev that I'm in home office... :@
TLDR: Dev changed const value without thinking, ignoring test failures and I had the fun of debunking for 2 days a mysterious HAProxy failure due to HTTP header validation... -
My desktop pc is suddenly having issues connecting to my home WiFi network, every few minutes it just stops having an internet connection while not showing anything out of the ordinary.
I finally have time to work on some side projects and now THIS happens, weirdly enough it's also just this network, my hotspot seems to work fine.
Now I have a watcher on to keep systemctl restarting the networkmanager, why can stuff just not work for once ? ;_;
I've had this issue since a few months but the failure interval has never been this bad. usually it was just one restart a day
Time to look up the linux mint forums again2 -
Finish a client project, with Laravel 5. Got a hang with the features and for once felt like I am "there" . nothing can beat me. then client request for the network to have no single point of failure.
I am like "whuttttt" how do I even replicate database and have fail over on it.1 -
I don't know about your country but this feature is novel among Nigeria's financial institutions. What usually happens in a typical bank app is same as above: fields are provided for entering account details. There is no way to know the outcome of the transfer until it's made. If it fails in transit (often, you're debited but the recipient gets nothing), you might get a reversal if you're lucky, after an indefinite period of time. Otherwise, you have to take it up with your bank or the recipient's bank. Or worse, with the central bank, when the first two are not being helpful enough
Enter this new generation fintech (Opay). They offer an addition that impresses all customers: after selecting the bank, a popup appears that notifies you on the stability of the receiver's network. Someone sent me this screenshot seeking my permission or provision of another bank. I didn't think much of it and asked them to proceed. To my surprise, transaction failed and their money instantly reversed
Those traditional banks clearly have no api for health checks, otherwise they'd all adopt it within their own apps. So, how is this possible? My only guess is that Opay maintains their own health checks system that is updated maybe by periodically pinging those banks with nominal fees like N1 and verifying whether money was received
It's obviously primitive but I doubt traditional bank apis return a failure response (since none currently tells you when transaction failed). So you'd have to rely on workarounds emulating manual and automated testing
To those in the fintech sector or with a faint idea of what's going on, can you explain?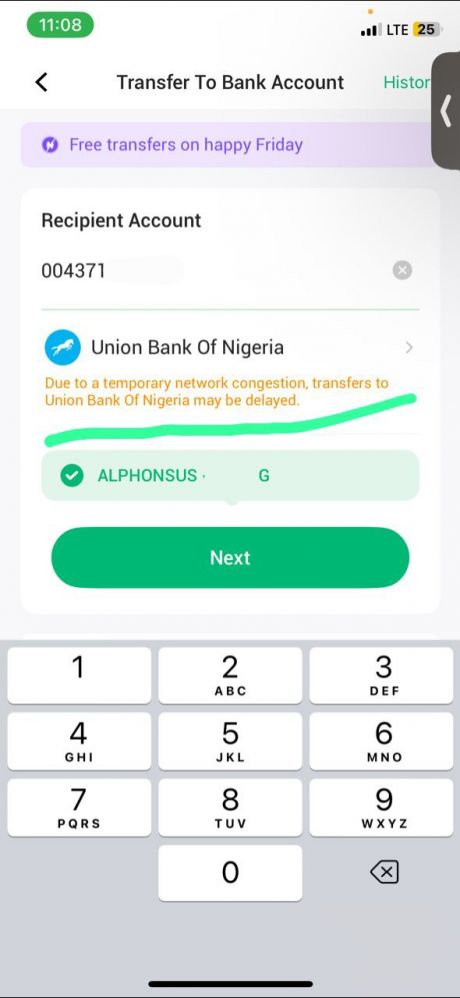 7
7













Top Tags
Weekly Rant
View