
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
So, you start with a PHP website.
Nah, no hating on PHP here, this is not about language design or performance or strict type systems...
This is about architecture.
No backend web framework, just "plain PHP".
Well, I can deal with that. As long as there is some consistency, I wouldn't even mind maintaining a PHP4 site with Y2K-era HTML4 and zero Javascript.
That sounds like fucking paradise to me right now. 😍
But no, of course it was updated to PHP7, using Laravel, and a main.js file was created. GREAT.... right? Yes. Sure. Totally cool. Gotta stay with the times. But there's still remnants of that ancient framework-less website underneath. So we enter an era of Laravel + Blade templates, with a little sprinkle of raw imported PHP files here and there.
Fine. Ancient PHP + Laravel + Blade + main.js + bootstrap.css. Whatever. I can still handle this. 🤨
But then the Frontend hipsters swoosh back their shawls, sip from their caramel lattes, and start whining: "We want React! We want SPA! No more BootstrapCSS, we're going to launch our own suite of SASS styles! IT'S BETTER".
OK, so we create REST endpoints, and the little monkeys who spend their time animating spinners to cover up all the XHR fuckups are satisfied. But they only care about the top most visited pages, so we ALSO need to keep our Blade templated HTML. We now have about 200 SPA/REST routes, and about 350 classic PHP/Blade pages.
So we enter the Era of Ancient PHP + Laravel + Blade + main.js + bootstrap.css + hipster.sass + REST + React + SPA 😑
Now the Backend grizzlies wake from their hibernation, growling: We have nearly 25 million lines of PHP! Monoliths are evil! Did you know Netflix uses microservices? If we break everything into tiny chunks of code, all our problems will be solved! Let's use DDD! Let's use messaging pipelines! Let's use caching! Let's use big data! Let's use search indexes!... Good right? Sure. Whatever.
OK, so we enter the Era of Ancient PHP + Laravel + Blade + main.js + bootstrap.css + hipster.sass + REST + React + SPA + Redis + RabbitMQ + Cassandra + Elastic 😫
Our monolith starts pooping out little microservices. Some polished pieces turn into pretty little gems... but the obese monolith keeps swelling as well, while simultaneously pooping out more and more little ugly turds at an ever faster rate.
Management rushes in: "Forget about frontend and microservices! We need a desktop app! We need mobile apps! I read in a magazine that the era of the web is over!"
OK, so we enter the Era of Ancient PHP + Laravel + Blade + main.js + bootstrap.css + hipster.sass + REST + GraphQL + React + SPA + Redis + RabbitMQ + Google pub/sub + Neo4J + Cassandra + Elastic + UWP + Android + iOS 😠
"Do you have a monolith or microservices" -- "Yes"
"Which database do you use" -- "Yes"
"Which API standard do you follow" -- "Yes"
"Do you use a CI/building service?" -- "Yes, 3"
"Which Laravel version do you use?" -- "Nine" -- "What, Laravel 9, that isn't even out yet?" -- "No, nine different versions, depends on the services"
"Besides PHP, do you use any Python, Ruby, NodeJS, C#, Golang, or Java?" -- "Not OR, AND. So that's a yes. And bash. Oh and Perl. Oh... and a bit of LUA I think?"
2% of pages are still served by raw, framework-less PHP.31 -
Found this gem on GitHub:
// At this point, I'd like to take a moment to speak to you about the Adobe PSD format.
// PSD is not a good format. PSD is not even a bad format. Calling it such would be an
// insult to other bad formats, such as PCX or JPEG. No, PSD is an abysmal format. Having
// worked on this code for several weeks now, my hate for PSD has grown to a raging fire
// that burns with the fierce passion of a million suns.
// If there are two different ways of doing something, PSD will do both, in different
// places. It will then make up three more ways no sane human would think of, and do those
// too. PSD makes inconsistency an art form. Why, for instance, did it suddenly decide
// that *these* particular chunks should be aligned to four bytes, and that this alignement
// should *not* be included in the size? Other chunks in other places are either unaligned,
// or aligned with the alignment included in the size. Here, though, it is not included.
// Either one of these three behaviours would be fine. A sane format would pick one. PSD,
// of course, uses all three, and more.
// Trying to get data out of a PSD file is like trying to find something in the attic of
// your eccentric old uncle who died in a freak freshwater shark attack on his 58th
// birthday. That last detail may not be important for the purposes of the simile, but
// at this point I am spending a lot of time imagining amusing fates for the people
// responsible for this Rube Goldberg of a file format.
// Earlier, I tried to get a hold of the latest specs for the PSD file format. To do this,
// I had to apply to them for permission to apply to them to have them consider sending
// me this sacred tome. This would have involved faxing them a copy of some document or
// other, probably signed in blood. I can only imagine that they make this process so
// difficult because they are intensely ashamed of having created this abomination. I
// was naturally not gullible enough to go through with this procedure, but if I had done
// so, I would have printed out every single page of the spec, and set them all on fire.
// Were it within my power, I would gather every single copy of those specs, and launch
// them on a spaceship directly into the sun.
//
// PSD is not my favourite file format.
Ref : https://github.com/zepouet/...16 -
The download manager is coming together nicely!
The idea is simple, all the downloads are multithreaded. It saves the chunks and then merges it together at the end. So far it uses 30-40mb for the whole thing!
Next stop, add queue management and then browser integration. The source code is here: https://github.com/tahnik/qDownload.
Don't blame me if you vomit once you see the code. I am still working on it and it will be clean soon. I would love to get some suggestion for the name of the project. It is "qDownload" currently and I fucking hate it.
@Dacexi is joining tomorrow to help with the UI. It's gonna be amazing 🤘 24
24 -
Trying to convince my coworker to have a git repo instead of resending chunks of code in Slack... lmao12
-
Dude, for the hundredth time, stop leaving random chunks of commented out code all over the place in case we "need to find it easily later"...
This is literally the reason we use git.
No, I will not pass it in a code review. The same as last time. And the time before...
Dahhhhh15 -
So probably about a decade ago at this point I was working for free for a friend's start-up hosting company. He had rented out a high-end server in some data center and sold out virtualized chunks to clients.
This is back when you had only a few options for running virtual servers, but the market was taking off like a bat out of hell. In our case, we used User-Mode Linux (UML).
UML is essentially a kernel hack that lets you run the kernel in user space. That alone helps keep things separate or jailed. I'm pretty sure some of you can shed more light on it, but that's as I understood it at the time and I wasn't too shabby at hacking the kernel when we'd have driver issues.
Anyway, one of the ways my friend would on-board someone was to generate a new disk image file, mount it, and then chroot to that mount path. He'd basically use a stock image to do this and then wipe it out before putting it live.
I'm not sure exactly what he was doing at the time, but I got a panicked message on New Years Day saying that he had deleted everything. By everything, he had done an rm -fr /home as root on what he had thought was the root of a drive image.
It wasn't an image. It was the host server.
In the stoke of a single command, all user data was lost. We were pretty much screwed, but I have a knack for not giving up - so I spent a ton of time investigating linux file recovery.
Fun fact about UML - since the kernel runs in user space as a regular ol' process, anything it opens is attached to that process. I had noticed that while the files were "gone", I could still see disk usage. I ended up finding the images attached to their file pointers associated with each running kernel - and thankfully all customers were running at the time.
The next part was crazy, and I still think is crazy. I don't remember the command, but I had to essentially copy the image from the referenced path into a new image file, then shutdown the kernel and power it back on from the new image. We had configs all set aside, so that was easy. When it finally worked I was floored.
Rinse and repeat, I managed to drag every last missing bit out of /proc - with the only side effect being that all MySQL databases needed to be cleaned up.3 -
My best case "Deploy Bittersweet Pipeline":
Prep a bunch of carrots, cucumber and tomatoes for day snacks. Roll & cut some pasta noodles, cook stock with fresh veggies & mushrooms, add some droopy soft boiled egg(s) to the broth, drizzle in some black garlic hot sauce. Enjoy that breakfast with an unsweetened Australian flat white and a half-liter cup of chai spiced green tea. Watch some science/tech/woodworking/cooking YouTube videos while feeding my Bittersweet Jr girl.
(yeah my mood is determined for about 90% by food)
Fire up docker compose & IDEs, and start refactoring code and migrating/fixing old databases.
My worst case "Fatal Incident Bittersweet Repair & Recovery Process":
Stuck while refactoring the worst kind of trash code since 9am.
Pour a glass of Tawny Port at 9pm. Pour a glass of cognac at 11pm. Unwrap 3 chocolate bars and break them into chunks in a bowl. Look at IDE, get nauseated, not from the booze or chocolate, but from the code.
Can't fall asleep because code is too broken, that crap should simply not exist. Take some LSD and amphetamine, can't sleep anyway. Start splitting several 10k-line-long files into smaller classes, type until my fingers have blisters. Empty two bags of Doritos, order a large Falafel with extra garlic sauce at 4am.
Fall asleep at 5am with my face on my keyboard, wake up at 9am with keyboard pattern on my skin.
Cook some hangover noodles.
Call work that I'm taking 3 days off. Feed Bittersweet Jr while I watch some YouTube channels with her. Bittersweet has successfully rebooted.1 -
Did anyone of you worked for a company where:
- there was a financial success
- code was clean and was enabler for fast delivery
- tests were professional
- CI/CD pipeline was working as expected
- features were developed in small chunks (few PRs per day)
- managers were trustful and were solving real issues to help you
- refactor was part of the everyday development
Is it even possible? Is there at least one company who achieved success doing the above?13 -
Not a hack but more of an orchestrated attack. It was high school and our computer labs ran windows and all of them were connected to a central server. Now i had just learnt about windows api and how it can be used to check the space available on a disk. So i wrote a small script to to write chunks of 5mb files in the directory where TURBO C++ was installed and let it run till the system ran out of space.
Then in the spirit of conspiracy i added the said script to the central node and asked everyone in the lab to copy it locally and execute.
Then a few days later, the poor lab incharge corners me and say who added the ms91.dll file(do not remember the exact name😐). I said that it is a standard Microsoft dll and also how would I know. Then he goes on saying how he had to reinstall windows on all computers. At first I felt sorry but then the spirit of satan rose in me and I denied any responsibility about it and returned back to class where each of my classmates had a good laugh about it. 😂😂 -
We've worked 5 months to decompose a complex and huge monolith into microservices, deployed in prod with zero defects. And finally moving to AWS, one by one.
How can i explain this work to bunch of 5 year olds? i.e. i've to present this to top level management with no tech knowledge.
I'm thinking of: Lets say a family of 6 people want to travel for 30 holidays to another country. A monolith can be equivalent to having everyone's luggage in huge bag, microservices can be packing luggage in sizable chunks acceptable by airlines.
I'm bad at explaining, can someone help with better example?10 -
Don't you feel sometimes like you may not be as good dev as you think you are? Like all you do is search for chunks of code in stackoverflow so you can assamble a semi functional project.
I'm having one of those days, and it just feels like shit.6 -
Buffer usage for simple file operation in python.
What the code "should" do, was using I think open or write a stream with a specific buffer size.
Buffer size should be specific, as it was a stream of a multiple gigabyte file over a direct interlink network connection.
Which should have speed things up tremendously, due to fewer syscalls and the machine having beefy resources for a large buffer.
So far the theory.
In practical, the devs made one very very very very very very very very stupid error.
They used dicts for configurations... With extremely bad naming.
configuration = {}
buffer_size = configuration.get("buffering", int(DEFAULT_BUFFERING))
You might immediately guess what has happened here.
DEFAULT_BUFFERING was set to true, evaluating to 1.
Yeah. Writing in 1 byte size chunks results in enormous speed deficiency, as the system is basically bombing itself with syscalls per nanoseconds.
Kinda obvious when you look at it in the raw pure form.
But I guess you can imagine how configuration actually looked....
Wild. Pretty wild. It was the main dict, hard coded, I think 200 entries plus and of course it looked like my toilet after having an spicy food evening and eating too much....
What's even worse is that none made the connection to the buffer size.
This simple and trivial thing entertained us for 2-3 weeks because *drumrolls please* none of the devs tested with large files.
So as usual there was the deployment and then "the sudden miraculous it works totally slow, must be admin / it fault" game.
At some time it landed then on my desk as pretty much everyone who had to deal with it was confused and angry, for understandable reasons (blame game).
It took me and the admin / devs then a few days to track it down, as we really started at the entirely wrong end of the problem, the network...
So much joy for such a stupid thing.18 -
Many people here rant about the dependency hell (rightly so). I'm doing systems programming for quite some time now and it changed my view on what I consider a dependency.
When you build an application you usually have a system you target and some libraries you use that you consider dependencies.
So the system is basically also a dependency (which is abstracted away in the best case by a framework).
What many people forget are standard libraries and runtimes. Things like strlen, memcpy and so on are not available on many smaller systems but you can provide implementations of them easily. Things like malloc are much harder to provide. On some system there is no heap where you could dynamically allocate from so you have to add some static memory to your application and mimic malloc allocating chunks from this static memory. Sometimes you have a heap but you need to acquire the rights to use it first. malloc doesn't provide an interface for this. It just takes it. So you have to acquire the rights and bring them magically to malloc without the actual application code noticing. So even using only the C standard library or the POSIX API can be a hard to satisfy dependency on some systems. Things like the C++ standard library or the Go runtime are often completely unavailable or only rudimentary.
For those of you aiming to write highly portable embedded applications please keep in mind:
- anything except the bare language features is a dependency
- require small and highly abstracted interfaces, e.g. instead of malloc require a pointer and a size to be given to you application instead of your application taking it
- document your ABI well because that's what many people are porting against (and it makes it easier to interface with other languages)2 -
Everyone and their dog is making a game, so why can't I?
1. open world (check)
2. taking inspiration from metro and fallout (check)
3. on a map roughly the size of the u.s. (check)
So I thought what I'd do is pretend to be one of those deaf mutes. While also pretending to be a programmer. Sometimes you make believe
so hard that it comes true apparently.
For the main map I thought I'd automate laying down the base map before hand tweaking it. It's been a bit of a slog. Roughly 1 pixel per mile. (okay, 1973 by 1067). The u.s. is 3.1 million miles, this would work out to 2.1 million miles instead. Eh.
Wrote the script to filter out all the ocean pixels, based on the elevation map, and output the difference. Still had to edit around the shoreline but it sped things up a lot. Just attached the elevation map, because the actual one is an ugly cluster of death magenta to represent the ocean.
Consequence of filtering is, the shoreline is messy and not entirely representative of the u.s.
The preprocessing step also added a lot of in-land 'lakes' that don't exist in some areas, like death valley. Already expected that.
But the plus side is I now have map layers for both elevation and ecology biomes. Aligning them close enough so that the heightmap wasn't displaced, and didn't cut off the shoreline in the ecology layer (at export), was a royal pain, and as super finicky. But thankfully thats done.
Next step is to go through the ecology map, copy each key color, and write down the biome id, courtesy of the 2017 ecoregions project.
From there, I write down the primary landscape features (water, plants, trees, terrain roughness, etc), anything easy to convey.
Main thing I'm interested in is tree types, because those, as tiles, convey a lot more information about the hex terrain than anything else.
Once the biomes are marked, and the tree types are written, the next step is to assign a tile to each tree type, and each density level of mountains (flat, hills, mountains, snowcapped peaks, etc).
The reference ids, colors, and numbers on the map will simplify the process.
After that, I'll write an exporter with python, and dump to csv or another format.
Next steps are laying out the instances in the level editor, that'll act as the tiles in question.
Theres a few naive approaches:
Spawn all the relevant instances at startup, and load the corresponding tiles.
Or setup chunks of instances, enough to cover the camera, and a buffer surrounding the camera. As the camera moves, reconfigure the instances to match the streamed in tile data.
Instances here make sense, because if theres any simulation going on (and I'd like there to be), they can detect in event code, when they are in the invisible buffer around the camera but not yet visible, and be activated by the camera, or deactive themselves after leaving the camera and buffer's area.
The alternative is to let a global controller stream the data in, as a series of tile IDs, corresponding to the various tile sprites, and code global interaction like tile picking into a single event, which seems unwieldy and not at all manageable. I can see it turning into a giant switch case already.
So instances it is.
Actually, if I do 16^2 pixel chunks, it only works out to 124x68 chunks in all. A few thousand, mostly inactive chunks is pretty trivial, and simplifies spawning and serializing/deserializing.
All of this doesn't account for
* putting lakes back in that aren't present
* lots of islands and parts of shores that would typically have bays and parts that jut out, need reworked.
* great lakes need refinement and corrections
* elevation key map too blocky. Need a higher resolution one while reducing color count
This can be solved by introducing some noise into the elevations, varying say, within one standard div.
* mountains will still require refinement to individual state geography. Thats for later on
* shoreline is too smooth, and needs to be less straight-line and less blocky. less corners.
* rivers need added, not just large ones but smaller ones too
* available tree assets need to be matched, as best and fully as possible, to types of trees represented in biome data, so that even if I don't have an exact match, I can still place *something* thats native or looks close enough to what you would expect in a given biome.
Ponderosa pines vs white pines for example.
This also doesn't account for 1. major and minor roads, 2. artificial and natural attractions, 3. other major features people in any given state are familiar with. 4. named places, 5. infrastructure, 6. cities and buildings and towns.
Also I'm pretty sure I cut off part of florida.
Woops, sorry everglades.
Guess I'll just make it a death-zone from nuclear fallout.
Take that gators!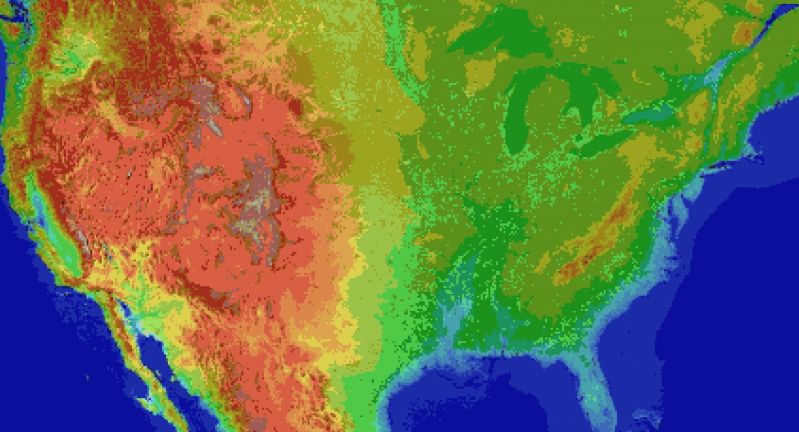 5
5 -
HTTPS requests in most languages:
Import a couple of libraries, you may need to install a few as well. It's possible that you will need to initialize and set up the socket. Be sure to specify SSL settings. Create the connection, provide it a URL, and attempt the connection. Read the response, usually in chunks. You may need to manually create a buffer of fixed size, depending on if the language has buffer helper classes or not. You will probably need to convert the input stream response to a string to do anything with it. Close the connection and clean up any buffers used.
HTTPS requests in Python:
import urllib
urllib.YEET()6 -
OK Google.... guess we'll play it the hard way....
I'll just upload all videos i want transcribed onto Youtube in smaller (10 minute?) chunks where machine transcribe is enabled... 2
2 -
Sometimes I wonder how software development in (bigger) teams worked in the 90s.
Take the first Pokémon games for example. It was the mid-90s and the final product would be Assembler code that goes onto a cartridge with limited space.
I believe version control systems didn't really exist back then (Git & Mercurial: 2005, SVN: 2004). So probably people took backups of the chunks of code they worked on, copied around a stitched-together code, threw everything together at the end of the day, etc. etc. ...
Does anyone here know if there is some kind of documentary about that topic or did anyone here experience that first-hand?
It would be really interesting to see how that stuff worked back then 😊4 -
Really pissed at how Amazon is just assing off large chunks of money by offering managed services that use open source projects. Have nothing against Amazon but isn't open source supposed to be left open source, they should atleast setup a ratio of giving back to the community which developed the project, that's not a lot to ask for and to give!16
-
The process of making my paging MIDI player has ground to a halt IMMEDIATELY:
Format 1 MIDIs.
There are 3 MIDI types: Format 0, 1, and 2.
Format 0 is two chunks long. One track chunk and the header chunk. Can be played with literally one chunk_load() call in my player.
Format 2 is (n+1) chunks long, with n being defined in the header chunk (which makes up the +1.) Can be played with one chunk_load() call per chunk in my player.
Format 1... is (n+1) chunks long, same as Format 2, but instead of being played one chunk at a time in sequence, it requires you play all chunks
AT THE SAME FUCKING TIME.
65534 maximum chunks (first track chunk is global tempo events and has no notes), maximum notes per chunk of ((FFFFFFFFh byte max chunk data area length)/3 = 1,431,655,763d)/2 (as Note On and Note Off have to be done for every note for it to be a valid note, and each eats 3 bytes) = 715,827,881 notes (truncated from 715,827,881.5), 715,827,881 * 65534 (max number of tracks with notes) = a grand total of 46,911,064,353,454 absolute maximum notes. At 6 bytes per (valid) note, disregarding track headers and footers, that's 281,466,386,120,724 bytes of memory at absolute minimum, or 255.992 TERABYTES of note data alone.
All potentially having to be played
ALL
AT
ONCE.
This wouldn't be so bad I thought at the start... I wasn't planning on supporting them.
Except...
>= 90% of MIDIs are Format 1.
Yup. The one format seemingly deliberately built not to be paged of the three is BY FAR the most common, even in cases where Format 0 would be a better fit.
Guess this is why no other player pages out MIDIs: the files are most commonly built specifically to disallow it.
Format 1 and 2 differ in the following way: Format 1's chunks all have to hit the piano keys, so to speak, all at once. Format 2's chunks hit one-by-one, even though it can have the same staggering number of notes as Format 1. One is built for short, detailed MIDIs, one for long, sparse ones.
No one seems to be making long ones.6 -
My God is map development insane. I had no idea.
For starters did you know there are a hundred different satellite map providers?
Just kidding, it's more than that.
Second there appears to be tens of thousands of people whos *entire* job is either analyzing map data, or making maps.
Hell this must be some people's whole *existence*. I am humbled.
I just got done grabbing basic land cover data for a neoscav style game spanning the u.s., when I came across the MRLC land cover data set.
One file was 17GB in size.
Worked out to 1px = 30 meters in their data set. I just need it at a one mile resolution, so I need it in 54px chunks, which I'll have to average, or find medians on, or do some sort of reduction.
Ecoregions.appspot.com actually has a pretty good data set but that's still manual. I ran it through gale and theres actually imperceptible thin line borders that share a separate *shade* of their region colors with the region itself, so I ran it through a mosaic effect, to remove the vast bulk of extraneous border colors, but I'll still have to hand remove the oceans if I go with image sources.
It's not that I havent done things involved like that before, naturally I'm insane. It's just involved.
The reason for editing out the oceans is because the oceans contain a metric boatload of shades of blue.
If I'm converting pixels to tiles, I have to break it down to one color per tile.
With the oceans, the boundary between the ocean and shore (not to mention depth information on the continental shelf) ends up sharing colors when I do a palette reduction, so that's a no-go. Of course I could build the palette bu hand, from sampling the map, and then just measure the distance of each sampled rgb color to that of every color in the palette, to see what color it primarily belongs to, but as it stands ecoregions coloring of the regions has some of them *really close* in rgb value as it is.
Now what I also could do is write a script to parse the shape files, construct polygons in sdl or love2d, and save it to a surface with simplified colors, and output that to bmp.
It's perfectly doable, but technically I'm on savings and supposed to be calling companies right now to see if I can get hired instead of being a bum :P14 -
Trying to troubleshoot this busted ass code for a client. Meanwhile, my wife is in class and my two daughters are blowing chunks.
Staring at devRant isn't fixing anything either. Lol -
How do I make my manager understand that something isn’t doable no matter how much effort, time and perseverance are put into it?
———context———
I’ve been tasked in optimizing a process that goes through a list of sites using the api that manage said sites. The main bottle neck of the process are the requests made to the api. I went as far as making multiple accounts to have multiple tokens fetch the data, balance the loads on the different accounts, make requests in parallel, make dedicated sub processes for each chunks. All of this doesn’t even help that much considering we end up getting rate limited anyway. As for the maintainer of the API, it’s a straight no-can-do if we ask to decrease the rate limit for us.
Essentially I did everything you could possibly do to optimize the process and yet… That’s not enough, it doesn’t fit the 2 days max process time spec that was given to me. So I decided I would tell them that the specs wouldn’t match what’s possible but they insist on 2 days.
I’ve even proposed a valid alternative but they don’t like it either, admittedly it’s not the best as it’s marked as “depreciated” but it would allow us to process data in real time instead of iterating each site.3 -
(Part 2/2?)
THE RAT-RACE ARC:
I get a mail 2 months into this fiasco telling me to register on their website and take up another test. I was already over with my emergency and was working my full-time default. (Fortunately I found another internship during this time which was one of the best initiatives I've worked with).
It asks me to register as a new user, take up the test and "share" my results. Not pushing it on insta/fb but legitimately share my test results link to my friends manually like a referral code. The more shares the more marks I'll get in the test. Why the test you ask. Of course to sign you up for the same Whatsapp trickery bullshit.
Luckily these nutcases didn't know they could be bypassed. I simply opened the link in incognito and logged in with my own account and that counted as a point. So I automated that shit.
Surprise surprise. The same fucking "Hello everyone" message into my mail. To my surprise I was relatively lucky to get ghosted after my attempt. This story is quite depressing in general cases. You're supposed to do this assignment shit for 2 months and then they ask for 2000 INR for a training period, past which you are paid between 1000/- and 7000/-. Though I didn't get the chance but I'm willing to bet you get 1000/- per month in a 2-MONTH INTERNSHIP. WTF.
You also have the other option of ranking first in their 3 consecutive competition that they hold. The theme is again to create chunks of their actual outsourced work.
WHY NOW:
The reason why this rant sparked is because I recently received an email with my results of the aptitude exam that I first took before the Whatsapp fiasco. I imagine they just pushed out a new update to their test thingy and forgot to set it's limit.
THE CORRECTION ARC:
I pushed this message to Internshala. They were kind enough to remove them from their website. I also shot down their Angel and Indeed listings. I sent a strongly worded email counting their con-artist operations and how I've alerted authorities (obviously a bluff but I was enjoying it). They most probably are not affected by this though. They might still be continuing their operations on their website.
I'm sharing the story here with the moral of:
Don't do jackshit if they're not compensating you for it
Always check for reviews before you start working at a place.
Be cautious of bulk messages (and the infamous HEY GUYS!! opening)
Don't do anything outside your work specification at least while doing an assignment.
You're free to question and inquire respectfully about the proceedings.
If you're good at your job you'll get good working place. No need to crush yourself with an oppressive job due to external restrictions.
And if you manage a company, please don't take advantage of helplessness.
There's no good ending to this tale as I have not received a follow-up. Though I want to see scumbags of their calibre shot down without remorse.
Good bye and thank you for listening. 2
2 -
Open street maps, I know it isn't quite what was asked, but it requires connection to be used and it sends maps chunks as images.4
-
I'm gonna start by assuming I'm not the only one who has to deal with this (because that's the case in almost any "Am I the only one that x?"), so here it goes...
How do you deal with the urge to use a framework / library for everything?
I started to notice this behavior in myself a few months back, "there's definitely someone who has already made this, so why should I reinvent the wheel?", and my biggest fear is to become someone who just links chunks of code 'till it works. Did you had to deal with this at some point? What was your approach to this "problem"?3 -
Whenever I cancel out old chunks of code that do not serve their function anymore, or that I commented out in early phases to make space for better functions, I feel dead inside. It's almost like if I was saying goodbye to a very old friend, who supported me through the project and reminded me of how I started it.
Than I notice how stupid and/or inelegant that chunk was, and feel better. 😂 -
What's the longest project you've worked on (in a passage of time type measurement)?. Mine' s a client website, 2 years (so far) in the making. 1 complete redesign, and re-written vast chunks of CSS and code because some of it was shit (2 yrs ago). Now it's super efficient and looking good. Still not finished though. Fortunately they know it's their fault and they have paid up to date, we are at double the original estimate now. I have not moaned at them because they have not moaned at my charges.2
-
It sometimes really sucks to see how many developers, mostly even much better than me, are too lazy to implement a function to its full UX finish.
Like how can you not implement pagination if you know there's going to be fuck ton of content, how can you not allow deleting entries, how can there be no proper search of content, but instead some google custom search, how can you not implement infinite loading everywhere, but only in parts of your application, how can you not caching a rendered version or improve the page, that loads EVERY SINGLE ENTRY in your database with 11k entries, by just adding a filter and loading only chunks of it.
I know sometimes you need to cut corners, but there's rarely any excuse with modern toolsets to just write 3 lines more and have it ready for such basic things.
I sometimes just wake up during the night or before falling asleep and think "oh, what if in the future he might want to manage that, it's just another view and another function handling a resource, laravel makes that very easy anyway", write in on my list and do it in a blink the next day, if there's nothing else like a major bug.
I have such high standard of delivery for myself, that it feels so weird, how somebody can just deliver such a shitty codebase (e.g. filled with "quick/temporary implementations"), not think of the future of the application or the complete user and or admin experience.
Especially it almost hurts seeing somebody so much more versatile in so many areas than me do it, like you perfectly fine know how to cache it in redis, you probably know a fuck ton of other ways I don't even know of yet to do it, yet you decide to make it such a fucking piece of shit and call it finished.2 -
If anyone has read any of my posts before you may know, they're usually of a certain... Shall we say, dark, nature?
Well this possibly represents one of the darkest things I've imagined (with regards to technology and programming) I've had.
I was asked if I want to be buried or cremated when I die and they seem so... Pedestrian and I thought long and hard about what would be a fitting way to honour my life and what to do with my remains and it came to me...
I want my flesh to be only partially treated with formaldehyde so chunks of me rot away and others don't.
I want my skeletal structure to be replace with titanium rods with actuators and servo motors where my joints would have been with an internal gyroscope to assist with balance and my corpse will be installed with some sort of IOT controller board with on board wifi.
The companion smart phone app will allow my partially rotting cybernetic zombie corpse to be driven around by a bored grave yard grounds keeper while kids are doing LSD pretending they're all that.
Make them really believe the apocalypse has begun and the dead have risen.
I could be a whole thing for future corpse disposal too.
"Smart corpses, for the loved one who will be more intelligent in death than they were in life."
Although that's probably a bit too harsh...7 -
There's like one guy in the office who actually knows anything about the software we sell. It's a mess of bolted together chunks of code from different client projects (that the clients have paid for and continue to pay a license fee for) we just cherry pick the best bits and repackage it for the next release.3
-
Forgetting every day tasks...
So I can use map, reduce, filter in my sleep, have memorised huge chunks of valuable programming information.
Today I went to the gym and laced up my jogging pants, looked at the vogue knot I'm supposed to tie to prevent them from falling down and my brain just said:
"Fucked if I know how to tie that!" -
I know streams are useful to enable faster per-chunk reading of large files (eg audio/ video), and in Node they can be piped, which also balances memory usage (when done correctly). But suppose I have a large JSON file of 500MB (say from a scraper) that I want to run some string content replacements on. Are streams fit for this kind of purpose? How do you go about altering the JSON file 'chunks' separately when the Buffer.toString of a chunk would probably be invalid partial JSON? I guess I could rephrase as: what is the best way to read large, structured text files (json, html etc), manipulate their contents and write them back (without reading them in memory at once)?4
-
I know this is utopic, but I've been thinking for a while now about starting an open source platform for figuring out the problems of our society and finding real world, applicable, open source solutions for them.
To give you some more details, the platform should have two interfaces:
- one for people involved in researching, compiling issues into smaller, concrete chunks that can be tackled in the real world, discuss and try to find workable solutions for the issues and so on
- one for the general public to search through the database of issues, become aware of the problems and follow progress on the issues that people started working on
Of course, anyone can join the platform, both as an observer (and have the ability to follow issues they find interesting) and/or contributor (and actually work with the community to make the world a better place in any way they can).
Each area of expertise would have some people that will manage the smaller communities that would build around issues, much like people already do in the open source community, managing teams to focus on the important thins for each issue. (I haven't found a solution for big egos getting in the way yet, but it would be nice if the people involved would focus on fixing stuff in stead of debating about tabs vs spaces, if you know what I mean).
The goal of this project would be to bring together as many people from all kind of fields to actually try to fix this broken society.
It would be even better if it attracted people with money and access to resources (one example off the top of my head being people like Elon Musk) that could help implement the solutions proposed by the community without expecting to gain profit off of it (profit is also acceptable if it is made in a considerate, fair and helpful way, but would not be promoted on the platform).
The whole thing would be voluntary work; no salary, no other commitment than the personal pledge that once someone chooses to tackle something, he/she will also see it trough (or at least do his/her best).
The platform would be something like a mix of real time communication, issue tracker, project management tool and publishing platform.
I don't yet have all the details for how it should all fit together, but if there is something that I would like to start, this is definitely it!
PS: I don't think I can ever do something like this by myself, and I don't really have the time to manage a community of developers to start work on it right now. But if you guys think something like this is something worth your time, I will make time and at least start on defining the architecture and try to turn this into a real project.
If enough people are interested, I will drop any other side projects and do my best to get this into the world!
Thank you for reading :)6 -
Do you have a routine? I work from home everyday since quarantine and I don't think we are going back to the office.
I would like to be more productive, not in the sense of forcing myself to do more job and add more stress, no one is complaining about the time it takes me to finish tasks.
I'm looking for a way to scatter my working hours so I have chunks of focus and chunks of breaks in which I go out for a walk or something instead of a big chunk of focus mixed with distraction. I'm behaving as if it were a "9-5 job" when it is actually "8 hours per day" with flexible schedule.8 -
What's the strangest Assembler or Pseudo-Assembler you've ever encountered?
I wrote a Z-machine (Infocom's virtual text adventure interpreter) and it was quite an interesting interpretation of bytes:
- The first 3 bits of an instruction tell you the opcode category, the rest are the instruction
- The 2nd (and maybe 3rd) byte tell you in 2-Bit chunks the operand types.
- text is encoded in 5-Bit chunks, with special characters for CapsLock that double function as padding (if your text doesn't align with the 3 letters per 2 bytes).
- and of course there are 5 different versions that all work slightly differently (as in CapsLock becomes Shift or "this special character isn't in use anymore")3 -
Dah, I wish I was better at painting. The easiest kind too - painting a room, not a picture. It's fine until I get to the edges. Then I mask off the area I don't want to paint, pull of the tape but no - turns out it's wonkier than a drunk student trying to walk in a straight line.
Go to touch it up, miss, get paint on the other bit I was trying to avoid. Great. Try taping it again - straighter this time - and it works, but then rips off chunks of paint when I take the tape off. Go to touch those bits up, then in my haste splatter it on the floor.
Seriously, how anyone can be this bad at this is beyond me.9 -
I wrote a simple Python script to split a Wikipedia page into manageable chunks. But it took a while to load, so I decided to add a loading indicator. Just a few dots appearing and disappearing. How hard could it be?
"Okay, so I just need a few dots as a loading thing."
"Right, so I suppose I'll need a separate thread for this... Better look up Python's threading again"
"So the thread is working, but it keeps printing it out on separate lines"
"Right, that should fix it ... nope."
"I should probably fix the horrible mess here"
"Hmm... maybe if I replace the weird print() calls with all those extra parameters with sys.stdout.write()..."
"Right, that kind of works, but now there's just a permanent row of dots"
"Okay, that's fixed... Ish."
Well, it works now, but there's a weird mess of two \r's and a somewhat odd loop. Oh, and there's more code for the loading indicator than for the actual functionality. This is CLI by the way.7 -
fcking dropbox. it seems that it doesn't work well with accounts which have over 300,000 files. In my case I have around 1,5 million files and total size is 500gb. Problem is that I am not able to sync them to my local machine. Every time I try to do that dropbox is stuck at "starting" and it's usage builds up till 3.5gb ram and then dropbox crashes.
What should I do if I want to sync everything in dropbox with my local machine in order to go through my old stuff and delete everything I don't need? I could do selective sync and go by chunks of 300k files, but it sounds like a pain in the ass since distribution of files across hundreds of folders is not even.
Maybe there is some better cloud service which deals better with large amounts of files? Maybe I could move all of my files from dropbox to that other cloud service and then sync it on my local machine properly?9 -
dammit ti why must your torture be limitless
> eZ80 has awesome DMA-like instruction that copies byte chunks based on registers and it's nigh-instant to copy 64k it's great
> TI has the opcode disabled outside a 4-byte chunk erroneously unincluded from all blacklists and access regulation
> can't bankswitch and keep registers, and can't write to anywhere but those 4 bytes in that bank
> no reusable code in target bank that i can use via mid-func bankswitch1 -
Having a look at electron again after giving up on it months ago.
I must say, the documentation has improved a lot since then, and it looks---dare I say---intuitive to use?
The electron api demos app is surely some help, but I'm not really all that sure how much it lives up to its name. It doesn't really demonstrate anything, and it doesn't cover the whole api, just small chunks of it.
Loving the event system though!12 -
Idk if it's my putrid chunks of fingers but Play Music's options button always jolts the scroll bar and rarely brings up the menu and I need to fucking complain to somewhere!
 2
2 -
My team has a pathological need to NOT comment! What the fuck!! I think it is because a lot of it is actually magic, so they don't want to admit ignorance. My code is full of "not sure why it works, but breaks when removed." Chunks. That way, when debugging, I actually know what is going on????
I am currently going through and editing someone else's code, and I see code that has no clear purpose, even when removed! Does it do something I don't see??? Does it do nothing?? Fuck! -
!rant
I have my 121 in a few days with my new manager and am trying to get a raise either through moving from junior to mid level dev or being given a significant raise , am being paid a tad below the London market rate's lower range for my skill level.
Any advice on how to approach the topic?
Some bits of my background:
I got almost 4 years of exp :
almost 2 working there...
6 months short term contract as a ruby sql dev another company...
1.5 years worked for an abusive joke of a company who took advantage of my naivety since i was fresh out of uni ( did stuff like pressured me to add more features to a pojo system i made for them) barely learned anything there since i was the only IT person there developing solo, the project lasted 1.5 years and was a total mess to finish, so am not too sure of factoring it into my years of exp.
My Qualifications are:
bsc in information systems
Msc in enterprise sw engineering
My "new" Manager is seeking to retire real soon.
The company isn't doing too well but we just landed 2 big customers who are buying the product my team is working on
I Am one of two last devs on my team and we are barely holding on with the load, can't afford the time to train a newbie to join us
my department is soon to be sold (soon according to what mgr says). They have been saying so for 10 months now.
Last year , since the acquisition Is taking so long and funds were running out We were hit by a wave of redundancies which slashed our workforce in august/ july, told we could last till march this year on our funds . Even senior staff were on a reduced work week...but since we Got new customers then money should be coming in again , this should mean thats no longer the case. Even the senior staff have returned to 5 day work weeks.
Am being given only JavaScript work to do despite being hired as a junior java dev, my more senior colleagues dont wanna even touch js with a long stick
Spoke to 3 recruiters , said they got open roles in the junior- mid level range that pay the proper market range if am interested to put my cv through.
Thats like 25% more than I currently make.
Am a bit scared to jump into a mid level position in another company because i lack a bit confidence in my core java skills.
although a senior dev who used to be on my team thinks i can do it.
i recon i can take on the responsibilities of a mid level dev in me existing company since am pretty familiar with the products
I dont get to work with senior devs and learn from them since we are so stretched thin, hence am not really getting the chance to grow my skills
I know i have gaps in my knowledge and skills having not been able work in java for a while hasn't allowed me to fix that too well. I badly need to learn stuff like proper unit testing, not the adhoc rubbish we do at the moment, frameworks like spring etc
Since I have been pretty much pushed into being the js guy for the large chunks of the project over the last year , its kinda funny am the only guy who has the barest idea how some of the client facing stuff works
The new manager does seem to be a nice guy but he is like a politician, a master bullshitter who kept reassuring all is well and the company is fineeee (just ignore the redundancies as the fly past you)
The deal for thr aquisition seem to have sped up according to rumors
And we heard is a massive company buying us, hence things might pick up again and be better than ever
Any ideas how to approach the 121 with him?
Any advice career wise?
Should i push for a raise ?
promotion to mid?
Leave to find a junior to mid level position?
Tought it out and wait for the take over or company crash while trying to fill the gaps in my knowledge ?
Sorry for the length of this post2 -
Rubber ducking your ass in a way, I figure things out as I rant and have to explain my reasoning or lack thereof every other sentence.
So lettuce harvest some more: I did not finish the linker as I initially planned, because I found a dumber way to solve the problem. I'm storing programs as bytecode chunks broken up into segment trees, and this is how we get namespaces, as each segment and value is labeled -- you can very well think of it as a file structure.
Each file proper, that is, every path you pass to the compiler, has it's own segment tree that results from breaking down the code within. We call this a clan, because it's a family of data, structures and procedures. It's a bit stupid not to call it "class", but that would imply each file can have only one class, which is generally good style but still technically not the case, hence the deliberate use of another word.
Anyway, because every clan is already represented as a tree, we can easily have two or more coexist by just parenting them as-is to a common root, enabling the fetching of symbols from one clan to another. We then perform a cannonical walk of the unified tree, push instructions to an assembly queue, and flatten the segmented memory into a single pool onto which we write the assembler's output.
I didn't think this would work, but it does. So how?
The assembly queue uses a highly sophisticated crackhead abstraction of the CVYC clan, or said plainly, clairvoyant code of the "fucked if I thought this would be simple" family. Fundamentally, every element in the queue is -- recursively -- either a fixed value or a function pointer plus arguments. So every instruction takes the form (ins (arg[0],arg[N])) where the instruction and the arguments may themselves be either fixed or indirect fetches that must be solved but in the ~ F U T U R E ~
Thusly, the assembler must be made aware of the fact that it's wearing sunglasses indoors and high on cocaine, so that these pointers -- and the accompanying arguments -- can be solved. However, your hemorroids are great, and sitting may be painful for long, hard times to come, because to even try and do this kind of John Connor solving pinky promises that loop on themselves is slowly reducing my sanity.
But minor time travel paradoxes aside, this allows for all existing symbols to be fetched at the time of assembly no matter where exactly in memory they reside; even if the namespace is mutated, and so the symbol duplicated, we can still modify the original symbol at the time of duplication to re-route fetchers to it's new location. And so the madness begins.
Effectively, our code can see the future, and it is not pleased with your test results. But enough about you being a disappointment to an equally misconstructed institution -- we are vermin of science, now stand still while I smack you with this Bible.
But seriously now, what I'm trying to say is that linking is not required as a separate step as a result of all this unintelligible fuckery; all the information required to access a file is the segment tree itself, so linking is appending trees to a new root, and a tree written to disk is essentially a linkable object file.
Mission accomplished... ? Perhaps.
This very much closes the chapter on *virtual* programs, that is, anything running on the VM. We're still lacking translation to native code, and that's an entirely different topic. Luckily, the language is pretty fucking close to assembler, so the translation may actually not be all that complicated.
But that is a story for another day, kids.
And now, a word from our sponsor:
<ad> Whoa, hold on there, crystal ball. It's clear to any tzaddiq that only prophets can prophecise, but if you are but a lowly goblinoid emperor of rectal pleasure, the simple truths can become very hard to grasp. How can one manage non-intertwining affairs in their professional and private lives while ALSO compulsively juggling nuts?
Enter: Testament, the gapp that will take your gonad-swallowing virtue to the next level. Ever felt like sucking on a hairy ballsack during office hours? We got you covered. With our state of the art cognitive implants, tracking devices and macumbeiras, you will be able to RIP your way into ultimate scrotolingual pleasure in no time!
Utilizing a highly elaborated process that combines illegal substances with the most forbidden schools of blood magic, we are able to [EXTREMELY CENSORED HERETICAL CONTENT] inside of your MATER with pinpoint accuracy! You shall be reformed in a parallel plane of existence, void of all that was your very being, just to suck on nads!
Just insert the ritual blade into your own testicles and let the spectral dance begin. Try Testament TODAY and use my promo code FIRSTBORNSFIRSTNUT for 20% OFF in your purchase of eternal damnation. Big ups to Testament for sponsoring DEEZ rant.2 -
Hmm... A big text on a UI.Card (on Pebble) crashes the watchapp.
I could design a string length handler and its own text display function...
Or I could divide the text into smaller chunks and call it a day.
Here we go,"4.5"! "4.5+"! "4.5++"!
And now I could look into why it crashes when pressing the back button on a semi long text...
Or I could think of it as an automated memory cleanup! Yeah, right! Awesome! Plus, it's only two press to go back where I was! -
Why do I always get the response: "just comment your code better" whenever im looking into ways to make my files smaller and more pleasant to read by abstracting big chunks into different files.
Or when i want to generate some documentation with storybooks or something.
Is it just me or am i that rebellious by wanting cleaner code..2 -
A fully deployed end to end example of CQRS/Eventsourcing using Haskell.... I only get 1-2 hour chunks to work on it sometimes weeks apart! Even then I get bogged down trying to improve my workflow with tmux and other cool Linux tools. 😣
-
No one's made a MIDI player that pages out the MIDI into individual data chunks (which are how the file format is set up) and the Black MIDI community will never be the same once I drop my WIP paging player3
-
Damn Apache Spark. Instead of supporting just one language that works perfectly well, let's support several languages that give users different results! It's so much fun to combine chunks of each language to get a fully working solution!3
-
Ah, the joy of finding code that looks like a never-ending stream of characters. Because hitting "Enter" is just too much effort, right?
Who needs readable chunks when you can have an eye strain-inducing monolith?3 -
So apparently jupyter / ipython adds the current workdir to kernel library path, and it crashes if you happen to have a file named something like "tokenize.py" in your workdir because it gets prioritised over ipython's builtin module with the same name. What a great design for something which is specifically made to run isolated chunks of code, that it can't even properly isolate itself from the workdir.1
-
There are times when I'm too tired I forget what I changed in the code so I write just "regular" in the title and nothing at all in the description even though it's very obvious i refactored large chunks of the code and added new ones... Regular riight
-
I've coded an script to download images to write them in chunks of 20Mb csv file using base64, this night will be long, after the download ends I have to upload them in another app.
 7
7 -
Hi folks,
I'm currently working on a project where I need to reassemble and play a video from chunks fetched on a server.
The chunks are created from an mp4 video file and with the help of the 'split' command in a terminal.
I can fetch and play the first chunk in a video tag. It displays the total length of the video and stops when the end of the chunk is reached.
But I cannot fetch the second one, somehow append it to the first one and play the newly created chunk.
I tried to concatenate the two chunks using arrayBuffer and Blobs but it didn't work.
Maybe the solution is with SourceBuffer ?
Let's find a way to do that !
Thanks you guys !1 -
[Prestashop question / rant]
Yes, it's not StackOverflow here, neither is it prestashop support forum - but I trust u people most :)
Proper solution for working with big(?) import of products from XML (2,5MB, ~8600 items) to MySQL(InnoDB) within prestashop backoffice module (OR standalone cronjob)
"solutions" I read about so far:
- Up php's max execution time/max memory limit to infinity and hope it's enough
- Run import as a cronjob
- Use MySQL XML parsing procedure and just supply raw xml file to it
- Convert to CSV and use prestashop import functionality (most unreliable so far)
- Instead of using ObjectModel, assemble raw sql queries for chunks of items
- Buy a pre-made module to just handle import (meh)
Maybe an expert on the topic could recommend something?3 -
It's something that comes with practice, but in general it's much better to overestimate than underestimate.
- Always take your time. Don't be rushed into plucking a number out of thin air.
- Break the task down into really small, atomic chunks.
- Each of those chunks will take at least twice as long as you think it does - nothing goes to plan 100% the first time!
- Make sure you add contingency at the end. -
This story starts with a call from the 1st line support that users were getting intermittent-production-only error in one of the key application my team were working on.
The problem was that the application was behind the hardened environment that we had no access to.
The only thing we could do is enable logging which in itself took a whole week to get approved. And the result the Developers favourite - NullReferenceException in one of the biggest methods, I've ever seen in my whole career. Needless to say, that was not very helpful and we were no closer to the solution.
What. A. Pain.
Frustrated with the issue and with business breathing down my neck I started slicing this Monster of a method into smaller and smaller chunks. Even if some action was just a one-liner that would not stop me to create a method. At one point I could no longer care for method names resorting to such classics like Method1, FooBar123 and DoStuff.
But. It. Worked.
After the next deployment logs were showing the same NullReferenceException but now the stack trace pointed me to some Method13.
The resulting stack trace finally allowed to pinpoint the issue. The fix then was just a simple null check.
While Dev team who did not appreciate my creative method naming it was obvious to everyone that even that was better than one big blob of code.
It might seem silly to separate the most obvious one-liners into their own methods and sometimes even whole classes but not living through that experience alone is worth it for me.
Did you ever found yourself in a situation where you wished your stack trace was just a little bit more in-depth? Tell me in the comments ^_^
So now go and look at your code and see if you can pepper it with smaller methods so that you stack traces can pave your way to your debugging success.
Originally posted on amoenus.dev/no-method-too-small-or-amoenus-dev 3
3


















































Top Tags
Weekly Rant
View