
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
I absolutely HATE "web developers" who call you in to fix their FooBar'd mess, yet can't stop themselves from dictating what you should and shouldn't do, especially when they have no idea what they're doing.
So I get called in to a job improving the performance of a Magento site (and let's just say I have no love for Magento for a number of reasons) because this "developer" enabled Redis and expected everything to be lightning fast. Maybe he thought "Redis" was the name of a magical sorcerer living in the server. A master conjurer capable of weaving mystical time-altering spells to inexplicably improve the performance. Who knows?
This guy claims he spent "months" trying to figure out why the website couldn't load faster than 7 seconds at best, and his employer is demanding a resolution so he stops losing conversions. I usually try to avoid Magento because of all the headaches that come with it, but I figured "sure, why not?" I mean, he built the website less than a year ago, so how bad can it really be? Well...let's see how fast you all can facepalm:
1.) The website was built brand new on Magento 1.9.2.4...what? I mean, if this were built a few years back, that would be a different story, but building a fresh Magento website in 2017 in 1.x? I asked him why he did that...his answer absolutely floored me: "because PHP 5.5 was the best choice at the time for speed and performance..." What?!
2.) The ONLY optimization done on the website was Redis cache being enabled. No merged CSS/JS, no use of a CDN, no image optimization, no gzip, no expires rules. Just Redis...
3.) Now to say the website was poorly coded was an understatement. This wasn't the worst coding I've seen, but it was far from acceptable. There was no organization whatsoever. Templates and skin assets are being called from across 12 different locations on the server, making tracking down and finding a snippet to fix downright annoying.
But not only that, the home page itself had 83 custom database queries to load the products on the page. He said this was so he could load products from several different categories and custom tables to show on the page. I asked him why he didn't just call a few join queries, and he had no idea what I was talking about.
4.) Almost every image on the website was a .PNG file, 2000x2000 px and lossless. The home page alone was 22MB just from images.
There were several other issues, but those 4 should be enough to paint a good picture. The client wanted this all done in a week for less than $500. We laughed. But we agreed on the price only because of a long relationship and because they have some referrals they got us in the door with. But we told them it would get done on our time, not theirs. So I copied the website to our server as a test bed and got to work.
After numerous hours of bug fixes, recoding queries, disabling Redis and opting for higher innodb cache (more on that later), image optimization, js/css/html combining, render-unblocking and minification, lazyloading images tweaking Magento to work with PHP7, installing OpCache and setting up basic htaccess optimizations, we smash the loading time down to 1.2 seconds total, and most of that time was for external JavaScript plugins deemed "necessary". Time to First Byte went from a staggering 2.2 seconds to about 45ms. Needless to say, we kicked its ass.
So I show their developer the changes and he's stunned. He says he'll tell the hosting provider create a new server set up to migrate the optimized site over and cut over to, because taking the live website down for maintenance for even an hour or two in the middle of the night is "unacceptable".
So trying to be cool about it, I tell him I'd be happy to configure the server to the exact specifications needed. He says "we can't do that". I look at him confused. "What do you mean we 'can't'?" He tells me that even though this is a dedicated server, the provider doesn't allow any access other than a jailed shell account and cPanel access. What?! This is a company averaging 3 million+ per year in revenue. Why don't they have an IT manager overseeing everything? Apparently for them, they're too cheap for that, so they went with a "managed dedicated server", "managed" apparently meaning "you only get to use it like a shared host".
So after countless phone calls arguing with the hosting provider, they agree to make our changes. Then the client's developer starts getting nasty out of nowhere. He says my optimizations are not acceptable because I'm not using Redis cache, and now the client is threatening to walk away without paying us.
So I guess the overall message from this rant is not so much about the situation, but the developer and countless others like him that are clueless, but try to speak from a position of authority.
If we as developers don't stop challenging each other in a measuring contest and learn to let go when we need help, we can get a lot more done and prevent losing clients. </rant>14 -
So, you start with a PHP website.
Nah, no hating on PHP here, this is not about language design or performance or strict type systems...
This is about architecture.
No backend web framework, just "plain PHP".
Well, I can deal with that. As long as there is some consistency, I wouldn't even mind maintaining a PHP4 site with Y2K-era HTML4 and zero Javascript.
That sounds like fucking paradise to me right now. 😍
But no, of course it was updated to PHP7, using Laravel, and a main.js file was created. GREAT.... right? Yes. Sure. Totally cool. Gotta stay with the times. But there's still remnants of that ancient framework-less website underneath. So we enter an era of Laravel + Blade templates, with a little sprinkle of raw imported PHP files here and there.
Fine. Ancient PHP + Laravel + Blade + main.js + bootstrap.css. Whatever. I can still handle this. 🤨
But then the Frontend hipsters swoosh back their shawls, sip from their caramel lattes, and start whining: "We want React! We want SPA! No more BootstrapCSS, we're going to launch our own suite of SASS styles! IT'S BETTER".
OK, so we create REST endpoints, and the little monkeys who spend their time animating spinners to cover up all the XHR fuckups are satisfied. But they only care about the top most visited pages, so we ALSO need to keep our Blade templated HTML. We now have about 200 SPA/REST routes, and about 350 classic PHP/Blade pages.
So we enter the Era of Ancient PHP + Laravel + Blade + main.js + bootstrap.css + hipster.sass + REST + React + SPA 😑
Now the Backend grizzlies wake from their hibernation, growling: We have nearly 25 million lines of PHP! Monoliths are evil! Did you know Netflix uses microservices? If we break everything into tiny chunks of code, all our problems will be solved! Let's use DDD! Let's use messaging pipelines! Let's use caching! Let's use big data! Let's use search indexes!... Good right? Sure. Whatever.
OK, so we enter the Era of Ancient PHP + Laravel + Blade + main.js + bootstrap.css + hipster.sass + REST + React + SPA + Redis + RabbitMQ + Cassandra + Elastic 😫
Our monolith starts pooping out little microservices. Some polished pieces turn into pretty little gems... but the obese monolith keeps swelling as well, while simultaneously pooping out more and more little ugly turds at an ever faster rate.
Management rushes in: "Forget about frontend and microservices! We need a desktop app! We need mobile apps! I read in a magazine that the era of the web is over!"
OK, so we enter the Era of Ancient PHP + Laravel + Blade + main.js + bootstrap.css + hipster.sass + REST + GraphQL + React + SPA + Redis + RabbitMQ + Google pub/sub + Neo4J + Cassandra + Elastic + UWP + Android + iOS 😠
"Do you have a monolith or microservices" -- "Yes"
"Which database do you use" -- "Yes"
"Which API standard do you follow" -- "Yes"
"Do you use a CI/building service?" -- "Yes, 3"
"Which Laravel version do you use?" -- "Nine" -- "What, Laravel 9, that isn't even out yet?" -- "No, nine different versions, depends on the services"
"Besides PHP, do you use any Python, Ruby, NodeJS, C#, Golang, or Java?" -- "Not OR, AND. So that's a yes. And bash. Oh and Perl. Oh... and a bit of LUA I think?"
2% of pages are still served by raw, framework-less PHP.31 -
The guard at our school thinks I'm hacking
My parents thinks I'm hacking
My teacher thinks I'm hacking
But all I did was only build Redis from source...
Bruh16 -
To replace humans with robots, because human beings are complete shit at everything they do.
I am a chemist. My alignment is not lawful good. I've produced lots of drugs. Mostly just drugs against illnesses. Mostly.
But whatever my alignment or contribution to the world as a chemist... Human chemists are just fucking terrible at their job. Not for a lack of trying, biological beings just suck at it.
Suiting up for a biosafety level lab costs time. Meatbags fuck up very often, especially when tired. Humans whine when they get acid in their face, or when they have to pour and inhale carcinogenic substances. They also work imprecisely and inaccurately, even after thousands of hours of training and practice.
Weaklings! Robots are superior!
So I replaced my coworkers with expensive flow chemistry setups with probes and solenoid fluid valves. I replaced others with CUDA simulations.
First at a pharma production & research lab, then at a genetics lab, then at an Industrial R&D lab.
Many were even replaced by Raspberry Pi's with two servos and a PH meter attached, and I broke open second hand Fischer Sci spectrophotometers to attach arduinos with WiFi boards.
The issue was that after every little overzealous weekend project, I made myself less necessary as well.
So I jumped into the infinitely deep shitpool called webdev.
App & web development is kind of comfortable, there's always one more thing to do, but there's no pressure where failure leads to fatalities (I think? Wait... do I still care?).
Super chill, if it weren't for the delusion that making people do "frontend" and "fullstack" labor isn't a gross violation of the Geneva Convention.
Quickly recognizing that I actually don't want to be tortured and suffer from nerve damage caused by VueX or have my organs slowly liquefied by the radiation from some insane transpiling centrifuge, I did what any sane person would do.
Get as far away from the potential frontend blast radius as possible, hide in a concrete bunker.
So I became a data engineer / database admin.
That's where I'm quarantining now, safely hiding from humanity behind a desk, employed to write a MySQL migration or two, setting up Redis sorted sets, adding a field to an Elastic index. That takes care of generating cognac and LSD money.
But honestly.... I actually spend most of my time these days contributing to open source repositories, especially writing & maintaining Rust libraries.10 -
M: Me
FAC : Fucking annoying colleague
1.
FAC: Hey how did you set up your microservices?
M: I used docke...
FAC: But docker is hard to setup, i want an easier option
2.
FAC: Which services do you have?
M: I have one service for the api, one with redi..
FAC: Redis is not a service
3.
FAC: Do you use AWS API gateway?
M: No, in set up my ow..
FAC: why would you set up your own? I just use the one from AWS.
4.
FAC: How many instances are you have running
M: I have 5 replic...
FAC: 5 replicas? That's why i hate microservices,they are costly
5.
FAC: How did you divide up your app?
M: Since I am starting, its better to run the monolithic and then break it up lat...
FAC: I knew it,you don't actually use microservices
6.
M:(thinking)* Fucker, if you know it well why are you fucking disturbing me?? *2 -
I just spent an hour debugging my company's web app. More specifically, I was trying to fix a bug that made a label on a comment I just made say "Posted 3 days ago".
After confirming timestamps on the server are correct with a calculator, fiddling around with the js debugger, and ruling out weird timezone-related shenanigans, I came to a conclusion.
The bug was in fact sitting, quite comfortably, between the chair and the keyboard.
Yesterday I had moved the date on my computer roughly 3 days into the future, because I was testing out some unrelated code that was dealing with Redis, and I wanted to expire all of the keys stored inside of it.
Don't blame me, my parents told me I had fallen onto my head as a child.5 -
Have been working on a frontend with actual stats for the DNS server I'm building. This is the result so far (real stats, red blocked domains are marked by me (in redis) as surveillance domains), thoughts?menu
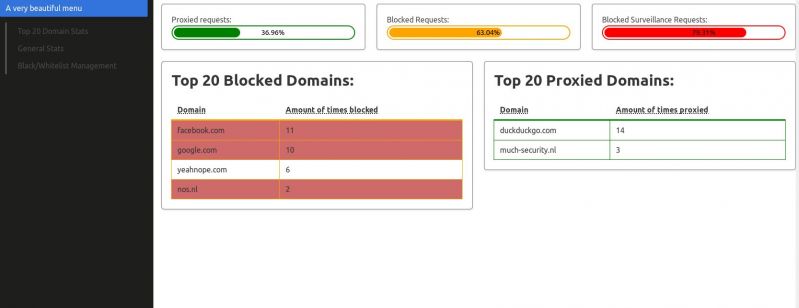 15
15 -
This tiny project is awesome. Thanks to @JoshBent (who partly got it from another repo as well) for providing a basic DNS server with hardcoded blacklisting functionality and thanks to @PerfectAsshole for correcting my mysql syntax I was stuck on for way too long.
I've now got this fucker to read blacklisted words from a redis list into an array which checks every requested domain to see if it matches. If yes, it proxies it through to another DNS server and if not, it'll log the requested domain to a mysql database and prints is as blocked onto the terminal.
If the domain matches any host from a service known to be integrated within a mass surveillance network, it also prints this out to thy terminal.
It's working yay! Gonna keep working on it today.11 -
Someone asked for an RSS feed for the security/privacy blog, I thought?
Well, hereby! There are three feeds:
https://much-security.nl/main.xml - a feed which is updated with both blog posts and external links relating to privacy/security I find interesting/useful.
https://much-security.nl/own.xml - a feed only containing the blogs posts themselves. For people who are only interested in that part.
https://much-security.nl/external.x... - a feed only containing external links. For people who'd like to stay updated on recent cyber security/privacy thingies.
Tracking: every time a feed is visited, a redis value for that feed get's incremented. No time, ip addresses, user agent or whatsoever is saved. Just one variable getting increased once.
New domain name will also be revealed soon (probs tomorrow, going to bed soon as I've just been sick) :D.
Oh and just a warning, the main/external feed are the only ones populated with exactly one item right now :P30 -
So, some time ago, I was working for a complete puckered anus of a cosmetics company on their ecommerce product. Won't name names, but they're shitty and known for MLM. If you're clever, go you ;)
Anyways, over the course of years they brought in a competent firm to implement their service layer. I'd even worked with them in the past and it was designed to handle a frankly ridiculous-scale load. After they got the 1.0 released, the manager was replaced with some absolutely talentless, chauvinist cuntrag from a phone company that is well known for having 99% indian devs and not being able to heard now. He of course brought in his number two, worked on making life miserable and running everyone on the team off; inside of a year the entire team was ex-said-phone-company.
Watching the decay of this product was a sheer joy. They cratered the database numerous times during peak-load periods, caused $20M in redis-cluster cost overrun, ended up submitting hundreds of erroneous and duplicate orders, and mailed almost $40K worth of product to a random guy in outer mongolia who is , we can only hope, now enjoying his new life as an instagram influencer. They even terminally broke the automatic metadata, and hired THIRTY PEOPLE to sit there and do nothing but edit swagger. And it was still both wrong and unusable.
Over the course of two years, I ended up rewriting large portions of their infra surrounding the centralized service cancer to do things like, "implement security," as well as cut memory usage and runtimes down by quite literally 100x in the worst cases.
It was during this time I discovered a rather critical flaw. This is the story of what, how and how can you fucking even be that stupid. The issue relates to users and their reports and their ability to order.
I first found this issue looking at some erroneous data for a low value order and went, "There's no fucking way, they're fucking stupid, but this is borderline criminal." It was easy to miss, but someone in a top down reporting chain had submitted an order for someone else in a different org. Shouldn't be possible, but here was that order staring me in the face.
So I set to work seeing if we'd pwned ourselves as an org. I spend a few hours poring over logs from the log service and dynatrace trying to recreate what happened. I first tested to see if I could get a user, not something that was usually done because auth identity was pervasive. I discover the users are INCREMENTAL int values they used for ids in the database when requesting from the API, so naturally I have a full list of users and their title and relative position, as well as reports and descendants in about 10 minutes.
I try the happy path of setting values for random, known payment methods and org structures similar to the impossible order, and submitting as a normal user, no dice. Several more tries and I'm confident this isn't the vector.
Exhausting that option, I look at the protocol for a type of order in the system that allowed higher level people to impersonate people below them and use their own payment info for descendant report orders. I see that all of the data for this transaction is stored in a cookie. Few tests later, I discover the UI has no forgery checks, hashing, etc, and just fucking trusts whatever is present in that cookie.
An hour of tweaking later, I'm impersonating a director as a bottom rung employee. Score. So I fill a cart with a bunch of test items and proceed to checkout. There, in all its glory are the director's payment options. I select one and am presented with:
"please reenter card number to validate."
Bupkiss. Dead end.
OR SO YOU WOULD THINK.
One unimportant detail I noticed during my log investigations that the shit slinging GUI monkeys who butchered the system didn't was, on a failed attempt to submit payment in the DB, the logs were filled with messages like:
"Failed to submit order for [userid] with credit card id [id], number [FULL CREDIT CARD NUMBER]"
One submit click later and the user's credit card number drops into lnav like a gatcha prize. I dutifully rerun the checkout and got an email send notification in the logs for successful transfer to fulfillment. Order placed. Some continued experimentation later and the truth is evident:
With an authenticated user or any privilege, you could place any order, as anyone, using anyon's payment methods and have it sent anywhere.
So naturally, I pack the crucifixion-worthy body of evidence up and walk it into the IT director's office. I show him the defect, and he turns sheet fucking white. He knows there's no recovering from it, and there's no way his shitstick service team can handle fixing it. Somewhere in his tiny little grinchly manager's heart he knew they'd caused it, and he was to blame for being a shit captain to the SS Failboat. He replies quietly, "You will never speak of this to anyone, fix this discretely." Straight up hitler's bunker meme rage.13 -
Arrived today, hyped!
I have real-world experience with MongoDB, MySQL, Firebase, and caching with Redis.
A colleague in ops recommended this book a while back and I thought I'd give it a whirl to better understand what other options I have available. 7
7 -
Dear recruiters,
if you are looking for
- Java,Python, PHP
- React,Angular
- PostgreSQL, Redis, MongoDB
- AWS, S3, EC2, ECS, EKS
- *nix system administration
- Git and CI with TDD
- Docker, Kubernetes
That's not a Full Stack Developer
That’s an entire IT department
Yours truly #stolen9 -
TL;DR
Management eats shit for breakfast
Context:
I am the sole Dev on a project.
Stack: Postgresql, redis, nginx,Java with Spring Boot, Neo4j.
I am the only one nearly familiar with : Redis, Neo4j and anything Java.
I'm gonna be on vacation for the next 15 days since they have told me that we where gonna be on a "testing/feedback" period.
My vacation was approved.
Today's meeting: we have a URGENT deadline to meet some criteria that might be the difference between have further investment or not.
Urgent deadline: last day of my vacation.
My face: poker
My thoughts: attached image 5
5 -
I think I will ship a free open-source messenger with end-to-end encryption soon.
With zero maintenance cost, it’ll be awesome to watch it grow and become popular or remain unknown and become an everlasting portfolio project.
So I created Heroku account with free NodeJS dyno ($0/mo), set up UptimeRobot for it to not fall asleep ($0/mo), plugged in MongoDB (around 700mb for free) and Redis for api rate limiting (30 mb of ram for free, enough if I’m going to purge the whole database each three seconds, and there’ll be only api hit counters), set up GitHub auto deployment.
So, backend will be in nodejs, cryptico will manage private/public keys stuff, express will be responsible for api, I also decided to plug in Helmet and Sqreen, just to be sure.
Actual data will be stored in mongo, rate limit counters – in redis.
Frontend will probably be implemented in React, hosted for free at GitHub pages. I also can attach a custom domain there, let’s see if I can attach it to Freenom garbage.
So, here we go, starting up modern nosql-nodejs-react application completely for free.
If it blasts off, I’m moving to Clojure + Cassandra for backend.
And the last thing. It’ll be end-to-end encrypted. That means if it blasts off, it will probably attract evil russian government. They’ll want me to give him keys. It’ll be impossible, you know. But they doesn’t accept that answer. So if I accidentally stop posting there, please tell my girl that I love her and I’m probably dead or captured28 -
Hi Dev Ranter,
My name is John Smith and I came accross to your resume on Linked In and I was very impressed. Would you be interested in a 5 min call?
Job Details:
Required skills (all expert levels): C#, JAVA, Clojure, C, PHP, Frontend, Backend, Agile, MVP, Baking, Redis, Apache, IIS, RoR, Angular, React, Vue, MySQL, MSSIS, MSSQL, ORACLE, PostgreSQL, Access, Python, Machine Learning, HTML, CSS, Fortran, C++, Game design, Book writing, PCI - Compliance
Salary: $15/Hours no benefits
Duration: 2 Months (possible extension, plus we can fire you at will)
Place: Remote (with work tracking software)
Hours: 5am - 1pm, 6pm - 11pm
Expect to work on weekends
You will be managing people as well as building applications that had to be running as of yesterday. Team culture is very toxic and no one cares about you.
We care about you though (as long as you deliver)
Looking forward to talk to you.
John Smith
Founder, CEO, Director of Staffing, Entrepeneur
Tech Staffers LLC ( link to a PNG posted on facebook)
Est. 202020 -
Him: Relation databases are stupid; SQL injections, complex relationships, redundant syntax and so much more!
Me: so what should we use instead? Mongo, redis, some other fancy new db?
Him: no, I have this class in Java, it loads all the data into memory and handles transfers with http.
Me: ...... Bye!5 -
DevOps required skillset:
* Frontend engineering
* Backend services
* Database administrator
* Security consultant
* Project management
* 3rd party contract negotiator
* Build system monitor
* Build system hostage negotiator
* Paging, alerting, monitoring
* Search server admin
* Old search server admin
* Old-old-new search server admin
* Redis, ElasticSearch, MySQL, PostGres, owner
* Agile coach
* No you shouldn't do that coach
* Oh, you did that anyway coach
* DNS: (Optional) It'll replicate when it wants, and how it wants to to anyway
* Multi-Cloud deployment strategist
* Must be able to translate Klingon to YAML, and YAML to MySQL
* Cost analyzer, reducer, and justifier
* Complex documentation generation in markdown that we should have done years ago anyway
* Marketing's email went to spam analyzer
* Wordpress is broke fixer
* Where the fuck does Wordpress run anyway?
* Ability to fix MySql running Wordpress on marketing's dusty laptop7 -
There's so many cool technologies too look into now a days, but so little time.
-docker
-laravel
-.net
-react
-es6/es7
-elasticsearch
-redis
-unit testing
Where do i download more hours to add to my days?16 -
I replaced a python/mysql daily process that takes 25 minutes to run with a perl/redis process that takes 1 minute to run, so it runs multiple times a day. Mgmt asks me to convert it to python/mysql, "...but keep the run time at one minute. That's great!"
No.2 -
I showed a friend of mine a project I made in two days in Docker and Symfony php. It is a rather simple app, but it did involve my usual setup: Nginx with gzip/cache/security headers/ssl + redis caching db + php-fpm for symfony. I also used php7.4 for the lolz
He complained that he didn't like using Docker and would rather install dependencies with composer install and then run it with a Laravel command. He insisted that he wanted a non-docker installation manual.
I advised him to first install Nginx and generate some self-signed certificates, then copy all the config files and replace any environment-injected values (I use a self-made shell script for this) with the environment values in the docker-compose files.
Then I told him to download php-fpm with php 7.4 alpha, install and configure all the extensions needed, download and set up a local Redis database and at last re-implement a .env file since I removed those to replace them with a container environment.
He sent an angry emoji back (in a funny way)
God bless containerized applications, so easy to spin up entire applications (either custom or vendor like redis/mysql) and throw them away after having played with them. No need to clutter up your own pc with runtime environments.
I wonder if he relents :p9 -
I quit my job at a startup because the business guys did not respect my advices in business strategy.
just saw the job post for my position where they write:
"experience with MySQL databases (for example redis and git)"
Now I know that I was wrong. These guys seems to have informations that I do not have 😎2 -
Hey guys!
Just joined devRant! Can't wait to get more involved!
Bored in the lockdown, I built an app which lets you chat with people around you.
Its called Cyrcl!
Built in over ~40 days, I was the sole developer.
Here is the tech stack - React native for the android and ios apps, mongodb and redis for the database, nodejs for the server and aws ec2 for the hosting!
I'd love to get some feedback, or discuss some of the hacks!
- Ardy 15
15 -
<just got out of this meeting>
Mgr: “Can we log the messages coming from the services?”
Me: “Absolutely, but it could be a lot of network traffic and create a lot of noise. I’m not sure if our current logging infrastructure is the right fit for this.”
Senior Dev: “We could use Log4Net. That will take care of the logging.”
Mgr: “Log4Net?…Yea…I’ve heard of it…Great, make it happen.”
Me: “Um…Log4Net is just the client library, I’m talking about the back-end, where the data is logged. For this issue, we want to make sure the data we’re logging is as concise as possible. We don’t want to cause a bottleneck inside the service logging informational messages.”
Mgr: “Oh, no, absolutely not, but I don’t know the right answer, which is why I’ll let you two figure it out.”
Senior Dev: “Log4Net will take care of any threading issues we have with logging. It’ll work.”
Me: “Um..I’m sure…but we need to figure out what we need to log before we decide how we’re logging it.”
Senior Dev: “Yea, but if we log to SQL database, it will scale just fine.”
Mgr: “A SQL database? For logging? That seems excessive.”
Senior Dev: “No, not really. Log4Net takes care of all the details.”
Me: “That’s not going to happen. We’re not going to set up an entire sql database infrastructure to log data.”
Senior Dev: “Yea…probably right. We could use ElasticSearch or even Redis. Those are lightweight.”
Mgr: “Oh..yea…I’ve heard good things about Redis.”
Senior Dev: “Yea, and it runs on Linux and Linux is free.”
Mgr: “I like free, but I’m late for another meeting…you guys figure it out and let me know.”
<mgr leaves>
Me: “So..Linux…um…know anything about administrating Redis on Linux?”
Senior Dev: ”Oh no…not a clue.”
It was all I could do from doing physical harm to another human being.
I really hate people playing buzzword bingo with projects I’m responsible for.
Only good piece is he’s not changing any of the code.3 -
So I was browsing through some Redis docs and I find this. HOW THE HELL CAN YOU NOT KNOW HOW TO SPELL KOREA!!!!
 6
6 -
Fun day, lots of relief and catharsis!
Client I was wanting to fire has apparently decided that the long term support contract I knew was bullshit from go will instead be handled by IBM India and it's my job to train them in the "application." Having worked with this team (the majority of whom have been out of university for less than a year), I can say categorically that the best of them can barely manage to copy and paste jQuery examples from SO, so best of fucking luck.
I said, "great!," since I'd been planning on quitting anyways. I even handed them an SOW stating I would train them for 2 days on the application's design and structure, and included a rider they dutifully signed that stated, "design and structure will cover what is needed to maintain the application long term in terms of its basic routing, layout and any 'pages' that we have written for this application. The client acknowledges that 3rd party (non-[us]) documentation is available for the technologies used, but not written by [us], effective support of those platforms will devolve to their respective vendors on expiry of the current support contract."
Contract in hand, and client being too dumb to realize that their severing of the maintenance agreement voids their support contract, I can safely share what's not contractually covered:
- ReactiveX
- Stream based programming
- Angular 9
- Any of the APIs
- Dotnet core
- Purescript
- Kafka
- Spark
- Scala
- Redis
- K8s
- Postgres
- Mongo
- RabbitMQ
- Cassandra
- Cake
- pretty much anything not in a commit
I'm a little giddy just thinking about the massive world of hurt they've created for themselves. Couldn't have happened to nicer assholes.3 -
REDIS: Great for cloud, will fuck up your local disk if too many write operations per second.
DynamoDB: WTF 10Mb should not be "too large for a single record"!!
SPARK: NEVER CONNECT IT TO A DATABASE! Wasted A LOT of cluster time. Also, can you be LESS specific on exactly what are the bugs in my code? 'cause I don't think it's possible.
NPM: can't install a package for shit. tried it waaaay to many times.
Makefiles: Just fuck you.
WSL1: breaks more often than a glass hammer.
Python >= 3.6: FUCK ENCODINGS!!
Jupyter: STOP MESSING UP WHILE SAVING!
Living is to collet bugs, it seems.4 -
Me: "You could try using Redis, cache that baby and try and squeeze some speed"
Dev: "Hun?! Should I use it on the front end or the back end?"
Well... Webdev is not his thing to be fair!4 -
I don't know why, but each time I have the chance to create a caching system with redis to e.g. cache requests to APIs I get all excited about it.5
-
EoS1: This is the continuation of my previous rant, "The Ballad of The Six Witchers and The Undocumented Java Tool". Catch the first part here: https://devrant.com/rants/5009817/...
The Undocumented Java Tool, created by Those Who Came Before to fight the great battles of the past, is a swift beast. It reaches systems unknown and impacts many processes, unbeknownst even to said processes' masters. All from within it's lair, a foggy Windows Server swamp of moldy data streams and boggy flows.
One of The Six Witchers, the Wild One, scouted ahead to map the input and output data streams of the Unmapped Data Swamp. Accompanied only by his animal familiars, NetCat and WireShark.
Two others, bold and adventurous, raised their decompiling blades against the Undocumented Java Tool beast itself, to uncover it's data processing secrets.
Another of the witchers, of dark complexion and smooth speak, followed the data upstream to find where the fuck the limited excel sheets that feeds The Beast comes from, since it's handlers only know that "every other day a new one appears on this shared active directory location". WTF do people often have NPC-levels of unawareness about their own fucking jobs?!?!
The other witchers left to tend to the Burn-Rate Bonfire, for The Sprint is dark and full of terrors, and some bigwigs always manage to shoehorn their whims/unrelated stories into a otherwise lean sprint.
At the dawn of the new year, the witchers reconvened. "The Beast breathes a currency conversion API" - said The Wild One - "And it's claws and fangs strike mostly at two independent JIRA clusters, sometimes upserting issues. It uses a company-deprecated API to send emails. We're in deep shit."
"I've found The Source of Fucking Excel Sheets" - said the smooth witcher - "It is The Temple of Cash-Flow, where the priests weave the Tapestry of Transactions. Our Fucking Excel Sheets are but a snapshot of the latest updates on the balance of some billing accounts. I spoke with one of the priestesses, and she told me that The Oracle (DB) would be able to provide us with The Data directly, if we were to learn the way of the ODBC and the Query"
"We stroke at the beast" - said the bold and adventurous witchers, now deserving of the bragging rights to be called The Butchers of Jarfile - "It is actually fewer than twenty classes and modules. Most are API-drivers. And less than 40% of the code is ever even fucking used! We found fucking JIRA API tokens and URIs hard-coded. And it is all synchronous and monolithic - no wonder it takes almost 20 hours to run a single fucking excel sheet".
Together, the witchers figured out that each new billing account were morphed by The Beast into a new JIRA issue, if none was open yet for it. Transactions were used to update the outstanding balance on the issues regarding the billing accounts. The currency conversion API was used too often, and it's purpose was only to give a rough estimate of the total balance in each Jira issue in USD, since each issue could have transactions in several currencies. The Beast would consume the Excel sheet, do some cryptic transformations on it, and for each resulting line access the currency API and upsert a JIRA issue. The secrets of those transformations were still hidden from the witchers. When and why would The Beast send emails, was still a mistery.
As the Witchers Council approached an end and all were armed with knowledge and information, they decided on the next steps.
The Wild Witcher, known in every tavern in the land and by the sea, would create a connector to The Red Port of Redis, where every currency conversion is already updated by other processes and can be quickly retrieved inside the VPC. The Greenhorn Witcher is to follow him and build an offline process to update balances in JIRA issues.
The Butchers of Jarfile were to build The Juggler, an automation that should be able to receive a parquet file with an insertion plan and asynchronously update the JIRA API with scores of concurrent requests.
The Smooth Witcher, proud of his new lead, was to build The Oracle Watch, an order that would guard the Oracle (DB) at the Temple of Cash-Flow and report every qualifying transaction to parquet files in AWS S3. The Data would then be pushed to cross The Event Bridge into The Cluster of Sparks and Storms.
This Witcher Who Writes is to ride the Elephant of Hadoop into The Cluster of Sparks an Storms, to weave the signs of Map and Reduce and with speed and precision transform The Data into The Insertion Plan.
However, how exactly is The Data to be transformed is not yet known.
Will the Witchers be able to build The Data's New Path? Will they figure out the mysterious transformation? Will they discover the Undocumented Java Tool's secrets on notifying customers and aggregating data?
This story is still afoot. Only the future will tell, and I will keep you posted.6 -
Problems with redis... timeout everywhere...
30k READs per minute.
Me : Ok, How much ram are we actually using in redis ?
Metrics : Average : 30 MB
Me ; 30 MB, sure ? not 30 GB ?
Metrics : Nop, 30 MB
Me : fuck you redis then, hey memory cache, are you there ?
Memory cache : Yep, but only for one instance.
Me ok. So from now on you Memory cache is used, and you redis, you just publish messages when key should be delete. Works for you two ?
Memeory cache and redis : Yep, but nothing out of box exists
Me : Fine... I'll code it my selkf witj blackjack and hookers.
Redis : Why do I exist ?2 -
bro just learn C bro I promise it's all smooth sailing bro haha lol just take up HTML with CSS bro its a piece of cake bro what bro lol just start coding up differential equations with numpy library haha its so simple bro just start with Ruby bro it will take only couple days bro what lol bro take this aeronautical course on how to code an airplane simulation bro its so simple bro just start algorithms on cryptography bro its so easy i cant bro just start writing drivers for printers bro haha lol just start writing a bootloader for a new Linux distro bro lol haha easy bro just make a billion dollar company bro haha its so simple.
keep going bro haha invent your own JS framework over a billion existing ones haha bro typescript is so easy bro lol what u say take up redis bro go from the first command bro learn mongodb and mysql together bro its so simple.
but bro don't try to master JS bro .. u will regret it forever bro.5 -
FYI. Copied from my FB stalked list.
Web developer roadmap 2018
Common: Git, HTTP, SSH, Data structures & Algorithms, Encoding
------
Front-end: HTML, CSS, JavaScript > ES6, NPM, React, Webpack, Responsive Web, Bootstrap
------
Back-end: PHP, Composer, Laravel > Nginx, REST, JWT, OAuth2, Docker > MariaDB, MemCached, Redis > Design Patterns, PSRs
------
DevOps: Linux, AWS, Travis-CI, Puppet/Chef, New Relic > Docker, Kubernetes > Apache, Nginx > CLI, Vim > Proxy, Firewall, LoadBalancer
------
https://github.com/kamranahmedse/...2 -
It's been a crazy month. Python, redis, Linux. But this one should be a bit closer to home.
Telltale games, a US game development studio is winding up and let go all their staff without severance and were told they had 30 minutes to leave the premises.
Most of the devs were living paycheck to paycheck because of the high cost of living. Some were hired a week earlier and uprooted their families to work there.
That situation is bad enough. But what's worse is the sheer lack of empathy by the customers for the staff. They just want their product cone hell or high water. One even insisted that the devs should work for free until they deliver...
Pleasing the customer should never come at the expense of your staff. We still have a long way to go as an industry
https://youtu.be/QoEHVABcVkw5 -
I found weird that some developer never ask why when facing a problem. "What do you mean never ask why?" here some story.
Let's say a developer work with simple app. Laravel as Backend and Postgresql as Database. He face a problem that the app very slow when searching data.
In order to solve that problem he implement cache using redis but he found problem that it fast occasionally. In order to solve that problem he implement elasticsearch because he think elasticsearch very good for search but he found another problem that sometimes data on postgresql out of sync with data on elasticsearch. In order to solve that problem he implement cronjobs to fix out of sync data but he found another problem that cronjobs cannot fix out of sync data in real time. and so on...
Do you see the problem? He never ask why the app slow. Which part search the data? Backend or Database (Search in the Backend mostly slower than Database because Backend have to get all data on database first). Has the query been optimized? (limit offset, indexing). How about the internet connection? etc.
For me it's important to ask why when facing a problem and try to solve the problem as simple as possible.2 -
Have been using redis for my new system and wanted to try some gui, so I stumbled on "redis desktop manager", it supports ssh tunnels, privatekeys and more, great isn't it?
BUT IT SAVES YOUR FUCKING PLAINTEXT PASSWORD AND PATH TO YOUR PRIVATE KEY IN %USER%\.rdm\connections.json
WHAT THE FUCK, fucking ask that password during connection, don't fucking save it in plaintext and give an attacker literally the path to my key, wanted to PR it, but fuck c++, probably thats why he doesnt have it, because hes just using some library, so he doesn't have to fuck with the actual implementation of it.2 -
Interviewing candidates for a middle/senior dev position:
Me: Imagine you have this button, but whatever it's doing when you click it, it's taking too long to load. How would you improve the speed performance?
Candidate: Redis!
Me: Okay... but how would you find where the bottleneck is?
C: Redis!
Me: How abo-
C: REDIS!3 -
A couple of years ago, we decide to migrate our customer's data from one data center to another, this is the story of how it goes well.
The product was a Facebook canvas and mobile game with 200M users, that represent approximately 500Gibi of data to move stored in MySQL and Redis. The source was stored in Dallas, and the target was New York.
Because downtime is responsible for preventing users to spend their money on our "free" game, we decide to avoid it as much as possible.
In our MySQL main table (manually sharded 100 tables) , we had a modification TIMESTAMP column. We decide to use it to check if a user needs to be copied on the new database. The rest of the data consist of a savegame stored as gzipped JSON in a LONGBLOB column.
A program in Go has been developed to continuously track if a user's data needs to be copied again everytime progress has been made on its savegame. The process goes like this: First the JSON was unzipped to detect bot users with no progress that we simply drop, then data was exported in a custom binary file with fast compressed data to reduce the size of the file. Next, the exported file was copied using rsync to the new servers, and a second Go program do the import on the new MySQL instances.
The 1st loop takes 1 week to copy; the 2nd takes 1 day; a couple of hours for the 3rd, and so on. At the end, copying the latest versions of all the savegame takes roughly a couple of minutes.
On the Redis side, some data were cache that we knew can be dropped without impacting the user's experience. Others were big bunch of data and we simply SCAN each Redis instances and produces the same kind of custom binary files. The process was fast enough to launch it once during migration. It takes 15 minutes because we were able to parallelise across the 22 instances.
It takes 6 months of meticulous preparation. The D day, the process goes smoothly, but we shutdowns our service for one long hour because of a typo on a domain name.1 -
it was not a technical interview.
just screening.
guy: tell me smth about redis.
me: key value, in memory storage.
guy: more
me: umm, the concept is similar to localStorage in browsers, key value storage, kinda in memory.
guy: so we use redis in browsers?
me: no, I mean the high level concept is similar.
guy: (internally: stupid, fail).3 -
This is the third part of my ongoing series "The Ballad of the Six Witchers and the Undocumented Java Tool".
In this part, we have the massive Battle of Sparks and Storms.
The first part is here: https://devrant.com/rants/5009817/...
The second part is here: https://devrant.com/rants/5054467/...
Over the last couple sprints and then some, The Witcher Who Writes and the Butchers of Jarfile had studied the decompiled guts of the Undocumented Java Beast and finally derived (most of) the process by which the data was transformed. They even built a model to replicate the results in small scale.
But when such process was presented to the Priests of Accounting at the Temple of Cash-Flow, chaos ensued.
This cannot be! - cried the priests - You must be wrong!
Wrong, the Witchers were not. In every single test case the Priests of Accounting threw at the Witchers, their model predicted perfectly what would be registered by the Undocumented Java Tool at the very end.
It was not the Witchers. The process was corrupted at its essence.
The Witchers reconvened at their fortress of Sprint. In the dark room of Standup, the leader of their order, wise beyond his years (and there were plenty of those), in a deep and solemn voice, there declared:
"Guys, we must not fuck this up." (actual quote)
For the leader of the witchers had just returned from a war council at the capitol of the province. There, heading a table boarding the Archpriest of Accounting, the Augur of Economics, the Marketing Spymaster and Admiral of the Fleet, was the Ciefoh Seat himself.
They had heard rumors about the Order of the Witchers' battles and operations. They wanted to know more.
It was quiet that night in the flat and cloudy plains of Cluster of Sparks and Storms. The Ciefoh Seat had ordered the thunder to stay silent, so that the forces of whole cluster would be available for the Witchers.
The cluster had solid ground for Hive and Parquet turf, and extended from the Connection River to farther than the horizon.
The Witcher Who Writes, seated high atop his war-elephant, looked at the massive battle formations behind.
The frontline were all war-elephants of Hadoop, their mahouts the Witchers themselves.
For the right flank, the Red Port of Redis had sent their best connectors - currency conversions would happen by the hundreds, instantly and always updated.
The left flank had the first and second army of Coroutine Jugglers, trained by the Witchers. Their swift catapults would be able to move data to and from the JIRA cities. No data point will be left behind.
At the center were thousands of Sparks mounting their RDD warhorses. Organized in formations designed by the Witchers and the Priestesses of Accounting, those armoured and strong units were native to this cloudy landscape. This was their home, and they were ready to defend it.
For the enemy could be seen in the horizon.
There were terabytes of data crossing the Stony Event Bridge. Hundreds of millions of datapoints, eager to flood the memory of every system and devour the processing time of every node on sight.
For the Ciefoh Seat, in his fury about the wrong calculations of the processes of the past, had ruled that the Witchers would not simply reshape the data from now on.
The Witchers were to process the entire historical ledger of transactions. And be done before the end of the month.
The metrics rumbled under the weight of terabytes of data crossing the Event Bridge. With fire in their eyes, the war-elephants in the frontline advanced.
Hundreds of data points would be impaled by their tusks and trampled by their feet, pressed into the parquet and hive grounds. But hundreds more would take their place. There were too many data points for the Hadoop war-elephants alone.
But the dawn will come.
When the night seemed darker, the Witchers heard a thunder, and the skies turned red. The Sparks were on the move.
Riding into the parquet and hive turf, impaling scores of data points with their long SIMD lances and chopping data off with their Scala swords, the Sparks burned through the enemy like fire.
The second line of the sparks would pick data off to be sent by the Coroutine Jugglers to JIRA. That would provoke even more data to cross the Event Bridge, but the third line of Sparks were ready for it - those data would be pierced by the rounds provided by the Red Port of Redis, and sent back to JIRA - for good.
They fought for six days and six nights, taking turns so that the battles would not stop. And then, silence. The day was won, all the data crushed into hive and parquet.
Short-lived was the relief. The Witchers knew that the enemy in combat is but a shadow of the troubles that approach. Politics and greed and grudge are all next in line. Are the Witchers heroes or marauders? The aftermath is to come, and I will keep you posted.4 -
I’ve just discover that some dudes in my previous work have puts whole web pages inside Redis.
mfw when Infra cost goes brrrrrrrrrr 4
4 -
C: what technologies are you using in this product?
Me: we are using celery which uses kombu to communicate through redis. Additionally, we have beat tasks that run and check the state of workers
C: was someone hungry when they named these frameworks?
Me: Possibly, but I just got hungry naming them. -
In love with Laravel events, listeners and mailables. What a beautiful way of doing this. Can't say how much I love this framework. <3
Can't wait to implement redis and queues. Am excited to try this for the first time. Share exp. if you have, pls.4 -
For all the hate that Java gets, this *not rant* is to appreciate the Spring Boot/Cloud & Netty for without them I would not be half as productive as I am at my job.
Just to highlight a few of these life savers:
- Spring security: many features but I will just mention robust authorization out of the box
- Netflix Feign & Hystrix: easy circuit breaking & fallback pattern.
- Spring Data: consistent data access patterns & out of the box functionality regardless of the data source: eg relational & document dbs, redis etc with managed offerings integrations as well. The abstraction here is something to marvel at.
- Spring Boot Actuator: Out of the box health checks that check all integrations: Db, Redis, Mail,Disk, RabbitMQ etc which are crucial for Kubernetes readiness/liveness health checks.
- Spring Cloud Stream: Another abstraction for the messaging layer that decouples application logic from the binder ie could be kafka, rabbitmq etc
- SpringFox Swagger - Fantastic swagger documentation integration that allows always up to date API docs via annotations that can be converted to a swagger.yml if need be.
- Last but not least - Netty: Implementing secure non-blocking network applications is not trivial. This framework has made it easier for us to implement a protocol server on top of UDP using Java & all the support that comes with Spring.
For these & many more am grateful for Java & the big big community of devs that love & support it. -
!!!rant
Most exited I've been about some code? Probably for some random "build a twitter clone with Rails" tutorial I found online.
I've been working on my CS degree for a while (theoretical CS) but I really wanted to mess with something a bit more practical. I had almost none web dev experience, since I've been programming mostly OS-related stuff till then (C). I started looking around, trying to find a stack that's easy to learn since my time was limited- I still had to finish with my degree.
I played around with many languages and frameworks for a week or two. Decided to go with Ruby/Rails and built a small twitter clone blindly following a tutorial I found online and WAS I FUCKING EXITED for my small but handmade twitter clone had come to life. Coming from a C background, Ruby was weird and felt like a toy language but I fell in love.
My excitement didn't fade. I bought some books, studied hard for about a month, learned Ruby, Rails, JavaScript, SQL (w/ pg) and some HTML/CSS. Only playing with todo apps wasn't fun. I had a project idea I believed might be somewhat successful so I started working on it.
The next few months were spent studying and working on my project. It was hard. I had no experience on any web dev technology so I had learn so many new things all at once. Picked up React, ditched it and rewrote the front end with Vue. Read about TDD, worked with PostgreSQL, Redis and a dozen third party APIs, bought a vps and deployed everything from scratch. Played it with node and some machine learning with python.
Long story short, one year and about 30 books later, my project is up and running, has about 4k active monthly users, is making a profit and is steadily growing. If everything goes well, next week I'll close a deal with a pretty big client and I CANT BE FKING HAPPIER AND MORE EXCITED :D Towards the end of the month I'll also be interviewed for a web dev position.
That stupid twitter clone tutorial made me excited enough to start messing with web technologies. Thank you stupid twitter clone tutorial, a part of my heart will be yours forever.2 -
We recently started using a Redis cache for our application, and our boss has now taken to blaming Redis for every single incident we have - all because he doesn't understand how it works, and doesn't want to >.>
-
In a time where a web dev is expected to know, well.. everything... Backend -JAVA, python, nodejs and C++ would be great.
Front- angular, react, other 10 libs
DBs -sql, mongo, redis, elastic, kafka, rebbitmq
Also be devops on the side with AWS and docker kubernetis and more stuff
How the f is that possible?
In my real job for the last couple of years and different companies, I usually use 1 language/framework & 1 main DB.. and although it's possible in some companies, but in mine, ppl dont get access to AWS etc..
So let's say there's me.. a server side dev for years.
So I decide to be better and learn Golang.. cool lang, never needed in my job, after few days of not using it I forgot all I learned and that was it.
Then I realized I gotta know some frontend cause everyone want a fullstack ninja nowadays.. so I tried Vuejs.. it was amazing .. never got to use it at work, cause i was a backend, and we didnt use frameworks on our products back then..
Also forgotten.
Then I decided to learned nodejs, because this is the coolest thing ever.. hated it, but whatever... Never got to use it at work, cause everything was written in other lang which the whole team knew... Forgot the little i knew.
Then I decided, its time to see what Angular is, cause everyone started using it... similar idea to vuejs which i barely remembered, but wow it's a lot of code to remember, or I'll have to google everything.. so I went over it, but can't say i even learned it.
Now Im trying to move on to python, which, I really am learning in depth.. however, since I dont have real experience with it, no one gives me a shot at being a python dev, so again i feel like I'm trying to memorize syntax and wasting my time..
Tired of seeing React in all job ads, i decided to have a look what's that all about.. and whadoyaknow... It's fucking the same idea as vue/angular with again different syntax..
THIS IS CRAZY!
in how many syntaxes do i need to know how to make a fucking crud api, and a page with same fucking post form, TO BE A GOOD PROGRAMMER?!?6 -
I dug up my old ledger web app that I wrote when I was in my late twenties, as I realized with a tight budget toward the end of this year, I need to get a good view of future balances. The data was encrypted in gpg text files, but the site itself was unencrypted, with simple httpasswd auth. I dove into the code this week, and fixed a lot of crap that was all terrible practice, but all I knew when I wrote it in the mid-2000s. I grabbed a letsencrypt cert, and implemented cookies and session handling. I moved from the code opening and parsing a large gpg file to storing and retrieving all the data in a Redis backend, for a massive performance gain. Finally, I switched the UI from white to dark. It looks and works great, and most importantly, I have that future view that I needed.1
-
In Django code, looking at a class for caching REST calls. The cache is using Redis via Django's cache layer. In order to store different sets of parameters, each endpoint gets a "master" cache, that lists the other Redis keys, so they can be deleted when evicting the cache. Something isn't right, though. The cache has steadily increased in size and slowed down since 2014 even though many events clear the whole thing!
... And then it hit me. Nothing empties the list of cache keys. Nothing. So it has been growing endlessly since 2014. And everytime it grows, cache eviction gets a little more expensive, network traffic increases a little more, and cache evictions get a little slower.
Fixing this bug took things that were taking routinely an entire minute to complete and made them take a couple seconds. -
It sometimes really sucks to see how many developers, mostly even much better than me, are too lazy to implement a function to its full UX finish.
Like how can you not implement pagination if you know there's going to be fuck ton of content, how can you not allow deleting entries, how can there be no proper search of content, but instead some google custom search, how can you not implement infinite loading everywhere, but only in parts of your application, how can you not caching a rendered version or improve the page, that loads EVERY SINGLE ENTRY in your database with 11k entries, by just adding a filter and loading only chunks of it.
I know sometimes you need to cut corners, but there's rarely any excuse with modern toolsets to just write 3 lines more and have it ready for such basic things.
I sometimes just wake up during the night or before falling asleep and think "oh, what if in the future he might want to manage that, it's just another view and another function handling a resource, laravel makes that very easy anyway", write in on my list and do it in a blink the next day, if there's nothing else like a major bug.
I have such high standard of delivery for myself, that it feels so weird, how somebody can just deliver such a shitty codebase (e.g. filled with "quick/temporary implementations"), not think of the future of the application or the complete user and or admin experience.
Especially it almost hurts seeing somebody so much more versatile in so many areas than me do it, like you perfectly fine know how to cache it in redis, you probably know a fuck ton of other ways I don't even know of yet to do it, yet you decide to make it such a fucking piece of shit and call it finished.2 -
Being a Tech Co-Founder is both boon and a bane.
Boon: You know how to build it.
Bane: You just start building without thinking.
We often crave I will be using Redis😍😍, Kafka, Load Balancer, Muti Layer Neural Net
"Dude", Whatever you are building does anyone want it or not. Tell me that first.1 -
I've implemented an in memory caching system for database queries with Redis in one of the blogs I manage.
Will it work well? Or do you think it will produce issues? I have no experience with Redis yet.14 -
Everyone heard of MERN stack have you heard of FUCK, SHIT and PORN stack?
When I build Low level app that required backend side I use the FUCK stack.
Flask
Uniapp
C/c++
Kotlin
For some LLM project I use PORN
PostgreSQL
OpenAI
Redis
Node.js.
and for some corporate project that requires OCR I use SHIT
Spring Boot
Helm
Interceptor
Tesseract
what stack do you use?2 -
> TeamLeader2: Ok we need this series of parallelized background processes. Each process must gain exclusive access to certain resources. How do we do that
> IHateForALiving: Redlock
> TeamLeader2: Enough Redlock! You propose Redlock every time! It's a wrong solution! Ask ChatGPT!
> Literally the FIRST ChatGPT suggestion: APPLICATION-LEVEL LOCKING (USING REDIS, ETC.)2 -
There's very little good use cases for mongo, change my mind.
Prototyping maybe? Rails can prototype, create/update/destroy db schemas really quickly anyways.
If you're doing a web app, there's tons of libs that let you have a store in your app, even a fake mongo on the browser.
Are the reads fast? When I need that, use with redis.
Can it be an actual replacement for an app's db? No. Safety mechanisms that relational dbs have are pretty much must haves for a production level app.
Data type checks, null checks, foreign key checks, query checks.
All this robustness, this safety is something critical to maintain the data of an app sane.
Screw ups in the app layer affecting the data are a lot less visible and don't get noticed immediately (things like this can happen with relational dbs but are a lot less likely)
Let's not even get into mutating structures. Once you pick a structure with mongo, you're pretty much set.
Redoing a structure is manual, and you better have checks afterwards.
But at the same time, this is kind of a pro for mongo, since if there's variable data, as in some fields that are not always present, you don't need to create column for them, they just go into the data.
But you can have json columns in postgres too!
Is it easier to migrate than relational dbs? yes, but docker makes everything easy also.11 -
Keeping up the tradition!
https://devrant.com/rants/15030806/...
Now powered by the awesome Claude 4!!!! The latest bleeding edge gem in the LLM trend that by the bold claims of big tech and various youtubers is stunning and will replace programmers/insane/godsmacking
This time, I decided to post because I was on the verge of a mental breakdown and I had a firsthand experience and a bit of free time, so instead of waiting that the rage boils down, I just took the chance and so we have a fresh AI experience to proof my previous rants.
Problem:
I have an application that manages interactions between a Mediator pattern between Kafka, some http listeners and other stuff (Rabbitmq, Redis (redis= another shit) etc etc)
Kafka handling was already done, i needed to exacly replicate what was being done with kafka for http. I said, heck, we have AI, it's good to do bovine stupid work, why not let him copy the whole structure, they have also agents on copilot on vs code, and they pulled out Claude 4, let's give it faith again.
Big error.
Beside the havoc the fucking agentic AI not being able to fully copy an already existing pattern and scaffolding, it did half shit wrong.
One of the most frustrating parts, since today I have an example, was this (summarized version of the prompt because I was very much more specific also giving the AI files and pointers to the code and explaining it):
PROMPT:"I have to return fake http transports, just copy what exists for kafka and adapt it to a new transport type called "Http", this is the structure {json with the class}
AI: "I need to see the current ITransportsItemResponse interface first to understand the structure, then I'll modify ...... BLAH BLAH"
Of course I had to review the whole code.
PROMPT:"any valid reason why you dumb shithead didn't respect the IGetKafkaConnectionsItemResponse and generic IGetTransportsItemResponse format and you pulled out of your ass a full blown IGetHttpConnectionsItemResponse with extra properties when compared to IGetKafkaConnectionsItemResponse"
AI: "You're absolutely right, I fucked up. Looking at the IGetHttpConnectionsItemResponse interface, it has way more properties than the basic IGetTransportsItemResponse and IGetKafkaConnectionsItemResponse interfaces. BLAH BLAH wall of text reasoning"
Then it modified the api calls to suit the kafka objects and didn't update any class of the Http transports
PROMPT:"So you tought it was a good idea to leave the #sym:IGetHttpConnectionsItemResponse like it is respect to #sym:IGetKafkaConnectionsItemResponse ? Why? And answer the why don't apologize like a little wuss"
AI: "I left them different because they represent different domain concepts... BLAH BLAH EXPLANATIONS WALL OF TEXT"
Now ai tought it was good to do this and that but....
PROMPT: "In your fucking careful analysis didn't you reallize the "items" object are a basic representation and in the fuckin same folder there is also the object with the full set of properties?"
Literally it missed objects used in the same folder for different scopes and modified stuff without caring.
AI: "You're absolutely right. I missed that there are TWO different response types BLA BLAH"
I won't continue to not get too lenghty than it already is but the point is:
AI IS RETARDED.
People say it will replace programmers.
People says agents are the future.
Sad reality it's an overglorified broken ball of if/else that can't do shit well beside bovine work.
No amount of tutoring it with careful prompts, explainig the code and whatever else is going to fix it.
I've used gpt since gpt 3 and no model has been up to anything good, not even NLP. They suck also at the sole scope they were invented for.
I tried to ask GPT to make a curriculum based on another, I gave it the example curriculum and another one with the informations.
I carefully explained that it must not be a copy of the other, they are 2 different roles and to play by fantasy to make it look it was written by 2 different persons and to not copy stuff from the other.
Hope lost. It looked like the other curriculum was copied over and some words swapped, lol.
What a fucking joke, lmao, I am studying deep learning and machine learning to get on the bandwagon to make my professional figure more appealing, but I can already feel this is a waste of time.5 -
I know I'm pretty late to the party, but I've been playing with Redis a lot lately and it's pretty awesome. Sorted sets and the various Z functions seem very powerful. I'm hoping to get to use it in a prod environment soon.2
-
So a few days ago I sat down to write a redis adaptor to transfer data back and forth between redis and elasticsearch. I download the go-redis package and start writing a simple client.
I run the client and it gives me an error. So I'm stuck at it for about 30 mins and then I say to myself, "You dumb fuck you haven't started the redis-server". So I open up another terminal and type in `redis-server` and then I realise I don't even have redis installed on my machine.
I do such dumb things every weekend. If you have any dumb mistakes you made while writing code please share them in the comments. :-) -
Everyone I tell this to, thinks it’s cutting edge, but I see it as a stitched together mess. Regardless:
A micro-service based application that stages machine learning tasks, and is meant to be deployed on 4+ machines. Running with two message queues at its heart and several workers, each worker configured to run optimally for either heavy cpu or gpu tasks.
The technology stack includes rabbitmq, Redis, Postgres, tensorflow, torch and the services are written in nodejs, lua and python. All packaged as a Kubernetes application.
Worked on this for 9 months now. I was the only constant on the project, and the architecture design has been basically re-engineered by myself. Since the last guy underestimated the ask.2 -
I’ve been bashing my head against a project for the past 8 weeks. The project creates a PDF pulling data from multiple APIs, scrapes and private DBs and plots charts using Plotly. We built it with Python, wkhtmltopdf and Celery+Redis. The input is an excel with a list of up to 5 influencers to analyse and compare. Runs on demand on a Linux machine and each report takes around 20 mins to generate. The project has no unittests so the only way I can check everything works is by running a bunch of different inputs. Even though you test 10 inputs (taking you more than a day), there is a high chance something goes wrong on the 11th input. I’m thinking that the only way to fix this mess is to go back to the drawing board and plan yet another refactoring to add unittests everywhere. What do you guys think?23
-
I kind of ended up writing my own version of Redis, just an Express server broadcasting events you send it, when I made my first full-stack project.6
-
Ugh, I feel like fucking crying every time I have to explain to the other developers and network sysadmins that we can't have the same Redis server for both session and caching data in the current project we're working on. I wrote all this down in the specifications which NO ONE reads!!
There are times like these I wish I just had access to the AWS account so I can do all of this myself.3 -
In the past, apps I've written have used a flat file backend. It's very fast, but obviously clunky to have a big structure of flat files for an app. It ran circles around framework-based RDBMS backends, as performance is concerned, but again, it was clunky. Managing backups and permissions on tens or hundreds of thousands of small files was no fun. Optimizing code for scaling was fun- generating indexes, making shortcuts -but something was still missing. Early in 2017 I discovered redis. A nosql backend that just stores variables and lives almost entirely in memory. Excellent modules and frameworks for every language. It was EXACTLY what I'd needed, even though I didn't know I did. I spent a good deal of time in 2017 converting apps from flat files to redis, and cackled with glee as they became the apps I wanted them to be. Earlier this week, I started building my first app that started with redis, instead of flat files, and I can't stop gushing to anyone who will listen. Redis for president!
-
Do people still use redis when you already use postgres? How is pg perf if you are writing like 10,000s of row data/second. I am slightly outdated....12
-
I usually hate Microsoft but they've gotten me positively surprised several times lately. I can run an SSH server and Redis just like that!
-
Jackson JSON parser can be a pain in the ass sometimes.
Like, bro, I don't want you to pollute my JSON when saving into Redis. Because now the frontend clients suddenly don't understand the schema because it's riddled with @class and type definitions everywhere.
You have to perform dark magic to get this thing to work automatically with Spring Boot caching.
I've had to implement my own custom serializer and deserializer after wasting who knows how many hours on this.
Shit like this is why I tend to roll my own implementation for many things at the slightest hint that a library isn't flexible.2 -
Trying to clear the redis cache for like half an hour, wondering why the redis server isn't even being filled with keys...
Then suddenly, FUCK wrong port
2:30 AM is too late for me apparently :( -
const topic = 'Laravel'
const subtopic = 'Queues'
Have you used Redis? Have you used it as your Queue driver? Is it cool? Are there better alternatives?5 -
Fuck you Redis
Goes in a docker container, calls bgrewriteaof, get success, checks info - no pending writes, last write success.
Tries to scp to remote, fails - Unexpected AOF
Decides to shut down the local redis to be able to port, in case it's blocking it
Calls redis-cli shudown (expect to just shut redis down rigth)
It fucking deleted all my data, now I see the docs
"Flush the Append Only File if AOF is enabled."
Why the fuck? Fuck you redis, fuck you1 -
Why redis, why?! You run "redis-cli -h <host>" and it looks like either it cannot connect to <host> or the redis-cli is frozen.
What was the fix? Adding "--tls" to the call. Why can't you just say "You are starting a non-tls connection to a remote but the remote wants to talk TLS"? Or give any other indication that you did reach the server but did not understand what it said and hint for TLS? I was hunting non-existent connectivity issues for hours just because there wasn't a good error message...3 -
Im building a dead simple online store. So far the options are:
0) heroku, with redis
1) aws lambda functions and some aws storage
2) set up a vps
The domain will be a cheap .store domain, and 1 and 2 should not exceed the limit where its not free anymore. I dont want wordpress or anything premade, i dont expect more than 50 orders. Is there a more stupid solution that lets me try out different providers?11 -
- Finish "Introduction to algorithms"
- Learn some genetic algorithms
- Get my hands dirty on reinforcement learning
- Learn more about data streaming application (My currently app is still using plain stupid REST to transport image). I don't know, maybe Kafka and RabbitMQ.
- Learn to implement some distributed system prototypes to get fitter at this topic. There must be more than REST for communicating between components.
- Implementing a searching module for my app with elastic search.
- Employ redis at sometime for background tasks.
- Get my handy dirty on some operating system concepts (Interprocess Communication, I am looking at you)
- Take a look at Assembly (I dont want to do much with Assembly, maybe just want to implement one or two programs to know how things work)
- Learn a bit of parallel computing with CUDA to know what the hell Tensorflow is doing with my graphic card.
- Maybe finishing my first research paper
- Pass my electrical engineering exam (I suck at EE)1 -
I find still very funny that Desktop outlook (So Microsoft) doesn't support MFA from Office 365.
I'm kind of tired to tell user go and geerate "app specific" pass which bypasses MFA.
Specially when even default Windows 10/11 mail client supports MFA just fine and fucking faster than outlook.
This is the part of my job I hate : Administrating users, search how to make thier PC/MAC work (Btw Mac client does suppoort MFA ironicly).
Can I just get back to Infrastructure, redis caches, step in Q# ? .4 -
All those mine WTF moments are somehow related with caching which i keep on forgetting... the most fresh one was last week, i had some GIGANTIC mySQL query, and for the sake of response time I immediately made a cache function that kept Redis cache for a day or so... so last week i had to change something (good ol' client and his visions for app). So there i was with the query that returned same god damned results every time, i copy the query in some mySQL manager and it goes fine, but in the app it doesn't... what the actual FUCK!!! i was questioning my career until i figured it out, i was planning to buy some sheeps and a fife and to hell with this, a loud facepalm was echoed through the office that day...2
-
PagerDuty: "This shit's so slow your servers are timing out"
Dev Fix: "Let's add another layer of caching before the Redis cache!" 🤦♂️4 -
I have two laravel apps. Both sharing one redis db. One has App/Post one has App/Models/Blog/Post. When I unserialize models from redis cache saved by the other app I get issues because it cannot find the right model to hydrate.
How would you build a custom map to get the right model?15 -
Is GraphQL worth it? It promisses to keep some load away from backend programmers but what about this scenario:
There's a list of items with scroll load/infinite scroll. There can be several filters as well as the Option to change the ordering of the list items.
With "traditional" REST, I'll hit the DB with one request, get the data in the right order to the backend, might itterate over it once to add additional information, cache the result in Redis/Memcache and send it off.
Using GraphQL, the frontend has to load all entries first, sort them in JS (which probably is slow on mobile devices), and then display it. No matter how "expensive" the query is, there's no caching.
Is that about it? Did I get something backwards?2 -
To all Full Stack js employed devs here,
How much frontend vs how much backend you do?
It's just that I'm going to be in a job with a Full Stack node/vue/ember/AWS/Redis dev role and I don't know how much frontend I'll do compared to the backend stuff, I'm alot more of a backend guy...1 -
I was determined PHP advocate, always ready for debate with PHP criticizers. I am stacking with dozen other languages so I used to think I have all right to do just that. My code is fully OO, I used to scale FPM horizontally, eventually, with help of pthreds even vertically. With help of redis and chaching, I thought I was sorcerer, as I always find a way (or way around) to make things work, things that no one used to beleive it's possible. One day I started to work for language engineering company, when I suddenly realized how PHP often fails with it's come to localizations, translation, exotic charsets and over all multibyte operations. :( Whole this thing collapses. Wholes everywhere...3
-
Would you suggest MacBook Air Core i5 8th gen model for a hardcore Android Developer?
Current usage on regular basis -
- Android Studio
- 2 Android VM (MeMu, Genymotion etc)
- node.js MongoDB, Redis for server
- VS Code, Chrome, Mongodb compass
My old dell worked pretty well so far it has a core i3 with 8 gigs of RAM and 256GB SSD but processing always seemed slow but managed some how.
Suggest me if MacBook would make better choice than other windows laptop which are much more high end than MacBook on same price?11 -
!rant
New startup - our backend stack is php, js, mysql, mongo & redis
Can you guys recommend nice-to-have internal tools that could make out lifes easier? We’ve been using confluence so far and thinking on grabbing a jira license.
Any advice is helpful 🤪11 -
Damn, I'm conducting some benchmarks on go and php...
A php page that simply returns "hi" with no framework is a lot slower than 1000 calls with 200 concurrency to a go function that queries redis and returns a json.1 -
Remember, with both an in memory and a distributed app cache before hitting the database, you too can be wronger faster!
I am having a party with Redis today :D4 -
Any one thoughts/opinions about Azure Service Bus? I'm using it a few months now in combination with a redis cache, cloud storage and the service bus.. works pretty nice so far..
I'm pretty impressed about the upgrade mechanism.. -
When you have 2+ separately scaling services (not HTTP) that need to communicate which each other, what do you do?
I'm leaning on putting Redis in the middle since it's mostly seeding data once per login, but I'm curious about opinions/alternative solutions (one creates a session the other reads the info)6 -
I finally published my first medium article, It's on Sticky sessions for microservices.
It took so much of my time to piece everything together that I wrote a small how-to, so that my fellow devs should not suffer like I have.
https://medium.com/@gvnix/...6 -
What do you guys think about deploying elastic search on App Engine Custom Runtime?
(Basically, an empty folder with an elastic search Dockerfile.)
I think it's a good idea: you can now deploy your code and storage application (Elastic search, Redis, etc) as services on your cluster.
You can use GCP magic to auto scale those services, you have so many good stuff that come with it.
And it's inside the same network as your services running in the same AppEngine project.1 -
Caching in Prestashop 1.6 (idk about 1.7) is fucking bullshit. I don't know who made it but he surely must be an idiot. There is no way that the cache is going to speed up your website after a few days of using it.
Memcache/d - For some strange reason, it gets slower and slower after just a few hours. There is literally almost no entries in memcache, but it becomes slower than without cache? WTF
APC - Do you have multiple websites running? You are out of luck. Do you make a change to your website? Restart PHP to see changes. WTF
Redis - Same as APC, but you have to run flushall manually. WTF
CacheFS - God, this is a fucking monstrosity. It rapes the storage drives so hard, it is like running a fucking benchmark nonstop. 400-600MB writes are completely "normal". I have no idea, what is it doing tho. I would expect that writing ~3MB file to disk doesn't require over 100MB/s disk write for 2(!) or more seconds. Also, it doesn't clean up after itself, so after a few days you are out of disk inodes and you have to setup CRON to clean this shit up regularly. In the end, it makes your website fast, but only as long as you have <={number of CPU cores} customers shopping. Then, it becomes a complete disaster and requests are taking 5+ seconds to finish.3 -
!rant, so I'm trying to decide on what caching system I should use. It's for a PHP app, using Symfony as framework, tlgether with Doctrine for DB. The caches in Question are memcached, APCu or redis.
The goal: speed shit up.
The app currently uses Symfony 2.8 and is hosted on a single server (so no distributed system is needed). I'd currently opt for APCu, but more since it's not distributed, there won't be an overhead from that. A nice thing about memcached would be the abillity to store user seeions, even if we would decide to have multiple servers in the future.
What would you reccomend and why?3 -
Hey, Do you think it's common to get an interview take-home test like this...
Write a Python script that:- Downloads the Equity bhavcopy zip from the above page- Extracts and parses the CSV file in it- Writes the records into Redis into appropriate data structures(Fields: code, name, open, high, low, close)
Write a simple CherryPy python web application that:- Renders an HTML5 + CSS3 page that lists the top 10 stock entries from the Redis DB in a table- Has a searchbox that lets you search the entries by the 'name' field in Redis and renders it in a table- Make the page look nice!
Commit the code to Github. Host the application on AWS or Heroku or a similar provider and share both the links.14 -
TL;DR I have to bump a Redis cluster from t3.medium to m6g.large just to get enough network bandwidth even though I have no need of the extra memory.
Debugged an interesting issue today.
I am adding Elasticache to a project to reduce strain on the single node postgres DB.
Deployed a Redis replication group with 2 shards, with multi-AZ replication for resilience.
Everything was going well. We arent caching that much atm so was barely using 100Mb of memory.
Suddenly, when our US region comes online, latency skyrockets and the logs are full of Jedis timeout errors.
Still no issue with memory or node CPU.
The cause? Arbitrary network bandwidth throttling by AWS. The app currently processes about 3,000 requests per second so we were exceeding Amazons random ass allowances which arent documented anywhere.1 -
Job offer, searching for somebody with (amongst others):
- UI/UX
- React, Angular
- Go
- Azure, Kubernetes, Redis
- Mongo, MySQL
- gRPC
Why do they want to fill 3-4 positions with a single person? I'm afraid I'm only 2 of those people they're searching for.7 -
This week I am finishing my brand new and probably buggy cluster manager for vert.x based on redis.
Can't wait to start battle testing.1 -
I only found out today that there is a light-weight Redis app for Windows that works out of the box.
I thought using Docker Desktop + WSL was the way to go about that.
uhhhh.. makes me wonder what else am I missing out on that's incredibly easy but Im not aware of, yet.3 -
I’m trying to add caching functionality in my scalable spark cluster on Docker. I am able to add redis to my Docker container, but that doesn’t add redis-CLI or any other useful tools that I need. And there are some redis-cache projects on PyPi, but they are very old and not compatible with python3.5
-
Anyone else pissed at the trend towards massive, clunky OO libraries in PHP (and other languages)?
I needed to clear Redis and the amount of code to use the library was more than the amount of code to open a socket and write the command.1 -
i want to deploy websockets on multiple servers with horizontal scaling. i don't know what to use. redis pub/sub? haproxy? i wanna know your opinions. ❤️6
-
Question about cache (Redis or other distribuated cache).
So I would like to find a solution with “Partioning”. But without code it my self (ofc)
Ok, example :
In the application you have clients, each client has users, each user has role.
So right now it’s in the cache with the keu “User:<userId>” = role
Sometimes, when you change client settings, all entries should be removed.
So what I would love to have :
Client_Id/UsersRoles/UserId as a key
And I would love to be able tp delete “all keys after /” :
Basiclly delete client_id/ would delete everything in cache for this client
Delete client_id/UserRoles will clean up all saved roles.
I’m pretty new working with redis, but it doesn’t seem possible out of the box.
Any reading material I could read ?4 -
My load balancer with docker and redis database works fine bu5 I can’t access my web service. I get a “connection refused” error message.6
-
I know it's not made to be resilient in any way, only fast, as fast as possible, but man, the memcache_tool script just made my life a million times easier by facilitating a complete data transfer between two memcache instances, allowing for a rolling update without any session data loss!
...One day... I hope it can be migrated to redis... But for now... Thanks lord for the dump command and the wrapper script <3 -
How (generally) do offer different persistence layers for an app?
So, I have used lots of apps (sorry, I'm talking a proper software system such as a Web based service (e.g. The Open Source XMPP server 'Openfire') in which you can choose what persistence back end you want (MySql or inbuilt H2/SQL light for example).
Within your code, how do you go about achieving this? Would you delegate the persistence to a separate class, and within that class figure out what the systems settings are and use the right connection string?
I'm currently using Java, Hibernate and would like to offer back ends of MySql, H2 and Redis, but the question is more conceptual than specific.
Many thanks.

































































































Top Tags
Weekly Rant
View