
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Hey everyone,
First off, a Merry Christmas to everyone who celebrates, happy holidays to everyone, and happy almost-new-year!
Tim and I are very happy with the year devRant has had, and thinking back, there are a lot of 2017 highlights to recap. Here are just a few of the ones that come to mind (this list is not exhaustive and I'm definitley forgetting stuff!):
- We introduced the devRant supporter program (devRant++)! (https://devrant.com/rants/638594/...). Thank you so much to everyone who has embraced devRant++! This program has helped us significantly and it's made it possible for us to mantain our current infrustructure and not have to cut down on servers/sacrifice app performance and stability.
- We added avatar pets (https://devrant.com/rants/455860/...)
- We finally got the domain devrant.com thanks to @wiardvanrij (https://devrant.com/rants/938509/...)
- The first international devRant meetup (Dutch) with organized by @linuxxx and was a huge success (https://devrant.com/rants/937319/... + https://devrant.com/rants/935713/...)
- We reached 50,000 downloads on Android (https://devrant.com/rants/728421/...)
- We introduced notif tabs (https://devrant.com/rants/1037456/...), which make it easy to filter your in-app notifications by type
- @AlexDeLarge became the first devRant user to hit 50,000++ (https://devrant.com/rants/885432/...), and @linuxxx became the first to hit 75,000++
- We made an April Fools joke that got a lot of people mad at us and hopefully got some laughs too (https://devrant.com/rants/506740/...)
- We launched devDucks!! (https://devducks.com)
- We got rid of the drawer menu in our mobile apps and switched to a tab layout
- We added the ability to subscribe to any user's rants (https://devrant.com/rants/538170/...)
- Introduced the post type selector (https://devrant.com/rants/850978/...) (which will be used for filtering - more details below)
- Started a bug/feature tracker GitHub repo (https://github.com/devRant/devRant)
- We did our first ever live stream (https://youtube.com/watch/...)
- Added an awesome all-black theme (devRant++) (https://devrant.com/rants/850978/...)
- We created an "active discussions" screen within the app so you can easily find rants with booming discussions!
- Thanks to the suggestion of many community members, we added "scroll to bottom" functionality to rants with long comment threads to make those rants more usable
- We improved our app stability and set our personal record for uptime, and we also cut request times in half with some database cluster upgrades
- Awesome new community projects: https://devrant.com/projects (more will be added to the list soon, sorry for the delay!)
- A new landing page for web (https://devrant.com), that was the first phase of our web overhaul coming soon (see below)
Even after all of this stuff, Tim and I both know there is a ton of work to do going forward and we want to continue to make devRant as good as it can be. We rely on your feedback to make that happen and we encourage everyone to keep submitting and discussing ideas in the bug/feature tracker (https://github.com/devRant/devRant).
We only have a little bit of the roadmap right now, but here's some things 2018 will bring:
- A brand new devRant web app: we've heard the feedback loud and clear. This is our top priority right now, and we're happy to say the completely redesigned/overhauled devRant web experience is almost done and will be released in early 2018. We think everyone will really like it.
- Functionality to filter rants by type: this feature was always planned since we introduced notif types, and it will soon be implemented. The notif type filter will allow you to select the types of rants you want to see for any of the sorting methods.
- App stability and usability: we want to dedicate a little time to making sure we don't forget to fix some long-standing bugs with our iOS/Android apps. This includes UI issues, push notification problems on Android, any many other small but annoying problems. We know the stability and usability of devRant is very important to the community, so it's important for us to give it the attention it deserves.
- Improved profiles/avatars: we can't reveal a ton here yet, but we've got some pretty cool ideas that we think everyone will enjoy.
- Private messaging: we think a PM system can add a lot to the app and make it much more intuitive to reach out to people privately. However, Tim and I believe in only launching carefully developed features, so rest assured that a lot of thought will be going into the system to maximize privacy, provide settings that make it easy to turn off, and provide security features that make it very difficult for abuse to take place. We're also open to any ideas here, so just let us know what you might be thinking.
There will be many more additions, but those are just a few we have in mind right now.
We've had a great year, and we really can't thank every member of the devRant community enough. We've always gotten amazingly positive feedback from the community, and we really do appreciate it. One of the most awesome things is when some compliments the kindness of the devRant community itself, which we hear a lot. It really is such a welcoming community and we love seeing devs of all kind and geographic locations welcomed with open arms.
2018 will be an important year for devRant as we continue to grow and we will need to continue the momentum. We think the ideas we have right now and the ones that will come from community feedback going forward will allow us to make this a big year and continue to improve the devRant community.
Thanks everyone, and thanks for your amazing contributions to the devRant community!
Looking forward to 2018,
- David and Tim 45
45 -
New devRant feature! Filtering by post type! This took a bit longer to get out than we had planned, but now that extra click to label a post type will be put to good use! Hate memes but love rants? Want to only see questions? Don't want to see random off-topic posts? Filter away!
We're pushing to Android now, iOS shortly, and web will be coming soon. 40
40 -
//
// devRant unofficial UWP update (v2.0.0-beta)
//
After several concepts, about 11 months of development (keep in mind that I released 20 updates for v1 in the meantime, so it wasn't a continous 11 months long development process) and a short closed beta phase, v2 is now available for everyone (as public beta)! :)
I tried to improve the app in every aspect, from finally responsive and good looking UI on Desktop version to backend performance improvements, which means that I almost coded it from scratch.
There are also of course a few new features (like "go to bottom" in rants), and more to come.
It's a very huge update, and unfortunately to move forward, improve the UI (add Fluent Design) and make it at the same level of new UWP apps, I was forced to drop the supported for these old Windows 10 builds:
- Threshold 1 (10240)
- Threshold 2 (10586)
Too many incompatiblity issues with the new UI, and for 1 person with a lot of other commitments outside this project (made for free, just for passion), it's impossible to work at 3 parallel versions of the same app.
I already done something like that during these 11 months (every single of the 20 updates for v1 needed to be implemented a second time for v2).
During the closed beta tests, thanks to the awesome testers who helped me way too much than I ever wished, I found out that there are already incompatiblity issues with Anniversary Update, which means that I will support two versions:
1) One for Creators Update and newer builds.
2) One for Anniversary Update (same features, but missing Fluent Design since it doesn't work on that OS version, and almost completly rewritten XAML styles).
For this reason v2 public beta is out now for Creators Update (and newer) as regular update, and will be out in a near future (can't say when) also for the Anniversary Update.
The users with older OS versions (problem which on PC could be solved in 1-2 days, just download updates) can download only the v1.5.9 (which probably won't be supported with new updates anymore, except for particular critcal bug fixes).
So if you have Windows 10 on PC and want to use v2 today, just be sure you have Creators Update or Fall Creators Update.
If you have Windows 10 PC with Anniversary Update, update it, or if you don't want to do that, wait a few weeks/months for the update with support for your build.
If you have an older version on PC, update it, or enjoy v1.5.9.
If you have Windows 10 Mobile Anniversary Update, update it (if it's possible for your device), or just wait a few weeks/months for the update with support for your build.
If you have Windows 10 Mobile, and because of Microsoft stupid policy, you can't update to Anniversary Update, enjoy v1.5.9, or try the "unofficial" method (registry hack) to update to a newer build.
I hope it's enough clear why not everyone can receive the update today, or at all. :P
Now I would like to thank a few people who made this possible.
As always, @dfox who is always available for help me with API implementations.
@thmnmlist, who helped me a lot during this period with really great UI suggestions (just check out his twitter, it's a really good person, friend, designer and artist: https://twitter.com/thmnmlist).
And of course everyone of the closed beta testers, that reported bugs and precious suggestions (some of them already implemented, others will arrive soon).
The order is random:
@Raamakrishnan
@Telescuffle
@Qaldim
@thmnmlist
@nikola1402
@aayusharyan
@cozyplanes
@Vivaed
@Byte
@RTRMS
@tylerleonhardt
@Seshpengiun
@MEGADROID
@nottoobright
Changelog of v2.0.0-beta:
- New UI with Fluent Design and huge improvements for Desktop;
- Added native support for Fall Creators Update (Build 16299);
- Changed minimum supported version to Creators Update (Build 15063), support for Anniversary Update (Build 14393) will arrive soon;
- Added mouse support for Pull-To-Refresh;
- Added ability to change your username and email;
- Added ability to filter (by 'Day', 'Week', 'Month' and 'All') the top Rants;
- Added ability to open rant links in-app;
- Added ability to zoom GIFs (just tap on them in the Rant View);
- Added 'go to bottom' button in the Rant View (if more than 3 comments);
- Added new theme ('Total Black');
- ...complete changelog in-app and on my website (can't post it here because of the 5000 characters limit)...
What will arrive in future updates:
- 'Active Discussions' screen so you can easily find rants that have recent comments/discussions;
- Support for 'Collabs';
- Push Notifications (it was postponed and announced too many times...);
- More themes and themes options;
- and more...
If you still didn't download devRant unofficial UWP, do it now: https://microsoft.com/store/apps/...
If you find some bugs or you have feature suggestion, post it on the Issue Tracker on GitHub (thanks in advance for your help!): https://github.com/JakubSteplowski/...
I hope you will enjoy it! ;) 52
52 -
In a user-interface design meeting over a regulatory compliance implementation:
User: “We’ll need to input a city.”
Dev: “Should we validate that city against the state, zip code, and country?”
User: “You are going to make me enter all that data? Ugh…then make it a drop-down. I select the city and the state, zip code auto-fill. I don’t want to make a mistake typing any of that data in.”
Me: “I don’t think a drop-down of every city in the US is feasible.”
Manage: “Why? There cannot be that many. Drop-down is fine. What about the button? We have a few icons to choose from…”
Me: “Uh..yea…there are thousands of cities in the US. Way too much data to for anyone to realistically scroll through”
Dev: “They won’t have to scroll, I’ll filter the list when they start typing.”
Me: “That’s not really the issue and if they are typing the city anyway, just let them type it in.”
User: “What if I mistype Ch1cago? We could inadvertently be out of compliance. The system should never open the company up for federal lawsuits”
Me: “If we’re hiring individuals responsible for legal compliance who can’t spell Chicago, we should be sued by the federal government. We should validate the data the best we can, but it is ultimately your department’s responsibility for data accuracy.”
Manager: “Now now…it’s all our responsibility. What is wrong with a few thousand item drop-down?”
Me: “Um, memory, network bandwidth, database storage, who maintains this list of cities? A lot of time and resources could be saved by simply paying attention.”
Manager: “Memory? Well, memory is cheap. If the workstation needs more memory, we’ll add more”
Dev: “Creating a drop-down is easy and selecting thousands of rows from the database should be fast enough. If the selection is slow, I’ll put it in a thread.”
DBA: “Table won’t be that big and won’t take up much disk space. We’ll need to setup stored procedures, and data import jobs from somewhere to maintain the data. New cities, name changes, ect. ”
Manager: “And if the network starts becoming too slow, we’ll have the Networking dept. open up the valves.”
Me: “Am I the only one seeing all the moving parts we’re introducing just to keep someone from misspelling ‘Chicago’? I’ll admit I’m wrong or maybe I’m not looking at the problem correctly. The point of redesigning the compliance system is to make it simpler, not more complex.”
Manager: “I’m missing the point to why we’re still talking about this. Decision has been made. Drop-down of all cities in the US. Moving on to the button’s icon ..”
Me: “Where is the list of cities going to come from?”
<few seconds of silence>
Dev: “Post office I guess.”
Me: “You guess?…OK…Who is going to manage this list of cities? The manager responsible for regulations?”
User: “Thousands of cities? Oh no …no one is our area has time for that. The system should do it”
Me: “OK, the system. That falls on the DBA. Are you going to be responsible for keeping the data accurate? What is going to audit the cities to make sure the names are properly named and associated with the correct state?”
DBA: “Uh..I don’t know…um…I can set up a job to run every night”
Me: “A job to do what? Validate the data against what?”
Manager: “Do you have a point? No one said it would be easy and all of those details can be answered later.”
Me: “Almost done, and this should be easy. How many cities do we currently have to maintain compliance?”
User: “Maybe 4 or 5. Not many. Regulations are mostly on a state level.”
Me: “When was the last time we created a new city compliance?”
User: “Maybe, 8 years ago. It was before I started.”
Me: “So we’re creating all this complexity for data that, realistically, probably won’t ever change?”
User: “Oh crap, you’re right. What the hell was I thinking…Scratch the drop-down idea. I doubt we’re have a new city regulation anytime soon and how hard is it to type in a city?”
Manager: “OK, are we done wasting everyone’s time on this? No drop-down of cities...next …Let’s get back to the button’s icon …”
Simplicity 1, complexity 0.16 -
Basically finished the notification filter script* already, but there's still some small bugs I want to get to first, so in the meanwhile I created a "subscribe" button script**, that simply posts a pin emoji and "Subscribing to the comments".
On desktop I usually used to post a dot to subscribe to rant comments, but with the new people wave, that was often misunderstood (you emoji users won the evolution of comment subscribing, RIP dot) I'm sure some other people that use the webapp more often, will find it useful too.
* notification filter: https://devrant.com/rants/1424435/...
** subscribe button: https://github.com/7twin/... 17
17 -
Fuck brand builders, or, how I learned to start giving a shit and love devrant.
Brand builders are people who generally have very little experience and are attempting to obfuscate their dearth of ability behind a wall of non-academic content generation. Subscribe, like, build a following and everyone will happily overlook the fact that your primary contribution to society is spreading facile content that further obfuscates the need for fundamentals. Their carefully crafted presence is designed promote themselves and their success while chipping away at the apparent value of professional ability. At one point, I thought medium would be the bottom of the barrel; a glorified blog that provides people with scant knowledge, little experience and routinely low integrity a platform to build an echo chamber of replayed or copied content, techno-mysticism and best-practice-superstition they mistake for a brand in an environment where there's little chance of peer review. I thought it couldn't get any worse.
Then I found dev.to
Dev.to is what happens when all the absence of ability and skills insecurity on the internet gets together to form a censorship mob to ensure that no criticism, reality or peer review will ever filter into the ramblings of people intent on forever remaining at the peak of the dunning-kreuger curve. It's the long tail of YMCA trophy culture.
Take for example this article:
https://dev.to/davidepacilio/...
It's a shit post listicle by someone claiming to be "senior," who confidently states that "you are only as good as the tools you use." Meanwhile all the great minds of history are giving him the side-eye because they understand tools are just a magnifier of ability. If you're an amazing carpenter, power tools will help you produce at an exponential rate. If you're a shitty carpenter, your work will still be shit, there will just be more of it. The actual phrase that's being butchered here is "you're only as good as the tools you create." There's no moral superiority to be had in being dependent on a tool, that's just a crutch. A true expert or professional is someone who can create tools to aid in their craft. Being a professional is having a thorough enough understanding of the thing you are doing so as to be able to craft force multipliers that make your work easier, not just someone who uses them.
Ok, so what?
I'm sure he's a plenty fine human to grab drinks with, no ill will to him as a human. That said, were you to comment something to that effect on dev.to, you'd be reported by all the hangers-on pretty much immediately, regardless of how much complimentary padding and passive, welcoming language you wrap your message in. The problem with a bunch of weak people ganging up on the voice of reason and deciding they don't want things like constructive criticism, peer review, academic process or the scientific method is, after you remove all of that, you're just left with a formless sea of ideas and thoughts with no categorization, no order. You find a lot of opinions and nothing to challenge them and thereby are left with no mechanism for strong ideas to rise to the top. In that system, the "correct" ideas are by default those posited by the strongest personality.
We all need some degree of positive reinforcement. We also need to be smacked upside the head when we're totally off in the weeds. It's all about balance. The forums of ancient Greece weren't filled with people fervently agreeing with one another and shouting down new ideas en masse. We need discourse, not demagoguery.
Dev.to, medium, etc are all the fast fashion of the tech industry. Personally, I'd prefer something designed to last a little longer.25 -
Time to make a deal with the devil
@theabbie since you love downloading the entire devRant db and writing little gimmicks, I have an idea for you.
Avatars are envcoded as URLs. Each part of an avatar is separated by an underscore. Shirt, pants, desk, whatever.
Make a bot or script or website or what-fucking-ever to query users with the same avatar as you. This would be:
- Same EXACT avatar (desk, pets, etc)
- Same body parts as you (face, skin color, hair, etc)
- Same body parts and clothing (everything that shows in the mini avatar next to comments, plus pants and shoes, I guess)
The doppelganger finder. Honestly I think it would be neat.
Would be even cooler if you could filter by active users (last post/comment within past 3 months)33 -
This begs for a rant... [too bad I can't post actual screenshots :/ ]
Me: He k8s team! We're having trouble with our k8s cluster. After scaling up and running h/c and Sanity tests environment was confirmed as Healthy and Stable. But once we'd started our load tests k8s cluster went out for a walk: most of the replicas got stoped and restarted and I cannot find in events' log WHY that happened. Could you please have a look?
k8s team [india]: Hello, thank you for reaching out to k8s support. We will check and let you know.
Me: Oh, you're welcome! I'll be just sitting here quietly and eagerly waiting for your reply. TIA! :slightly_smiling_face:
<5 minutes later>
k8s team India: Hi. Could you give me a list of replicas that were failing?
Me: I gave you a Grafana link with a timeframe filter. Look there -- almost all apps show instability at k8s layer. For instance APP_1 and APP_2 were OK. But APP_3, APP_4 and APP_5 were crashing all over the place
k8s team India: ok I will check.
<My shift has ended. k8s team works in different timezone. I've opened up Slack this morning>
k8s team India: HI. APP_1 and APP_2 are fine. I don't even see any errors from logs, no restarts. All response codes are 200.
Me: 🤦♂️ .... Man, isn't that what I've said? ... 🤦♂️5 -
I wrote a node + vue web app that consumes bing api and lets you block specific hosts with a click, and I have some thoughts I need to post somewhere.
My main motivation for this it is that the search results I've been getting with the big search engines are lacking a lot of quality. The SEO situation right now is very complex but the bottom line is that there is a lot of white hat SEO abuse.
Commercial companies are fucking up the internet very hard. Search results have become way too profit oriented thus unneutral. Personal blogs are becoming very rare. Information is losing quality and sites are losing identity. The internet is consollidating.
So, I decided to write something to help me give this situation the middle finger.
I wrote this because I consider the ability to block specific sites a basic universal right. If you were ripped off by a website or you just don't like it, then you should be able to block said site from your search results. It's not rocket science.
Google used to have this feature integrated but they removed it in 2013. They also had an extension that did this client side, but they removed it in 2018 too. We're years past the time where Google forgot their "Don't be evil" motto.
AFAIK, the only search engine on earth that lets you block sites is millionshort.com, but if you block too many sites, the performance degrades. And the company that runs it is a for profit too.
There is a third party extension that blocks sites called uBlacklist. The problem is that it only works on google. I wrote my app so as to escape google's tracking clutches, ads and their annoying products showing up in between my results.
But aside uBlacklist does the same thing as my app, including the limitation that this isn't an actual search engine, it's just filtering search results after they are generated.
This is far from ideal because filter results before the results are generated would be much more preferred.
But developing a search engine is prohibitively expensive to both index and rank pages for a single person. Which is sad, but can't do much about it.
I'm also thinking of implementing the ability promote certain sites, the opposite to blocking, so these promoted sites would get more priority within the results.
I guess I would have to move the promoted sites between all pages I fetched to the first page/s, but client side.
But this is suboptimal compared to having actual access to the rank algorithm, where you could promote sites in a smarter way, but again, I can't build a search engine by myself.
I'm using mongo to cache the results, so with a click of a button I can retrieve the results of a previous query without hitting bing. So far a couple of queries don't seem to bring much performance or space issues.
On using bing: bing is basically the only realiable API option I could find that was hobby cost worthy. Most microsoft products are usually my last choice.
Bing is giving me a 7 day free trial of their search API until I register a CC. They offer a free tier, but I'm not sure if that's only for these 7 days. Otherwise, I'm gonna need to pay like 5$.
Paying or not, having to use a CC to use this software I wrote sucks balls.
So far the usage of this app has resulted in me becoming more critical of sites and finding sites of better quality. I think overall it helps me to become a better programmer, all the while having better protection of my privacy.
One not upside is that I'm the only one curating myself, whereas I could benefit from other people that I trust own block/promote lists.
I will git push it somewhere at some point, but it does require some more work:
I would want to add a docker-compose script to make it easy to start, and I didn't write any tests unfortunately (I did use eslint for both apps, though).
The performance is not excellent (the app has not experienced blocks so far, but it does make the coolers spin after a bit) because the algorithms I wrote were very POC.
But it took me some time to write it, and I need to catch some breath.
There are other more open efforts that seem to be more ethical, but they are usually hard to use or just incomplete.
commoncrawl.org is a free index of the web. one problem I found is that it doesn't seem to index everything (for example, it doesn't seem to index the blog of a friend I know that has been writing for years and is indexed by google).
it also requires knowledge on reading warc files, which will surely require some time investment to learn.
it also seems kinda slow for responses,
it is also generated only once a month, and I would still have little idea on how to implement a pagerank algorithm, let alone code it.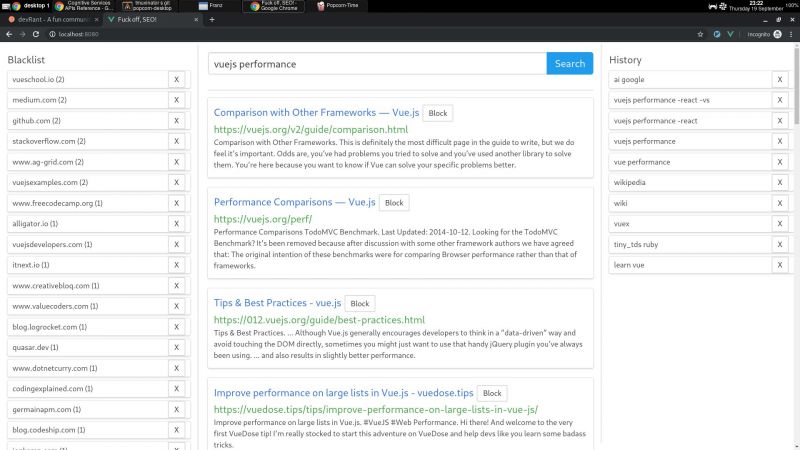 4
4 -
Two big moments today:
1. Holy hell, how did I ever get on without a proper debugger? Was debugging some old code by eye (following along and keeping track mentally, of what the variables should be and what each step did). That didn't work because the code isn't intuitive. Tried the print() method, old reliable as it were. Kinda worked but didn't give me enough fine-grain control.
Bit the bullet and installed Wing IDE for python. And bam, it hit me. How did I ever live without step-through, and breakpoints before now?
2. Remember that non-sieve prime generator I wrote a while back? (well maybe some of you do). The one that generated quasi lucas carmichael (QLC) numbers? Well thats what I managed to debug. I figured out why it wasn't working. Last time I released it, I included two core methods, genprimes() and nextPrime(). The first generates a list of primes accurately, up to some n, and only needs a small handful of QLC numbers filtered out after the fact (because the set of primes generated and the set of QLC numbers overlap. Well I think they call it an embedding, as in QLC is included in the series generated by genprimes, but not the converse, but I digress).
nextPrime() was supposed to take any arbitrary n above zero, and accurately return the nearest prime number above the argument. But for some reason when it started, it would return 2,3,5,6...but genprimes() would work fine for some reason.
So genprimes loops over an index, i, and tests it for primality. It begins by entering the loop, and doing "result = gffi(i)".
This calls into something a function that runs four tests on the argument passed to it. I won't go into detail here about what those are because I don't even remember how I came up with them (I'll make a separate post when the code is fully fixed).
If the number fails any of these tests then gffi would just return the value of i that was passed to it, unaltered. Otherwise, if it did pass all of them, it would return i+1.
And once back in genPrimes() we would check if the variable 'result' was greater than the loop index. And if it was, then it was either prime (comparatively plentiful) or a QLC number (comparatively rare)--these two types and no others.
nextPrime() was only taking n, and didn't have this index to compare to, so the prior steps in genprimes were acting as a filter that nextPrime() didn't have, while internally gffi() was returning not only primes, and QLCs, but also plenty of composite numbers.
Now *why* that last step in genPrimes() was filtering out all the composites, idk.
But now that I understand whats going on I can fix it and hypothetically it should be possible to enter a positive n of any size, and without additional primality checks (such as is done with sieves, where you have to check off multiples of n), get the nearest prime numbers. Of course I'm not familiar enough with prime number generation to know if thats an achievement or worthwhile mentioning, so if anyone *is* familiar, and how something like that holds up compared to other linear generators (O(n)?), I'd be interested to hear about it.
I also am working on filtering out the intersection of the sets (QLC numbers), which I'm pretty sure I figured out how to incorporate into the prime generator itself.
I also think it may be possible to generator primes even faster, using the carmichael numbers or related set--or even derive a function that maps one set of upper-and-lower bounds around a semiprime, and map those same bounds to carmichael numbers that act as the upper and lower bound numbers on the factors of a semiprime.
Meanwhile I'm also looking into testing the prime generator on a larger set of numbers (to make sure it doesn't fail at large values of n) and so I'm looking for more computing power if anyone has it on hand, or is willing to test it at sufficiently large bit lengths (512, 1024, etc).
Lastly, the earlier work I posted (linked below), I realized could be applied with ECM to greatly reduce the smallest factor of a large number.
If ECM, being one of the best methods available, only handles 50-60 digit numbers, & your factors are 70+ digits, then being able to transform your semiprime product into another product tree thats non-semiprime, with factors that ARE in range of ECM, and which *does* contain either of the original factors, means products that *were not* formally factorable by ECM, *could* be now.
That wouldn't have been possible though withput enormous help from many others such as hitko who took the time to explain the solution was a form of modular exponentiation, Fast-Nop who contributed on other threads, Voxera who did as well, and support from Scor in particular, and many others.
Thank you all. And more to come.
Links mentioned (because DR wouldn't accept them as they were):
https://pastebin.com/MWechZj912 -
I know being hostile to new users is not ok.
But have you seen the shit new users post? Who wants to be part of a community of simple minded and unexperienced idiots?
New users do it all: awful english, strawman, meme reposts, and now, advertising.
I wished there was a "above certain karma" filter, so I could avoid the trash.
But there's not, so the only tool I have is telling them their arguments are stupid.
I don't mind someone BEING a beginner. But as such I would expect them stfu a bit.16 -
1. Apply to as mant jobs as possible daily on dice/linkedin/indeed
using keyword resumes customized by scrapping
2. Filter out low-effort crap companies and filter out recruiters.
3. Post "dice/indeed/linkedin daily decrapified."
Tada! Fewer time-wasters during the job hunt.
4. Bonus: turn into a search engine.
5. Daily double round: turn crap listings and quality listings into AI training sets. Incorporate into search engine.
If industry can use bullshit hiring filters, we can use application filters!4 -
!(!(!(!rant)))
When you're using a sophisticated software and you've shown your work to your non-dev friends and they say "Wow! What APP did u use?"
Furk it! App sounds like a small icon on your mobile phone to take a selfie putting a dog filter to post for everyone to see! You call this tool just an "APP"? May Zeus forgive this blasphemy.
destroy(rant);11 -
Linux is shit, OSX and iOS are trash, windows is the only OS that actually works, open source is always inferior to closed source, if you use VPN or encryption youre a criminal, java is slow, vim worse than nano, ..
Now that I've got your attention and you probably raged and downvoted.
Downvotes don't actually work on devrant. (not a bug)
This has been going on for months already - why have that function to begin with, if its just not fucking working? The usual answer to people throwing a fit is "just downvote it", WHY? it doesnt fucking work.
For a while specific options while downvoting DID actually work, but now any of the downvote options are just straight trashed and ignored, they are saved, dont get me wrong (or else it would be too obvious), but they dont affect any of the scores at all.
I understand mass bot downvoting should be prevented, but why take away anyones voice by completely ignoring downvotes. I really dont get it, its not "punishing" the creator of said post or comment, its simply reflecting what the users actually think of said comment or post, it boils my blood how thats even a thing, I am honestly disappointed.
Why should also downvoting something hide it from the feed (especially on the "recent" filter), let me fucking decide what I want on my feed via option then atleast. What if I don't agree with a rant, downvote it, but then want to see what others thought of it? how am I supposed to find it again? 24
24 -
Silly and stupid me.
Woke up.
Check phone. Check devRant.
Saw Trogus's filter update post.
Happy and left a comment.
Went to playstore and update.
Open devRant and use the feature.
Tried to filter only Rants and Questions type.
Happy and went back to sleep again bcz Saturday.
Continue the rest of day with other stuffs.
Use devRant again.
"Huh why the heck is the first post about some random quote?"
"Why the hell is second post meme"
"Why...why...why"
Check filter feature again.
Facepalm.
Silly me and stupid my eyes and useless my brain is not worthy for good and clean UIUX.4 -
@Kiki and I built something (99.99% of the work was done by him only)
Since I was 6 month old, I was annoyed by Reddit's front page. While I liked how it remained same for everyone, there were a lot of unwanted subs filling the feed which didn't interest me and moreover were quite annoying.
Hence, I was thinking of a feature where we can filter out subs from the front page. I even made a post back in days and did not get a proper response.
I waited for Reddit to implement but they are just bloating the product now.
So night before yesterday, after I was done fantasising how I save the school from a terrorist attack, I got an idea.
A Chrome extension which can hide a list of subs or keywords we feed to it.
So if I add r/MakeMeSuffer to the list, extension should click on 'Hide' button on the post and it will no longer appear. Well this was the initial logic I had in mind.
I immediately pinged @Kiki and he was like he already has something similar. We experimented and with in an hour or two, he built an extension which worked better than I thought.
He implemented the dark theme as well. Kickasssss!!!!
So now we are here, to share with you and get your feedback on how we can improve this further.
Once the community responds to this, we are taking this to Product Hunt, Reddit, and @Kiki will also publish this on Chrome store.
We are really excited about this idea and many more. So let me know how you feel about this.
https://github.com/mvoloskov/hazmat
Incase you struggle with installation, HMU, after a lot of hand holding from the creator, I am now an expert in installing and managing Chrome extension 🤣🤣21 -
Go find the most cancerous Instagram page in the "coding community" and multiply it by 10.
Bonus points if they:
>>post vague and utter bullshit motivational captions with completely irrelevant pictures.
>>Have the word "entrepreneur" in their bio
>>Have emojis in their bio
>>Mention coffee in their bio
Oh and you know the shitty clean versions of songs that filter out anything that is slightly offensive words? (I recently heard a song that filtered the words "balls" and "vagina." Apparently anatomy is offensive to the snowflakes now.) That's gonna happen to our code. We're gonna have shitty censored versions that remove all "offensive" words.5 -
Whelp. I started making a very simple website with a single-page design, which I intended to use for managing my own personal knowledge on a particular subject matter, with some basic categorization features and a simple rich text editor for entering data. Partly as an exercise in web development, and partly due to not being happy with existing options out there. All was going well...
...and then feature creep happened. Now I have implemented support for multiple users with different access levels; user profiles; encrypted login system (and encrypted cookies that contain no sensitive data lol) and session handling according to (perceived) best practices; secure password recovery; user-management interface for admins; public, private and group-based sections with multiple categories and posts in each category that can be sorted by sort order value or drag and drop; custom user-created groups where they can give other users access to their sections; notifications; context menus for everything; post & user flagging system, moderation queue and support system; post revisions with comparison between different revisions; support for mobile devices and touch/swipe gestures to open/close menus or navigate between posts; easily extendible css themes with two different dark themes and one ugly as heck light theme; lazy loading of images in posts that won't load until you actually open them; auto-saving of posts in case of browser crash or accidental navigation away from page; plus various other small stuff like syntax highlighting for code, internal post linking, favouriting of posts, free-text filter, no-javascript mode, invitation system, secure (yeah right) image uploading, post-locking...
On my TODO-list: Comment and/or upvote system, spoiler tag, GDPR compliance (if I ever launch it haha), data-limits, a simple user action log for admins/moderators, overall improved security measures, refactor various controllers, clean up the code...
It STILL uses a single-page design, and the amount of feature requests (and bugs) added to my Trello board increases exponentially with every passing week. No other living person has seen the website yet, and at the pace I'm going, humanity will have gone through at least one major extinction event before I consider it "done" enough to show anyone.
help4 -
Facebook's algorithm is so bad that I can't believe that. In the past few days I marked ~20 posts from the same person with the same/similar content as "Hide post - see fewer posts like this". And now, not that I see fewer of these posts, they are literally throwing all such posts of that person to my feed. I know that I can unfollow this person but I don't want to. I just want to filter out these specific posts (they are all the same, some link, image of an old black and white photo and some description).5
-
Dev Diary Entry #56
Dear diary, the part of the website that allows users to post their own articles - based on an robust rights system - through a rich text editor, is done! It has a revision system and everything. Now to work on a secure way for them to upload images and use these in their articles, as I don't allow links to external images on the site.
Dev Diary Entry #57
Dear diary, today I finally finished the image uploading feature for my website, and I have secured it as well as I can.
First, I check filesize and filetype client-side (for user convenience), then I check the same things serverside, and only allow images in certain formats to be uploaded.
Next, I completely disregard the original filename (and extension) of the image and generate UUIDs for them instead, and use fileinfo/mimetype to determine extension. I then recreate the image serverside, either in original dimensions or downsized if too large, and store the new image (and its thumbnail) in a non-shared, private folder outside the webpage root, inaccessible to other users, and add an image entry in my database that contains the file path, user who uploaded it, all that jazz.
I then serve the image to the users through a server-side script instead of allowing them direct access to the image. Great success. What could possibly go horribly wrong?
Dev Diary Entry #58
Dear diary, I am contemplating scrapping the idea of allowing users to upload images, text, comments or any other contents to the website, since I do not have the capacity to implement the copyright-filter that will probably soon become a requirement in the EU... :(
Wat to do, wat to do...1 -
I just wasted 4 hours debugging a wordpress plugin because the API was returning only the first element of a list. I posted it on support forums, downloaded the plugin's source code and tried to manually find the cause, and I was about to post an issue on the plugin's github page.
It turns out that I forgot I had '$[0]' in my insomnia json filter.... I should probably look for a different job.3 -
In getting a remote job, go to a lot of online job boards. Filter their feed for remote work or work from anywhere. Get the RSS feed (if they don't have it, make one yourself), and add them to your RSS reader, like Feedly.
Do the following daily:
Go through the feed, study the job post ad, apply for the job as per their instructions. Archive those you don't have an interest in and those that you have applied. Repeat.
This also applies for hunting freelance contacts too.3 -
The post-filter algorithm on devrant is really great I'll have to admit it!
Each related posts are aligned in sequence regardless of their tags.
Could this be image meta-data comparison? How does it...? 2
2 -
Sometimes in our personal projects we write crazy commit messages. I'll post mine because its a weekend and I hope someone has a well deserved start. Feel free to post yours, regex out your username, time and hash and paste chronologically. ISSA THREAD MY DUDES AND DUDETTES
--
Initialization of NDM in Kotlin
Small changes, wiping drive
Small changes, wiping drive
Lottie, Backdrop contrast and logging in implementation
Added Lotties, added Link variable to Database Manifest
Fixed menu engine, added Smart adapter, indexing, Extra menus on home and Calendar
b4 work
Added branch and few changes
really before work
Merge remote-tracking branch 'origin/master'
really before work 4 sho
Refined Search response
Added Swipe to menus and nested tabs
Added custom tab library
tabs and shh
MORE TIME WASTED ON just 3 files
api and rx
New models new handlers, new static leaky objects xd, a few icons
minor changes
minor changesqwqaweqweweqwe
db db dbbb
Added Reading display and delete function
tryin to add web socket...fail
tryin to add web socket...success
New robust content handler, linked to a web socket. :) happy data-ring lol
A lot of changes, no time to explain
minor fixes ehehhe
Added args and content builder to content id
Converted some fragments into NDMListFragments
dsa
MAjor BiG ChANgEs added Listable interface added refresh and online cache added many stuff
MAjor mAjOr BiG ChANgEs added multiClick block added in-fragment Menu (and handling) added in-fragment list irem click handling
Unformatted some code, added midi handler, new menus, added manifest
Update and Insert (upsert) extension to Listable ArrayList
Test for hymnbook offline changing
Changed menuId from int to key string :) added refresh ...global... :(
Added Scale Gesture Listener
Changed Font and size of titlebar, text selection arg. NEW NEW Readings layout.
minor fix on duplicate readings
added isUserDatabase attribute to hymn database file added markwon to stanza views
Home changes :)
Modular hymn Editing
Home changes :) part 2
Home changes :) part 3
Unified Stanza view
Perfected stanza sharing
Added Summernote!!
minor changes
Another change but from source tree :)))
Added Span Saving
Added Working Quick Access
Added a caption system, well text captions only
Added Stanza view modes...quite stable though
From work changes
JUST a [ush
Touch horizontal needs fix
Return api heruko
Added bible index
Added new settings file
Added settings and new icons
Minor changes to settings
Restored ping
Toggles and Pickers in settings
Added Section Title
Added Publishing Access Panel
Added Some new color changes on restart. When am I going to be tired of adding files :)
Before the confession
Theme Adaptation to views
Before Realm DB
Theme Activity :)
Changes to theme Activity
Changes to theme Activity part 2 mini
Some laptop changes, so you wont know what changed :)
Images...
Rush ourd
Added palette from images
Added lastModified filter
Problem with cache response
works work
Some Improvements, changed calendar recycle view
Tonic Sol-fa Screen Added
Merge Pull
Yes colors
Before leasing out to testers
Working but unformated table
Added Seperators but we have a glithchchchc
Tonic sol-fa nice, dots left, and some extras :)))
Just a nice commit on a good friday.
Just a quickie
I dont know what im committing...2 -
So I promised a post after work last night, discussing the new factorization technique.
As before, I use a method called decon() that takes any number, like 697 for example, and first breaks it down into the respective digits and magnitudes.
697 becomes -> 600, 90, and 7.
It then factors *those* to give a decomposition matrix that looks something like the following when printed out:
offset: 3, exp: [[Decimal('2'), Decimal('3')], [Decimal('3'), Decimal('1')], [Decimal('5'), Decimal('2')]]
offset: 2, exp: [[Decimal('2'), Decimal('1')], [Decimal('3'), Decimal('2')], [Decimal('5'), Decimal('1')]]
offset: 1, exp: [[Decimal('7'), Decimal('1')]]
Each entry is a pair of numbers representing a prime base and an exponent.
Now the idea was that, in theory, at each magnitude of a product, we could actually search through the *range* of the product of these exponents.
So for offset three (600) here, we're looking at
2^3 * 3 ^ 1 * 5 ^ 2.
But actually we're searching
2^3 * 3 ^ 1 * 5 ^ 2.
2^3 * 3 ^ 1 * 5 ^ 1
2^3 * 3 ^ 1 * 5 ^ 0
2^3 * 3 ^ 0 * 5 ^ 2.
2^3 * 3 ^ 1 * 5 ^ 1
etc..
On the basis that whatever it generates may be the digits of another magnitude in one of our target product's factors.
And the first optimization or filter we can apply is to notice that assuming our factors pq=n,
and where p <= q, it will always be more efficient to search for the digits of p (because its under n^0.5 or the square root), than the larger factor q.
So by implication we can filter out any product of this exponent search that is greater than the square root of n.
Writing this code was a bit of a headache because I had to deal with potentially very large lists of bases and exponents, so I couldn't just use loops within loops.
Instead I resorted to writing a three state state machine that 'counted down' across these exponents, and it just works.
And now, in practice this doesn't immediately give us anything useful. And I had hoped this would at least give us *upperbounds* to start our search from, for any particular digit of a product's factors at a given magnitude. So the 12 digit (or pick a magnitude out of a hat) of an example product might give us an upperbound on the 2's exponent for that same digit in our lowest factor q of n.
It didn't work out that way. Sometimes there would be 'inversions', where the exponent of a factor on a magnitude of n, would be *lower* than the exponent of that factor on the same digit of q.
But when I started tearing into examples and generating test data I started to see certain patterns emerge, and immediately I found a way to not just pin down these inversions, but get *tight* bounds on the 2's exponents in the corresponding digit for our product's factor itself. It was like the complications I initially saw actually became a means to *tighten* the bounds.
For example, for one particular semiprime n=pq, this was some of the data:
n - offset: 6, exp: [[Decimal('2'), Decimal('5')], [Decimal('5'), Decimal('5')]]
q - offset: 6, exp: [[Decimal('2'), Decimal('6')], [Decimal('3'), Decimal('1')], [Decimal('5'), Decimal('5')]]
It's almost like the base 3 exponent in [n:7] gives away the presence of 3^1 in [q:6], even
though theres no subsequent presence of 3^n in [n:6] itself.
And I found this rule held each time I tested it.
Other rules, not so much, and other rules still would fail in the presence of yet other rules, almost like a giant switchboard.
I immediately realized the implications: rules had precedence, acted predictable when in isolated instances, and changed in specific instances in combination with other rules.
This was ripe for a decision tree generated through random search.
Another product n=pq, with mroe data
q(4)
offset: 4, exp: [[Decimal('2'), Decimal('4')], [Decimal('5'), Decimal('3')]]
n(4)
offset: 4, exp: [[Decimal('2'), Decimal('3')], [Decimal('3'), Decimal('2')], [Decimal('5'), Decimal('3')]]
Suggesting that a nontrivial base 3 exponent (**2 rather than **1) suggests the exponent on the 2 in the relevant
digit of [n], is one less than the same base 2 digital exponent at the same digit on [q]
And so it was clear from the get go that this approach held promise.
From there I discovered a bunch more rules and made some observations.
The bulk of the patterns, regardless of how large the product grows, should be present in the smaller bases (some bound of primes, say the first dozen), because the bulk of exponents for the factorization of any magnitude of a number, overwhelming lean heavily in the lower prime bases.
It was if the entire vulnerability was hiding in plain sight for four+ years, and we'd been approaching factorization all wrong from the beginning, by trying to factor a number, and all its digits at all its magnitudes, all at once, when like addition or multiplication, factorization could be done piecemeal if we knew the patterns to look for.7 -
MongoDB database with really relational data. One main collection that had refs to four other collections, all of those references necessary to populate data for a page view. Complicated aggregate to populate all the necessary data and then filter based on criteria selected by the user. And then the client decides that he wants the information to be sortable by column. Some of those columns are fields on the main model, no problem. Others are fields on the refs, which is more of a problem. Especially given that these refs aren’t one single object. They’re arrays of objects.
The revelation was that I could just write an aggregate function to flat map the main collection, returning only the fields necessary for the search, and output it to a new collection and instead use that new collection for displaying and filtering/sorting search results.
But you can’t run the aggregate all the time, you surely say. If anything changes in the main collection, it won’t be reflected in the search results!
Mongoose post(‘findOneAndUpdate’) hooks, my friends. Mongoose post(‘findOneAndUpdate’) hooks.
Never been so happy to have a thing working properly in my life.2 -
I'm not able to post my Banner as a signature, because the filter recognize this banner as the same exact image.
Please think about a signature option5 -
[long confession/question]
So I was asked by a client to make an app similar to prisma(not exactly that but let's say a caricature app) and I knew I have to research a lot.
Now I have been loyal to PHP for over 5 years so I first tried with GD and imagick but the results were not very good, so I thought let's try opencv. I didn’t wanna make any compromises so I didn't go the bridging way, I worked on native python even though I am a newbie in it. I was fairly impressed with the cartoonizing results but others weren't. Soon I got to know that this would take much more than simple filter combinations or matrix manipulations.
I read about prisma and got to know it uses deep neural networks for the same.
Now, in the five years I have learnt almost all the things a run-of-the-mill "Full stack Web Developer" should know.
I have a fair knowledge of PHP, many of its frameworks, many js frameworks(obviously jquery), I have a very good understanding of CSS and its models, I have worked on some cool algos and found solutions to many problems but I haven't gotten to stage where I can implement neural networks/machine learning in my projects.
It just scares me.
___
A little back story: I have been the CTO of a small scale company for about 1.5 years now.
___
So all this got me to asking myself should I just step down from the post to a position where I can learn more skills. Managing takes a lot more time where I can't learn a lot. Sure I learnt some other important things but not as much tech knowledge as I would have in a more basic position.
I know not many of you must have read this far, but if you did what do you think I should do? Really depressed at the moment.5 -
Sorry in advance if it's not the right kind of post
I was thinking about a feature that will ease the interaction between people
Can a ignore/mute option like the one in dota 2 be a thing in devrant ?
Like once i ignore someone, i dont see any of his messages ever in any topic
It's mostly a user side filter thing
This way everyone can speak without the drama that come with conflictual subjects
The offender can still speak his mind and everyone expect those who ignored him can see his messages
The user who ignored someone can still live in a fairytale feed where he see things that wont trigger him
Win win 🤔3 -
Feature Request:
We can now categorise rants we post, please let us filter rants in the feed by category.5 -
I finally have some motivation to write some personal code... on an existing project.
(Work has been too hectic the last few months so don't want to do anymore at home...)
Anyway... I noticed that my Prime Video Tracker app doesn't pick up some of the new Movies now available on Prime, so I did some fixing.
Good News (GN): The search URL is actually static so can goto the same URL for the same search results
GN: The program can filter the movies by a Minimum # of Ratings they have (currently set to 100... use to be 10)
Bad News (BN): The number of movies in the search results is over 5000 (used to be 100-200) so even with this filter, a lot get returned.
GN: the traversal is fully automated
BN: Need to manually look at the descriptions of each and add them the Watchlist
BN: I now have 200 movies on my Watchlist and still going...
So now I have another "Infinite list". Existing ones:
-TED Talks
-NLegs
-Blinkist Read List
-Comics (sort of, I have a huge backlog for Cyanide and Happiness)
-Photos that need "post-processing"
I'm pretty sure I'm forgetting some others...


























Top Tags
Weekly Rant
View