
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Its Friday, you all know what that means! ... Its results day for practiseSafeHex's most incompetent co-worker!!!
*audience: wwwwwwooooooooo!!!!*
We've had a bewildering array of candidates, lets remind ourselves:
- a psychopath that genuinely scared me a little
- a CEO I would take pleasure seeing in pain
- a pothead who mistook me for his drug dealer
- an unbelievable idiot
- an arrogant idiot obsessed with strings
Tough competition, but there can be only one ... *drum roll* ... the winner is ... none of them!
*audience: GASP!*
*audience member: what?*
*audience member: no way!*
*audience member: your fucking kidding me!*
Sir calm down! this is a day time show, no need for that ... let me explain, there is a winner ... but we've kept him till last and for a good reason
*audience: ooooohhhhh*
You see our final contestant and ultimate winner of this series is our good old friend "C", taking the letters of each of our previous contestants, that spells TRAGIC which is the only word to explain C.
*audience: laughs*
Oh I assure you its no laughing matter. C was with us for 6 whole months ... 6 excruciatingly painful months.
Backstory:
We needed someone with frontend, backend and experience with IoT devices, or raspberry PI's. We didn't think we'd get it all, but in walked an interviewee with web development experience, a tiny bit of Angular and his masters project was building a robot device that would change LED's depending on your facial expressions. PERFECT!!!
... oh to have a time machine
Working with C:
- He never actually did the tutorials I first set him on for Node.js and Angular 2+ because they were "too boring". I didn't find this out until some time later.
- The first project I had him work on was a small dashboard and backend, but he decided to use Angular 1 and a different database than what we were using because "for me, these are easier".
- He called that project done without testing / deploying it in the cloud, despite that being part of the ticket, because he didn't know how. Rather than tell or ask anyone ... he just didn't do it and moved on.
- As part of his first tech review I had to explain to him why he should be using if / else, rather than just if's.
- Despite his past experience building server applications and dashboards (4 years!), he never heard of a websocket, and it took a considerable amount of time to explain.
- When he used a node module to open a server socket, he sat staring at me like a deer caught in headlights completely unaware of how to use / test it was working. I again had to explain it and ultimately test it for him with a command line client.
- He didn't understand the need to leave logging inside an application to report errors. Because he used to ... I shit you not ... drive to his customers, plug into their server and debug their application using a debugger.
... props for using a debugger, but fuck me.
- Once, after an entire 2 days of tapping me on the shoulder every 15 mins for questions / issues, I had to stop and ask:
Me: "Have you googled it?"
C: "... eh, no"
Me: "can I ask why?"
C: "well, for me, I only google for something I don't know"
Me: "... well do you know what this error message means?"
C: "ah good point, i'll try this time"
... maybe he was A's stoner buddy?
- He burned through our free cloud usage allowance for a month, after 1 day, meaning he couldn't test anything else under his account. He left an application running, broadcasting a lot of data. Turns out the on / off button on the dashboard only worked for "on". He had been killing his terminal locally and didn't know how to "ctrl + c a cloud app" ... so left it running. His intention was to restart the app every time you are done using it ... but forgot.
- His issue with the previous one ... not any of his countless mistakes, not the lack of even trying to make the button work, no, no, not for C. C's issue is the cloud is "shit" for giving us such little allowances. (for the record in a month I had never used more than 5%).
- I had to explain environment variables and why they are necessary for passwords and tokens etc. He didn't know it wasn't ok to commit these into GitHub.
- At his project meetups with partners I had to repeatedly ask him to stop googling gifs and pay attention to the talks.
- He complained that we don't have 3 hour lunch breaks like his last place.
- He once copied and pasted the same function 450 times into a file as a load test ... are loops too mainstream nowadays?
You see C is our winner, because after 6 painful months (companies internal process / requirements) he actually achieved nothing. I really mean that, nothing. Every thing was so broken, so insecure / wide open, built without any kind of common sense or standards I had to delete it all and start again ... it took me 2 weeks.
I hope you've all enjoyed this series and will join me in praying for the return of my sanity ... I do miss it a lot.
Yours truly,
practiseSafeHex20 -
Oh, man, I just realized I haven't ranted one of my best stories on here!
So, here goes!
A few years back the company I work for was contacted by an older client regarding a new project.
The guy was now pitching to build the website for the Parliament of another country (not gonna name it, NDAs and stuff), and was planning on outsourcing the development, as he had no team and he was only aiming on taking care of the client service/project management side of the project.
Out of principle (and also to preserve our mental integrity), we have purposely avoided working with government bodies of any kind, in any country, but he was a friend of our CEO and pleaded until we singed on board.
Now, the project itself was way bigger than we expected, as the wanted more of an internal CRM, centralized document archive, event management, internal planning, multiple interfaced, role based access restricted monster of an administration interface, complete with regular user website, also packed with all kind of features, dashboards and so on.
Long story short, a lot bigger than what we were expecting based on the initial brief.
The development period was hell. New features were coming in on a weekly basis. Already implemented functionality was constantly being changed or redefined. No requests we ever made about clarifications and/or materials or information were ever answered on time.
They also somehow bullied the guy that brought us the project into also including the data migration from the old website into the new one we were building and we somehow ended up having to extract meaningful, formatted, sanitized content parsing static HTML files and connecting them to download-able files (almost every page in the old website had files available to download) we needed to also include in a sane way.
Now, don't think the files were simple URL paths we can trace to a folder/file path, oh no!!! The links were some form of hash combination that had to be exploded and tested against some king of database relationship tables that only had hashed indexes relating to other tables, that also only had hashed indexes relating to some other tables that kept a database of the website pages HTML file naming. So what we had to do is identify the files based on a combination of hashed indexes and re-hashed HTML file names that in the end would give us a filename for a real file that we had to then search for inside a list of over 20 folders not related to one another.
So we did this. Created a script that processed the hell out of over 10000 HTML files, database entries and files and re-indexed and re-named all this shit into a meaningful database of sane data and well organized files.
So, with this we were nearing the finish line for the project, which by now exceeded the estimated time by over to times.
We test everything, retest it all again for good measure, pack everything up for deployment, simulate on a staging environment, give the final client access to the staging version, get them to accept that all requirements are met, finish writing the documentation for the codebase, write detailed deployment procedure, include some automation and testing tools also for good measure, recommend production setup, hardware specs, software versions, server side optimization like caching, load balancing and all that we could think would ever be useful, all with more documentation and instructions.
As the project was built on PHP/MySQL (as requested), we recommended a Linux environment for production. Oh, I forgot to tell you that over the development period they kept asking us to also include steps for Windows procedures along with our regular documentation. Was a bit strange, but we added it in there just so we can finish and close the damn project.
So, we send them all the above and go get drunk as fuck in celebration of getting rid of them once and for all...
Next day: hung over, I get to the office, open my laptop and see on new email. I only had the one new mail, so I open it to see what it's about.
Lo and behold! The fuckers over in the other country that called themselves "IT guys", and were the ones making all the changes and additions to our requirements, were not capable enough to follow step by step instructions in order to deploy the project on their servers!!!
[Continues in the comments]25 -
My first job: The Mystery of The Powered-Down Server
I paid my way through college by working every-other-semester in the Cooperative-Education Program my school provided. My first job was with a small company (now defunct) which made some of the very first optical-storage robotic storage systems. I honestly forgot what I was "officially" hired for at first, but I quickly moved up into the kernel device-driver team and was quite happy there.
It was primarily a Solaris shop, with a smattering of IBM AIX RS/6000. It was one of these ill-fated RS/6000 machines which (by no fault of its own) plays a major role in this story.
One day, I came to work to find my team-leader in quite a tizzy -- cursing and ranting about our VAR selling us bad equipment; about how IBM just doesn't make good hardware like they did in the good old days; about how back when _he_ was in charge of buying equipment this wouldn't happen, and on and on and on.
Our primary AIX dev server was powered off when he arrived. He booted it up, checked logs and was running self-diagnostics, but absolutely nothing so far indicated why the machine had shut down. We blew a couple of hours trying to figure out what happened, to no avail. Eventually, with other deadlines looming, we just chalked it up be something we'll look into more later.
Several days went by, with the usual day-to-day comings and goings; no surprises.
Then, next week, it happened again.
My team-leader was LIVID. The same server was hard-down again when he came in; no explanation. He opened a ticket with IBM and put in a call to our VAR rep, demanding answers -- how could they sell us bad equipment -- why isn't there any indication of what's failing -- someone must come out here and fix this NOW, and on and on and on.
(As a quick aside, in case it's not clearly coming through between-the-lines, our team leader was always a little bit "over to top" for me. He was the kind of person who "got things done," and as long as you stayed on his good side, you could just watch the fireworks most days - but it became pretty exhausting sometimes).
Back our story -
An IBM CE comes out and does a full on-site hardware diagnostic -- tears the whole server down, runs through everything one part a time. Absolutely. Nothing. Wrong.
I recall, at some point of all this, making the comment "It's almost like someone just pulls the plug on it -- like the power just, poof, goes away."
My team-leader demands the CE replace the power supply, even though it appeared to be operating normally. He does, at our cost, of course.
Another weeks goes by and all is forgotten in the swamp of work we have to do.
Until one day, the next week... Yes, you guessed it... It happens again. The server is down. Heads are exploding (will at least one head we all know by now). With all the screaming going on, the entire office staff should have comped some Advil.
My team-leader demands the facilities team do a full diagnostic on the UPS system and assure we aren't getting drop-outs on the power system. They do the diagnostic. They also review the logs for the power/load distribution to the entire lab and office spaces. Nothing is amiss.
This would also be a good time draw the picture of where this server is -- this particular server is not in the actual server room, it's out in the office area. That's on purpose, since it is connected to a demo robotics cabinet we use for testing and POC work. And customer demos. This will date me, but these were the days when robotic storage was new and VERY exciting to watch...
So, this is basically a couple of big boxes out on the office floor, with power cables running into a special power-drop near the middle of the room. That information might seem superfluous now, but will come into play shortly in our story.
So, we still have no answer to what's causing the server problems, but we all have work to do, so we keep plugging away, hoping for the best.
The team leader is insisting the VAR swap in a new server.
One night, we (the device-driver team) are working late, burning the midnight oil, right there in the office, and we bear witness to something I will never forget.
The cleaning staff came in.
Anxious for a brief distraction from our marathon of debugging, we stopped to watch them set up and start cleaning the office for a bit.
Then, friends, I Am Not Making This Up(tm)... I watched one of the cleaning staff walk right over to that beautiful RS/6000 dev server, dwarfed in shadow beside that huge robotic disc enclosure... and yank the server power cable right out of the dedicated power drop. And plug in their vacuum cleaner. And vacuum the floor.
We each looked at one-another, slowly, in bewilderment... and then went home, after a brief discussion on the way out the door.
You see, our team-leader wasn't with us that night; so before we left, we all agreed to come in late the next day. Very late indeed.9 -
Not a rant, but I found this funny enough to share.
About two weeks ago, I’m contacted by a third party development firm that is responsible for building the next iteration of a control board were are developing. Alongside build of the PCB they were scoped to flash the firmware and verify all connected components.
During the call, they tell me they don’t have the resources to build our testing environment with the Ansible script I provided, and they don’t know if the updates they have made will work with our control system. Ugh...really...
I attempt to walk them through the 3 pretty simple commands to launch the playbook. Instead of listening, their project manager insists that I need to load up the environment and send them a ready to go system.
I quickly load up a RaspberryPi and prepare it for shipping. I hand the box to our shipping clerk and fill out the shipping request documentation. Then about a week goes by and this is where the story really begins.
I get an email from the same rep asking where the environment is, and I head down to the warehouse to inquire where the RaspberryPi might be. After speaking with the head clerk, we can’t seem to track down the package. I’m assured that they will find the Pi and send me the shipment update.
I pass the information along and after about a day and a half I still didn’t receive word back from the warehouse team. I load up another Pi and head back down to the warehouse. I follow up with the warehouse staff. They inform me that they have not been able to locate my package and another warehouse worker is called over. He says he hasn’t seen it, but they they were having a food day that day and he thinks more than likely someone ate it.
Like it didn’t even click at first but after a few seconds I realize that these guys have literally been looking for a pie for the past two days...and I JUST DIE.
After the 5 or so minutes of laughing I show them the newly flashed RaspberryPi, and of course they know exactly where the original one was.
It’s shipped out now, but wow. Also, it turns out the PCB manufacturing company didn’t even really need this and it was all a guise to hide that they are behind schedule and that they will not be able to finish the work scoped. FML!6 -
THIS is why unit testing is important, I often see newbs scour at the idea of debugging or testing:
My high school cs project, i made a 2d game in c++. A generic top down tank game. Being my FIRST project and knowing nothing about debugging or testing and just straight up kept at it for 3 months. Used everything c++ and OOP had to offer, thinking "It works now, sure will work later"
Fast forward evaluation day i had over 5k lines of code here, and not a day of testing; ALL the bugs thought to themselves- "YOU KNOW WHAT LETS GUT THIS KID "
Now I did see some minor infractions several times but nothing too serious to make me refactor my code. But here goes
I started my game on a different system, with a low end processor about 1/4 the power of mine( fair assumption). The game crashed in loading screen. Okay lets do that again. Finally starts and tanks are going off screen, dead tanks are not being de-spawned and ended up crashing game again. Wow okay again! Backround image didn't load, can only see black background. Again! Crashed when i used a special ability. Went on for some time and i gave up.
Prof saw the pain, he'd probably seen dis shit a million times, saw all the hard work and i got a good grade anyways. But god that was embarrassing, entire class saw that and I cringe at the thought of it.
I never looked at testing the same way again. 5
5 -
I'm trying to sign up for insurance benefits at work.
Step 1: Trying to find the website link -- it's non-existent. I don't know where I found it, but I saved it in keepassxc so I wouldn't have to search again. Time wasted: 30 minutes.
Step 2: Trying to log in. Ostensibly, this uses my work account. It does not. Time wasted: 10 minutes.
Step 3: Creating an account. Username and Password requirements are stupid, and the page doesn't show all of them. The username must be /[A-Za-z0-9]{8,60}/. The maximum password length is VARCHAR(20), and must include upper/lower case, number, special symbol, etc. and cannot include "password", repeated charcters, your username, etc. There is also a (required!) hint with /[A-Za-z0-9 ]{8,60}/ validation. Want to type a sentence? better not use any punctuation!
I find it hilarious that both my username and password hint can be three times longer than my actual password -- and can contain the password. Such brilliant security.
My typical username is less than 8 characters. All of my typical password formats are >25 characters. Trying to figure out memorable credentials and figuring out the hidden complexity/validation requirements for all of these and the hint... Time wasted: 30 minutes.
Step 4: Post-login. The website, post-login, does not work in firefox. I assumed it was one of my many ad/tracker/header/etc. blockers, and systematically disabled every one of them. After enabling ad and tracker networks, more and more of the site loaded, but it always failed. After disabling bloody everything, the site still refused to work. Why? It was fetching deeply-nested markup, plus styling and javascript, encoded in xml, via api. And that xml wasn't valid xml (missing root element). The failure wasn't due to blocking a vitally-important ad or tracker (as apparently they're all vital and the site chain-loads them off one another before loading content), it's due to shoddy development and lack of testing. Matches the rest of the site perfectly. Anyway, I eventually managed to get the site to load in Safari, of all browsers, on a different computer. Time wasted: 40 minutes.
Step 5: Contact info. After getting the site to work, I clicked the [Enroll] button. "Please allow about 10 minutes to enroll," it says. I'm up to an hour and 50 minutes by now. The first thing it asks for is contact info, such as email, phone, address, etc. It gives me a warning next to phone, saying I'm not set up for notifications yet. I think that's great. I select "change" next to the email, and try to give it my work email. There are two "preferred" radio buttons, one next to "Work email," one next to "Personal email" -- but there is only one textbox. Fine, I select the "Work" preferred button, sign up for a faux-personal tutanota email for work, and type it in. The site complains that I selected "Work" but only entered a personal email. Seriously serious. Out of curiosity, I select the "change" next to the phone number, and see that it gives me four options (home, work, cell, personal?), but only one set of inputs -- next to personal. Yep. That's amazing. Time spent: 10 minutes.
Step 6: Ranting. I started going through the benefits, realized it would take an hour+ to add dependents, research the various options, pick which benefits I want, etc. I'm already up to two hours by now, so instead I decided to stop and rant about how ridiculous this entire thing is. While typing this up, the site (unsurprisingly) automatically logged me out. Fine, I'll just log in again... and get an error saying my credentials are invalid. Okay... I very carefully type them in again. error: invalid credentials. sajfkasdjf.
Step 7 is going to be: Try to figure out how to log in again. Ugh.
"Please allow about 10 minutes" it said. Where's that facepalm emoji?
But like, seriously. How does someone even build a website THIS bad?12 -
I have come to the conclusion that certain people have a tech aura that can fix or break things just by being near them. Apparently I can do both. Have you had a similar experience?
The other day a colleague was trying to play a YouTube video for the class (I work in a primary school) and the page refused to load. After 20m of failed page refreshes they called me. I walked in, sat next to the computer, and before I even touched anything YouTube suddenly appeared on the screen like it was trolling us the whole time. Much to the amazement of the class of kids who bow think I am some kind of tech-witch.
On the flipside - Linux hates me. It always has. Some years ago I decided to force myself upon Linux so I got a friend to install a dual boot on my machine. Knowing the effect I seem to have on Linux he demanded I stay out of the room until he was done. Two hours later and some stability testing later he called me back in to introduce me to my new setup. The moment I walked into the room Linux kernel panicked and never booted again.
If only I could learn to control this mystical power over technological life and death!13 -
Our web department was deploying a fairly large sales campaign (equivalent to a ‘Black Friday’ for us), and the day before, at 4:00PM, one of the devs emails us and asks “Hey, just a heads up, the main sales page takes almost 30 seconds to load. Any chance you could find out why? Thanks!”
We click the URL they sent, and sure enough, 30 seconds on the dot.
Our department manager almost fell out of his chair (a few ‘F’ bombs were thrown).
DBAs sit next door, so he shouts…
Mgr: ”Hey, did you know the new sales page is taking 30 seconds to open!?”
DBA: “Yea, but it’s not the database. Are you just now hearing about this? They have had performance problems for over week now. Our traces show it’s something on their end.”
Mgr: “-bleep- no!”
Mgr tries to get a hold of anyone …no one is answering the phone..so he leaves to find someone…anyone with authority.
4:15 he comes back..
Mgr: “-beep- All the web managers were in a meeting. I had to interrupt and ask if they knew about the performance problem.”
Me: “Oh crap. I assume they didn’t know or they wouldn’t be in a meeting.”
Mgr: “-bleep- no! No one knew. Apparently the only ones who knew were the 3 developers and the DBA!”
Me: “Uh…what exactly do they want us to do?”
Mgr: “The –bleep- if I know!”
Me: “Are there any load tests we could use for the staging servers? Maybe it’s only the developer servers.”
DBA: “No, just those 3 developers testing. They could reproduce the slowness on staging, so no need for the load tests.”
Mgr: “Oh my –bleep-ing God!”
4:30 ..one of the vice presidents comes into our area…
VP: “So, do we know what the problem is? John tells me you guys are fixing the problem.”
Mgr: “No, we just heard about the problem half hour ago. DBAs said the database side is fine and the traces look like the bottleneck is on web side of things.”
VP: “Hmm, no, John said the problem is the caching. Aren’t you responsible for that?”
Mgr: “Uh…um…yea, but I don’t think anyone knows what the problem is yet.”
VP: “Well, get the caching problem fixed as soon as possible. Our sales numbers this year hinge on the deployment tomorrow.”
- VP leaves -
Me: “I looked at the cache, it’s fine. Their traffic is barely a blip. How much do you want to bet they have a bug or a mistyped url in their javascript? A consistent 30 second load time is suspiciously indicative of a timeout somewhere.”
Mgr: “I was thinking the same thing. I’ll have networking run a trace.”
4:45 Networking run their trace, and sure enough, there was some relative path of ‘something’ pointing to a local resource not on development, it was waiting/timing out after 30 seconds. Fixed the path and page loaded instantaneously. Network admin walks over..
NetworkAdmin: “We had no idea they were having problems. If they told us last week, we could have identified the issue. Did anyone else think 30 second load time was a bit suspicious?”
4:50 VP walks in (“John” is the web team manager)..
VP: “John said the caching issue is fixed. Great job everyone.”
Mgr: “It wasn’t the caching, it was a mistyped resource or something in a javascript file.”
VP: “But the caching is fixed? Right? John said it was caching. Anyway, great job everyone. We’re going to have a great day tomorrow!”
VP leaves
NetworkAdmin: “Ouch…you feel that?”
Me: “Feel what?”
NetworkAdmin: “That bus John just threw us under.”
Mgr: “Yea, but I think John just saved 3 jobs. Remember that.”4 -
Have been trying to setup Netdata as a monitoring system for a while now and finally got it working!
Instead of the built-in webhooks I just did a curl to a url containing a php page/file which error logs the status and description (just for testing).
It took me way too long to get it to work but BAM.
Immediately made a new cpu load rule (one minute high load):
The satisfaction of getting an error message in the php logs containing my custom rule as warning and a minute later as critical 😍
Netdata ❤6 -
I am much too tired to go into details, probably because I left the office at 11:15pm, but I finally finished a feature. It doesn't even sound like a particularly large or complicated feature. It sounds like a simple, 1-2 day feature until you look at it closely.
It took me an entire fucking week. and all the while I was coaching a junior dev who had just picked up Rails and was building something very similar.
It's the model, controller, and UI for creating a parent object along with 0-n child objects, with default children suggestions, a fancy ui including the ability to dynamically add/remove children via buttons. and have the entire happy family save nicely and atomically on the backend. Plus a detailed-but-simple listing for non-technicals including some absolutely nontrivial css acrobatics.
After getting about 90% of everything built and working and beautiful, I learned that Rails does quite a bit of this for you, through `accepts_nested_params_for :collection`. But that requires very specific form input namespacing, and building that out correctly is flipping difficult. It's not like I could find good examples anywhere, either. I looked for hours. I finally found a rails tutorial vide linked from a comment on a SO answer from five years ago, and mashed its oversimplified and dated examples with the newer documentation, and worked around the issues that of course arose from that disasterous paring.
like.
I needed to store a template of the child object markup somewhere, yeah? The video had me trying to store all of the markup in a `data-fields=" "` attrib. wth? I tried storing it as a string and injecting it into javascript, but that didn't work either. parsing errors! yay! good job, you two.
So I ended up storing the markup (rendered from a rails partial) in an html comment of all things, and pulling the markup out of the comment and gsubbing its IDs on document load. This has the annoying effect of preventing me from using html comments in that partial (not that i really use them anyway, but.)
Just.
Every step of the way on building this was another mountain climb.
* singular vs plural naming and routing, and named routes. and dealing with issues arising from existing incorrect pluralization.
* reverse polymorphic relation (child -> x parent)
* The testing suite is incompatible with the new rails6. There is no fix. None. I checked. Nope. Not happening.
* Rails6 randomly and constantly crashes and/or caches random things (including arbitrary code changes) in development mode (and only development mode) when working with multiple databases.
* nested form builders
* styling a fucking checkbox
* Making that checkbox (rather, its label and container div) into a sexy animated slider
* passing data and locals to and between partials
* misleading documentation
* building the partials to be self-contained and reusable
* coercing form builders into namespacing nested html inputs the way Rails expects
* input namespacing redux, now with nested form builders too!
* Figuring out how to generate markup for an empty child when I'm no longer rendering the children myself
* Figuring out where the fuck to put the blank child template markup so it's accessible, has the right namespacing, and is not submitted with everything else
* Figuring out how the fuck to read an html comment with JS
* nested strong params
* nested strong params
* nested fucking strong params
* caching parsed children's data on parent when the whole thing is bloody atomic.
* Converting datetimes from/to milliseconds on save/load
* CSS and bootstrap collisions
* CSS and bootstrap stupidity
* Reinventing the entire multi-child / nested params / atomic creating/updating/deleting feature on my own before discovering Rails can do that for you.
Just.
I am so glad it's working.
I don't even feel relieved. I just feel exhausted.
But it's done.
finally.
and it's done well. It's all self-contained and reusable, it's easy to read, has separate styling and reusable partials, etc. It's a two line copy/paste drop-in for any other model that needs it. Two lines and it just works, and even tells you if you screwed up.
I'm incredibly proud of everything that went into this.
But mostly I'm just incredibly tired.
Time for some well-deserved sleep.7 -
OK< been a long time user of Unity.
Tried the latest update as I and others were enthusiastic about creating a joint project of gamers and developers.
As I was building up a started website and we were getting things with Unity ready...BOOM,. They Fuck up the installs.
Not just a minor thing here or there but not finding its own Fucking file locations where it installs shit. You try and say, Hey Unity you fucking twat, install here in this folder.
Boom again, it installs part of it there, and then continues installing shit everywhere else it wants to. Then the assholes at Unity give this Bullshit claim "the bug has been fixed."
Just reinstall.
Fuck you, its never that simple, You have to delete all sorts of fucking files to make sure conflicts from a previous corruption isn't just loaded on top of so it does not fuck up later.
So we did all that from programs, program data, program(x86), AppData Local, Local Low, and Roaming.
For added measure we manually removed all the crap from the registry folders (that was a pain but necessary), and then ran a cleaner to make sure all the left over shit was gone.
Thinking, OK you shit tech MoFo's we are clean and here we go.
HOLY SHIT BALLS, Its fucking worse with the LTS version it recommends and Slow as Fuck with their most recent version which is like 2020 itself, and insane piece of fucking bloated garbage and slower than a brick hard shit without fruit.
So we were going to all go post on the forums, and complain the fix section isn't fixed for shit.
Fuck us running backwards naked through a field of razor grass. Its so overloaded with complaints that they shut down further posts.
What makes this shit worse is we cannot even get the previous fucking versions of the editor before all this to work where our only option is without using the fucking Hub demand is just install 2018.
great if we started coding and testing in that. We cannot get shit where we were at back on track because you cannot fucking backward load an exported saved asset file.
Unity's suggestion? Start over.
Our Suggestion? Stop fucking smoking or using whatever fucking drug you assholes are on, you fucking disabled the gear options so we can resolve shit ourselves, and admit you did that shit and other sneaky piece of shit back stabby, security vulnerable data leak bullshit things to your end users.
Listen to your fucking experienced and long time users and get rid of the Fucking backward stepped hub piece of shit everyone with more brains than whatever piss ant pieces of shit praised that the rest of us have hated from day fucking one!
And while fixing this shit like it should be fucking fixed if you shit head bastards want to continue to exist as a fucking company, overhaul the fucking website or get the fuck out of business with now completely worthless SHIT.
Phew:
Suffice it to say....
We are now considering dealing with the learning curve and post pone our project going with unreal just because of these all around complete fuck ups that herald back to shit games of versions 3.0 and earlier. 6
6 -
I'm astonished again. Linux isn't designed as GUI OS - where Windows has dynamic thread priorities for freshly woken up threads as to increase GUI snappiness.
Now, my CPU has four physical and eight logical cores for SMT. I'm running eight worker threads of some parallel testing stuff, and I'm glad that I chose the AMD 3400G over the 3200G. The CPU load is 100%. On top of that, MP3 audio, the browser, and I'm dd'ing an external USB3 HDD.
Holy shit, the browser is just as smooth as if the CPU were idle. No perceivable lag. I hadn't expected desktop Linux to be that great.
I'm also surprised that the CPU temperature doesn't exceed 44°C despite full load at 21°C ambient, and the cooling is inaudible. Sure, my cooler is massively over-dimensioned to achieve exactly that, but it's still amazing.
It's what I would have wanted ten years ago and only could approach somewhat, but now the tech is actually there.18 -
I think my server got hacked, yesterday I made a new server on scaleway for the sake of testing I made a user called dev, with password dev. Forgot to change password before I went to bed.
Logged in today to find that load is 5x.x and this (image) in my crontab
Note to self: You are a disgrace, who the hell uses 'dev' as password for ssh on port 22 -_-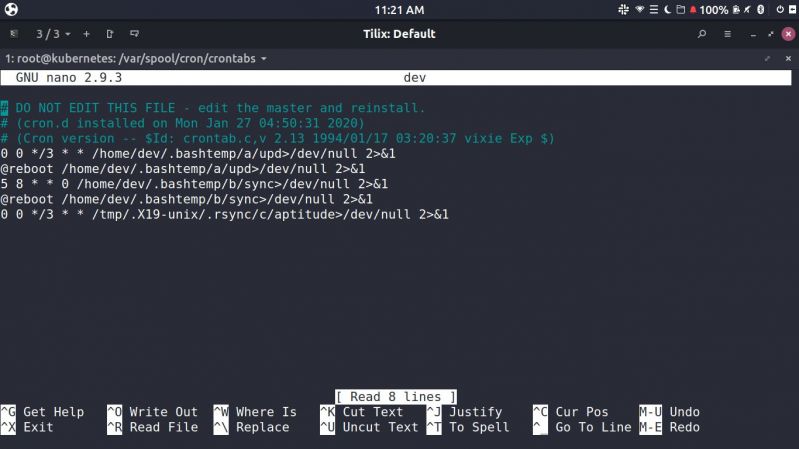 21
21 -
I wrote a todo list program, which also is my first self written api. Currently load testing. Server is ok.
 6
6 -
Best code performance incr. I made?
Many, many years ago our scaling strategy was to throw hardware at performance problems. Hardware consisted of dedicated web server and backing SQL server box, so each site instance had two servers (and data replication processes in place)
Two servers turned into 4, 4 to 8, 8 to around 16 (don't remember exactly what we ended up with). With Window's server and SQL Server licenses getting into the hundreds of thousands of dollars, the 'powers-that-be' were becoming very concerned with our IT budget. With our IT-VP and other web mgrs being hardware-centric, they simply shrugged and told the company that's just the way it is.
Taking it upon myself, started looking into utilizing web services, caching data (Microsoft's Velocity at the time), and a service that returned product data, the bottleneck for most of the performance issues. Description, price, simple stuff. Testing the scaling with our dev environment, single web server and single backing sql server, the service was able to handle 10x the traffic with much better performance.
Since the majority of the IT mgmt were hardware centric, they blew off the results saying my tests were contrived and my solution wouldn't work in 'the real world'. Not 100% wrong, I had no idea what would happen when real traffic would hit the site.
With our other hardware guys concerned the web hardware budget was tearing into everything else, they helped convince the 'powers-that-be' to give my idea a shot.
Fast forward a couple of months (lots of web code changes), early one morning we started slowly turning on the new framework (3 load balanced web service servers, 3 web servers, one sql server). 5 minutes...no issues, 10 minutes...no issues,an hour...everything is looking great. Then (A is a network admin)...
A: "Umm...guys...hardly any of the other web servers are being hit. The new servers are handling almost 100% of the traffic."
VP: "That can't be right. Something must be wrong with the load balancers. Rollback!"
A:"No, everything is fine. Load balancer is working and the performance spikes are coming from the old servers, not the new ones. Wow!, this is awesome!"
<Web manager 'Stacey'>
Stacey: "We probably still need to rollback. We'll need to do a full analysis to why the performance improved and apply it the current hardware setup."
A: "Page load times are now under 100 milliseconds from almost 3 seconds. Lets not rollback and see what happens."
Stacey:"I don't know, customers aren't used to such fast load times. They'll think something is wrong and go to a competitor. Rollback."
VP: "Agreed. We don't why this so fast. We'll need to replicate what is going on to the current architecture. Good try guys."
<later that day>
VP: "We've received hundreds of emails complementing us on the web site performance this morning and upset that the site suddenly slowed down again. CEO got wind of these emails and instructed us to move forward with the new framework."
After full implementation, we were able to scale back to only a few web servers and a single sql server, saving an initial $300,000 and a potential future savings of over $500,000. Budget analysis considering other factors, over the next 7 years, this would save the company over a million dollars.
At the semi-annual company wide meeting, our VP made a speech.
VP: "I'd like to thank everyone for this hard fought journey to get our web site up to industry standards for the benefit of our customers and stakeholders. Most of all, I'd like to thank Stacey for all her effort in designing and implementation of the scaling solution. Great job Stacy!"
<hands her a blank white envelope, hmmm...wonder what was in it?>
A few devs who sat in front of me turn around, network guys to the right, all look at me with puzzled looks with one mouth-ing "WTF?"7 -
Got pulled out of bed at 6 am again this morning, our VMs were acting up again. Not booting, running extremely slow, high disk usage, etc.
This was the 6 time in as many weeks this happened. And always the marching orders were the same. Find the bug, smash the bug, get it working with the least effort. I've dumped hundreds of hours maintaining this broken shitheap of a system, putting off other duties to keep mission critical stations running.
The culprits? Scummy consultants, Windows 10 1709, and Citrix Studio.
Xen Server performed well enough, likely due to its open source origins and Centos architecture.
Whelp. DasSeahawks was good and pissed. Nothing like getting rousted out of bed after a few scant hours rest for patching the same broken system.
DasSeahawks lost his temper. Things went flying. Exorcists were dispatched and promptly eaten.
Enough. No consultants, no analysts, and no experts touched it. No phone calls, no manuals, not even a google search. Just a very pissed admin and his minion declaring blitzkrieg.
We made our game plan, moved the users out, smoked our cigs, chugged monster, and queued a gnu-metal playlist on spotify.
Then we took a wrecking ball to the whole setup. User docs were saved, all else was rm -r * && shred && summon -u Poseidon -beast Land_Cracken.
Started at 3pm and finished just after midnight. Rebuilt all the vms with RDP, murdered citrix studio (and their bullshit licenses), completely blocked Windows 10 updates after 1607, and load balanced the network.
So what do we get when all the experts are fired? Stabbed lightning. VMs boot in less than 10 seconds, apps open instantly, and server resources are half their previous usage state. My VMs are now the fastest stations in our complex, as they should be.
Next to do: install our mxgpu, script up snapshots and heartbeat, destroy Windows ads/telemetry, and setup PDQ. damn its good to be good!
What i learned --> never allow testing to go to production, consultants will fuck up your shit for a buck, and vendors are half as reliable over consultants. Windows works great without Microsoft, thin clients are overpriced, and getting pissed gets things done.
This my friends, is why admins are assholes.4 -
Hi Lead Architect,
Oh? You want me to explain how database clustering works? I guess you're just testing me because I'm new and junior.
Oh, and also explain how load balancing works? And what a bastion host is?
What's the architectural intent of this project? Let's have a look at the documentation and diagrams you have been creating of your designs.
You don't have any? That's okay, you've only been leading the architect team on this project for a year now.
Why don't you just keeping asking the most junior dev on the team about how the fuck you are supposed to do your job. As if I know how to do your job when I have zero training and am just expected to know everything.
Oh, its 3pm and you're heading to the pub. That's cool, I'll just guess what I need to build.2 -
I'm having an existential crisis with this client.
We are spending millions of $s every year to make sure the product's performance is perfect. We are testing various scenarios, fine-tuning PLABs: the environment, application, middleware, infra,... And then we provide our recommendations to the client: "To handle load of XX parallel users focusing on YY, yy and Zy APIs, use <THIS> configuration".
And what the client does?
- take our recommendations and measure the wind speed outside
- if speed is <20m/s and milk hasn't gone bad yet, add 2x more instances of API X
- otherwise add 3xX, 1xY and give more CPUs to Z
- split the setup in half and deploy in 2 completely separate load-balanced prod environments.
- <do other "tweaking">
- bomb our team with questions "why do we have slow RTs?", "why did the env crash?", "why do we have all those errors?", "why has this been overlooked in PLABs?!?"
If you're improvising despite our recommendations, wtf are we doing here???
One day I will crack. Hopefully, not sometime soon.3 -
I just love how liferay keeps finding ways to surprise me...
Customer: need to fix this security issue
me: ok
me: fixed. Testing locally. Works 100%.
Me: testing on dev server. Works 100%
qa: testing on dev server. Works 100%
me: all good. Deploying to preprod
customer: it doesn't work
me: testing preprod - it doesn't work.
Me: scp whole app to local machine. App works 100%.
Me: preview loaded liferay properties in preprod via liferay adm panel. All props loaded ok.
Me: attach jdb to preprod's liferay to see what props are loaded. Only defaults are used [custom props not loaded according to jdb]
me: is there some quantum mechanics involved..? Liferay managed to both load and not to load props at the same time and the state only changes as it's observed...2 -
FUCK IT
After YEARS of research, I couldn't find a single working load testing tool
So this weekend I created my own. With blackjack and hookers.
It's limited to my app, so not reusable, but wow in 1 weekend I got more data and found more infra problems than in the past 3 years.17 -
Our project at work goes live in 3 weeks.
The code base has no automated tests, breaks very often, has never had any level of manual testing
will not be releasing with any form of enforced roles or permissions in our first release now due to no time to enforce, however there is a whole admin api where you can literally change anything in our database including roles.
We also have teams in various countries all working separately on the same solution using microservices with shared nuget packages and they aren't using them properly.
Our pull requests are so big - as much as, 75 file changes - in our fe app that I can't keep up with it and I honestly have no idea if it even works or not due to no automated tests and no time to manually test.
We have no testing team, or qa team of any sort.
Every request into the system has to hit a minimum of 3 different databases via 3 different microservices so 1 request = 4 requests with the load on the servers.
We don't use any file streams so everything is just shoved in the buffer on the server.
Most of the people working on the angular apps cba to learn angular, no one across 2 teams cba to learn git. We use git so they constantly face problems. The guy in charge has 0 experience in angular but makes me do things how he wants architecturally so half the patterns make no sense.
No one looks at the pull requests, they just click approve so they may as well push directly to master.
Unfinished work gets put in for pull request so we don't know if the app is in a release state since aall teams are working independently, but on the same code base.
I sat down and tested the app myself for an hour and found 25 fe only issues, and 5 breaking cross browser issues.
Most of our databases are not normalised. Most of our databases make no sense. 99% of our tables have no indexing since there is no expertise with free time to do it.
No one there understands css properly. Or javascript.
Our. Net core microservices all directly use ef in the controller actions so there is no shared code there.
Our customer facing fe app is not dry because no tests so it was decided it was better this way.
Management has no idea on code state, it seems team lead is lieing to them about things like having any level of tests.
Management hire devs that claim to be experts but then it turns out they have basically no knowledge of what they were hired to do, even don't know what json is or the framework or language they are hired for, but we just leave them to get on with it and again make prs too big to review.
Honestly I have no hope that this will go well now but I am morbidly curious to watch. I've never seen anything like the train wreck that we are about to get experience.5 -
!rant
So I was experimenting with distributing load on separate processes in node.js. I wrote the simplest isPrime function for performance testing, and I calculated a lot of primes. To be able to see the result, I generated a 1920x1080 image where each white pixel represents a prime.
New wallpaper? 5
5 -
(long post is long)
This one is for the .net folks. After evaluating the technology top to bottom and even reimplementing several examples I commonly use for smoke testing new technology, I'm just going to call it:
Blazor is the next Silverlight.
It's just beyond the pale in terms of being architecturally flawed, and yet they're rushing it out as hard as possible to coincide with the .Net 5 rebranding silo extravaganza. We are officially entering round 3 of "sacrifice .Net on the altar of enterprise comfort." Get excited.
Since we've arrived here, I can only assume the Asp.net Ajax fiasco is far enough in the past that a new generation of devs doesn't recall its inherent catastrophic weaknesses. The architecture was this:
1. Create a component as a "WebUserControl"
2. Any time a bound DOM operation occurs from user interaction, send a payload back to the server
3. The server runs the code to process the event; it spits back more HTML
Some client-side js then dutifully updates the UI by unceremoniously stuffing the markup into an element's innerHTML property like so much sausage.
If you understand that, you've adequately understood how Blazor works. There's some optimization like signalR WebSockets for update streaming (the first and only time most blazor devs will ever use WebSockets, I even see developers claiming that they're "using SignalR, Idserver4, gRPC, etc." because the template seeds it for them. The hubris.), but that's the gist. The astute viewer will have noticed a few things here, including the disconnect between repaints, inability to blend update operations and transitions, and the potential for absolutely obliterative, connection-volatile, abusive transactional logic flying back and forth to the server. It's the bring out your dead approach to seeing how much of your IT budget is dedicated to paying for bandwidth and CPU time.
Blazor goes a step further in the server-side render scenario and sends every DOM event it binds to the server for processing. These include millisecond-scale events like scroll, which, at least according to GitHub issues, devs are quickly realizing requires debouncing, though they aren't quite sure how to accomplish that. Since this immediately becomes an issue with tickets saying things like, "scroll event crater server, Ugg need help! You said Blazorclub good. Ugg believe, Ugg wants reparations!" the team chooses a great answer to many problems for the wrong reasons:
gRPC
For those who aren't familiar, gRPC has a substantial amount of compression primarily courtesy of a rather excellent binary format developed by Google. Who needs the Quickie Mart, or indeed a sound markup delivery and view strategy when you can compress the shit out of the payload and ignore the problem. (Shhh, I hear you back there, no spoilers. What will happen when even that compression ceases to cut it, indeed). One might look at all this inductive-reasoning-as-development and ask themselves, "butwai?!" The reason is that the server-side story is just a way to buy time to flesh out the even more fundamentally broken browser-side story. To explain that, we need a little perspective.
The relationship between Microsoft and it's enterprise customers is your typical mutually abusive co-dependent relationship. Microsoft goes through phases of tacit disinterest, where it virtually ignores them. And rightly so, the enterprise customers tend to be weaksauce, mono-platform, mono-language types who come to work, collect a paycheck, and go home. They want to suckle on the teat of the vendor that enables them to get a plug and play experience for delivering their internal systems.
And that's fine. But it's also dull; it's the spouse that lets themselves go, it's the girlfriend in the distracted boyfriend meme. Those aren't the people who keep your platform relevant and competitive. For Microsoft, that crowd has always been the exploratory end of the developer community: alt.net, and more recently, the dotnet core community (StackOverflow 2020's most loved platform, for the haters). Alt.net seeded every competitive advantage the dotnet ecosystem has, and dotnet core capitalized on. Like DI? You're welcome. Are you enjoying MVC? Your gratitude is understood. Cool serializers, gRPC/protobuff, 1st class APIs, metadata-driven clients, code generation, micro ORMs, etc., etc., et al. Dear enterpriseur, you are fucking welcome.
Anyways, b2blazor. So, the front end (Blazor WebAssembly) story begins with the average enterprise FOMO. When enterprises get FOMO, they start to Karen/Kevin super hard, slinging around money, privilege, premiere support tickets, etc. until Microsoft, the distracted boyfriend, eventually turns back and says, "sorry babe, wut was that?" You know, shit like managers unironically looking at cloud reps and demanding to know if "you can handle our load!" Meanwhile, any actual engineer hides under the table facepalming and trying not to die from embarrassment.36 -
tl;dr - why you no read this?
Here I am pondering why I continue to return to my job everyday when we are currently at month 13 of a 4 month project... yea let that set in for a minute... which is still at least 3-4 months away from being deployed due to annual leave of key stake holders and the whole Christmas period creeping up and things just not going as planned every step of the way.
There's no greater demotivater - is that even how you spell it - then being stuck in a project for so long you really just don't give a shit if it works or not anymore.
This has gone from a simple - relatively speaking - project to some monolithic mayhem of requirement changes and process adjustments, that have not only delayed our team, but 3rd party vendors needing to change things as well, or the requirements being wrong early so when you get up to business testing it's like "nope, that's not what we wanted" .... despite all the sessions of you personally giving the PM all the damn requirements.
But in saying that, they (3rd party) aren't innocent either, we have found nothing but issue after issue with their product since we started this project that who ever signed off on going forward with the thing should have been shot from both sides - it's not designed for the scale we will be using it yet we didn't find that out till we got so far into the rabbit hole we had a chance to be able to do load testing.
Meh, guess I'll go to work Monday and spend another week in misery trying to deliver something that just doesn't want to know what the finish line is.4 -
In This Rant: A mildly satisfying piece of mind story.
Using code to prove yourself right is a hell of a drug.
A few weeks ago I whipped up a tiny program that downloads configs from hardware we manage. Since the vendor's API documentation is hidden behind a pay wall, my method of extraction is different. It results in bigger files, but testing showed it to still be valid.
Enter today. Interns at work downloaded a config to load onto a spare machine and it won't work.
"TheCapeGreek, your configs don't work"
I was confused since I tested the files when I built it and it worked. I am also currently fleshing out that download utility's features so the fear that I've been wasting the past 2 weeks on improvements is looming.
Last 15 minutes of the day and nothing else to do so I figured I might as well whip up a string comparer. The smaller file's content is scattered in the big file so a direct diff won't work.
Code it all, quick hardcoded proof of concept code, bit it got the job done. I was right, my bigger file is still correct!
Turns out the issue was with the machine they were configuring. They found this out before I finished my test code, so I'm off the hook already, but it was good to have piece of mind haha!1 -
OK semi rant... Would like suggestions
Boss wants me to figure out someway to find the maximum load/users our servers/API/database can handle before it freezes or crashes **under normal usage**.
HOW THE FUCK AM I SUPPOSED TO DO THAT WITH 1 PC? The question seems to me to mean how big a DDoS can it handle?
I'm not sure if this is vague requirements, don't know what they're talking about, or they think I can shit gold... for nothing... or I'm missing something (I'm thinking how many concurrent requests and a single Neville melee even with 4 CPUs)
"Oh just doing up some cloud servers"
Uh well I'm a developer, I've never used Chef or Puppet and or cloud sucks, it's like a web GUI, not only do I have to create the instances manually and would have to upload the testing programs to each manually... And set up the envs needed to run it.
Docker you say? There's no Docker here... Prebuilt VM images? Not supported.
And it's due in 2 weeks...11 -
Last day of agile project i get asked for confirmation that the alpha system can handle 100000 records. We have had no load testing requests only feature pushes every sprint.
I see the back-end guys have used EF in a search function that eager joins a bunch of tables. Then the results get sorted and filtered in application code. It works fine for a few hundred records but the customer will do about 100k new records a year.
Yeah this won’t meet requirements. I wish they asked for some load testing before the last day. They aren’t going to like that one person can do a search every 15 seconds by the end of the year when I tell them. FML12 -
Fuck me I'm pissed. This sprint, my tech lead has been away and a senior dev has been covering for him. We plan a load of work and distribute stories and we churn threw it quite well. However, my senior dev says let's not deploy until all the works done. I was like, how is it going to be tested? He was like well it will be fine because it's all one test. Bs. We now have 2 days left, tester is getting stressed because they don't know what to test or what's been finished. Scrum master is asking why all of it should be tested at the same time and I'm here like this is fucking dumb. Also the tester decided to start testing with the most complex piece of work, rather than prioritising.
Starting to wonder if I'm just the outsider or whether no one understands that granularity is better.2 -
PM: Page load times are up. It might be your API blocking requests.
Me: Possible, though most of my load testing was performed against a random sample of requests at nearly 5 times the expected average per minute rate. I can add some logs but I think this is a red herring theory.
PM: Yes add logs, and New Relic and get it released ASAP.
Me: To confirm, you want me to make a bunch of diagnostic changes to a mission-critical API the day before Holiday break...
I felt like that guy from the Apollo 13 team warning Gene Kranz that the LEM was not built for this and I can make no guarantees... Released an hour before we went home for the weekend. -
Working on codebase of a 20+ year old system that the company I work for bought five years ago and in that time there’s been no refactoring, no security updates, no attempt to create automated testing (there is none), new features have just been built on the codebase with no regard for quality and it’s just spun into the horror cesspool that it is today.
I joined one year ago and I’m slowly refactoring the codebase and updating it to get it to a more modern codebase, cleaner code, faster load times and creating a ton of dev documentation so the devs in India can start getting into best practices and start producing quality code.4 -
Due to coronovirus, my work asked everyone to login for 30mins (in a 2hr window) to test test max load/capacity...
1. how do you test max load if people can login at different times...
2. Isn't there software that can test that.... Isn't this load testing?11 -
Who the fuck invented the glorified pile of shit people call laravel? Is this actually used in PROD for anything else than load testing a monitoring server by creating loads of error messages?
OOP exists for a reason, not to create bazillions of classes with static methods.
Dump that shit ffs!6 -
We take over development of a live customer facing system and PM agrees date for our first code deployment with client CIO
Me: The dev and staging environments don't have any test data currently as the old agency screwed it up
PM: Well you better load some
Me: There isn't any... It'll take 10 days to copy prod db due to hosting provider SLAs, leaving 1 week for SIT, UAT and performance testing (assuming they don't screw up)
PM: Well the date is set, 1 week will be enough for testing2 -
I need some opinions on Rx and MVVM. Its being done in iOS, but I think its fairly general programming question.
The small team I joined is using Rx (I've never used it before) and I'm trying to learn and catch up to them. Looking at the code, I think there are thousands of lines of over-engineered code that could be done so much simpler. From a non Rx point of view, I think we are following some bad practises, from an Rx point of view the guys are saying this is what Rx needs to be. I'm trying to discuss this with them, but they are shooting me down saying I just don't know enough about Rx. Maybe thats true, maybe I just don't get it, but they aren't exactly explaining it, just telling me i'm wrong and they are right. I need another set of eyes on this to see if it is just me.
One of the main points is that there are many places where network errors shouldn't complete the observable (i.e. can't call onError), I understand this concept. I read a response from the RxSwift maintainers that said the way to handle this was to wrap your response type in a class with a generic type (e.g. Result<T>) that contained a property to denote a success or error and maybe an error message. This way errors (such as incorrect password) won't cause it to complete, everything goes through onNext and users can retry / go again, makes sense.
The guys are saying that this breaks Rx principals and MVVM. Instead we need separate observables for every type of response. So we have viewModels that contain:
- isSuccessObservable
- isErrorObservable
- isLoadingObservable
- isRefreshingObservable
- etc. (some have close to 10 different observables)
To me this is overkill to have so many streams all frequently only ever delivering 1 or none messages. I would have aimed for 1 observable, that returns an object holding properties for each of these things, and sending several messages. Is that not what streams are suppose to do? Then the local code can use filters as part of the subscriptions. The major benefit of having 1 is that it becomes easier to make it generic and abstract away, which brings us to point 2.
Currently, due to each viewModel having different numbers of observables and methods of different names (but effectively doing the same thing) the guys create a new custom protocol (equivalent of a java interface) for each viewModel with its N observables. The viewModel creates local variables of PublishSubject, BehavorSubject, Driver etc. Then it implements the procotol / interface and casts all the local's back as observables. e.g.
protocol CarViewModelType {
isSuccessObservable: Observable<Car>
isErrorObservable: Observable<String>
isLoadingObservable: Observable<Void>
}
class CarViewModel {
isSuccessSubject: PublishSubject<Car>
isErrorSubject: PublishSubject<String>
isLoadingSubject: PublishSubject<Void>
// other stuff
}
extension CarViewModel: CarViewModelType {
isSuccessObservable {
return isSuccessSubject.asObservable()
}
isErrorObservable {
return isSuccessSubject.asObservable()
}
isLoadingObservable {
return isSuccessSubject.asObservable()
}
}
This has to be created by hand, for every viewModel, of which there is one for every screen and there is 40+ screens. This same structure is copy / pasted into every viewModel. As mentioned above I would like to make this all generic. Have a generic protocol for all viewModels to define 1 Observable, 1 local variable of generic type and handle the cast back automatically. The method to trigger all the business logic could also have its name standardised ("load", "fetch", "processData" etc.). Maybe we could also figure out a few other bits too. This would remove a lot of code, as well as making the code more readable (less messy), and make unit testing much easier. While it could never do everything automatically we could test the basic responses of each viewModel and have at least some testing done by default and not have everything be very boilerplate-y and copy / paste nature.
The guys think that subscribing to isSuccess and / or isError is perfect Rx + MVVM. But for some reason subscribing to status.filter(success) or status.filter(!success) is a sin of unimaginable proportions. Also the idea of multiple buttons and events all "reacting" to the same method named e.g. "load", is bad Rx (why if they all need to do the same thing?)
My thoughts on this are:
- To me its indentical in meaning and architecture, one way is just significantly less code.
- Lets say I agree its not textbook, is it not worth bending the rules to reduce code.
- We are already breaking the rules of MVVM to introduce coordinators (which I hate, as they are adding even more unnecessary code), so why is breaking it to reduce code such a no no.
Any thoughts on the above? Am I way off the mark or is this classic Rx?16 -
*Repost of my own accidentally deleted post*
A Short story that i made on an Android component
===============================
Once upon a time there used to be a ViewPager who was not able to load a Fragment UI.
All the ViewPagers in town can properly load the Fragrant UI but this one was little different.
He wanted to be more then just a ViewPager. He used to see an Activity that can load anything. He was inspired from the Activity and wanted to be like the Activity but his destiny made him just a ViewPager.
So he refused to cooperate. He started to protest silently, No log, nothing.
Everyone assumed this ViewPager have a bug in it. but he was planning something really big that will left everyone in shock and awe moment.
He was planning to rise against the evil 😈 developers who continuously making him to load Fragrant UI
He assembled the biggest army of the bugs that humanity ever seen to counter the developers.
He distributed these bugs in all over the developer's code to make them fire from their work.
Even he taught bugs to not caught in QA testing but appear in production randomly.
So they silently started going into production
And then chaos is erupted all around the world, bugs started to surface and interrupted the daily life of humanity.
In this chaos the ViewPager RAISED!
And took over all the base classes.
ViewPager was unaware of few facts. this unnecessary rise in his power made whole system unstable
Without the base classes the system finally collapsed and then ViewPager as well with the system.
This was the end of everything for the ViewPager but he was satisfied as he lived the life he always wanted
THE END -
## building my own router
I hoped things would go more smoothly :)
Anyway, my new miniPC easily accepted CentOS 8 - no fuss here. And I've got to say - I love CentOS8 so far! Shell has amazing nifty tricks, UI (gnome3) is also snappy, video/audio/ethernet,.. everything works.
What I did NOT expect is hardware being off. Well okay, the price was low - it was obvious smth is not right. But still.. I decided to build my own router so that I could swap wifi card whenever I want. So that I could run my own network services in there. Turns out - the card swapping is not as easy as one might think.
I got the AX200 WiFi6 card for that very purpose. But once plugged in the OS can only see it's bluetooth module. Weird... What's even weirder is that even though the card is PCIe, the OS uses btusb module to talk to that device. What? USB?? emm.. What??
And there it is. After opening it up again I noticed that the mPCIe area is marked with a label: "USB WIFI / WWAN". USB? Does that mean this PCIe slot is wired into the USB bus? Not impossible I guess.
Googling for a "pcie wifi over usb" or smth like that brought me to one reddit (I think?) where someone wanted to build a DIY wifi mPCIe -> USB adapter and someone else adviced hime that (for some reason) at best he could only get bluetooth working (hey! just like me!). It's got to do smth with pcie channels and USB being too weak to handle all that load, or smth.. IDK, I'm not a HW guy.
Well that sucks then! I have a mPCIe slot that does not work as a PCIe. Shit! So I guess the best I could do is to plug back in the same wifi card that came with the device. It smells like 2003 - supports only g protocol. Fine, let's try that. Maybe I'll find a way to work around this mPCIe limitation later on (USB adapter or smth... except there are no USB WIFI6 dongles yet :( ). So I plug it back in and start turning it into a router. Disable NetworkManager, configure static NCs' settings, install dhcpd, hostapd, bind and others. Looks like all is done! Now it's time to start it all. systemctl start hostapd --> FAILED. wtf? journalctl says it could not initialize a driver. umm okay? Why? Forums say I should airodump-ng check and kill whatever's using that device. Fine. airodumo reveals avahi and wpa_suppl are still using it. kill, kill, GOTTA KILL 'EM ALL!! Starting hostapd again -- same shit... wtf?
iw list
My gawd... That shitty network card does not even support AP mode :( I mean.. My USB wifi dongle for 2€ supports 2x more modes, is faster, has better range and is easier to work with than this old tart!
Yeah. That was an interesting day. When enfironment engineers break my testing environments at work I'm glad I have where to spend my time now.
BTW any ideas how to bypass this mPCIe nonsense? Come on, there are USB GPUs out there.. Why can't they make a USB (or dual-USB if they really need to) mPCIe adapter?8 -
Load tests:
I'm used to do load tests in Visual Studio where it gives which line is exactly your bottleneck. But now I'm using VS Code (visual studio requires enterprise license for load tests :\ no longer have one)
Anyways long story short, what are the best practices for load tests? For me what I'm testing is how much can a given hardware specs handle and when test fails I go back and check if code can be optimized, is this the correct way to do this?7 -
Hey Guys
Today I'm bringing a tool for you guys, mount servers with old phones Or have servers in your phone for testing.
Tool: Servers Ultimate Pro
Web:: https://icecoldapps.com/app/...
Note1.: Doesn't handle well above android 6+, So test one of the free servers you're intending to use before buying.
Note2.: This App costs around 10€/$ but you can get single App servers for free (I think even html + php + mysql package for free).
Not promotional, I'm just a user that loves this App.
I already talked about this a few times (usually I just call the cell phone I'm using my web server), but as a noob I don't even knot the possibilities.
This App comes with more then 70 protocols (60+ servers and a mix of servers).
From ssh, ftp, html (nginx, lightppd, Apache, simple) with php and mysql, Webdav...
<quote>
Run over 60 servers with over 70 protocols!
Now you can run a CVS, DC Hub, DHCP, UPnP, DNS, Dynamic DNS, eDonkey, Email (POP3 / SMTP), FTP Proxy, FTP, FTPS, Flash Policy, Git, Gopher, HTTP Snoop, ICAP, IRC Bot, IRC, ISCSI, Icecast, LPD, Load Balancer, MQTT, Memcached, MongoDB, MySQL, NFS, NTP, NZB Client, Napster, PHP and Lighttpd, PXE, Port Forwarder, Proxy, RTMP, Remote Control, Rsync, SMB/CIFS, SMPP, SMS, Socks, SFTP, SSH, Server Monitor, Stomp, Styx, Syslog, TFTP, Telnet, Test, Time, Torrent Client, Torrent Tracker, Trigger, UPnP Port Mapper, VNC, Wake On Lan, Web, WebDAV, WebSocket, X11 and/or XMPP server!
</quote>7 -
That moment you forget to tell the devs about the new tests and end up doing brute force for some pen testing and load capacity and they do a rant of you
-
So.. playing around with jquerys load() function because I'm trying to implement some updating functionality to a specific div. After researching a bit, it didn't seem like it would be too difficult.. but I could not for the life of me figure out why my template was not displaying! I tried testing with just some basic html and it worked fine. Even took a few snippets from my template and again.. it worked. As soon as I copy/pasted my whole template, the page renders nothing. I was seriously getting frustrated so I started entering the template manually testing each line. It worked until I got to this special div container I made.. went and looked at the css properties for it and..
display: none;
*facepalm*
I forgot I had set it to none because I was using jquerys fadeIn() function xD seriously?? -
I just fucked up real bad:
My phone was giving some error about not being able to install an update. Fair enough, i think to myself, so i try rebooting. Still nothing...
I then remember that i at some point OEM unlocked it for some testing, so i start up adb and see if i can connect during the update process. I can't. This is bad: I can't get into my home environment, nor can i connect with adb
Then i try booting into recovery, but instead of booting to ACTUAL recovery, it boots to some custom made "E-Recovery" made by huawei (my phone is a huawei p9 lite), which only gives me the option to download the update, which crashes, and no way of resetting. However, from here, i am finally able to connect to my internal storage via hisuite to make a backup
Next up: Bootloader
So i next load up the unlocked bootloader to try and manually flash the update. That works great, but it still wont boot normally. So i figure: it must think my device is in fact a different device. At this point i'm pretty fucked: Even though i have my data backed up, i can't manually download the update from huawei's site because i don't have the right keys, and i can't download an OTA because their site sucks and half of the downloads don't work, including the one i need. So now i'm stuck here with a bricked phone because EMUI doesn't know how to install an update.
I then did the stupidest thing i have done to date: i wanted to flash a custom recovery image over the "E-Recovery" in order to do some troubleshooting, but instead of writing
"fastboot (mydeviceid) flash recovery recovery.img"
I wrote
"fastboot (mydeviceid) flash boot recovery.img"
Meaning i flashed my BOOT partition with a custom recovery image that turned out to not be able to run. Great! Now i've totally fucked my boot sequence
I can't call their support line either, because as soon as they realize i've tried to restore it myself, and therefor had my OEM unlocked, they basically just hang up.7 -
A very long rant.. but I'm looking to share some experiences, maybe a different perspective.. huge changes at the company.
So my company is starting our microservices journey (we have a 359 retail websites at this moment)
First question was: What to build first?
The first thing we had to do was to decide what we wanted to build as our first microservice. We went looking for a microservice that can be used read only, consumers could easily implement without overhauling production software and is isolated from other processes.
We’ve ended up with building a catalog service as our first microservice. That catalog service provides consumers of the microservice information of our catalog and its most essential information about items in the catalog.
By starting with building the catalog service the team could focus on building the microservice without any time pressure. The initial functionalities of the catalog service were being created to replace existing functionality which were working fine.
Because we choose such an isolated functionality we were able to introduce the new catalog service into production step by step. Instead of replacing the search functionality of the webshops using a big-bang approach, we choose A/B split testing to measure our changes and gradually increase the load of the microservice.
Next step: Choosing a datastore
The search engine that was in production when we started this project was making user of Solr. Due to the use of Lucene it was performing very well as a search engine, but from engineering perspective it lacked some functionalities. It came short if you wanted to run it in a cluster environment, configuring it was hard and not user friendly and last but not least, development of Solr seemed to be grinded to a halt.
Elasticsearch started entering the scene as a competitor for Solr and brought interesting features. Still using Lucene, which we were happy with, it was build with clustering in mind and being provided out of the box. Managing Elasticsearch was easy since there are REST APIs for configuration and as a fallback there are YAML configurations available.
We decided to use Elasticsearch since it provides us the strengths and capabilities of Lucene with the added joy of easy configuration, clustering and a lively community driving the project.
Even bigger challenge? Which programming language will we use
The team responsible for developing this first microservice consists out of a group web developers. So when looking for a programming language for the microservice, we went searching for a language close to their hearts and expertise. At that time a typical web developer at least had knowledge of PHP and Javascript.
What we’ve noticed during researching various languages is that almost all actions done by the catalog service will boil down to the following paradigm:
- Execute a HTTP call to fetch some JSON
- Transform JSON to a desired output
- Respond with the transformed JSON
Actions that easily can be done in a parallel and asynchronous manner and mainly consists out of transforming JSON from the source to a desired output. The programming language used for the catalog service should hold strong qualifications for those kind of actions.
Another thing to notice is that some functionalities that will be built using the catalog service will result into a high level of concurrent requests. For example the type-ahead functionality will trigger several requests to the catalog service per usage of a user.
To us, PHP and .NET at that time weren’t sufficient enough to us for building the catalog service based on the requirements we’ve set. Eventually we’ve decided to use Node.js which is better suited for the things we are looking for as described earlier. Node.js provides a non-blocking I/O model and being event driven helps us developing a high performance microservice.
The leap to start programming Node.js is relatively small since it basically is Javascript. A language that is familiar for the developers around that time. While Node.js is displaying some new concepts it is relatively easy for a developer to start using it.
The beauty of microservices and the isolation it provides, is that you can choose the best tool for that particular microservice. Not all microservices will be developed using Node.js and Elasticsearch. All kinds of combinations might arise and this is what makes the microservices architecture so flexible.
Even when Node.js or Elasticsearch turns out to be a bad choice for the catalog service it is relatively easy to switch that choice for magic ‘X’ or component ‘Z’. By focussing on creating a solid API the components that are driving that API don’t matter that much. It should do what you ask of it and when it is lacking you just replace it.
Many more headaches to come later this year ;)3 -
I got plenty of stories of yelling at co-workers before for assortment of reasons. But let me tell you a story of a time I almost yelled.
Think of Adam Sandler when he's a bit ticked. He says something nice with nice words but he delivers it in an upset and load tone but not actually screaming/yelling. That's me trying to hold back but it reveals how upset I am. I do try to stay courteous and gentlemanly (I'm really trying to manage my anger after so much BS I've been getting after a decade of working). But there are times where my patience is testing its limits and well, I implode.
And when that happens, I regret doing that to my co-workers as we are all trying to get things done and still get paid by the end of day. But they stoopid! UGH!
Co-workers, I can tolerate a little more. But clients are a completely different story. Ever tried fake smiling for over 3 hour meeting of ridiculous change requests and has the balls to make them free? It fcking HURTS! -
WHY does VS code load up Pandas dataframes so damn slowly? It’s bad enough that it seems to take an extra few seconds to get PyQt5 going, but the dataframes are awful, even with small 50 record Parquet files.
I don’t have the attention span to sit there and wait for this without finding myself playing with my phone or surfing.
I guess for debugging and testing I should just create a column A, column B, column C dataframe on the fly and give it some 1, 2, 3 kind of values.
But, Jesus, man... This shouldn’t take 30 seconds to load a simple form. 🙄2 -
!rant
I have my 121 in a few days with my new manager and am trying to get a raise either through moving from junior to mid level dev or being given a significant raise , am being paid a tad below the London market rate's lower range for my skill level.
Any advice on how to approach the topic?
Some bits of my background:
I got almost 4 years of exp :
almost 2 working there...
6 months short term contract as a ruby sql dev another company...
1.5 years worked for an abusive joke of a company who took advantage of my naivety since i was fresh out of uni ( did stuff like pressured me to add more features to a pojo system i made for them) barely learned anything there since i was the only IT person there developing solo, the project lasted 1.5 years and was a total mess to finish, so am not too sure of factoring it into my years of exp.
My Qualifications are:
bsc in information systems
Msc in enterprise sw engineering
My "new" Manager is seeking to retire real soon.
The company isn't doing too well but we just landed 2 big customers who are buying the product my team is working on
I Am one of two last devs on my team and we are barely holding on with the load, can't afford the time to train a newbie to join us
my department is soon to be sold (soon according to what mgr says). They have been saying so for 10 months now.
Last year , since the acquisition Is taking so long and funds were running out We were hit by a wave of redundancies which slashed our workforce in august/ july, told we could last till march this year on our funds . Even senior staff were on a reduced work week...but since we Got new customers then money should be coming in again , this should mean thats no longer the case. Even the senior staff have returned to 5 day work weeks.
Am being given only JavaScript work to do despite being hired as a junior java dev, my more senior colleagues dont wanna even touch js with a long stick
Spoke to 3 recruiters , said they got open roles in the junior- mid level range that pay the proper market range if am interested to put my cv through.
Thats like 25% more than I currently make.
Am a bit scared to jump into a mid level position in another company because i lack a bit confidence in my core java skills.
although a senior dev who used to be on my team thinks i can do it.
i recon i can take on the responsibilities of a mid level dev in me existing company since am pretty familiar with the products
I dont get to work with senior devs and learn from them since we are so stretched thin, hence am not really getting the chance to grow my skills
I know i have gaps in my knowledge and skills having not been able work in java for a while hasn't allowed me to fix that too well. I badly need to learn stuff like proper unit testing, not the adhoc rubbish we do at the moment, frameworks like spring etc
Since I have been pretty much pushed into being the js guy for the large chunks of the project over the last year , its kinda funny am the only guy who has the barest idea how some of the client facing stuff works
The new manager does seem to be a nice guy but he is like a politician, a master bullshitter who kept reassuring all is well and the company is fineeee (just ignore the redundancies as the fly past you)
The deal for thr aquisition seem to have sped up according to rumors
And we heard is a massive company buying us, hence things might pick up again and be better than ever
Any ideas how to approach the 121 with him?
Any advice career wise?
Should i push for a raise ?
promotion to mid?
Leave to find a junior to mid level position?
Tought it out and wait for the take over or company crash while trying to fill the gaps in my knowledge ?
Sorry for the length of this post2 -
What the hell am I!? I wonder if you guys can help me...
I've been programming most of my life but I've never actually been a developer by title or job role. I thought maybe if I list what I do and have done someone here could help? I'm sure there are more of you in a similar boat.
- C# and VB dev for some quick DBMS projects to help me understand and mine databases and create a nice simple view for project teams to show findings from the data to help make certain decisions.
- Automating a lot of my colleagues work with Python and if very restricted then just VBA macros in Excel and MSP. This did also include creating tools to gather data during workshops and converting the data for input into other systems.
- Brought Linux to the office with most team members now moving over to Linux with the peace of mind to know that though they do need to try solve their own problems, I can help if need be.
- Had to learn AWS and then implement an autoscaling and load balanced data center installation of a few Atlassian toolsets.
- Creating the architecture diagrams documentation needed for things like the above point.
- Having said that, also have ended up setting up all the Jira/Confluence etc. servers we use and have implemented so far whether cloud (Azure/AWS) or on prem and set up scripts to automate where possible.
- Implemented an automated workflow view in SharePoint based on SP list data and though in an ASPX page, primarily built in JS.
- Building test systems in PHP/JS with Laravel and Angular to help manage integration between systems. Having quite a time right looking into how to build middleware to connect between SOAP and REST API's, the trouble caused more by the systems and their reliance on frameworks we're trying to cut out of the picture.
- Working on BI and MI and training a team to help on the report creation so that I can do the fun creative stuff and then set them to work on the detail :)
Actually it seems safe to say that it seems that though I've finally moved into a dev office (beforehand being the only developer around) I seem to be the one they go to when a strategic solution is needed ASAP and the normal processes can't be followed (fun for someone with a CompSci degree and a number of project management courses under the belt... though I honestly do enjoy the challenges)
But I always end up Jack of all but master of, well hopefully some at least. let's not even get started on the tech related hobbies from circuit design and IoT to Andoid / iOS and game dev and enjoying a bit of pen testing to make sure we're all safe at work and at home.
As much as I don't like boxes, I'm interested to know if there is in fact a box for me? By the way, the above is just a snapshot of my last two years minus the project management work...2 -
How the fuck you people do load testing ?
Don't tell me JMeter, it's useless as it doesn't represent an actual browser session...
I'm not taliong "test APIs" but the whole user experiance....
Can't find a single tool which does it at 1000+ sessions....5 -
Sophomore year starting soon so I'm looking for new project (s) to complete in parallel with the studies.
Some are more design-y and some more backend-y but I recently started getting better at designing so :)
1) Learn some fragment shader stuff. I've always been messing around with graphics and have a game on steam, so I think that's a good idea to be paired with signal processing.
2) Reactive web services. Preferably with spring-boot or vert.x but
3) I would also like to dive into golang (and make some reactive thing with it)
4) WebAssembly seems nice... But I got some concerns
5) exercise making wireframes -> CSS (with some js)
6) I've never really done any real backed work with nodejs, except serving and aot compiling js, or doing gulp tasks
7) Implementing a whole project, or a fraction of it as serverless on aws
* I'm definitely going to use a couple very simple services to make a docker swarm with load balancing, etc, just because I know how everything works but got no practical knowledge
8) Design an esports jersey for the university department I'm in (shouldn't take long)
So what do you guys think? Recommendations are welcome :)
P.S. last year in review:
> A webapp running on a raspberry pi powering a reflex testing game on gpio (java/spring-boot , codename: buttonmasher)
> small Elastic search cluster to monitor some random university servers through kibana dashboards
> laser tracking on wall of *any* colour and variable light conditions via a webcam (opencv) , controlling the mouse pointer, whether you run it against a projector or any wall
> jstrain.herokuapp.com => a small JavaScript powered tool with a DSL to help you train more efficiently without a coach
> Various random Photoshop stuff -
I want to ask for your opinion guys, because I don't know if I am right or wrong.
So, some days ago, my brother sent me some code to check out for an automation that he does for testing purposes, since he's a QA (I am a programmer). He should be able to send XML data to a server and depending on the process that he tests, the data is different every time. I saw a strange thing, he hardcodes the XML tags and concatenates them with data which I find stupid. So I proposed him to use a template to generate XML data, because I think it's more flexible and easier, making data and presentation separate. That way if in the future he wants to start using JSON he could do it in no time. I made the code in a separate file which he imports and uses it's functions (they are two so no need for classes) and uses them to load the template and render it as he passes the data as a hash table. He insists that concatenating data and XML tags is easier and simpler and I can't wrap my mind how could that be true. I gave him an example in which the data structure for a process is changed and he have to open the file and change the XML tags or the structure and he still says that's simpler.
What is the right decision in this situation. Keep in mind that I simplified the process a lot and it actually involves sending the data and reporting the results, but they are not important here since I am talking only about generating data. -
!rant
Tldr check out http://guitarprohub.mrstebo.co.uk/
And ignore the stats on the first page. That is my next job to track downloads and searches 😄
I have never been taught how to "plan" projects, but with a small plan I managed to get this site running in about a 3 days (in between having to look after the kids!) only running on a free heroku instance for testing.
If anyone wants to get their hands dirty with the code then let me know. Not a pro at rails yet, but from the stats in new relic it seems to be running pretty quickly! Even with contacting an external site it was only taking 2ms to load a page of tabs!









































Top Tags
Weekly Rant
View