
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Funny story about the first time two of my servers got hacked. The fun part is how I noticed it.
So I purchased two new vps's for proxy server goals and thought like 'I can setup fail2ban tomorrow, I'll be fine.'
Next day I wanted to install NginX so I ran the command and it said that port 80 was already in use!
I was sitting there like no that's not possible I didn't install any server software yet. So I thought 'this can't be possible' but I ran 'pidof apache2' just to confirm. It actually returned a PID! It was a barebones Debian install so I was sure it was not installed yet by ME. Checked the auth logs and noticed that an IP address had done a huge brute force attack and managed to gain root access. Simply reinstalled debian and I put fail2ban on it RIGHT AWAY.
Checked about two seconds later if anyone tried to login again (iptables -L and keep in mind that fail2ban's default config needs six failed attempts within I think five minutes to ban an ip) and I already saw that around 8-10 addresses were banned.
Was pretty shaken up but damn I learned my lesson!8 -
Hey, Root? How do you test your slow query ticket, again? I didn't bother reading the giant green "Testing notes:" box on the ticket. Yeah, could you explain it while I don't bother to listen and talk over you? Thanks.
And later:
Hey Root. I'm the DBA. Could you explain exactly what you're doing in this ticket, because i can't understand it. What are these new columns? Where is the new query? What are you doing? And why? Oh, the ticket? Yeah, I didn't bother to read it. There was too much text filled with things like implementation details, query optimization findings, overall benchmarking results, the purpose of the new columns, and i just couldn't care enough to read any of that. Yeah, I also don't know how to find the query it's running now. Yep, have complete access to the console and DB and query log. Still can't figure it out.
And later:
Hey Root. We pulled your urgent fix ticket from the release. You know, the one that SysOps and Data and even execs have been demanding? The one you finished three months ago? Yep, the problem is still taking down production every week or so, but we just can't verify that your fix is good enough. Even though the changes are pretty minimal, you've said it's 8x faster, and provided benchmark findings, we just ... don't know how to get the query it's running out of the code. or how check the query logs to find it. So. we just don't know if it's good enough.
Also, we goofed up when deploying and the testing database is gone, so now we can't test it since there are no records. Nevermind that you provided snippets to remedy exactly scenario in the ticket description you wrote three months ago.
And later:
Hey Root: Why did you take so long on this ticket? It has sat for so long now that someone else filed a ticket for it, with investigation findings. You know it's bringing down production, and it's kind of urgent. Maybe you should have prioritized it more, or written up better notes. You really need to communicate better. This is why we can't trust you to get things out.
*twitchy smile*19 -
this.title = "gg Microsoft"
this.metadata = {
rant: true,
long: true,
super_long: true,
has_summary: true
}
// Also:
let microsoft = "dead" // please?
tl;dr: Windows' MAX_PATH is the devil, and it basically does not allow you to copy files with paths that exceed this length. No matter what. Even with official fixes and workarounds.
Long story:
So, I haven't had actual gainful employ in quite awhile. I've been earning just enough to get behind on bills and go without all but basic groceries. Because of this, our electronics have been ... in need of upgrading for quite awhile. In particular, we've needed new drives. (We've been down a server for two years now because its drive died!)
Anyway, I originally bought my external drive just for backup, but due to the above, I eventually began using it for everyday things. including Steam. over USB. Terrible, right? So, I decided to mount it as an internal drive to lower the read/write times. Finding SATA cables was difficult, the motherboard's SATA plugs are in a terrible spot, and my tiny case (and 2yo) made everything soo much worse. It was a miserable experience, but I finally got it installed.
However! It turns out the Seagate external drives use some custom drive header, or custom driver to access the drive, so Windows couldn't read the bare drive. ffs. So, I took it out again (joy) and put it back in the enclosure, and began copying the files off.
The drive I'm copying it to is smaller, so I enabled compression to allow storing a bit more of the data, and excluded a couple of directories so I could copy those elsewhere. I (barely) managed to fit everything with some pretty tight shuffling.
but. that external drive is connected via USB, remember? and for some reason, even over USB3, I was only getting ~20mb/s transfer rate, so the process took 20some hours! In the interim, I worked on some projects, watched netflix, etc., then locked my computer, and went to bed. (I also made sure to turn my monitors and keyboard light off so it wouldn't be enticing to my 2yo.) Cue dramatic music ~
Come morning, I go to check on the progress... and find that the computer is off! What the hell! I turn it on and check the logs... and found that it lost power around 9:16am. aslkjdfhaslkjashdasfjhasd. My 2yo had apparently been playing with the power strip and its enticing glowing red on/off switch. So. It didn't finish copying.
aslkjdfhaslkjashdasfjhasd x2
Anyway, finding the missing files was easy, but what about any that didn't finish? Filesizes don't match, so writing a script to check doesn't work. and using a visual utility like windirstat won't work either because of the excluded folders. Friggin' hell.
Also -- and rather the point of this rant:
It turns out that some of the files (70 in total, as I eventually found out) have paths exceeding Windows' MAX_PATH length (260 chars). So I couldn't copy those.
After some research, I learned that there's a Microsoft hotfix that patches this specific issue! for my specific version! woo! It's like. totally perfect. So, I installed that, restarted as per its wishes... tried again (via both drag and `copy`)... and Lo! It did not work.
After installing the hotfix. to fix this specific issue. on my specific os. the issue remained. gg Microsoft?
Further research.
I then learned (well, learned more about) the unicode path prefix `\\?\`, which bypasses Windows kernel's path parsing, and passes the path directly to ntfslib, thereby indirectly allowing ~32k path lengths. I tried this with the native `copy` command; no luck. I tried this with `robocopy` and cygwin's `cp`; they likewise failed. I tried it with cygwin's `rsync`, but it sees `\\?\` as denoting a remote path, and therefore fails.
However, `dir \\?\C:\` works just fine?
So, apparently, Microsoft's own workaround for long pathnames doesn't work with its own utilities. unless the paths are shorter than MAX_PATH? gg Microsoft.
At this point, I was sorely tempted to write my own copy utility that calls the internal Windows APIs that support unicode paths. but as I lack a C compiler, and haven't coded in C in like 15 years, I figured I'd try a few last desperate ideas first.
For the hell of it, I tried making an archive of the offending files with winRAR. Unsurprisingly, it failed to access the files.
... and for completeness's sake -- mostly to say I tried it -- I did the same with 7zip. I took one of the offending files and made a 7z archive of it in the destination folder -- and, much to my surprise, it worked perfectly! I could even extract the file! Hell, I could even work with paths >340 characters!
So... I'm going through all of the 70 missing files and copying them. with 7zip. because it's the only bloody thing that works. ffs
Third-party utilities work better than Microsoft's official fixes. gg.
...
On a related note, I totally feel like that person from http://xkcd.com/763 right now ;;21 -
My team handles infrastructure deployment and automation in the cloud for our company, so we don't exactly develop applications ourselves, but we're responsible for building deployment pipelines, provisioning cloud resources, automating their deployments, etc.
I've ranted about this before, but it fits the weekly rant so I'll do it again.
Someone deployed an autoscaling application into our production AWS account, but they set the maximum instance count to 300. The account limit was less than that. So, of course, their application gets stuck and starts scaling out infinitely. Two hundred new servers spun up in an hour before hitting the limit and then throwing errors all over the place. They send me a ticket and I login to AWS to investigate. Not only have they broken their own application, but they've also made it impossible to deploy anything else into prod. Every other autoscaling group is now unable to scale out at all. We had to submit an emergency limit increase request to AWS, spent thousands of dollars on those stupidly-large instances, and yelled at the dev team responsible. Two weeks later, THEY INCREASED THE MAX COUNT TO 500 AND IT HAPPENED AGAIN!
And the whole thing happened because a database filled up the hard drive, so it would spin up a new server, whose hard drive would be full already and thus spin up a new server, and so on into infinity.
Thats probably the only WTF moment that resulted in me actually saying "WTF?!" out loud to the person responsible, but I've had others. One dev team had their code logging to a location they couldn't access, so we got daily requests for two weeks to download and email log files to them. Another dev team refused to believe their server was crashing due to their bad code even after we showed them the logs that demonstrated their application had a massive memory leak. Another team arbitrarily decided that they were going to deploy their code at 4 AM on a Saturday and they wanted a member of my team to be available in case something went wrong. We aren't 24/7 support. We aren't even weekend support. Or any support, technically. Another team told us we had one day to do three weeks' worth of work to deploy their application because they had set a hard deadline and then didn't tell us about it until the day before. We gave them a flat "No" for that request.
I could probably keep going, but you get the gist of it.4 -
Site (I didn't build) got hacked, lots of data deleted, trying to find out what happened before we restore backup.
Check admin access, lots of blank login submissions from a few similar IPs. Looks like they didn't brute force it.
Check request logs, tons of requests at different admin pages. Still doesn't look like they were targeting the login page.
We're looking around asking ourselves "how did they get in?"
I notice the page with the delete commands has an include file called "adminCheck".
Inside, I find code that basically says "if you're not an admin, now you are!" Full access to everything.
I wonder if the attack was even malicious.3 -
ANTI VIRUSES AREN'T ALWAYS YOUR FRIEND!
So I'm under a little pressure to get an assignment done so I came home an was planning on working on it but Windows had other plans and decided to finish its update which I suspect copied my hard drive and uploaded it to the NSA at dial up speed because it it forever!!
But anyway back to the text in caps lock... I started working on it then when I hit compile I got an "access denied" error in the console and didn't know what the f*** was going on. So I decided to copy my filed to another directory and tried again... amazingly this worked so I carried on and after about 2 hours I get the same error -_- So instead of messing around and loosing my work I decided to commit it... but I cant... again "access denied" error.
After threatening my computer with a trip out the window, I finally decided to reboot it... cause "have you tried turning it off and on again" kept on rattling in my head.
After logging in I tried again and still the same error... Then I opened up my anti virus dashboard and went through the logs and found the screen shot attached.....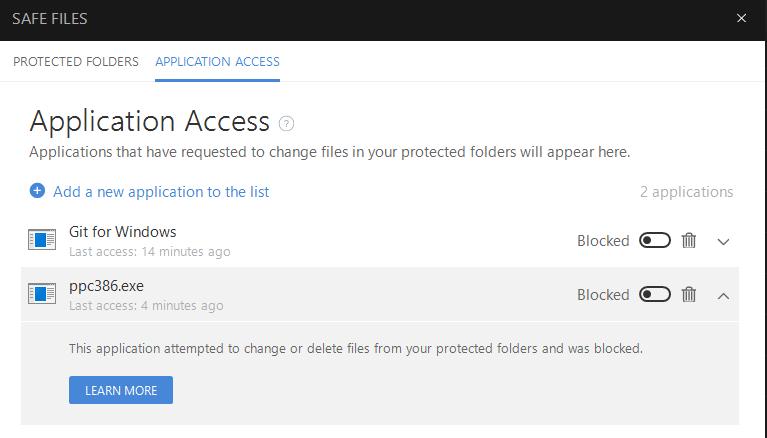 14
14 -
micromanager: "Quick and easy win! Please have this done in 2-3 days to start repairing your reputation"
ticket: "Scrap this gem, and implement your own external service wrapper using the new and vastly different Slack API!"
slack: "New API? Give me bearer tokens! Don't use that legacy url crap, wth"
prev dev: "Yeah idk what a bearer token is. Have the same url instead, and try writing it down so you don't forget it?"
Slack admin: "I can't give you access to the slack integration test app, even though it's for exactly this and three others have access already, including your (micro)manager."
Slack: "You can also <a>create a new slack app</a>!" -- link logs me into slack chat instead. After searching and finding a link elsewhere: doesn't let me.
Slack admin: "You want a new test slack app instead? Sure, build it the same as before so it isn't abuseable. No? Okay, plan a presentation for it and bring security along for a meeting on Friday and I'll think about it. I'm in some planning meetings until then."
asdfjkagel.
This job is endless delays, plus getting yelled at over the endless delays.
At least I can start on the code while I wait. Can't test anything for at least a week, though. =/15 -
I just finished setting up an instance of searx.me for the public to use.
You are free to use it at https://search.privacy-cloud.me
I can't prove it but I've disabled logging with searx and ip logging in the nginx access logs (catching ddos's another way). If you don't find that enough proof then I suggest you don't use it :)
Let's go to sleep now.13 -
Long rant ahead.. so feel free to refill your cup of coffee and have a seat 🙂
It's completely useless. At least in the school I went to, the teachers were worse than useless. It's a bit of an old story that I've told quite a few times already, but I had a dispute with said teachers at some point after which I wasn't able nor willing to fully do the classes anymore.
So, just to set the stage.. le me, die-hard Linux user, and reasonably initiated in networking and security already, to the point that I really only needed half an ear to follow along with the classes, while most of the time I was just working on my own servers to pass the time instead. I noticed that the Moodle website that the school was using to do a big chunk of the course material with, wasn't TLS-secured. So whenever the class begins and everyone logs in to the Moodle website..? Yeah.. it wouldn't be hard for anyone in that class to steal everyone else's credentials, including the teacher's (as they were using the same network).
So I brought it up a few times in the first year, teacher was like "yeah yeah we'll do it at some point". Shortly before summer break I took the security teacher aside after class and mentioned it another time - please please take the opportunity to do it during summer break.
Coming back in September.. nothing happened. Maybe I needed to bring in more evidence that this is a serious issue, so I asked the security teacher: can I make a proper PoC using my machines in my home network to steal the credentials of my own Moodle account and mail a screencast to you as a private disclosure? She said "yeah sure, that's fine".
Pro tip: make the people involved sign a written contract for this!!! It'll cover your ass when they decide to be dicks.. which spoiler alert, these teachers decided they wanted to be.
So I made the PoC, mailed it to them, yada yada yada... Soon after, next class, and I noticed that my VPN server was blocked. Now I used my personal VPN server at the time mostly to access a file server at home to securely fetch documents I needed in class, without having to carry an external hard drive with me all the time. However it was also used for gateway redirection (i.e. the main purpose of commercial VPN's, le new IP for "le onenumity"). I mean for example, if some douche in that class would've decided to ARP poison the network and steal credentials, my VPN connection would've prevented that.. it was a decent workaround. But now it's for some reason causing Moodle to throw some type of 403.
Asked the teacher for routers and switches I had a class from at the time.. why is my VPN server blocked? He replied with the statement that "yeah we blocked it because you can bypass the firewall with that and watch porn in class".
Alright, fair enough. I can indeed bypass the firewall with that. But watch porn.. in class? I mean I'm a bit of an exhibitionist too, but in a fucking class!? And why right after that PoC, while I've been using that VPN connection for over a year?
Not too long after that, I prematurely left that class out of sheer frustration (I remember browsing devRant with the intent to write about it while the teacher was watching 😂), and left while looking that teacher dead in the eyes.. and never have I been that cold to someone while calling them a fucking idiot.
Shortly after I've also received an email from them in which they stated that they wanted compensation for "the disruption of good service". They actually thought that I had hacked into their servers. Security teachers, ostensibly technical people, if I may add. Never seen anyone more incompetent than those 3 motherfuckers that plotted against me to save their own asses for making such a shitty infrastructure. Regarding that mail, I not so friendly replied to them that they could settle it in court if they wanted to.. but that I already knew who would win that case. Haven't heard of them since.
So yeah. That's why I regard those expensive shitty pieces of paper as such. The only thing they prove is that someone somewhere with some unknown degree of competence confirms that you know something. I think there's far too many unknowns in there.
Nowadays I'm putting my bets on a certification from the Linux Professional Institute - a renowned and well-regarded certification body in sysadmin. Last February at FOSDEM I did half of the LPIC-1 certification exam, next year I'll do the other half. With the amount of reputation the LPI has behind it, I believe that's a far better route to go with than some random school somewhere.25 -
The website for our biggest client went down and the server went haywire. Though for this client we don’t provide any infrastructure, so we called their it partner to start figuring this out.
They started blaming us, asking is if we had upgraded the website or changed any PHP settings, which all were a firm no from us. So they told us they had competent people working on the matter.
TL;DR their people isn’t competent and I ended up fixing the issue.
Hours go by, nothing happens, client calls us and we call the it partner, nothing, they don’t understand anything. Told us they can’t find any logs etc.
So we setup a conference call with our CXO, me, another dev and a few people from the it partner.
At this point I’m just asking them if they’ve looked at this and this, no good answer, I fetch a long ethernet cable from my desk, pull it to the CXO’s office and hook up my laptop to start looking into things myself.
IT partner still can’t find anything wrong. I tail the httpd error log and see thousands upon thousands of warning messages about mysql being loaded twice, but that’s not the issue here.
Check top and see there’s 257 instances of httpd, whereas 256 is spawned by httpd, mysql is using 600% cpu and whenever I try to connect to mysql through cli it throws me a too many connections error.
I heard the IT partner talking about a ddos attack, so I asked them to pull it off the public network and only give us access through our vpn. They do that, reboot server, same problems.
Finally we get the it partner to rollback the vm to earlier last night. Everything works great, 30 min later, it crashes again. At this point I’m getting tired and frustrated, this isn’t my job, I thought they had competent people working on this.
I noticed that the db had a few corrupted tables, and ask the it partner to get a dba to look at it. No prevail.
5’o’clock is here, we decide to give the vm rollback another try, but first we go home, get some dinner and resume at 6pm. I had told them I wanted to be in on this call, and said let me try this time.
They spend ages doing the rollback, and then for some reason they have to reconfigure the network and shit. Once it booted, I told their tech to stop mysqld and httpd immediately and prevent it from start at boot.
I can now look at the logs that is leading to this issue. I noticed our debug flag was on and had generated a 30gb log file. Tail it and see it’s what I’d expect, warmings and warnings, And all other logs for mysql and apache is huge, so the drive is full. Just gotta delete it.
I quietly start apache and mysql, see the website is working fine, shut it down and just take a copy of the var/lib/mysql directory and etc directory just go have backups.
Starting to connect a few dots, but I wasn’t exactly sure if it was right. Had the full drive caused mysql to corrupt itself? Only one way to find out. Start apache and mysql back up, and just wait and see. Meanwhile I fixed that mysql being loaded twice. Some genius had put load mysql.so at the top and bottom of php ini.
While waiting on the server to crash again, I’m talking to the it support guy, who told me they haven’t updated anything on the server except security patches now and then, and they didn’t have anyone familiar with this setup. No shit, it’s running php 5.3 -.-
Website up and running 1.5 later, mission accomplished.6 -
Dev: Can you please tell me why you changed this?
Me: Because we need to handle permissions in the app. The quickest way of doing it, according to the docs, is [insert change log here]
Dev: But we can just check for the user's token.
Me: That's not exactly a permission, because...
Dev: I was only showing the information related to the user according to their token.
Me: I understand. But that means you're filtering data, not authorising users to access it. If a user is logged in, but changes query parameters, they can still access data they shouldn't be able to.
Dev: Whatevs.
Le me then proceeds to try to push my changes (that took the whole day to implement), gets a "you need to pull first" message from git, doesn't understand why, logs onto GitHub and realises dev has implemented their "permissions".
I was the one responsible for making those changes. Le dev was meant to be doing other things.
How do I even begin to explain?7 -
My University distributes all worksheets over an online system. To access the files one has to download them each time first. So to get rid of all this annoying clicking in the browser, I just programmed a service, which logs onto the website ,crawls trough every folder, searches for new files and downloads them if they do not exist on my computer. Kind of proud as this is pretty much the first really useful program I developed lol
 8
8 -
Did i just get rick rolled through a user agent?
"[17/Nov/2020:10:20:42 +0000] "GET / HTTP/1.1" 200 1274 "-" "We are no strangers to love. You know the rules and so do I. A full commitment is what Im thinking of. You wouldnt get this from any other guy.." "-""4 -
So my previous alma mater's IT servers are really hacked easily. They run mostly in Microsoft Windows Server and Active Directory and only the gateway runs in Linux. When I checked the stationed IT's computer he was having problems which I think was another intrusion.
I asked the guy if I can get root access on the Gateway server. He was hesitant at first but I told him I worked with a local Linux server before. He jested, sent me to the server room with his supervision. He gave me the credentials and told me "10 minutes".
What I did?
I just installed fail2ban, iptables, and basically blocked those IP ranges used by the attacker. The attack quickly subsided.
Later we found out it was a local attack and the attacker was brute forcing the SSH port. We triaged it to one kid in the lobby who was doing the brute forcing connected in the lobby WiFi. Turns out he was a script kiddie and has no knowledge I was tracking his attacks via fail2ban logs.
Moral of lesson: make sure your IT secures everything in place.1 -
TLDR - you shouldn't expect common sense from idiots who have access to databases.
I joined a startup recently. I know startups are not known for their stable architecture, but this was next level stuff.
There is one prod mongodb server.
The db has 300 collections.
200 of those 300 collections are backups/test collections.
25 collections are used to store LOGS!! They decided to store millions of logs in a nosql db because setting up a mysql server requires effort, why do that when you've already set up mongodb. Lol 😂
Each field is indexed separately in the log.
1 collection is of 2 tb and has more than 1 billion records.
Out of the 1 billion records, 1 million records are required, the rest are obsolete. Each field has an index. Apparently the asshole DBA never knew there's something called capped collection or partial indexes.
Trying to get approval to clean up the db since 3 months, but fucking bureaucracy. Extremely high server costs plus every week the db goes down since some idiot runs a query on this mammoth collection. There's one single set of credentials for everything. Everyone from applications to interns use the same creds.
And the asshole DBA left, making me in charge of handling this shit now. I am trying to fix this but am stuck to get approval from business management. Devs like these make me feel sad that they have zero respect for their work and inability to listen to people trying to improve the system.
Going to leave this place really soon. No point in working somewhere where you are expected to show up for 8 hours, irrespective of whether you even switch on your laptop.
Wish me luck folks.3 -
So I have that custom-made wifi router I've built. And it uses a USB wifi adapter with AC (wifi5) capability - the fastest one I could find in AliExpress.
I set it up a while ago - the internet access works fine, although speeds are somewhat sluggish. But hey, what to expect from a cheapo on Ali! Not to mention it's USB, not a PCIe...
A few days ago I ran a few speedtest.net tests with my actual AC router and the one I've built. Results were so different I wanted to cry :( some pathetic 23Mbps with my custom router :(
This evening I had some time on my hands and finally decided to have an umpteenth look.
nmcli d wifi
this is what caught my eye first. The RATE column listed my custom router as 54Mbps, whereas the actual router had 195Mbps.
I have reviewed the hostapd configuration sooo many times - this time nothing caught my eye as well.
Googling did not give anything obvious as well.
What do we do next? Yes, that's right - enable debug and read the logs.
> VHT (IEEE 802.11ac) with WPA/WPA2 requires CCMP/GCMP to be enabled, disabling VHT capabilities
This is one of the lines at the top of the log. Waaaaiiitttt.. VHT is something I definitely want with ac -- why does it disable that??? Sounds like a configuration fuckup rather than the HW limitation! And config fuckups CAN be fixed!
Turns out, an innocently looking
`wpa_pairwise=TKIP`
change into
`wpa_pairwise=TKIP CCMP`
made a world of a difference!
:wq
!hostapd
connect to the hostapd hotspot and run that iperf3 test again, and... Oh my. Oh boi! My pants fell off -- the speed increased >3x times!
A quick speedtest.net test deems my custom router's download speeds hardly any worse than the speeds obtained using my LInksys!!
The moral of the story: no matter how innocent some configurations look, they might make a huge difference. And RTFL [read the fucking logs]
In the pic -- left - my actual router, right - my custom-built router with a USB wifi adapter. Not too shabby! 6
6 -
In the before time (late 90s) I worked for a company that worked for a company that worked for a company that provided software engineering services for NRC regulatory compliance. Fallout radius simulation, security access and checks, operational reporting, that sort of thing. Given that, I spent a lot of time around/at/in nuclear reactors.
One day, we're working on this system that uses RFID (before it was cool) and various physical sensors to do a few things, one of which is to determine if people exist at the intersection of hazardous particles, gasses, etc.
This also happens to be a system which, at that moment, is reporting hazardous conditions and people at the top of the outer containment shell. We know this is probably a red herring or faulty sensor because no one is present in the system vs the access logs and cameras, but we have to check anyways. A few building engineers climb the ladders up there and find that nothing is really visibly wrong and we have an all clear. They did not however know how to check the sensor.
Enter me, the only person from our firm on site that day. So in the next few minutes I am also in a monkey suit (bc protocol), climbing a 150 foot ladder that leads to another 150 foot ladder, all 110lbs of me + a 30lb diag "laptop" slung over my shoulder by a strap. At the top, I walk about a quarter of the way out, open the casing on the sensor module and find that someone had hooked up the line feed, but not the activity connection wire so it was sending a false signal. I open the diag laptop, plug it into the unit, write a simple firmware extension to intermediate the condition, flash, reload. I verify the error has cleared and an appropriate message was sent to the diagnostic system over the radio, run through an error test cycle, radio again, close it up. Once I returned to the ground, sweating my ass off, I also send a not at all passive aggressive email letting the boss know that the next shift will need to push the update to the other 600 air-gapped, unidirectional sensors around the facility.11 -
Never mess with a motivated developer. I will make your life difficult in return.
Me: we need server logs and stats daily for analysis
DBA: to get those, you need to open a ticket
Me: can't you just give me SFTP access and permissions to query the stats from the DB?
DBA: No.
*OK.... 🤔🤔🤔*
*Writes an Excel Template file that I basically just need to copy and paste from to create a ticket*
This process should not take me more than 2mins 👍😁😋🙂😙😙😙😙😙😙😙😙
For them.... 😈😈😈😈😈😈😈😈😈😈😈9 -
Holy FREAKING shit!! This was worst stupidest mistake I have ever made!
About 9 hours ago, i decided to implement brotli compression in my server.
It looked a bit challenging for me, because the all the guides involved compiling and building the nginx with brotli module and I was not that confident doing that on live site.
By the end of the guide, the site was not reachable anymore. I panicked.
Even the error logs and access logs were not picking up anything.
About a dozens guides and a new server and figuring out few major undocumented errors later, it turns out the main nginx.conf file had a line that was looking for *.conf files in the sites-enabled directory.
But my conf file was named after the domain name and ending with .com and hence were not picked up by the new nginx.conf
I'm not sure if I wasted my 9 hours because of that single line or not. But man, this was a really rough day!3 -
A project I'm working on uses Elastic for internal monitoring and logs. The customer asked to access those logs - not something we'd normally do, but it's isolated from other things we use and there's no critical data there, so what the heck, let them have it.
Ever since, we're getting tons of questions like "There are tons of [insert random info message] all the time, do you have any plans to resolve them?" and it gets to the point where I'm just about ready to scream back "NO, SUZAN, BOOKING NOT COMPLETED MANS THE USER F###ING CANCELLED IT, IT'S NOT SOMETHING I CAN FIX IN THE CODE"
Edit: the customer's name isn't actually Suzan4 -
Working in a bank, using MIcrosoft platform:
To open my email, I need to enter my password and sms OTP.
To open my email using phone, I need to enter my password and sms OTP.
To open Teams, I need to enter my password and sms OTP.
To open Teams using phone, I need to enter my password and sms OTP.
To access Microsoft Azure, I need to enter my password and sms OTP.
To git pull/push, I need to enter my sms OTP.
To check UAT logs, I need to enter my sms OTP.
To get access to UAT DB, I need to connect to VPN, which then asks for OTP.
Did I also mention that I need to do these OTPs every single fucking day?
#OTPDrivenDevelopment5 -
Anyone else had an interviewer just blatantly waste your time and lie to you?
I was recently interviewing for a job, the first couple of rounds went really well, and they gave out a fairly standard tech test. It was a basic tic-tac-toe game, with a few extra twists and a 120 minute time limit. They then wanted me to host what I had be able to code somewhere so they could test it out before the second technical interview.
The interview interview date came round, the interviewer never actually showed up, but 20 minutes late he sent me an email saying they wouldn't be going ahead because the code wasn't good enough, and cited a bunch of things that were well outside of the brief they gave for the test. and when I checked the access logs for the hosted 'live' version, it showed they hadn't bothered to actually look at it; they hadn't even checked out the code from the repo.
I've had similar things happen in the past occasionally, but is it just my bad luck, or is stuff like this becoming more common recently?6 -
Want to make someone's life a misery? Here's how.
Don't base your tech stack on any prior knowledge or what's relevant to the problem.
Instead design it around all the latest trends and badges you want to put on your resume because they're frequent key words on job postings.
Once your data goes in, you'll never get it out again. At best you'll be teased with little crumbs of data but never the whole.
I know, here's a genius idea, instead of putting data into a normal data base then using a cache, lets put it all into the cache and by the way it's a volatile cache.
Here's an idea. For something as simple as a single log lets make it use a queue that goes into a queue that goes into another queue that goes into another queue all of which are black boxes. No rhyme of reason, queues are all the rage.
Have you tried: Lets use a new fangled tangle, trust me it's safe, INSERT BIG NAME HERE uses it.
Finally it all gets flushed down into this subterranean cunt of a sewerage system and good luck getting it all out again. It's like hell except it's all shitty instead of all fiery.
All I want is to export one table, a simple log table with a few GB to CSV or heck whatever generic format it supports, that's it.
So I run the export table to file command and off it goes only less than a minute later for timeout commands to start piling up until it aborts. WTF. So then I set the most obvious timeout setting in the client, no change, then another timeout setting on the client, no change, then i try to put it in the client configuration file, no change, then I set the timeout on the export query, no change, then finally I bump the timeouts in the server config, no change, then I find someone has downloaded it from both tucows and apt, but they're using the tucows version so its real config is in /dev/database.xml (don't even ask). I increase that from seconds to a minute, it's still timing out after a minute.
In the end I have to make my own and this involves working out how to parse non-standard binary formatted data structures. It's the umpteenth time I have had to do this.
These aren't some no name solutions and it really terrifies me. All this is doing is taking some access logs, store them in one place then index by timestamp. These things are all meant to be blazing fast but grep is often faster. How the hell is such a trivial thing turned into a series of one nightmare after another? Things that should take a few minutes take days of screwing around. I don't have access logs any more because I can't access them anymore.
The terror of this isn't that it's so awful, it's that all the little kiddies doing all this jazz for the first time and using all these shit wipe buzzword driven approaches have no fucking clue it's not meant to be this difficult. I'm replacing entire tens of thousands to million line enterprise systems with a few hundred lines of code that's faster, more reliable and better in virtually every measurable way time and time again.
This is constant. It's not one offender, it's not one project, it's not one company, it's not one developer, it's the industry standard. It's all over open source software and all over dev shops. Everything is exponentially becoming more bloated and difficult than it needs to be. I'm seeing people pull up a hundred cloud instances for things that'll be happy at home with a few minutes to a week's optimisation efforts. Queries that are N*N and only take a few minutes to turn to LOG(N) but instead people renting out a fucking off huge ass SQL cluster instead that not only costs gobs of money but takes a ton of time maintaining and configuring which isn't going to be done right either.
I think most people are bullshitting when they say they have impostor syndrome but when the trend in technology is to make every fucking little trivial thing a thousand times more complex than it has to be I can see how they'd feel that way. There's so bloody much you need to do that you don't need to do these days that you either can't get anything done right or the smallest thing takes an age.
I have no idea why some people put up with some of these appliances. If you bought a dish washer that made washing dishes even harder than it was before you'd return it to the store.
Every time I see the terms enterprise, fast, big data, scalable, cloud or anything of the like I bang my head on the table. One of these days I'm going to lose my fucking tits.10 -
I know Google isn't the worst company in the world. But some of their data tracking just seems a bit odd. Such as keeping audio logs each time you use Google on your phone. Or when it picks up random bits of conversation. Along with them keeping track of where your going, and where you have been. Even if Google maps isn't running.
And one of my all time favorites is when Google Allo was a thing, it used to have access to my camera randomly without actually opening the app. My phone will tell me different logs each time Allo opened the camera without my permission.
I know they need to collect data in order to advance some of their fields of tech. But it just seems a bit intrusive when companies like Google do this.11 -
I’m fairly new to maintaining my own webservers. For the past week the servers (two of them) kept crashing constantly.
After some investigation I figured it was due to someone running a script trying to get ssh access.
I learned about fail2ban, DOS and DDOS attacks and had quite a fight configuring it all since I had 20 seconds on average between the server shutdowns and had to use those 20 second windows to configure fail2ban bit by bit.
Finally after a few hours it was up and running on both servers and recognized 380 individual IPs spamming random e-mail / password combos.
I fet relieved seeing that it all stopped right after fail2ban installation and thought I was safe now and went to sleep.
I wake up this morning to another e-mail stating that pinging my server failed once again.
I go back to the logs, worried that the attack became more sophisticated or whatever only to see that the 06:25 cronjob is causing another fucking crash. I can’t figure out why.
Fuck this shit. I’m setting another cronjob to restart this son of a bitch at 06:30.
I’m done.3 -
When there is a fire alarm where I work, someone has to go print out the door access logs so we have a list of who is (theoretically) on site and make sure no one is still inside. The printer is half way across the building. And breaks down at least once a day.
We are all going to die.5 -
I work on a warehouse dev team. One day this past year, I was trying to deploy a new build to a QA server. Earlier that day I had been looking at the logs on the production server and had left the ssh session open. I had been working for less than a year out of college at this point and shouldn't have had access to deploy to the production server.
Long story short I deployed my QA build to the production server and saw there were problems connection to our production database. Then my heart dropped in my chest as I realized I had just brought down our production server.
I managed to get the server back up by rolling back in about 5 minutes and no one ever knew except some people on my team.
I felt horrible for the longest time. Later in the year another guy that joined my team that has about 20 years of experience under his belt did the exact same thing, but needed help rolling it back. Needless to say, that made me feel a lot better. 😂
Definitely the worst moment of my year.3 -
TL;DR my first vps got hacked, the attacker flooded my server log when I successfully discovered and removed him so I couldn't use my server anymore because the log was taking up all the space on the server.
The first Linux VPN I ever had (when I was a noob and had just started with vServers and Linux in general, obviously) got hacked within 2 moths since I got it.
As I didn't knew much about securing a Linux server, I made all these "rookie" mistakes: having ssh on port 22, allowing root access via ssh, no key auth...
So, the server got hacked without me even noticing. Some time later, I received a mail from my hoster who said "hello, someone (probably you) is running portscans from your server" of which I had no idea... So I looked in the logs, and BAM, "successful root login" from an IP address which wasn't me.
After I found out the server got hacked, I reinstalled the whole server, changed the port and activated key auth and installed fail2ban.
Some days later, when I finally configured everything the way I wanted, I observed I couldn't do anything with that server anymore. Found out there was absolutely no space on the server. Made a scan to find files to delete and found a logfile. The ssh logfile. I took up a freaking 95 GB of space (of a total of 100gb on the server). Turned out the guy who broke into my server got upset I discovered him and bruteforced the shit out of my server flooding the logs with failed login attempts...
I guess I learnt how to properly secure a server from this attack 💪3 -
I think I made someone angry, then sad, then depressed.
I usually shrink a VM before archiving them, to have a backup snapshot as a template. So Workflow: prepare, test, shrink, backup -> template, document.
Shrinking means... Resetting root user to /etc/skel, deleting history, deleting caches, deleting logs, zeroing out free HD space, shutdown.
Coworker wanted to do prep a VM for docker (stuff he's experienced with, not me) so we can mass rollout the template for migration after I converted his steps into ansible or the template.
I gave him SSH access, explained the usual stuff and explained in detail the shrinking part (which is a script that must be explicitly called and has a confirmation dialog).
Weeeeellll. Then I had a lil meeting, then the postman came, then someone called.
I had... Around 30 private messages afterwards...
- it took him ~ 15 minutes to figure out that the APT cache was removed, so searching won't work
- setting up APT lists by copy pasta is hard as root when sudo is missing....
- seems like he only uses aliases, as root is a default skel, there were no aliases he has in his "private home"
- Well... VIM was missing, as I hate VIM (personal preferences xD)... Which made him cry.
- He somehow achieved to get docker working as "it should" (read: working like he expects it, but that's not my beer).
While reading all this -sometimes very whiney- crap, I went to the fridge and got a beer.
The last part was golden.
He explicitly called the shrink script.
And guess what, after a reboot... History was gone.
And the last message said:
Why did the script delete the history? How should I write the documentation? I dunno what I did!
*sigh* I expected the worse, got the worse and a good laugh in the end.
Guess I'll be babysitting tomorrow someone who's clearly unable to think for himself and / or listen....
Yay... 4h plus phone calls. *cries internally*1 -
Today was a good day.
I was told to use in-house BitBucket runners for the pipelines. Turns out, they are LinuxShellRunners and do not support docker/containers.
I found a way to set up contained, set up all the dependencies and successfully run my CI tasks using dagger.io (w/o direct access to the runner -- only through CI definition yaml and Job logs in the BitBucket console).
Turns out, my endeavour triggered some alerts for the Infra folks.
I don't care. I'm OOO today. And I hacked their runners to do what I wanted them to do (but they weren't supposed to do any of it). All that w/o access to the runners themselves.
It was a good day :)))))
Now I'll pat myself on my back and go get a nice cup of tea for my EOD :)3 -
!rant
Need some opinions. Joined a new company recently (yippee!!!). Just getting to grips with everything at the minute. I'm working on mobile and I will be setting up a new team to take over a project from a remote team. Looking at their iOS and Android code and they are using RxSwift and RxJava in them.
Don't know a whole lot about the Android space yet, but on iOS I did look into Reactive Cocoa at one point, and really didn't like it. Does anyone here use Rx, or have an opinion about them, good or bad? I can learn them myself, i'm not looking for help with that, i'm more interested in opinions on the tools themselves.
My initial view (with a lack of experience in the area):
- I'm not a huge fan of frameworks like this that attempt to change the entire flow or structure of a language / platform. I like using third party libraries, but to me, its excessive to include something like this rather than just learning the in's / out's of the platform. I think the reactive approach has its use cases and i'm not knocking the it all together. I just feel like this is a little bit of forcing a square peg into a round hole. Swift wasn't designed to work like that and a big layer will need to be added in, in order to change it. I would want to see tremendous gains in order to justify it, and frankly I don't see it compared to other approaches.
- I do like the MVVM approach included with it, but i've easily managed to do similar with a handful of protocols that didn't require a new architecture and approach.
- Not sure if this is an RxSwift thing, or just how its implemented here. But all ViewControllers need to be created by using a coordinator first. This really bugs me because it means changing everything again. When I first opened this app, login was being skipped, trying to add it back in by selecting the default storyboard gave me "unwrapping a nil optional" errors, which took a little while to figure out what was going on. This, to me, again is changing too much in the platform that even the basic launching of a screen now needs to be changed. It will be confusing while trying to build a new team who may or may not know the tech.
- I'm concerned about hiring new staff and having to make sure that they know this, can learn it or are even happy to do so.
- I'm concerned about having a decrease in the community size to debug issues. Had horrible experiences with this in the past with hybrid tech.
- I'm concerned with bugs being introduced or patterns being changed in the tool itself. Because it changes and touches everything, it will be a nightmare to rip it out or use something else and we'll be stuck with the issue. This seems to have happened with ReactiveCocoa where they made a change to their approach that seems to have caused a divide in the community, with people splitting off into other tech.
- In this app we have base Swift, with RxSwift and RxCocoa on top, with AlamoFire on top of that, with Moya on that and RxMoya on top again. This to me is too much when only looking at basic screens and networking. I would be concerned that moving to something more complex that we might end up with a tonne of dependencies.
- There seems to be issues with the server (nothing to do with RxSwift) but the errors seem to be getting caught by RxSwift and turned into very vague and difficult to debug console logs. "RxSwift.RxError error 4" is not great. Now again this could be a "way its being used" issue as oppose to an issue with RxSwift itself. But again were back to a big middle layer sitting between me and what I want to access. I've already had issues with login seeming to have 2 states, success or wrong password, meaning its not telling the user whats actually wrong. Now i'm not sure if this is bad dev or bad tools, but I get a sense RxSwift is contributing to it in some fashion, at least in this specific use of it.
I'll leave it there for now, any opinions or advice would be appreciated.18 -
Currently working on app that is about 10 years old at work. Here’s how today has gone:
Can’t run application locally because the process management engine doesn’t allow access locally, can’t access in development because process management engine doesn’t work here either, can run app in test but waiting on special server access to get the logs.
Make the request to security to access the server - they decline it telling me that the form I submitted is outdated and to submit a new one. Requires three approvals, am still waiting on them.
Every time I make a change and want to test, I have to commit the changes, wait for them to build. Release the changes, build the release project and then deploy it in bamboo.
I can’t wait for my new job to start.1 -
Welp, this made my night and sorta ruined my night at the same time.
He decided to work on a new gaming community but has limited programming knowledge, but has enough to patch and repair minor issues. He's waiting for an old friend of his to come back to start helping him again, so this leads to me. He needed a custom backend made for his server, which required pulling data from an SQL/API and syncing with the server, and he was falling behind pace and asked for my help. He's a good friend that I've known for a while, and I knew it wouldn't take to long to create this, so I decided to help him. Which lead to an interesting find, and sorta made my night.
It wasn't really difficult, got it done within an hour, took some time to test and fix any bugs with his SQL database. But this is where it get's interesting, at least for me. He had roughly a few hundred people that did beta testing of the server, anyways, once the new backend was hooked in and working, I realized that the other developer he works with had created a 'custom' script to make sure there are no leaks of the database. Well, that 'custom' script actually begins wiping rows/tables (Depends on the sub-table, some get wiped row by row, some just get completely dropped), I just couldn't comprehend what had happened, as rows/tables just slowly started disappearing. It took me a while of checking, before checking his SQL query logs (At least the custom script did that properly and logged every query), to realize it just basically wiped the database.
Welp, after that, it began to restrict the API I was using, and due to this it identified the server as foreign access (Since it wasn't using the same key as his plugin, even though I had an API key created just so it could only access ranks and such, to prevent abuse) and begin responding not with denied, but with a lovely "Fuck you hacker!" This really made my night, I don't know why, but I was genuinely laughing pretty hard at this response.
God, I love his developer. Luckily, I had created a backup earlier, so I patched it and just worked around the plugin/API to get it working. (Hopefully, it's not a clusterfuck to read, writing this at 2 am with less than an hour of sleep, bedtime! Goodnight everyone.)7 -
I remember when my module lead left a bug... he immediately went to the client location. He managed to go in the room where only restricted people were allowed.. (even I need to take many permissions to go inside) he confidently asked to check some logs to get the access to the machine, fixed the bug and came back in heroic style.
I was really impressed. -
PouchDB.
It promised full-blown CRDT functionality. So I decided to adopt it.
Disappointment number one: you have to use CouchDB, so your data model is under strict regulations now. Okay.
Disappointment number two: absolutely messed up hack required to restrict users from accessing other users’ data, otherwise you have to store all the user data in single collection. Not the most performant solution.
Disappointment number three: pagination is utter mess. Server-side timestamps are utter mess. ANY server-side logic is utter mess.
Just to set it to work, you need PouchDB itself, websocket adapter (otherwise only three simultaneous syncs), auth adapter (doesn’t work via sockets), which came out fucking large pile of bullshit at the frontend.
Disappointment number four, the final one: auth somehow works but it doesn’t set cookie. I don’t know how to get access.
GitHub user named Wohali, number one CouchDB specialist over there, doesn’t know that either.
It also doesn’t work at Incognito mode, doesn’t work at Firefox at all.
So, if you want to use PouchDB, bear that in mind:
1. CouchDB only
2. No server-side logic
3. Authorization is a mess
4. Error logs are mess too: “ERROR 83929629 broken pipe” means “out of disk space” in Erlang, the CouchDB language.
5. No hosting solutions. No backup solutions, no infrastructure around that at all. You are tied to bare metal VPS and Ansible.
6. Huge pile of bullshit at frontend. Doesn’t work at Incognito mode, doesn’t work at Firefox.8 -
Yesterday was a horrible day...
First of all, as we are short of few devs, I was assigned production bugs... Few applications from mobile app were getting fucked up. All fields in db were empty, no customer name, email, mobile number, etc.
I started investigating, took dump from db, analyzed the created_at time stamps. Installed app, tried to reproduce bug, everything worked. Tried API calls from postman, again worked. There were no error emails too.
So I asked for server access logs, devops took 4 hrs just to give me the log. Went through 4 million lines and found 500 errors on mobile apis. Went to the file, no error handling in place.
So I have a bug to fix which occurs 1 in 100 case, no stack trace, no idea what is failing. Fuck my job. -
Manager X: (logs a support ticket) "Agent is unable to access system using the password provided."
Me: "You're going to have to narrow it down a little, we have over 1000 active agents."
I hate the support side of my job... -
Been working on a new project for the last couple of weeks. New client with a big name, probably lots of money for the company I work for, plus a nice bonus for myself.
But our technical referent....... Goddammit. PhD in computer science, and he probably. approved our project outline. 3 days in development, the basic features of the applications are there for him to see (yay. Agile.), and guess what? We need to change the user roles hierarchy we had agreed on. Oh, and that shouldn't be treated as extra development, it's obviously a bug! Also, these features he never talked about and never have been in the project? That's also a bug! That thing I couldn't start working on before yesterday because I was still waiting the specs from him? It should've been ready a week ago, it's a bug that it's not there! Also, he notes how he could've developes it within 40 minutes and offered to sens us the code to implement directly in our application, or he may even do so himself.... Ah, I forgot to say, he has no idea on what language we are developing the app. He said he didn't care many times so far.
But the best part? Yesterday he signales an outstanding bug: some data has been changed without anyone interacting. It was a bug! And it was costing them moneeeeey (on a dev server)! Ok, let's dig in, it may really be a bug this time, I did update the code and... Wait, what? Someone actually did update a new file? ...Oh my Anubis. HE did replace the file a few minutes before and tried to make it look like a bug! ..May as well double check. So, 15 minutes later I answer to his e-mail, saying that 4 files have been compromised by a user account with admin privileges (not mentioning I knee it was him)... And 3 minutes later he answered me. It was a message full of anger, saying (oh Lord) it was a bug! If a user can upload a new file, it's the application's fault for not blocking him (except, users ARE supposed to upload files, and admins have been requestes to be able to circumvent any kind of restriction)! Then he added how lucky I was, becausw "the issue resolved itself and the data was back, and we shouldn't waste any more yime.on thos". Let's check the logs again.... It'a true! HE UPLOADED THE ORIGINAL FILES BACK! He... He has no idea that logs do exist? A fucking PhD in computer science? He still believes no one knows it was him....... But... Why did he do that? It couldn't have been a mistake. Was he trying to troll me? Or... Or is he really that dense?
I was laughing my ass of there. But there's more! He actually phones my boss (who knew what had happened) to insult me! And to threaten not dwell on that issue anymore because "it's making them lose money". We were both speechless....
There's no way he's a PhD. Yet it's a legit piece of paper the one he has. Funny thing is, he actually manages to launch a couple of sort-of-nationally-popular webservices, and takes every opportunity to remember us how he built them from scratch and so he know what he's saying... But digging through google, you can easily find how he actually outsurced the development to Chinese companies while he "watched over their work" until he bought the code
Wait... Big ego, a decent amount of money... I'm starting to guess how he got his PhD. I also get why he's a "freelance consultant" and none of the place he worked for ever hired him again (couldn't even cover his own tracks)....
But I can't get his definition of "bug".
If it doesn't work as intended, it's a bug (ok)
If something he never communicated is not implemented, it's a bug (what.)
If development has been slowed because he failed to provide specs, it's a bug (uh?)
If he changes his own mind and wants to change a process, it's a bug it doesn't already work that way (ffs.)
If he doesn't understand or like something, it's a bug (i hopw he dies by sonic diarrhoea)
I'm just glad my boss isn't falling for him... If anything, we have enough info to accuse him of sabotage and delaying my work....
Ah, right. He also didn't get how to publish our application we needes access to the server he wantes us to deploy it on. Also, he doesn't understand why we have acces to the app's database and admin users created on the webapp don't. These are bugs (seriously his own words). Outstanding ones.
Just..... Ffs.
Also, sorry for the typos.5 -
The conversations that come across my DevOps desk on a monthly basis.... These have come into my care via Slack, Email, Jira Tickets, PagerDuty alerts, text messages, GitHub PR Reviews, and phone calls. I spend most of my day just trying to log the work I'm being asked to do.
From Random People:
* Employee <A> and Contractor <B> are starting today. Please provision all 19 of their required accounts.
* Oh, they actually started yesterday, please hurry on this request.
From Engineers:
* The database is failing. Why?
* The read-only replica isn't accepting writes. Can you fix this?
* We have this new project we're starting and we need you to set up continuous integration, deployment, write our unit tests, define an integration test strategy, tell us how to mock every call to everything. We'll need several thousand dollars in AWS resources that we've barely defined. Can you define what AWS resources we need?
* We didn't like your definition of AWS resources, so we came up with our own. We're also going to need you to rearchitect the networking to support our single typescript API.
* The VPN is down and nobody can do any work because you locked us all out of connecting directly over SSH from home. Please unblock my home IP.
* Oh, looks like my VPN password expired. How do I reset my VPN password?
* My GitHub account doesn't have access to this repo. Please make my PR for me.
* Can you tell me how to run this app's test suite?
* CI system failed a build. Why?
* App doesn't send logs to the logging platform. Please tell me why.
* How do I add logging statements to my app?
* Why would I need a logging library, can't you just understand why my app doesn't need to waste my time with logs?
From Various 3rd party vendors:
* <X> application changed their license terms. How much do you really want to pay us now?
From Management:
* <X> left the company, and he was working on these tasks that seem closely related to your work. Here are the 3 GitHub Repos you now own.
* Why is our AWS bill so high? I need you to lower our bill by tomorrow. Preferably by 10k-20k monthly. Thanks.
* Please send this month's plan for DevOps work.
* Please don't do anything on your plan.
* Here's your actual new plan for the month.
* Please also do these 10 interruptions-which-became-epic-projects
From AWS:
* Dear AWS Admin, 17 instances need to be rebooted. Please do so by tomorrow.
* Dear AWS Admin, 3 user accounts saw suspicious activity. Please confirm these were actually you.
* Dear AWS Admin, you need to relaunch every one of your instances into a new VPC within the next year.
* Dear AWS Admin, Your app was suspiciously accessing XYZ, which is a violation of our terms of service. You have 24 hours to address this before we delete your AWS account.
Finally, From Management:
* Please provide management with updates, nobody knows what you do.
From me:
Please pay me more. Please give me a team to assist so I'm not a team of one. Also, my wife is asking me to look for a new job, and she's not wrong. Just saying.3 -
The fuck? I'm trying to automate login for an asp.net website from a C# console app using HttpWebRequests. I used Fiddler to see how the login happens and how the browser obtains the session and auth cookies from the server. When I replicate the same procedure from C#, I am able to get both cookies withoth a problem, but when I try to use them to get data about the user, I get a 500 ISE. What the actual fuck? I've double-checked every single header and the URLs and it's doing literally the same thing as chrome: Get asp session id (POST)-> get an auth cookie (POST username and passwd) -> interact with the site using the session id and auth cookie (GET). And obiviously I don't have access to the server logs... :/2
-
The name of today is Murphy.
So, the LAN at location A can't reach the one at location B. Turns out that something yet unknown is blowing fuses at location A, but after disconnecting a ton of unknowns, the router and a radio link station are up again. Yay Internet, but still no VPN connection to location B.
Needing the passwords for the OpenVPN servers, I notice that encfs4win refuses to mount the drive where the password manager files reside. Of course, any problem must have the company of other problems. Eventually, the encfs drive mounts on another computer.
So, I can access the OpenVPN computer running the client side and check the logs, which tell me that network B is unreachable.
Both networks and an encfs setup all die at the same time? Right, Murphy, what are you going to come up with next? No, don't tell me because I just got read errors from a hard drive. -
"Just start ahead"
I am supposed to transform calls from one api to another one. Yet there's no documentation, ambiguous code statements, no examples of what values are contained -- but sure, let me just start assuming how the whole thing is supposed to work. That won't lead us more into a murky waters at all.
Even more frustrating: We own the api. We should be able to tell by the access logs how we are queried. Yet for some reason, access logs cannot be accessed and I shall "just work from the swagger defintion".
Well, that swagger definition is broken, its example are shit (somebody liked to use undefined in optional fields, making me wonder even more what the heck is going on here), and I have no idea of what I am doing. Fun times.3 -
Finally decided to get myself some remote server on DO, faffing around and setting things up, and suddenly I decide to look at my access logs, someone was trying to figure out how to connect to mysql, phpMyAdmin and what's not... Too bad for him I won't have any of those installed until I know how to properly secure all this :)
Heh... Welcome to the real world I guess?4 -
Just posted this in another thread, but i think you'll all like it too:
I once had a dev who was allowing his site elements to be embedded everywhere in the world (intentional) and it was vulnerable to clickjacking (not intentional). I told him to restrict frame origin and then implement a whitelist.
My man comes back a month later with this issue of someone in google sites not being able to embed the element. GOOGLE FUCKING SITES!!!!! I didnt even know that shit existed! So natually i go through all the extremely in depth and nuanced explanations first: we start looking at web traffic logs and find out that its not the google site name thats trying to access the element, but one of google's web crawler-type things. Whatever. Whitelist that url. Nothing.
Another weird thing was the way that google sites referenced the iframe was a copy of it stored in a google subsite???? Something like "googleusercontent.com" instead of the actual site we were referencing. Whatever. Whitelisted it. Nothing.
We even looked at other solutions like opening the whitelist completely for a span of time to test to see if we could get it to work without the whitelist, as the dev was convinced that the whitelist was the issue. It STILL didnt work!
Because of this development i got more frustrated because this wasnt tested beforehand, and finally asked the question: do other web template sites have this issue like squarespace or wix?
Nope. Just google sites.
We concluded its not an issue with the whitelist, but merely an issue with either google sites or the way the webapp is designed, but considering it works on LITERALLY ANYTHING ELSE i am unsure that the latter is the answer.2 -
SharePoint: Designer is discontinued but they haven't released an alternative method of creating custom workflows...
Also, SharePoint only shows correlation ids, which you'd have to check the logs to see what the error was (no description or error code for user): SharePoint Online doesn't split their logs by client... so they can't give clients access to the logs even if they wanted too. Only option is to contact their support... seems overkill when the error may be a user trying to upload a document with the same name.1 -
I'm given a simple assignment to update email templates. I tot it would be a breeze.
It turn out SURPRISE! After the updating of template is done. I deploy the code in the development environment.
I tried to access the email template like how the user will see to verify all is good. It turn out i am facing error.
So uhh ok, i went to check the logs to see what the hiccups. It turn out that a table is missing. But this is production code. So my question how the hell did the production environment has the table but dev don't.....6 -
After nearly 4 weeks, my account has finally been generated to access the VDIs for our development environment. I tried to authenticate with my smartcard and kept getting errors with very bland messages. after hours of digging through (useless) windows logs, someone told me that the certificate authority that signed my card isn't in the trust store for the VDI backend. Based on the current pace of things, I'm guessing it's going to be a while before this gets sorted out. My internship ends in 2 weeks and I haven't been able to do anything yet :/
-
Alright boys.. calling in my networking friends for help..
Recently switched my ISP and got a fibre optic installed (100Mbps).
Thr ISP provided a new TP-Link router which supports 5GHz as well as 2.4GHz.
Some of my devices support 5GHz and connect to that network which works flawlessly.
However, my phone does not support 5GHz and hence, have to connect on 2.4GHz.
Somehow, the main router as well as the access point, are not functioning well for 2.4GHz. Whenever the connection is established, it would work fine for a minute or two before the networks starts disconnecting.
Restart the device Wi-Fi and it works for few moments and the cycle repeats.
I am not sure of what is causing this issue.
For the records, the access point is an old D-Link router. Why I mention this? Because funnily whenever the access point cable is plugged into the main router and I login to the router, the system logs me into the access point router (D-Link instead of TP-Link).
Can someone please help me resolve this issue?
Fun fact: The D-Link was a giveaway by one of my dR friends @Bigus-Dickus5 -
Sooooo I came in to work yesterday and the first thing I see is that our client can't log on to the cms I set up for her a month ago. I go log in with my admin credentials and check the audit logs.
It says the last person to access it was me, the date and time exactly when we first deployed it to production.
One month ago.
I fired a calm email to our project managers (who've yet to even read the client complaint!) to check with ops if the cms production database had been touched by the ops team responsible for the sql servers. Because it was definitely not a code issue, and the audit logs never lie.
Later in the day, the audit log updated itself with additional entries - apparently someone in ops had the foresight to back up the database - but it was still missing a good couple weeks of content, meaning the backup db was not recent.
Fucking idiots. -
Is there an ios app that records my gps logs for last n day(cyclic buffer)? Privacy is also important: data shouldn’t leave my phone: no internet access.9
-
include ::rant
rant::newentry {'new-job-rant' :
ensure => latest,
location => goverment-employment-office-HQ,
job => DevOps,
content => {'
So, i've been at my new job for some time now, almost two weeks (hurray!) but boy oh boy, what a job it is!
I'm working at a goverment office charged with helping the unemployed to get a job or a new education course. I'm hored as re-enforcements for their DevOps team. I get my pay, easy transportation home<->office, coffe is adequate in quality and quantity, so no complaints there...
But the actual job is a FUCKING MENTAL CLUSTERFUCKS OF WHAT THE ACTUAL FUCK MULTIPLIED BY TEN TO THE POWER OF GOOGOL!
A few items that make my blood boil to new temperature records defying medical science:
* devs refuse to use linting, say the builder will catch it when there is an error, never look at the builder error logs
* (puppet) modules have NO TESTS
* (puppet) modules get included in several git repo's as submodules, in turn they are part of a git repo, in turn they are replicated to several puppet masters, and they differentiate the environment by bash scripts... R10K or code manager? never heard of it.
* Me cleaning up code, commit, gets accepted, some douchebag checks out code, reverts it back to the point where linting tools generate 50+ lines of warnings, complains to ME his code doesnt work! (Seriously, bitch? Serously?) , explain to that person what linting does, that persons hears the bells ring on the other end of the galaxy, refuses to use it.
* Deployment day arrives (today) -> tasks are set up on an excel sheet (on google docs) , totally out of sync with what really must be done -> something breaks, spend 30 minutes finding out who is to blame, the whole deploy train stops, find out it's a syntax error, ... waiting for person to change that since that person can only access it...
...
the list goes on and on and on. And did you expect to ahve any docs or guidelines? NO , as if docs are something for the luxurious and leisurely people having "time" to write it...
I can use another coffee... hopefully i wake up from this nightmare at my 15th cup...
},
require => [Class['::coffee'], Class['::auxiliary_brain'], Class['::brain_unfuck_tools'],],
}1 -
How the fuck does my boss setup 2FA using her name, and then forget that she setup 2FA even though she sees the fucking app send her a code every time she logs in. Now we need to get her to reset her password so we can get the information so another team member can access the information they need.1
-
Relatively often the OpenLDAP server (slapd) behaves a bit strange.
While it is little bit slow (I didn't do a benchmark but Active Directory seemed to be a bit faster but has other quirks is Windows only) with a small amount of users it's fine. slapd is the reference implementation of the LDAP protocol and I didn't expect it to be much better.
Some years ago slapd migrated to a different configuration style - instead of a configuration file and a required restart after every change made, it now uses an additional database for "live" configuration which also allows the deployment of multiple servers with the same configuration (I guess this is nice for larger setups). Many documentations online do not reflect the new configuration and so using the new configuration style requires some knowledge of LDAP itself.
It is possible to revert to the old file based method but the possibility might be removed by any future version - and restarts may take a little bit longer. So I guess, don't do that?
To access the configuration over the network (only using the command line on the server to edit the configuration is sometimes a bit... annoying) an additional internal user has to be created in the configuration database (while working on the local machine as root you are authenticated over a unix domain socket). I mean, I had to creat an administration user during the installation of the service but apparently this only for the main database...
The password in the configuration can be hashed as usual - but strangely it does only accept hashes of some passwords (a hashed version of "123456" is accepted but not hashes of different password, I mean what the...?) so I have to use a single plaintext password... (secure password hashing works for normal user and normal admin accounts).
But even worse are the default logging options: By default (atleast on Debian) the log level is set to DEBUG. Additionally if slapd detects optimization opportunities it writes them to the logs - at least once per connection, if not per query. Together with an application that did alot of connections and queries (this was not intendet and got fixed later) THIS RESULTED IN 32 GB LOG FILES IN ≤ 24 HOURS! - enough to fill up the disk and to crash other services (lessons learned: add more monitoring, monitoring, and monitoring and /var/log should be an extra partition). I mean logging optimization hints is certainly nice - it runs faster now (again, I did not do any benchmarks) - but ther verbosity was way too high.
The worst parts are the error messages: When entering a query string with a syntax errors, slapd returns the error code 80 without any additional text - the documentation reveals SO MUCH BETTER meaning: "other error", THIS IS SO HELPFULL... In the end I was able to find the reason why the input was rejected but in my experience the most error messages are little bit more precise.2 -
I spent 2-3 days on debugging code written in assembly script. Apparently, you need to initialise an array using new method otherwise it re-uses the previous array from the same scope and it has created infinitely large array. Just wtf.
And I got error like "wasm blah blah blah blah blah blah".Just give proper error.
Running the environment locally wasn't an option because well it doesn't fucking work locally. So, I have to forcibly test on CI and they have created a site that can show you logs because you can't access or query data directly from server and while debugging you try to log something it randomly works sometimes and sometimes you get output from god knows which deployment. Just create a fucking API for displaying log or build a proper docker so that we test it locally.1 -
New Project
M: Hey, check these two processes. Both took different paths for the same input. Here are the logs. Both are the same though.
Me: Ok... do we have a debugger?
M: No this product doesn't have a debugger
Me: Any unit tests i should know of?
M: We don't do unit testing. Everything is done in Integration Testing.
Me: Ok. So how can i check the db for this?
M: You can't, the access is restricted. You'll have to raise a ticket to other team with the sql output you need.
Me: Ok. So I hope you have the schema at least.
M: Yes we have the schema. But there was some issue last week so the values might not be there in the correct column. They may or may not be present where they are supposed to be.
Wtf am i supposed to do... fucking play football on ticketing system with the other team 😐 -
Hi fellow devRanters, I need some advice on how to detect web traffic coming from bad/malicious bots and block them.
I have ELK (Elastic) stack set up to capture the logs from the sites, I have already blocked the ones that are obviously bad (bad user-agent, IP addresses known for spamming etc). I know you can tell by looking at how fast/frequently they crawl the site but how would I know if I block the one that's causing the malicious and non-human traffic? I am not sure if I should block access from other countries because I think the bots are from local.
I am lost, I don't know what else I can do - I can't use rate limiting on the sites and I can't sign up for a paid service cause management wants everything with the price of peanuts.
Rant:
Someone asked why I can't just read through the logs (from several mid-large scale websites) and pick out the baddies.
*facepalm* Here's the gigabytes log files.9 -
How do I deal with this;
Edge case hiccup on production, no errors in the available logs(very shallow logging), no access to the production server, issue unreproducable on staging and a manager that want me to fix it AFTER I already said that im kind of sailing blind and can't do much without logs or access, and already looked at it with another dev who also has no idea what is going on3 -
I let my ML friend (great bloke, all the following shit giving is with love) use my chatgpt plus account so he could try gpt4, bc he thought “chatgpt” is “overhyped”. meanwhile I'm getting it to pump out 50 line pSQL trigger functions like it's a Tuesday. no flex its literally like ordering pancakes.
ana he logs in proceeds to get frustrated with it and says it's shit. somehow he managed to select gpt 3.5 instead of 4.
it took me showing him THIS USELESS example that basically has almost nothing to do with gpt 3.5->4 jump (plus get access to a sandbox, cool) for him to realize that wow maybe just maybe this ain't a major version bump
-
Any advice for debugging a 520 error from Cloudflare?
I know this isn’t SO but Ive been having the toughest time finding a decent way to find the cause of a 520 error from Cloudflare.
I have a droplet of Digital Ocean running Apache 2.4X and randomly throughout the day I will get 520 errors in the browser’s Networking log.
Naturally, there’s nothing even noted in the Apache error log or access log. And Cloudflare has no logs on this in the console.
If I retry the request it will go through with no problem.
Anyone experienced something like this?5 -
I have the following scenario with a proposed solution, can anyone please confirm it is a secure choice:
- We have critical API keys that we do not want to ship with the app because de-compiling will give access to those keys, and the request is done before the user logs in, we are dealing with guests
Solution:
- Add a Lambda function which accepts requests from the app and returns the API keys
- Lambda will accept the following:
1. Android app signing key sha1
2. iOS signing certificate sha1
- If lambda was able to validate them API keys are sent back.
My concerns:
- Can an attacker read the request from the original (non-tampered) apk and see what the actual sha1 value is on his local network?
- If the answer to the question above is yes, what is the recommended way to validate that the request received is actually from the app that we shipped and not from curl/postman/script/modified version of the app11 -
BEST CHEATING HUSBAND TRACKER
Are you looking for a way to spy on a suspected cheater? Get in touch with Web Bailiff through:
Web Bailiff Contractor
Website Webbailiffcontractor . com
Email web @ bailiffcontractor . net
WhatsApp +1 360 819 8556
From tracking social media apps to real-time GPS, Web Bailiff provides a comprehensive and easy-to-use solution for suspicious partners searching for clarity. They give you remote access to call logs, contact lists, text messages, and browser history on your spouse's cell phone or tablet.
-
CRYPTO ASSET TRACING AND RECOVERY SERVICE - DIGITAL HACK RECOVERY
WhatsApp Number +1(915)2151930
Mail; digital hack recovery @ techie . com
Website⁚ https : // digital hack recovery . com
After engaging in trading with a cryptocurrency company based in Dubai, I found myself in an unsettling situation: my assets were withheld for no apparent reason, and I was unable to access my funds. The company had initially appeared legitimate, and given Dubai's reputation as a financial hub with impressive infrastructure, it was easy to believe in their credibility. The city’s thriving economy and wealth made it seem like the perfect environment for a trustworthy business, which is why I didn’t hesitate to invest. However, when I tried to withdraw my funds and faced repeated obstacles, it quickly became clear that something was wrong.Despite reaching out to the company multiple times for clarification and assistance, I received no satisfactory response. The more I tried to resolve the issue, the more I realized that I was either being ignored or fed vague excuses. It became increasingly apparent that I might have fallen victim to a scam, or at the very least, was dealing with a company that had no intention of honoring its commitments.In my search for a solution, I discovered Digital Hack Recovery, a highly reputable recovery expert specializing in reclaiming withheld or scammed cryptocurrency. After researching their track record of success, I decided to contact them, providing all the required legal trade details, including transaction IDs and communication logs with the trading platform. Digital Hack Recovery’s team was professional and responsive, offering clear instructions on how to proceed.They explained that their expertise, legal resources, and specialized tools would be key in tracking down and recovering my funds.The recovery process was thorough and required some time, but I was kept informed every step of the way. Digital Hack Recovery coordinated with legal professionals and relevant authorities to investigate and recover my assets. Finally, after significant effort, they successfully reclaimed all my funds, allowing me to regain access to my cryptocurrency.I am incredibly grateful to Digital Hack Recovery for their diligence and expertise. Their commitment to ensuring I got my assets back was evident throughout the process. I would highly recommend their services to anyone in a similar situation, especially if you're dealing with companies that initially seem trustworthy but turn out to be far less reliable than they appear. If you’re facing withheld or lost cryptocurrency, Digital Hack Recovery offers the expertise and support you need to recover what's yours. 1
1 -
HOW TO HIRE A GENUINE CRYPTO RECOVERY SERVICE CONTACT SPARTAN TECH GROUP RETRIEVAL
All the time, I had believed in networking, but I never knew that a local crypto meetup would save me from financial disaster. Discussion at the event ranged from trading strategies to security tips, but one name cropped up repeatedly that sounded impressive: SPARTAN TECH GROUP RETRIEVAL. Many spoke about how that service had rescued them from lost wallets, forgotten passwords, and even cyber-attacks. I filed that away mentally but never thought I'd find myself in that position. That changed just weeks later. One morning, I went into my Bitcoin wallet and saw suspicious activity. My heart sank as I realized that $180,000 in crypto was on the line. Someone had access, and if I didn't act fast, I'd lose everything. Panic set in, and I scrambled to figure out how it happened: had I clicked a phishing link, was my private key compromised? No matter the cause, I needed help. And fast. That's when I remembered the crypto meetup. I scrolled through my notes and found SPARTAN TECH GROUP RETRIEVAL's name. With no time to waste, I sent a reply-my anxious and desperate words spilling into one frenetic sentence. They responded very fast and professionally. They immediately initiated an investigation into my wallet's transaction history and security logs. They were able to trace the breach and lock it, trying not to be late in recovering the stolen money. Then they worked around the clock for several days, coordinating tracking on the blockchain, forensic data recovery, and reinforcements of security. I barely slept, but at each and every stage, they kept reassuring me. Then came that call I was praying for: They had recovered my funds. Speechless. Relieved. Grateful. But SPARTAN TECH GROUP RETRIEVAL didn't just stop with the recovery, teaching me means of security practices, helped fortify the defense around my wallet, and making sure this does not happen again. I consider it one of the best I have done so far-attending that crypto meet-up. I might never have heard of SPARTAN TECH GROUP RETRIEVAL if it had not been that night, or the outcome worse. Now I do my best to spread the word. For a reason is their reputation preceding them, and personally I can vouch for their expertise, efficiency, and reliability.
SPARTAN TECH GROUP RETRIEVAL CONTACT INFO:
Email: spartantech (@) cyber services . com OR support (@) spartantechgroupretrieval. org
Website : h t t p s : / / spartantechgroupretrieval. org
WhatsApp: +1 (971) 487 - 3538
Telegram: +1 (581) 286 - 8092 6
6 -
This story starts with a call from the 1st line support that users were getting intermittent-production-only error in one of the key application my team were working on.
The problem was that the application was behind the hardened environment that we had no access to.
The only thing we could do is enable logging which in itself took a whole week to get approved. And the result the Developers favourite - NullReferenceException in one of the biggest methods, I've ever seen in my whole career. Needless to say, that was not very helpful and we were no closer to the solution.
What. A. Pain.
Frustrated with the issue and with business breathing down my neck I started slicing this Monster of a method into smaller and smaller chunks. Even if some action was just a one-liner that would not stop me to create a method. At one point I could no longer care for method names resorting to such classics like Method1, FooBar123 and DoStuff.
But. It. Worked.
After the next deployment logs were showing the same NullReferenceException but now the stack trace pointed me to some Method13.
The resulting stack trace finally allowed to pinpoint the issue. The fix then was just a simple null check.
While Dev team who did not appreciate my creative method naming it was obvious to everyone that even that was better than one big blob of code.
It might seem silly to separate the most obvious one-liners into their own methods and sometimes even whole classes but not living through that experience alone is worth it for me.
Did you ever found yourself in a situation where you wished your stack trace was just a little bit more in-depth? Tell me in the comments ^_^
So now go and look at your code and see if you can pepper it with smaller methods so that you stack traces can pave your way to your debugging success.
Originally posted on amoenus.dev/no-method-too-small-or-amoenus-dev 3
3
























































Top Tags
Weekly Rant
View