
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Its Friday, you all know what that means! ... Its results day for practiseSafeHex's most incompetent co-worker!!!
*audience: wwwwwwooooooooo!!!!*
We've had a bewildering array of candidates, lets remind ourselves:
- a psychopath that genuinely scared me a little
- a CEO I would take pleasure seeing in pain
- a pothead who mistook me for his drug dealer
- an unbelievable idiot
- an arrogant idiot obsessed with strings
Tough competition, but there can be only one ... *drum roll* ... the winner is ... none of them!
*audience: GASP!*
*audience member: what?*
*audience member: no way!*
*audience member: your fucking kidding me!*
Sir calm down! this is a day time show, no need for that ... let me explain, there is a winner ... but we've kept him till last and for a good reason
*audience: ooooohhhhh*
You see our final contestant and ultimate winner of this series is our good old friend "C", taking the letters of each of our previous contestants, that spells TRAGIC which is the only word to explain C.
*audience: laughs*
Oh I assure you its no laughing matter. C was with us for 6 whole months ... 6 excruciatingly painful months.
Backstory:
We needed someone with frontend, backend and experience with IoT devices, or raspberry PI's. We didn't think we'd get it all, but in walked an interviewee with web development experience, a tiny bit of Angular and his masters project was building a robot device that would change LED's depending on your facial expressions. PERFECT!!!
... oh to have a time machine
Working with C:
- He never actually did the tutorials I first set him on for Node.js and Angular 2+ because they were "too boring". I didn't find this out until some time later.
- The first project I had him work on was a small dashboard and backend, but he decided to use Angular 1 and a different database than what we were using because "for me, these are easier".
- He called that project done without testing / deploying it in the cloud, despite that being part of the ticket, because he didn't know how. Rather than tell or ask anyone ... he just didn't do it and moved on.
- As part of his first tech review I had to explain to him why he should be using if / else, rather than just if's.
- Despite his past experience building server applications and dashboards (4 years!), he never heard of a websocket, and it took a considerable amount of time to explain.
- When he used a node module to open a server socket, he sat staring at me like a deer caught in headlights completely unaware of how to use / test it was working. I again had to explain it and ultimately test it for him with a command line client.
- He didn't understand the need to leave logging inside an application to report errors. Because he used to ... I shit you not ... drive to his customers, plug into their server and debug their application using a debugger.
... props for using a debugger, but fuck me.
- Once, after an entire 2 days of tapping me on the shoulder every 15 mins for questions / issues, I had to stop and ask:
Me: "Have you googled it?"
C: "... eh, no"
Me: "can I ask why?"
C: "well, for me, I only google for something I don't know"
Me: "... well do you know what this error message means?"
C: "ah good point, i'll try this time"
... maybe he was A's stoner buddy?
- He burned through our free cloud usage allowance for a month, after 1 day, meaning he couldn't test anything else under his account. He left an application running, broadcasting a lot of data. Turns out the on / off button on the dashboard only worked for "on". He had been killing his terminal locally and didn't know how to "ctrl + c a cloud app" ... so left it running. His intention was to restart the app every time you are done using it ... but forgot.
- His issue with the previous one ... not any of his countless mistakes, not the lack of even trying to make the button work, no, no, not for C. C's issue is the cloud is "shit" for giving us such little allowances. (for the record in a month I had never used more than 5%).
- I had to explain environment variables and why they are necessary for passwords and tokens etc. He didn't know it wasn't ok to commit these into GitHub.
- At his project meetups with partners I had to repeatedly ask him to stop googling gifs and pay attention to the talks.
- He complained that we don't have 3 hour lunch breaks like his last place.
- He once copied and pasted the same function 450 times into a file as a load test ... are loops too mainstream nowadays?
You see C is our winner, because after 6 painful months (companies internal process / requirements) he actually achieved nothing. I really mean that, nothing. Every thing was so broken, so insecure / wide open, built without any kind of common sense or standards I had to delete it all and start again ... it took me 2 weeks.
I hope you've all enjoyed this series and will join me in praying for the return of my sanity ... I do miss it a lot.
Yours truly,
practiseSafeHex20 -
RANT Incoming
Not necessarily dev related but I need to get this off my chest.
So a bit of a backstory. I had to stay late from school the other day and ended up having to take an Uber home. The ride was fine lady was nice. Everything seems to be going well and there were no signs of any payment failure.
Then yesterday, I had to stay late again. I never said that I had an outstanding balance on my account. Apparently Uber was having problems charging my Android pay account.
So I ended up being stuck at school for like 3 hours. Great!😑
So I emailed Uber when I got home. And this is when I started pulling my hair out. I don't know how many replies I had, but each time I had to tell them that I was not using a prepaid card.
This was one of my replies:
"I'm sorry, are you real? If you are, here is a quick summary of the issue. I am using ANDROID PAY with my CHASE DEBIT CARD. Not, NOT, NOT a prepaid card. I happen to know that CHASE DEBIT CARD(which is the card I use, in case you have already forgotten) works with uber because MY FATHER USES THE EXACT SAME TYPE OF CARD with uber. He uses a CHASE DEBIT CARD(again I use that same type of card as well). So by using LOGIC I am able to deduce that a CHASE DEBIT CARD is in fact compatible. AGAIN THIS IS NOT A PREPAID CARD!!! If the card is incompatible, WHY DOES THE APP ALLOW BE TO ADD IT?!?! Also in response to your last email... Because I am using Android pay, do you really think that an ANDROID would be able to use APPLE pay? Also Google wallet is DISCONTINUED! Finally, PayPal DOES NOT CONNECT TO UBER. Returns a "Server Error." So please stop wasting my time with generic help solutions. Believe me, I have already googled my issue, and nothing comes up. That is why I contacted Uber. I want my driver to be paid, and, uber had made it SO painful with unhelpful "Solutions" to problems that don't even APPLY TO MY ISSUE. No not even mention PREPAID cards in your reply or I will consider you a robot built by monkeys banging their heads on a keyboard. Uber HAS my VALID payment information, USE IT! If there is a phone number I can call, please, enlighten me"
And the response was:
"Thanks for reaching out with this.
Happy to help with this issue you are having.
After reviewing your I can see that the only payment method associated with your account is an ANDROID PAY card and it is also a prepaid card. Some cards and methods are not compatible with our billing processes and can't be used with Uber. This includes prepaid cards."
So I concluded that they are monkeys.
Then Uber banned me from logging into my account because I didn't pay.
So now it is impossible for me to pay because I can't do anything with my account.
Now they want my SSN and a bunch of other shit that I won't give them.
I told them that they were being illogical, and I got the exact same response about the prepaid bullshit.
So I sent them this photo as a goodbye.
I get my driver's licence next weekend, so I won't need Uber anymore. YAY!
Also mind grammatical errors, I talked it in and am to lazy to proofread 13
13 -
Spent most of the day debugging issues with a new release. Logging tool was saying we were getting HTTP 400’s and 500’s from the backend. Couldn’t figure it out.
Eventually found the backend sometimes sends down successful responses but with statusCode 500 for no reason what so ever. Got so annoyed ... but said the 400’s must be us so can’t blame them for everything.
Turns out backend also sometimes does the opposite. Sends down errors with HTTP 200’s. A junior app Dev was apparently so annoyed that backend wouldn’t fix it, that he wrote code to parse the response, if it contained an error, re-wrote the statusCode to 400 and then passed the response up to the next layer. He never documented it before he left.
Saving the best part for last. Backend says their code is fine, it must be one of the other layers (load balancers, proxies etc) managed by one of the other teams in the company ... we didn’t contact any of these teams, no no no, that would require effort. No we’ve just blamed them privately and that’s that.
#successfulRelease4 -
ANTI VIRUSES AREN'T ALWAYS YOUR FRIEND!
So I'm under a little pressure to get an assignment done so I came home an was planning on working on it but Windows had other plans and decided to finish its update which I suspect copied my hard drive and uploaded it to the NSA at dial up speed because it it forever!!
But anyway back to the text in caps lock... I started working on it then when I hit compile I got an "access denied" error in the console and didn't know what the f*** was going on. So I decided to copy my filed to another directory and tried again... amazingly this worked so I carried on and after about 2 hours I get the same error -_- So instead of messing around and loosing my work I decided to commit it... but I cant... again "access denied" error.
After threatening my computer with a trip out the window, I finally decided to reboot it... cause "have you tried turning it off and on again" kept on rattling in my head.
After logging in I tried again and still the same error... Then I opened up my anti virus dashboard and went through the logs and found the screen shot attached.....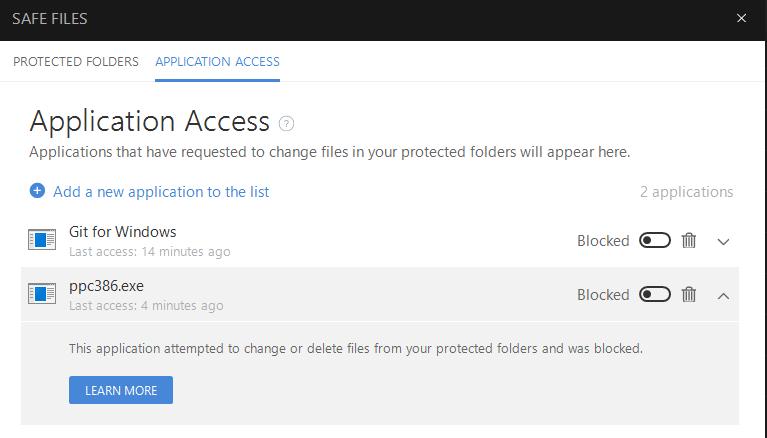 14
14 -
I wrote a database migration to add a column to a table and populated that column upon record creation.
But the code is so freaking convoluted that it took me four days of clawing my eyes out to manage this.
BUT IT'S FINALLY DONE.
FREAKING YAY.
Why so long, you ask? Just how convoluted could this possibly be? Follow my lead ~
There's an API to create a gift. (Possibly more; I have no bloody clue.)
I needed the mobile dev contractor to tell me which APIs he uses because there are lots of unused ones, and no reasoning to their naming, nor comments telling me what they do.
This API takes the supplied gift params, cherry-picks a few bits of useful data out (by passing both hashes by reference to several methods), replaces a couple of them with lookups / class instances (more pass-by-reference nonsense). After all of this, it logs the resulting (and very different) mess, and happily declares it the original supplied params. Utterly useless for basically everything, and so very wrong.
It then uses this data to call GiftSale#create, which returns an instance of GiftSale (that's actually a Gift; more on that soon).
GiftSale inherits from Gift, and redefines three of its methods.
GiftSale#create performs a lot of validations / data massaging, some by reference, some not. It uses `super` to call Gift#create which actually maps to the constructor Gift#initialize.
Gift#initialize calls Gift#pre_init (passing the data by reference again), which does nothing and returns null. But remember: GiftSale inherits from Gift, meaning GiftSale#pre_init supersedes Gift#pre_init, so that one is called instead. GiftSale#pre_init returns a Stripe charge object upon success, or a Gift (and a log entry containing '500 Internal') upon failure. But this is irrelevant because the return value is never actually used. Pass by reference, remember? I didn't.
We're now back at Gift#initialize, Rails finally creates a Gift object using the args modified [mostly] in-place by all of the above.
Another step back and we're at GiftSale#create again. This method returns either the shiny new Gift object or an error string (???), and the API logic branches on its type. For further confusion: not all of the method's returns are explicit, and those implicit return values are nested three levels deep. (In Ruby, a method will return the last executed line's return value automatically, allowing e.g. `def add(a,b); a+b; end`)
So, to summarize: GiftSale#create jumps back and forth between Gift five times before finally creating a Gift instance, and each jump further modifies the supplied params in-place.
Also. There are no rescue/catch blocks, meaning any issue with any of the above results in a 500. (A real 500, not a fake 500 like last time. A real 500, with tragic consequences.)
If you're having trouble following the above... yep! That's why it took FOUR FREAKING DAYS! I had no tests, no documentation, no already-built way of testing the API, and no idea what data to send it. especially considering it requires data from Stripe. It also requires an active session token + user data, and I likewise had no login API tests, documentation, logging, no idea how to create a user ... fucking hell, it's a mess.)
Also, and quite confusingly:
There's a class for GiftSale, but there's no table for it.
Gift and GiftSale are completely interchangeable except for their #create methods.
So, why does GiftSale exist?
I have no bloody idea.
All it seems to do is make everything far more complicated than it needs to be.
Anyway. My total commit?
Six lines.
IN FOUR FUCKING DAYS!
AHSKJGHALSKHGLKAHDSGJKASGH.7 -
Yesterday the web site started logging an exception “A task was canceled” when making a http call using the .Net HTTPClient class (site calling a REST service).
Emails back n’ forth ..blaming the database…blaming the network..then a senior web developer blamed the logging (the system I’m responsible for).
Under the hood, the logger is sending the exception data to another REST service (which sends emails, generates reports etc.) which I had to quickly re-direct the discussion because if we’re seeing the exception email, the logging didn’t cause the exception, it’s just reporting it. Felt a little sad having to explain it to other IT professionals, but everyone seemed to agree and focused on the server resources.
Last night I get a call about the exceptions occurring again in much larger numbers (from 100 to over 5,000 within a few minutes). I log in, add myself to the large skype group chat going on just to catch the same senior web developer say …
“Here is the APM data that shows logging is causing the http tasks to get canceled.”
FRACK!
Me: “No, that data just shows the logging http traffic of the exception. The exception is occurring before any logging is executed. The task is either being canceled due to a network time out or IIS is running out of threads. The web site is failing to execute the http call to the REST service.”
Several other devs, DBAs, and network admins agree.
The errors only lasted a couple of minutes (exactly 2 minutes, which seemed odd), so everyone agrees to dig into the data further in the morning.
This morning I login to my computer to discover the error(s) occurred again at 6:20AM and an email from the senior web developer saying we (my mgr, her mgr, network admins, DBAs, etc) need to discuss changes to the logging system to prevent this problem from negatively affecting the customer experience...blah blah blah.
FRACKing female dog!
Good news is we never had the meeting. When the senior web dev manager came in, he cancelled the meeting.
Turned out to be a hiccup in a domain controller causing the servers to lose their connection to each other for 2 minutes (1-minute timeout, 1 minute to fully re-sync). The exact two-minute burst of errors explained (and proven via wireshark).
People and their petty office politics piss me off.2 -
Worst hack/attack I had to deal with?
Worst, or funniest. A partnership with a Canadian company got turned upside down and our company decided to 'part ways' by simply not returning his phone calls/emails, etc. A big 'jerk move' IMO, but all I was responsible for was a web portal into our system (submitting orders, inventory, etc).
After the separation, I removed the login permissions, but the ex-partner system was set up to 'ping' our site for various updates and we were logging the failed login attempts, maybe 5 a day or so. Our network admin got tired of seeing that error in his logs and reached out to the VP (responsible for the 'break up') and requested he tell the partner their system is still trying to login and stop it. Couple of days later, we were getting random 300, 500, 1000 failed login attempts (causing automated emails to notify that there was a problem). The partner knew that we were likely getting alerted, and kept up the barage. When alerts get high enough, they are sent to the IT-VP, which gets a whole bunch of people involved.
VP-Marketing: "Why are you allowing them into our system?! Cut them off, NOW!"
Me: "I'm not letting them in, I'm stopping them, hence the login error."
VP-Marketing: "That jackass said he will keep trying to get into our system unless we pay him $10,000. Just turn those machines off!"
VP-IT : "We can't. They serve our other international partners."
<slams hand on table>
VP-Marketing: "I don't fucking believe this! How the fuck did you let this happen!?"
VP-IT: "Yes, you shouldn't have allowed the partner into our system to begin with. What are you going to do to fix this situation?"
Me: "Um, we've been testing for months already went live some time ago. I didn't know you defaulted on the contract until last week. 'Jake' is likely running a script. He'll get bored of doing that and in a couple of weeks, he'll stop. I say lets ignore him. This really a network problem, not a coding problem."
IT-MGR: "Now..now...lets not make excuses and point fingers. It's time to fix your code."
IT-VP: "I agree. We're not going to let anyone blackmail us. Make it happen."
So I figure out the partner's IP address, and hard-code the value in my service so it doesn't log the login failure (if IP = '10.50.etc and so on' major hack job). That worked for a couple of days, then (I suspect) the ISP re-assigned a new IP and the errors started up again.
After a few angry emails from the 'powers-that-be', our network admin stops by my desk.
D: "Dude, I'm sorry, I've been so busy. I just heard and I wished they had told me what was going on. I'm going to block his entire domain and send a request to the ISP to shut him down. This was my problem to fix, you should have never been involved."
After 'D' worked his mojo, the errors stopped.
Month later, 'D' gave me an update. He was still logging the traffic from the partner's system (the ISP wanted extensive logs to prove the customer was abusing their service) and like magic one day, it all stopped. ~2 weeks after the 'break up'.8 -
The day I discovered Schrödinger's lesser known paradox of simultaneously being fired and not fired.
This isn't really much of a dev story, but I figured I'd share it anyway.
About two minutes into signing into all my stuff, I suddenly was kicked out of everything. I tried logging in a few more times, and then suddenly started getting the error, "Your account has been disabled for security reasons." I couldn't sign into chat, and co-workers confirmed that I was missing from the company directory. My manager didn't come in for another two hours, and we couldn't get anyone else to answer what the hell was going on. So I was kinda panicking.
Eventually, we found out from one of our coordinators that someone else with the same name as me was leaving the company, and they had deactivated the wrong person.
It ended up getting a lot better. They told me that it could take up to 48 hours to restore my access (it took longer), so I found stuff to do so I could maintain my paycheck. One of those things was assisting someone with data collection and processing, where I eventually said, "Dude, I could totally automate this," and now that's what I'm getting paid to do.1 -
Introduced a ‘new’ logging framework for our web site. Web team is testing the integration and I get an email saying the logging wasn’t working. Instead of sending me how she is searching the logs, she sends me a screen shot of the code (which is ass-backwards of how I documented the logging library, but that’s another rant). OK, she wrote 5 lines of code that should be one line, but OK, the error still should have logged fine. I search the logs, and sure enough, there they are. Errors logged just as they should.
So I email back (with screenshot of the search query and results) asking how she searched for the errors.
Hour later she responds ..”I don’t know.”
That’s it.
WTF do you mean “I don’t know”?…WTF…you are a –bleep-ing developer too! This is not the first –bleep-ing splunk query you’ve written!
OK..I’m calm..feeling better. Wouldn’t be so bad if she emailed just me with the question (I’m not a splunk query expert either, we can figure it out together), but she was sure to cc 3 of the PMs involved in the integration, my boss, and other team members to make it sound like the problem was my code.3 -
What features would you want in a logger?
Here's what I'm planning so far:
- Tagged entries for easy scanning of log file
- Support for indenting to group similar sequential entries
- Multiple entry types (normal, info, event, warning, error, fatal, debug, verbose)
- Meta entries, so the logger logging about itself, e.g. disk i/o failures.
- Ability to add custom entry types, including tag, log-level, etc.
- Customizable timestamp function
- Support for JS's async nature -- this equates to passing a unique key per 'thread'; the logger will re-write all the parent blocks for context, if necessary. if that sounds confusing, it's okay; just trust that it makes sense.
- Caching, retries, etc. in the event of disk i/o issues.
- Support for custom writers, allowing you to e.g. write logs to an API rather than console or disk.
How about these features?
- Multiple (named) logs with separate writers (console, disk, etc.)
- Ability to individually enable/disable writing of specific entry types. (want verbose but not info? sure thing, weirdo!)
- Multiple writers per log. Combined with the above, this would allow you to write specific entry types (e.g. error, warning, fatal) to stderr instead of stdout, or to different apis.
- Ability to write the same log entry to multiple logs simultaneously
What do you think of these features?
What other features would you want?
I'm open to suggestions!17 -
Did a bunch more cowboy coding today as I call it (coding in vi on production). Gather 'round kiddies, uncle Logan's got a story fer ya…
First things first, disclaimer: I'm no sysadmin. I respect sysadmins and the work they do, but I'm the first to admit my strengths definitely lie more in writing programs rather than running servers.
Anyhow, I recently inherited someone else's codebase (the story of my profession career, but I digress) and let me tell you this thing has amateur hour written all over it. It's written in PHP and JavaScript by a self-taught programmer who apparently discovered procedural programming and decided there was nothing left to learn and stopped there (no disrespect to self-taught programmers).
I could rant for days about the various problems this codebase has, but today I have a very specific story to tell. A story about errors and logs.
And it all started when I noticed the disk space on our server was gradually decreasing.
So today I logged onto our API server (Ubuntu running Apache/PHP) and did a df -h to check the disk space, and was surprised to see that it had noticeably decreased since the last time I'd checked when everything was running smoothly. But seeing as this server does not store any persistent customer data (we have a separate db server) and purely hosts the stateless API, it should NOT be consuming disk space over time at all.
The only thing I could think of was the logs, but the logs were very quiet, just the odd benign message that was fully expected. Just to be sure I did an ls -Sh to check the size of the logs, and while some of them were a little big, nothing over a few megs. Nothing to account for gigabytes of disk space gradually disappearing.
What could it be? I wondered.
cd ../..
du . | sort --sort=numeric
What's this? 2671132 K in some log folder buried in the api source code? I cd into it and it turns out there are separate PHP log files in there, split up by customer, so that each customer of ours (we have 120) has their own respective error log! (Why??)
Armed with this newfound piece of (still rather unbelievable) evidence I perform a mad scramble to search the codebase for where this extra logging is happening and sure enough I find a custom PHP error handler that is capturing (most) errors and redirecting them to these individualized log files.
Conveniently enough, not ALL errors were being absorbed though, so I still knew the main error_log was working (and any time I explicitly error_logged it would go there, so I was none the wiser that this other error-catching was even happening).
Needless to say I removed the code as quickly as I found it, tail -f'd the error_log and to my dismay it was being absolutely flooded with syntax errors, runtime PHP exceptions, warnings galore, and all sorts of other things.
My jaw almost hit the floor. I've been with this company for 6 months and had no idea these errors were even happening!
The sad thing was how easy to fix all the errors ended up being. Most of them were "undefined index" errors that could have been completely avoided with a simple isset() check, but instead ended up throwing an exception, nullifying any code that came after it.
Anyway kids, the moral of the story is don't split up your log files. It makes absolutely no sense and can end up obscuring easily fixable bugs for half a year or more!
Happy coding.6 -
So we have an API that my team is supposed send messages to in a fire and forget kind of style.
We are dependent on it. If it fails there is some annoying manual labor involved to clean that mess up. (If it even can be cleaned up, as sometimes it is also time-sensitive.)
Yet once in a while, that endpoint just crashes by letting the request vanish. No response, no error, nothing, it is just gone.
Digging through the log files of that API nothing pops up. Yet then I realize the size of the log files. About ~30GB on good old plain text log files.
It turns out that that API has taken the LOG EVERYTHING approach so much too heart that it logs to the point of its own death.
Is circular logging such a bleeding edge technology? It's not like there are external solutions for it like loggly or kibana. But oh, one might have to pay for them. Just dump it to the disk :/
This is again a combination of developers thinking "I don't need to care about space! It's cheap!" and managers thinking "100 GB should be enough for that server cluster. Let's restrict its HDD to 100GB, save some money!"
And then, here I stand trying to keep my sanity :/1 -
Wanna hear a story? The consultancy firm I work for has been hired to work on a WPF project for a big Fashion Industry giant.
We are talking of their most important project yet, the ones the "buyers" use to order them their products globally, for each of the retail stores this Fashion giant has around the world. Do you want to know what I found? Wel, come my sweet summer child.
DB: not even a single foreign key. Impossibile to understand without any priopr working experience on the application. Six "quantity" tables to keep aligned with values that will dictate the quantities to be sent to production (we are talking SKUs here: shoes, bags..)
BE: autogenerated controllers using T4 templates. Inputs directly serialized in headers. Async logging (i.e. await Logger.Error(ex)). Entities returned as response to the front end, no DTOs whatsoever.
WPF: riddled with code behind and third party components (dev express) and Business Logic that should belong to the Business Layer. No real api client, just a highly customized "Rest Helper". No error reporting or dealing with exceptions. Multiple endpoints call to get data that would be combined into one single model which happens to be the one needed by the UI. No save function: a timer checks the components for changes and autosaves them every x seconds. Saving for the most critical part occurring when switching cells or rows, often resulting in race conditions at DB level.
What do you think of this piece of shit?6 -
I'm getting annoyed with the increasing number of platforms that implement the "Oops, something went wrong" vague error message.8
-
Had an internet/network outage and the web site started logging thousands of errors and I see they purposely created a custom exception class just to avoid/get around our standard logging+data gathering (on SqlExceptions, we gather+log all the necessary details to Splunk so our DBAs can troubleshoot the problem).
If we didn't already know what the problem was, WTF would anyone do with 'There was a SQL exception, Query'? OK, what was the exception? A timeout? A syntax error? Value out of range? What was the target server? Which database? Our web developers live in a different world. I don't understand em. 1
1 -
TL;DR: Google asked me to PROVIDE a phone number to verify connection from a new device, on the said device.
Yesterdayto log into my work Google account from my personal laptop to check emails, calendars update and so on. I opened up a private navigation window, went to Google sign-in page, entered my credentials, all is well.
Google then decided to "verify it's me" and prompted me to PROVIDE a phone number (work account without work phone means no phone number set up) so that they can send a verification code to the number I just provided to make sure the connection is legit.
Didn't want to do that, clicked "use another method" and got asked to fill the last password I remember, which would be my current password thanks to my trusty password manager. After submitting, I'm prompted with an error saying I have to contact my admin to reset my password because they can't log me in with my CURRENT password.
I ain't gonna do that, so went back to login page, provided my phone number, got the code, filled in the code, next thing I know I'm browsing through my emails.
What the duck? Could have been anybody giving any phone number. So much for extra security.
Also don't care that they have my phone number, the issue is more about the way used to obtain it: locking me out of my account and having no other way of logging in.6 -
A service had/has been logging hundreds of errors in the development environment and I reached out to the owning process mgr that the error was occurring and perhaps a good opportunity to log additional data to help troubleshoot the issue if the problem ever made its way to production. He responded saying the error was related to a new feature they weren't going to implement in the backing dev database (TL;DR), and they know it works in production (my spidey sense goes off).
They deployed the changes to production this morning and immediately starting throwing errors (same error I sent)
Mgr messaged me a little while ago "Did you make any changes to the documentation service? We're getting this error .."
50% sure someone misspelled something in a config, but only thing they are logging is 'Unable to parse document'. Nothing that indicates an issue with the service they're using.2 -
In today's episode of kidding on SystemD, we have a surprise guest star appearance - Apache Foundation HTTPD server, or as we in the Debian ecosystem call it, the Apache webserver!
So, imagine a situation like this - Its friday afternoon, you have just migrated a bunch of web domains under a new, up to date, system. Everything works just fine, until... You try to generate SSL certificates from Lets Encrypt.
Such a mundane task, done more than a thousand times already... Yet... No matter what you do, nothing works. Apache just returns a HTTP status code 403 - Forbidden.
Of course, what many folk would think of first when it came to a 403 error is - Ooooh, a permission issue somewhere in the directory structure!
So you check it... And re-check it to make sure... And even switch over to the user the webserver runs under, yet... You can access the challenge just fine, what the hell!
So you go deeper... And enable the most verbose level of logging apache is capable of - Trace8. That tells you... Not a whole lot more... Apparently, the webserver was unable to find file specified? But... Its right there, you can see it!
So you go another step deeper and start tracing the process' system calls to see exactly where it calls stat/lstat on the file, and you see that it... Calls lstat and... It... Returns -1? What the hell#2!
So, you compile a custom binary that calls lstat on the first argument given and prints out everything it returns... And... It works fine!
Until now, I chose to omit one important detail that might have given away the issue to the more knowledgeable right away. Our webservers have the URL /.well-known/acme-challenge/, used for ACME challenges, aliased somewhere else on the filesystem - To /tmp/challenges.
See the issue already?
Some *bleep* over at the Debian Package Maintainer group decided that Apache could save very sensitive data into /tmp, so, it would be for the best if they changed something that worked for decades, and enabled a SystemD service unit option "PrivateTmp" for the webserver, by default.
What it does is that, anytime a process started with this option enabled writes to /tmp/*, the call gets hijacked or something, and actually makes the write to a private /tmp/something/tmp/ directory, where something... Appeared as a completely random name, with the "apache2.service" glued at the end.
That was also the only reason why I managed fix this issue - On the umpteenth time of checking the directory structure, I noticed a "systemd-private-foobarbas-apache2.service-cookie42" directory there... That contained nothing but a "tmp" directory with 777 as its permission, owned by the process' user and group.
Overriding that unit file option finally fixed the issue completely.
I have just one question - Why? Why change something that worked for decades? I understand that, in case you save something into /tmp, it may be read by 3rd parties or programs, but I am of the opinion that, if you did that, its only and only your fault if you wrote sensitive data into the temporary directory.
And as far as I am aware, by default, Apache does not actually write anything even remotely sensitive into /tmp, so...
Why. WHY!
I wasted 4 hours of my life debugging this! Only to find out its just another SystemD-enabled "feature" now!
And as much as I love kidding on SystemD, this time, I see it more as a fault of the package maintainers, because... I found no default apache2/httpd service file in the apache repo mirror... So...8 -
Helpdesk: We can't figure out our own ambigious error message, you should solve it in another way...
Me: I see in the console that I get an execption response with an ID, you must be logging these exceptions, can't you check those?
Me thinking: you've just reduced yourself to desk without the help part -
Avoid ACPICA if at all possible. It's one garbage tier cluster fuck of bad design, horrible documentation and downright misleading and wrong code
It's meant to consist of an ASL compiler, disassembler, debugger, dumper, various user space utitilies and a kernel resident OSPM implementation *if* you can figure out what belongs to what. Even just compiling this pile of trash is a mystery in itself. Think you need the source files in source/common? EEEEH, wrong. Well, at least partially since most of them seem to be for the user space stuff..? Other ones *are* needed on the other hand. At least the disassembler and/or debugger and/or dumper components seem to reference them. Not that I could figure out how to compile those anyways. The real path to your goal seems to be to ignore a seemingly arbitrary subset of source and header files until your linker stops complaining
There's also a bunch of configuration defines, some of which *you* define, some defined *for* you, based on again others. Of course most of them do stupid shit. Enabling the debugger automatically enables debug logging. Enabling the disassembler force enables debug allocation tracking... What?
The code itself isn't of much help either. Looking in "os_specific/service_layers" you find what looks to be reference implementations of acpica functions in certain os' like windows and unix. Of course I had a look because AcpiOsReadMemory is supposed to read physical memory and I don't know how I would even implement that. But hey, osunixxf.c (xf for interface... of course) should tell me. I'll let you see for yourself in the attached image. Apparently it does fuck all and just returns AE_OK. No error, no logging, no nothing. Just ok. As you can imagine, AcpiOsWriteMemory doesn't do much more either.
...okay so maybe physical memory accesses aren't actually used and these functions are some sort of relic from past times? Nope! They are absolutely necessary for doing low level device interaction. WTF. So finally I went to the linux source and checked how *they* implemented them, and just as I thought, these functions are anything but no-ops...
...So for what fucking reason do these stupid interface implementations even exist but to purposefully mislead you?? They aren't used for fucking anything! As far as I know Windows doesn't even *use* ACPICA and Linux have their own fork with working implementations... They just sit there, just to tell you how to NOT do it
So that's some of my thoughts about ACPICA. Note that I haven't even used it as a library yet, I just got it to compile and link and it already fucked with me this much.
There's also so much more I didn't mention like that you *have* to modify the acpica source in order to get your own platform header working (else #error) eventhough the docs explicitely instruct you not too but you get the point
Don't use ACPICA if you don't have to. Save your sanity for something that's worth it
-
SO MAD. Hands are shaking after dealing with this awful API for too long. I just sent this to a contact at JP Morgan Chase.
-------------------
Hello [X],
1. I'm having absolutely no luck logging in to this account to check the Order Abstraction service settings. I was able to log in once earlier this morning, but ever since I've received this frustratingly vague "We are currently unable to complete your request" error message (attached). I even switched IP's via a VPN, and was able to get as far as entering the below Identification Code until I got the same message. Has this account been blocked? Password incorrect? What's the issue?
2. I've been researching the Order Abstraction API for hours as well, attempting to defuddle this gem of an API call response:
error=1&message=Authentication+failure....processing+stopped
NOWHERE in the documentation (last updated 14 months ago) is there any reference to this^^ error or any sort of standardized error-handling description whatsoever - unless you count the detailed error codes outlined for the Hosted Payment responses, which this Order Abstraction service completely ignores. Finally, the HTTP response status code from the Abstraction API is "200 OK", signaling that everything is fine and dandy, which is incorrect. The error message indicates there should be a 400-level status code response, such as 401 Unauthorized, 403 Forbidden or at least 400 Bad Request.
Frankly, I am extremely frustrated and tired of working with poorly documented, poorly designed and poorly maintained developer services which fail to follow basic methodology standardized decades ago. Error messages should be clear and descriptive, including HTTP status codes and a parseable response - preferably JSON or XML.
-----
This whole piece of garbage is junk. If you're big enough to own a bank, you're big enough to provide useful error messages to the developers kind enough to attempt to work with you. 2
2 -
Ran the build today 4:30 and found out our grunt file is missing some pretty critical error checks without even logging a warning. A dependency was unavailable and it was pushed to production. The site was down for 30+ minutes.1
-
Once I implemented a giant ASCII skull for logging a fatal error in the company's app. Let's just say my feature did not get to production.4
-
At work, all errors within the site are logged into our database with a subject and error column. SQL errors are logged in the subject field while the traceback is put in the error column. However, a lot of SQL errors are really large and exceed the max character width of the subject field, causing yet another SQL error, and the cycle repeats. This recursive error has been the bane of my existence, because 1) it times my local dev instance out and 2) the error doesn't end up getting logged because the server both freezes and the error can't be inserted in the database. You can't even begin to imagine how many hours I've wasted trying to find what line I changed cause total and utter failure with absolutely 0 error logging. Next thing on my todo list is to fix this fucking issue since the head dev refuses to get it done.1
-
2 hour meeting to brainstorm ideas to improve our system health monitoring (logging, alerting, monitoring, and metrics)
Never got past the alerting part. Piss poor excuses for human being managers kept 'blaming' our logging infrastructure for allowing them to log exceptions as 'Warnings', purposely by-passing the alerting system.
Then the d-head tried to 'educate' everyone the difference between error and exception …frack-wad…the difference isn't philosophical…shut up.
The B manager kept referring to our old logging system (like we stopped using it 5 years ago) and if it were written correctly, the legacy code would be easier to migrate. Fracking lying B….shut the frack up.
The fracking idiots then wanted to add direct-bypass of the alerting system (I purposely made the code to bypass alerting painful to write)
Mgr1: "The only way this will work is if you, by default, allow errors to bypass the alerting system. When all of our code is migrated, we'll change a config or something to enable alerting. That shouldn't be too hard."
Me: "Not going to happen. I made by-passing the alert system painful on purpose. If I make it easy, you'll never go back and change code."
Mgr2: "Oh, yes we will. Just mark that method as obsolete. That way, it will force us to fix the code."
Me: "The by-pass method is already obsolete and the teams are already ignoring the build warnings."
Mgr1: "No, that is not correct. We have a process to fix all build warnings related to obsolete methods."
Mgr2: "Yes. It won't be like the old system. We just never had time to go back and fix that code."
Me: "The method has been obsolete for almost a year. If your teams haven't fixed their code by now, it's not going to be fixed."
Mgr1: "You're expecting everything to be changed in one day. Our code base is way too big and there are too many changes to make. All we are asking for is a simple change that will give us the time we need to make the system better. We all want to make the system better…right?"
Me: "We made the changes to the core system over two years ago, and we had this same conversation, remember? If your team hasn't made any changes by now, they aren't going to. The only way they will change code to the new standard is if we make the old way painful. Sorry, that's the truth."
Mgr2: "Why did we make changes to the logging system? Why weren't any of us involved? If there were going to be all these changes, our team should have been part of the process."
Me: "You were and declined every meeting and every attempt to include your area. Considering the massive amount of infrastructure changes there was zero code changes required by your team. The new system simply worked. You can't take advantage of the new features which is why we're here today. I'm here to offer my help in any way I can with the transition."
Mgr1: "The new logging doesn't support logging of the different web page areas. Until you can make that change, we can't begin changing our code."
Me: "Logging properties is just a name+value pair dictionary. All you need to do is standardize on a name and how you add it to the collection."
Mgr2: "So, it's not a standard field? How difficult would it be to change the core assembly? This has to be standard across all our areas and shouldn't be up to the developers to type in anything they want."
- Frack wads smile and nod to each other like fracking chickens in a feeding frenzy
Me: "It can, but what will you call this property? What controls its value?"
- The look I got from both the d-bags I could tell a blood vessel popped.
Mgr1: "Oh…um….I don't know…Area? Yea … Area."
Mgr2: "Um…that's not specific enough. How about Page?"
Mgr1: "Well, pages can cross different areas, and areas cross different pages…what do you think?"
Me: "Don't know, don't care. It's up to you. I just need a name."
Mgr2: "Modules! Our MVC framework is broken up in Modules."
DevMgr: "We already have a field for Module. It's how we're segmenting the different business processes"
Mgr1: "Doesn't matter, we'll come up with a name later. Until then, we won't make any changes until there is a name."
DevMgr: "So what did we accomplish?"
Me: "That we need to review the web's logging and alerting process and make sure we're capturing errors being hidden as warnings."
Mgr1: "Nooo….we didn't accomplish anything. This meeting had no agenda and no purpose. We should have been included in the logging process changes from day one."
Mgr2: "I agree, I'm not sure why we're here"
Me: "This was a brainstorming meeting as listed in the agenda. We've accomplished 2 of the 4 items. I think we've established your commitment to making the system better. Thank you all for coming."
- Mgr1 and 2 left without looking at me or saying a word.1 -
Microsoft and their dev tools...
> Trying to login to Azure VM
> Get an error, saying that password needs to be changed before logging in the first time
> Head over to Azure portal, try resetting password
> Password reset is not successful. Reason: Account already exists (???)
> Google the error message. Found solution (coming from a Microsoft employee!): Create a new user, login with that, fix the password for user #1 inside the VM, then delete the new user
What's wrong with these people? 😂3 -
I like my log messages to indicate automatically where in the code something happened, so that I can easily identify where a message originated from while tracking down problems.
In C/C++ this is nice and easy - write a logging routine, wrap it in macros for the different log levels and have that automatically output __FILE__, __LINE__ etc.
I wanted to do something similar in NodeJS, as I'd found myself manually writing the file name in the log message and then splitting functionality out into new files and it became a mess.
The only way I found to be able to do this was to create an "Error" object and access the "stack" member of it. This is a string containing a stack backtrace, suitable for writing to console/file. I just wanted the filename/line/routine.
So I ended up splitting the string into lines, then for each of the lines, trimming the surrounding spaces (or tabs?), and parsing them to see if the stack entry is inside my logger module. The first entry outside of that module must therefore be the thing that called it, so I then parse out the routine or object and method, filename and line number.
It's a lot of clumsy work but the output is pretty neat. I just wish it were simpler!2 -
God I fucking hate macs.
I got a mac at work. I tried to install ubuntu, with rather questionable results (unfortunately, I expected that) - so I tried to get mac work for me the way I like a system to work. I needed to download slack, simple enough, right? Ha, you wish. It's gotta be done through Apple store, so I went to create an Apple ID inside the Apple Store form. And, well, it just errored out on the submission. Great start. I went then to the settings and created an account there, great success, went back to Apple Store. Unfortunately being logged in at the system level doesn't mean you are logged in to the store. So, I went to log in to the store, simple enough, right? No, nothing's simple with Apple. After logging in I got a message that the Apple ID has not yet been used with Apple Store and that I need to review the account's setting. So, I click the "review" button and... I'm presented with a log in form. Yep, a perfect log in loop. I can't log in because I can't review the account but I can't review the account because I can't log in. Fun :)
You can't just go to the web admin panel for your account to review it for Apple Store, that would too be too easy. After a bit of searching I've found an answer on StackOverflow. You need to log in to iTunes. Through a fucking MUSIC APP. To install a free application from the store you need to log in to a music app. Yes, we're all mad here.
Then, after finding out that to be able to use side buttons on my mouse I need an app that I need to manually restart every time I restart the machine and that I need to have an app to fucking transfer files from an android I need another fucking app, because reading a storage of a linux-based system would be too standards compliant - something in me broke. I found out that installing windows on a mac is officially supported.
Supported doesn't mean that it's easy. I tried to install it trying different solutions from SO, but each time I would get an error that Windows couldn't modify the boot partition. Turns out that even wiping the drive and reinstalling OSX doesn't remove residual files on a boot partition and Windows installer is not allowed to modify them. It took me hunting into some shady looking site to actually find this answer. I have no fucking idea how long it all took me, but, finally, great success, Windows, WSL, side buttons working, I can even install slack from an installer. I just wish I could have those hours of my life back.12 -
Today after longer vacation I came back to work.
Edit: wrote this rant long time ago, but never finished. Was too pissed.
Some easy meetings, then wanted to start on an easy job.
Just migrating some things from bash regex voodoo to proper tools like JQ.
Finished in roughly 1 h. Lovely.
Made some tea, ate some cookies.
Set up dev environment, found no documentation what so ever, got it running after half an hour.
Annoying, but ok.
Then I tried my scripts...
They worked... Except they didn't.
Console log empty, response code 200 with state: GENERATE_NO_FILES.
Eh. Fuck you. Just fuck you.
Fixed the logging configuration, which was broken since uhm... 2 years plus?
Well... Another half another hour gone...
Kinda pissed now.
Still script return failed...
Poking and trying to sprinkle debug all over that shit cause everything seems ... An incohesive, inconsistent diarrhea.
3 hours later...
Made the ticket to rewrite it.
I did nothing wrong at all.
The API just has no workflow at all. The
*seperate* API calls have to be in an **specific** order - as otherwise the generation will fail, as the prerequisites for the generation are not fulfilled.
Yeah. Completely logical. Especially not to give out any kind of warning or an error message like requirements not met, blablabla.
I drank that evening 2 six packs of beer. I was raging mad....
Then gave that shit to another manager, as I never want to touch that nuclear waste again....
How can someone be so brain damaged -.-1 -
I'm considering quitting a job I started a few weeks ago. I'll probably try to find other work first I suppose.
I'm UK based and this is the 6th programming/DevOps role I've had and I've never seen a team that is so utterly opposed to change. This is the largest company I've worked for in a full time capacity so someone please tell me if I'm going to see the same things at other companies of similar sizes (1000 employees). Or even tell me if I'm just being too opinionated and that I simply have different priorities than others I'm working with. The only upside so far is that at least 90% of the people I've been speaking to are very friendly and aren't outwardly toxic.
My first week, I explained during the daily stand up how I had been updating the readmes of a couple of code bases as I set them up locally, updated docker files to fix a few issues, made missing env files, and I didn't mention that I had also started a soon to be very long list of major problems in the code bases. 30 minutes later I get a call from the team lead saying he'd had complaints from another dev about the changes I'd spoke about making to their work. I was told to stash my changes for a few weeks at least and not to bother committing them.
Since then I've found out that even if I had wanted to, I wouldn't have been allowed to merge in my changes. Sprints are 2 weeks long, and are planned several sprints ahead. Trying to get any tickets planned in so far has been a brick wall, and it's clear management only cares about features.
Weirdly enough but not unsurprisingly I've heard loads of complaints about the slow turn around of the dev team to get out anything, be it bug fixes or features. It's weird because when I pointed out that there's currently no centralised logging or an error management platform like bugsnag, there was zero interest. I wrote a 4 page report on the benefits and how it would help the dev team to get away from fire fighting and these hidden issues they keep running into. But I was told that it would have to be planned for next year's work, as this year everything is already planned and there's no space in the budget for the roughly $20 a month a standard bugsnag plan would take.
The reason I even had time to write up such a report is because I get given work that takes 30 minutes and I'm seemingly expected to take several days to do it. I tried asking for more work at the start but I could tell the lead was busy and was frankly just annoyed that he was having to find me work within the narrow confines of what's planned for the sprint.
So I tried to keep busy with a load of code reviews and writing reports on road mapping out how we could improve various things. It's still not much to do though. And hey when I brought up actually implementing psr12 coding standards, there currently aren't any standards and the code bases even use a mix of spaces and tab indentation in the same file, I seemingly got a positive impression at the only senior developer meeting I've been to so far. However when I wrote up a confluence doc on setting up psr12 code sniffing in the various IDEs everyone uses, and mentioned it in a daily stand up, I once again got kickback and a talking to.
It's pretty clear that they'd like me to sit down, do my assigned work, and otherwise try to look busy. While continuing with their terrible practices.
After today I think I'll have to stop trying to do code reviews too as it's clear they don't actually want code to be reviewed. A junior dev who only started writing code last year had written probably the single worst pull request I've ever seen. However it's still a perfectly reasonable thing, they're junior and that's what code reviews are for. So I went through file by file and gently suggested a cleaner or safer way to achieve things, or in a couple of the worst cases I suggested that they bring up a refactor ticket to be made as the code base was trapping them in shocking practices. I'm talking html in strings being concatenated in a class. Database migrations that use hard coded IDs from production data. Database queries that again quote arbitrary production IDs. A mix of tabs and spaces in the same file. Indentation being way off. Etc, the list goes on.
Well of course I get massive kickback from that too, not just from the team lead who they complained to but the junior was incredibly rude and basically told me to shut up because this was how it was done in this code base. For the last 2 days it's been a bit of a back and forth of me at least trying to get the guy to fix the formatting issues, and my lead has messaged me multiple times asking if it can go through code review to QA yet. I don't know why they even bother with code reviews at this point.15 -
Developer just emailed our team a complaint that our logging assembly was resulting in their poor test coverage and they sent a change request to give them the ability to mock the underlying log provider (ex. from the event log to ‘something else’).
Looked at their tests, and they are testing whether or not the .Log was executed (on an exception, if the .Log method was not executed, the test failed), which seemed a bit worthless because we’ve already got coverage in our unit tests.
We had a meeting to discuss the issue.
Me: “I’m OK with changing the logging code if it’s necessary, but I want to understand why.”
DevA: “Logging errors is crucial to the database transaction. If someone removes the logging, the tests should fail.”
Me: “If someone removes the error logging on purpose, then they likely have an agenda and will remove the test validation too. It wouldn’t be an accident.”
DevA: “That’s not my problem. They will have to deal with HR.”
Me: “We purposely prevented someone from intercepting the logging just for that purpose. Your test code already covers the business rule, testing the logging seems out of place. That would like writing a test to make sure the System.IO.File.ReadAllText actually reads all the text from a file. You kinda assume a few smart Microsoft engineers already wrote tests for that.”
DevA: “Yea, I guess that would be silly.”
Got cc’ed an email a little bit ago from DevA to his boss..
“We’re not going to be able to change logging assembly. This may have some impact on our overall test coverage as those lines of code will not get testing coverage. You will have to let the DevMgr know we will not meet our test coverage goals.”
WTF!1 -
Bruh, imagine paying taxes for a site that literally throws a cryptic error message, instead of telling you "Page not found", because those retards literally redirect to /Account/Login after successfully logging in.
Even better, most people here are don't understand English well enough to understand what is going on.
And I pretty much doubt an admin has been informed... 3
3 -
Multi User, One Account, and other shit
I'm gonna rant about something as a user, and someone who makes stupid web stuff.
My bank has been updating their web banking over time and they decided that every individual on an account, should have their own login. They really want to push this on their users, I suspect specifically folks like me and my wife who share one login for the joint accounts we have at the bank together.
Why share one login, because it's the only sure fire way I know that I and my wife can see all the same shit no doubt about it.
The banks never tell you what you can see or can't with joint accounts, I doubt it is even documented on their end, but in every damn case something is hidden or different in some weird way.
Messages to the bank people? If I send it, my wife often can't. I get that for security reasons that's a thing, but it makes no sense for a joint account.
ANY difference to me breaks online banking ENTIRELY. Joint accounts are supposed to be... well one account that is the same.
Other banks we used where we had different logins for the joint account, each login actually had separate bill pay accounts per user. So if I went to bill pay and scheduled something to be paid, my wife had no idea, same if she did.
Right fucking there, banking is just broken entirely!
So no Mr. Bank, fuck you we're both logging in via the same login.
Fast forward to N00bPancakes making a thing.
So my employer has a customer (Direct Customer). Direct Customer wants a thing that makes communication with their customer (Indirect Customer) easier.
The worst thing about making something for your customer's customer is that Direct Customer always imagines that Indirect Customer is gonna be super ninja power users....
But no, that's not the case... in fact almost nobody is a power user, and absolutely nobody WANTS to be a power users.
Worse yet in my case the only reason this tool exists is because Direct Customer and Indirect Customer can't communicate well enough anyway... that should tell you something about the amount of effort Indirect Customer is willing to expend.
So with that tool, this situation constantly comes up:
Direct Customer thinks it would be great if every user from Indirect Company had some sort of custom messaging, views, and etc in of Cool Communication Tool. The reason is because that's what Direct Customer loves about Ultra Complex Primary Tool that they use ....
Then I have to fight the constant fight of:
NOBODY WANTS TO BE A POWER USER, NOBODY EVEN WANTS TO DO MUCH OF ANYTHING ON THE INTERNET THAT ISN'T SCREAMING AT OTHER PEOPLE OR POST MEMES OR WATCH SHITTY VIDEOS. THE MOMENT ANYONE AT INDIRECT COMPANY LOGS IN AND SEES ANY INFO THAT IS DIFFERENT FROM THEIR COWORKER THEY'LL SHIT THEMSELVES, FLOOD EVERYONE WITH 'OH GAWD SOME NON SPECIFIED THING IS WRONG' AND RESPOND TO EMAILS LIKE A JELLYFISH DROPPED OFF IN NEW MEXICO... AND NOTHING WILL GET DONE!!!
God damn it people.
Also side rant while I'm busy fighting the good fight to keep shit simple and etc:
People bitch about how horrible the modern web is and then bitch at web devs like we're rulers of the internet or something.... What really pisses me off about that is other devs who do that.... like bro, do you make policy at your company? You decide not to sell some info or whatever shit your company sells? Like fuck off with your 'man I miss html' because you got scared by some shitty JS error and ran back to your language of choice and just poked your head out of the the basement and got scared... and you shit on another developer about that? Fuck you. -
Spent hours trying to connect to a remote desktop using RDP, it was logging from win 7 but gives error with win 10.
Later, I discovered the solution was to add the computer name before the username!!!!
computername/username -
Boss: I don't want centralized error logging
Me: But we have 50+ client sites running the same web app, why the fuck wouldn't we?
Boss: What if the database is offline, then we wouldn't be able to log exceptions
Me: *beats head against desk*1 -
Microsoft certsrv is returning UTF-8 on the authorization error page but UTF-16 when logging in via basic auth...
Debugged this for 2 hours today to parse the response correctly. Thanks Microsoft -
So to give you a feel for what evil, clusterfuck code it was in: this projects largest part was coded by a maniac, witty physicist confined in the factory for a month, intended as a 'provisional' solution of course it ran for years. The style was like C with a bit of classes.. and a big chunk of shared memory as a global mud of storage, communication and catastrophe. Optimistic or no locking of the memory between process barriers, arrays with self implemented boundary checks that would give you the zeroth element on failure and write an error log of which there were often dozens in the log. But if that sounds terrifying already, it is only baseline uneasyness which was largely surpassed by the shear mass of code, special units, undocumented madness. And I had like three month to write a simulator of the physical factory and sensors to feed that behemoth with the 'right' inputs. Still I don't know how I stood it through, but I resigned little time afterwards.
Well, lastly to the bug: there was some central map in that shared memory that hold like view of the central customer data. And somehow - maybe not that surprisingly giving the surrounding codebase - it sometimes got corrupted. Once in a month or two times a day. Tried to put in logging, more checks - but never really could pinpoint the problem... Till today I still get the haunting feeling of a luring memory corruption beneath my feet, if I get closer to the metal core of pure C.1 -
Wanted to get to bed early tonight, but ended up wasting two hours after I moved code from my development machine over to a test system and it was failing. After adding all kinds of logging to figure out where it was failing on the test machine i realized i fixed am error in an input file on my dev machine, but that error in the input fine was still there on the test machine. Another night with little sleep and tomorrow is Monday. 😭
-
I hate reading tons of informative logging lines that libraries and frameworks produce (Spring and NodeJS, for example).
npm install somelib
(depending on the software): 200 lines of text of information regarding the progress. This is the equivalent of displaying 200 alert boxes. lol.
Wait.. where was the error.. ah, there, that one relevant piece of text. I only had to visually scan 199 others..
Yeah, I know, I can configure them to only display a certain category (info, dev, etc) but it's annoying when that's not the case.4 -
Wanted to add a simple log entry when a model changes state in a certain way.
Unit tests pass, functional tests pass, manual tests through application GUI pass.
But for some fucking reason the single line logging call I added results in an error 500 when the application is accessed through a REST API.
Going to have a fun day tomorrow debugging this shit. -
What the hell is the point of this small projects team spending 2-3 months on developing extensive logging system for an internal application for inside and outside customers to use if your application isn’t going to log any of the fucking errors. Sure you write the failure status to the database, but it just says failure with an even more vague explanation than microsoft’s errors. “An error occurred”. No shit, that’s why I’m looking in the logs and database to debug the application to get these files on their merry way so our company can stay in compliance with the state, feds, and not pay out the wazzoo in fines. All our other applications state where the error occured such as “failed to connect to the email server”, why can’t this one.
-
> Error
> Error
> Adds "console.log(valueThatIsRelatedToError)"
> Smiles because I managed to not fuck up logging to the console1 -
Note: I had AI rephrase this because apparently it was too full of swearing or smth to be accepted and I was getting a "there was an error posting this rant". Nice that people at devrant's can't even show a clear error of WTF is going on, not even in chrome dev tool console/network requests, so maybe you're able to figure out WTF is going on and fix your post. They must be the same kind of people I'm ranting about.
-----------End of the note.----------------
TL;DR;: My coworkers are smart idiots that learn fast but can't control themselves into turning any project into a trashcan of spaghetti code and I'm burning out and want to switch for couple years to a simpler job.
I'm considering leaving my career in programming, consulting, and project management in favor of a more straightforward, manual labor job—perhaps something like baking or another role that relies on physical effort rather than constant problem solving.
I’ve reached a point where I can no longer tolerate the challenges of my current position, especially due to the dynamics with my coworkers. I long for a day where I can work for eight hours, exhaust myself physically, and then go home without any lingering mental responsibilities or ties to complex problem solving.
Over the past decade, I’ve collaborated with many people, yet I've only had the opportunity to manage an entire project from scratch on my own twice. In those rare instances, everything ran smoothly, issues were quickly resolved, and the code remained stable for years without constant complaints from clients.
Unfortunately, my coworkers, despite their intelligence, tend to overcomplicate even simple tasks. They often fall into the trap of overengineering, chasing the latest technologies and implementing unnecessarily complex paradigms, design patterns, frameworks, and techniques—even when I’ve offered simpler, proven solutions.
For example, I’ve built robust portals that handle everything from national highway finances and warehousing to HR and inventory management for major companies. In contrast, when others attempt similar projects, the resulting code becomes overwhelmingly complex and difficult to manage.
To give a few specific examples:
Example 1: The .NET Portal
We began developing a .NET portal about two months ago, which is now nearing version 1.0. Before we even started, the team had created multiple flowcharts to split the project into components like SaaS deployment, Docker integration, obfuscation, and separate portals for user administration and backend processes. Within a few weeks, they scrutinized and debated numerous authentication technologies—even though we had successfully implemented JWT token solutions in the past. The team continually shifts focus, leaving me uncertain about the final direction.
Example 2: Over-Engineering with Patterns
In another project, the team overused inversion of control (IoC) and mediation patterns, even going so far as to have an AI generate a custom message bus. Navigating this overly decoupled code is challenging; even Visual Studio’s IntelliSense struggles to provide guidance, and the code often feels like a puzzle that changes whenever I return from a break.
Example 3: Complicated Logging Implementation
We needed to add logging functionality, and I proposed a simple solution using custom exceptions that would bubble up to a central logging mechanism. Despite its past success in saving time and reducing frustration, the team decided to implement three different logging methods—one using .NET’s ILogger, another with Serilog, and a third hybrid approach. They even suggested using a rarely seen technique involving stack traces to determine which function threw an error. This approach added unnecessary complexity and only increased my frustration.
Now, even though the project is too far along for me to withdraw, I find myself feeling burned out just a few days back at work. The code has become a tangled mess, and even routine tasks like adding logging are turning into sources of intense frustration due to constantly shifting ideas and overly complicated designs.
On top of all this, I’m also disappointed with the performance of AI tools, which seem to be producing unreliable code that requires further fixes, compounding my frustration.
I’m now seriously contemplating a complete career change—perhaps even moving to a country with a better work environment, such as Denmark or Switzerland—in the hope of finding a job where the work is more straightforward and less mentally taxing and better paying4 -
Half a day wasted. FUCK!
I use grafana loki and mimir/prometheus for telemetry. A few days ago I queried loki to see if logging is still working. Yesterday I changed the datasource to mimir, changed the query parameters to get metrics from another env, ran the query, and... Querier [mimir] crashed.
Wtf.
Error says it got too much data to chew on.
So I spend 4 hours playing with the querier and grpc limits, balancing between limit errors and OOMKills [2G ram].
I got suspicious about oomk. Why would it...
Then I tried to shrink the timeframe to 15min. Still oomk. Down to 5min -- now it worked. But the number of different metrics returned was over 1k
then I look once again at the query. And ofc it is ´{env="prod"}´
turns out, forgetting that you're querying metrics with a logs' query is an expensive and frustrating mistake. Esp. at 3am.
idk why it even returned me anything...5 -
when the stack trace wasn't included in the error logging
fuck me, how the fuck am i supposed to know where the exception occurred
perhaps i've taken it all for granted thinking that the default toString implementation of an exception would've included that5 -
Compare and harmonize the web configs
Oh no someone set execution timeouts to 14 days
Fuck fuck fuckity duck
Hey compare all the web configs of all environments and harmonize them all wtf cmon bruh do your job as a developer
Take them and back them up into svn. What do you mean svn isn't a back up system of course it is well its the only thing we have fuck
What do you mean we have shit logging where people will catch an exception and only print the word exception in the log you can figure it out can't you we have live produxtion issues that hace to be solved now what the fuck
How dare you make a. Mistake copying our shitload of a bloated codebase and configuring our 100s of different options all by fukcing hand what the fuck dude do yoh write anyrhing down?
Please catalogue all the exception mails we are getting but we have no db or error reporting system so they all just plop into tue inbox and thats all ypur fuckjng data figure it out kid
This is a rewarding, fulfilling job whwrw you can be both dev ops and a developer and manage all of our fucking environments of which there are about 15 of all your own with no sort of tool or software to aid you because haha what the fuck we wouldn't make your life easy
Whata that you want to spend time to write stuff or change stuff that will nake it easier fot you fuxk that bruh get back to your biklable tasks like holy shit you thjnk this is a charity ofr aomw shit
Live production issues
Live production issues
Produxtion issues. A ghost in the machine. Find it fix if find it fix it find it fix it cmon why can't you fix it I expect you to spend your day hopelessly pretending to try to solve something you fucker
One of the only peopel able to help you sometimes though hes a bit of an old laxky, yeah hea fucking leaving see ya seeya kid and now we're not hirinf anyone to fuckjng help you no no no managing and monitoring the environments its your jov alll fof them every sngle on do you knkw all the xonfiguraiton values for them yet??
Instead we are hiring a new sales person to fucking make us some more money and we don't need naother seceloper to help you infqct lets have you use this mid end retail computer from 2014 to develop on yeah yeah oh but all our shitty code and visual studip will destry your memory but too bad!! Hahahahahdhsj
Go lice is all you, why sare you so slow
How long will it take
How long will it take
How long will it take
How long witll it tqk2
How long will it take holy shit
Give time estimate for sonethign that I don't fucking know how about it will tqke till fuxk you oxloxk4 -
I've just learned that our front-end application throws a simple 404 error when trying to retrieve an avatar that does not exists.
But our technicians/support use this error in the console to show the customers that there is indeed a problem with the application functionality but have unsufficient logging from the back-end to troubleshoot with their internal tools.
What a bunch of liars trying to keep the customer satisfied and it works relatively well :D2 -
So, do any of your poor fuckers have the opportunity - nay, PRIVILEGE of using the absolute clusterfuck piece of shit known as SQL Server Integration Services?
Why do I keep seeing articles about how "powerful" and "fast" it is? Why do people recommend it? Why do some think it's easy to use - or even useful?
It can't report an error to save its life. It's logging is fucked. It's not just that it swallows all exceptions and gives unhelpful error messages with no debugging information attached, its logging API is also fucked. For example, depending on where you want to log a message - it's a totally different API, with a billion parameters most of which you need to supply "-1" or "null" to just to get it do FUCKING DO SOMETHING. Also - you'll only see those messages if you run the job within the context of SQL FUCKING SERVER - good luck developing on your ACTUAL FUCKING MACHINE.
So apart from shitty logging, it has inherited Microsoft's insane need to make everything STATICALLY GODDAMN TYPED. For EVERY FUCKING COMPONENT you need to define the output fields, types and lengths - like this is 1994. Are you consuming a dynamic data structure, perhaps some EAV thing from a sales system? FUCK YOU. Oh - and you can't use any of the advances in .NET in the last 10 years - mainly, NuGet and modern C# language features.
Using a modern C# language feature REMOVES THE ABILITY TO FUCKING DEBUG ANYTHING. THE FUCKER WILL NOT STOP ON YOUR BREAKPOINTS. In addition - need a JSON parsing library? Want to import a SDK specific to what you're doing? Want to use a 3rd party date library? WELL FUCK YOU. YOU HAVE TO INDEPENDENTLY INSTALL THE ASSEMBLIES INTO THE GAC AND MAKE IT CONSISTENT ACROSS ALL YOUR ENVIRONMENTS.
While i'm at it - need to connect to anything? FUCK YOU, WE ONLY INCLUDE THE MOST BASIC DATABASE CONNECTORS. Need to transform anything? FUCK YOU, WRITE A SCRIPT TASK. Ok, i'd like to write a script task please. FUCK YOU IM GOING TO PAUSE FOR THE NEXT 10 MINUTES WHILE I FIRE UP A WHOLE FUCKING NEW INSTANCE OF VISUAL STUDIO JUST TO EDIT THE FUCKING SCRIPT. Heaven forbid you forget to click the "stop" button after running the package and open the script. Those changes you just made? HAHA FUCK YOU I DISCARDED THEM.
I honestly cant understand why anyone uses this shit. I guess I shouldn't really expect anything less from Microsoft - all of their products are average as fuck.
Why do I use this shit? I work for a bunch of fucks that are so far entrenched in Microsoft technologies that they literally cannot see outside of them (and indeed don't want to - because even a cursory look would force them to conclude that they fucked up, and if you're a manager thats something you can never do).
Ok, rant over. Also fuck you SSIS1 -
Relatively often the OpenLDAP server (slapd) behaves a bit strange.
While it is little bit slow (I didn't do a benchmark but Active Directory seemed to be a bit faster but has other quirks is Windows only) with a small amount of users it's fine. slapd is the reference implementation of the LDAP protocol and I didn't expect it to be much better.
Some years ago slapd migrated to a different configuration style - instead of a configuration file and a required restart after every change made, it now uses an additional database for "live" configuration which also allows the deployment of multiple servers with the same configuration (I guess this is nice for larger setups). Many documentations online do not reflect the new configuration and so using the new configuration style requires some knowledge of LDAP itself.
It is possible to revert to the old file based method but the possibility might be removed by any future version - and restarts may take a little bit longer. So I guess, don't do that?
To access the configuration over the network (only using the command line on the server to edit the configuration is sometimes a bit... annoying) an additional internal user has to be created in the configuration database (while working on the local machine as root you are authenticated over a unix domain socket). I mean, I had to creat an administration user during the installation of the service but apparently this only for the main database...
The password in the configuration can be hashed as usual - but strangely it does only accept hashes of some passwords (a hashed version of "123456" is accepted but not hashes of different password, I mean what the...?) so I have to use a single plaintext password... (secure password hashing works for normal user and normal admin accounts).
But even worse are the default logging options: By default (atleast on Debian) the log level is set to DEBUG. Additionally if slapd detects optimization opportunities it writes them to the logs - at least once per connection, if not per query. Together with an application that did alot of connections and queries (this was not intendet and got fixed later) THIS RESULTED IN 32 GB LOG FILES IN ≤ 24 HOURS! - enough to fill up the disk and to crash other services (lessons learned: add more monitoring, monitoring, and monitoring and /var/log should be an extra partition). I mean logging optimization hints is certainly nice - it runs faster now (again, I did not do any benchmarks) - but ther verbosity was way too high.
The worst parts are the error messages: When entering a query string with a syntax errors, slapd returns the error code 80 without any additional text - the documentation reveals SO MUCH BETTER meaning: "other error", THIS IS SO HELPFULL... In the end I was able to find the reason why the input was rejected but in my experience the most error messages are little bit more precise.2 -
TRUSTED IN REGAIN YOUR LOST CRYPT0|USDT|ETHEREUM WITH FOLKWIN EXPERT RECOVERY.
It all started with an irresistible promise: a guaranteed 110% return in just 14 days. The websites inversely com and copyread com were boasting about the incredible returns they could generate, claiming that if I invested $1,000, I would see $1,100 in return after only two weeks. As a novice investor, the idea of such rapid, high returns seemed like a once-in-a-lifetime opportunity. So, I decided to take the plunge and invested $30,000 into each platform, hoping to cash in on these “guaranteed” profits. The first few days passed without incident, and I started to feel confident that I was on the right track. However, as the 14-day period came to a close, my excitement quickly turned into frustration. Despite logging in to check on my funds, I couldn’t access any of my money. It was like my account had disappeared. Emails to customer service went unanswered, and any attempts to withdraw my earnings were met with a series of vague error messages. What I thought was a smart investment began to feel more like a nightmare. I was left completely stuck, unable to withdraw a single penny. It didn’t take long for me to realize that I had likely fallen victim to an online scam. Desperate and unsure where to turn, I reached out to a friend I met on TikTok, who had mentioned being in a similar situation before. They recommended that I get in touch with Folkwin Expert Recovery—a service they had used to recover their own lost funds from another shady platform. Skeptical but desperate, I decided to give it a try. To my surprise, the team at Folkwin Expert Recovery responded quickly and began to guide me through the process. They explained how common these types of scams were and assured me that they could help recover my money. After a financial commitment on my part, the team worked diligently to track down my lost funds. Within a few weeks, I had successfully recovered all of my $60,000.Thanks to ( FOLKWINEXPERTRECOVERY(@)TECH-CENTER. COM),Whatsapp/ +1 740-705-0711 I was not only able to get my money back but also received valuable advice on how to safely invest in cryptocurrency. They helped me understand which platforms are legitimate and how to avoid risky ventures in the future. The service they provided was truly invaluable, and I couldn’t be more grateful for their assistance. If you’ve found yourself in a similar situation caught up in a scam or unsure where to turn for help I highly recommend reaching out to Folkwin Expert Recovery the only solution, to recover lost or your stolen Crypto/Usd/Btc/Ethereum without falling victim to Scams....
Warm greetings,
Dr Michael Theodore. 1
1 -
This story starts with a call from the 1st line support that users were getting intermittent-production-only error in one of the key application my team were working on.
The problem was that the application was behind the hardened environment that we had no access to.
The only thing we could do is enable logging which in itself took a whole week to get approved. And the result the Developers favourite - NullReferenceException in one of the biggest methods, I've ever seen in my whole career. Needless to say, that was not very helpful and we were no closer to the solution.
What. A. Pain.
Frustrated with the issue and with business breathing down my neck I started slicing this Monster of a method into smaller and smaller chunks. Even if some action was just a one-liner that would not stop me to create a method. At one point I could no longer care for method names resorting to such classics like Method1, FooBar123 and DoStuff.
But. It. Worked.
After the next deployment logs were showing the same NullReferenceException but now the stack trace pointed me to some Method13.
The resulting stack trace finally allowed to pinpoint the issue. The fix then was just a simple null check.
While Dev team who did not appreciate my creative method naming it was obvious to everyone that even that was better than one big blob of code.
It might seem silly to separate the most obvious one-liners into their own methods and sometimes even whole classes but not living through that experience alone is worth it for me.
Did you ever found yourself in a situation where you wished your stack trace was just a little bit more in-depth? Tell me in the comments ^_^
So now go and look at your code and see if you can pepper it with smaller methods so that you stack traces can pave your way to your debugging success.
Originally posted on amoenus.dev/no-method-too-small-or-amoenus-dev 3
3














































Top Tags
Weekly Rant
View