
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
click click...
*reload*
_________________
| |
| This will be wra|
| |
|_________________|
hm.....
ah...
*hits ctrl+s*
*smiling*
*reloads*
_________________
| |
| This will be wra|
| |
|_________________|
what the f..
..
..
hm....
hm....
aha
ctrl+alt+t
*confidentiality*
sudo sublime /opt/htdocs/learning_css/wrapping_text.html
********
o.O but my code ....it's here.....but why wasn't it showing....
*just to be safe*
ctrl+s
*reload*
_________________
| |
| This will be wra|
| |
|_________________|
meh..... what was I thinking
*wastes time restarting xampp*
*searches CSS everywhere*
*steals working code*
*eyes red as hell*
*it's 3 am*
*after 1hr*
*accidentally reloads*
_________________
| |
| This will be |
| wrapped |
|_________________|
o.O
*blinking in confusion*
what the .... how did it work....
I changed nothing.....
*realises* 19
19 -
Client: "This feature doesn't work! I thought you said it was done?!"
Me: "Please press CTRL+F5 and try again..."
Client: "Okay, great, works now."
A conversation I seem to have on a very regular basis.8 -
Project manager: I thought you said you made sure it was live today! I'm going to have to explain that you're the main issue with why it isn't live to management!
Me: have you cleared your cache?.... (long silence)
I swear it's the new "have you tried turning it off and then on again".2 -
That moment when you've been trying to fix a bug for hours then suddenly realize you've fixed it hours ago but just didn't clear the cache
 5
5 -
There's not much worse than trying to fix your CSS for half an hour, only to realise that it's a cache issue...9
-
I befriended a much-older dev who's notoriously known for cursing in source code comments.
His best comment was F.I.S.H., which is his cursing acronym for "fucking incredible shitty hack"6 -
Today I asked my client to do "ctrl+f5" to empty browser cache he literally did "ctrl+f+5" and said "it did nothing"6
-
I saw a commit with suspicious code days ago. After warning my immediate superior he ignored me and yesterday proceeded to deploy.
Now we have items in cache for days instead of minutes. I guess next time he will listen to me.4 -
Sometimes we say the customers they have to clear their browser cache but actually we are fixing the bugs they just found while talking with them on the phone.5
-
Holy donkey nuts, I get too scared to leaved unpushed code when I take a coffee break.
https://webcache.googleusercontent.com/... 18
18 -
There are two hard problems in computer science: naming things, cache invalidation and off-by-1 errors4
-
My boss in our northern office literally told my colleague that he'd been refreshing the site several times every few minutes and could clearly see that we hadn't done shit.
Keep in mind that we are heavily cached with Varnish and Drupal Cache on our server, and this guy is never at the office. He was seeing our website from 3 days ago because his browser was retrieving local cache from the last time he was actually there and it was during a time where we had some broken items on the site.
The part that pisses me off most is that not only did he not know to purge his browser cache to see changes, but he thought my coworker was making up hocus-pocus technobabble to "cover for me" by telling him how to clear his cache.
This guy installed AirMail, 8 times on his Mac because he was entering SMTP settings that were literally given to him in screenshots with every step illustrated and every field of configuration available for reference, incorrectly. So yeah I can see how he would be technically capable of micro managing me. Fuck.2 -
Fucking cache in browser made me think that code is still working untill I opened it in incognito.6
-
Ok, some @#$#!!@ at my company set the WordPress cache directory to "/" on a Linux server, some other plugin triggered the cache clear and the Apache user was the owner of almost all the WordPress directories of several MU installations, this all happened on a Friday afternoon.2
-
Known IPs for github (add to /etc/hosts)
192.30.253.113 github.com
192.30.253.113 ssh.github.com
more on https://webcache.googleusercontent.com/...9 -
Relying on Chrome to remember all my passwords. I have no idea any more what passwords I have chosen for several important sites. Don't even want to think about what happens the day I switch PC or reset that cache somehow.10
-
Google chrome
Plz come on
Just take the whole c drive for ur cache and stuff...
Dont take my whole ram11 -
My damn 50 GB mobile broadband got used up because I did not realise that instead of using a local video for testing my website, I had set the video src to a HD version of Big Buck Bunny and disabled the fucking browser cache!6
-
I recently interviewed for a job at company where I had 20 minutes to code a solution in python (whose standard library I know nothing about) to a question, which also included googling certain finance-related APIs, with not one but two technical interviewers looking over my shoulder THE ENTIRE TIME.9
-
When you change something in the webdesign, the user doesn't see it after refresh and you have to explain 'cache' 😐7
-
Clearing the cache.
Tried clearing cms cache
Tried restarting iis
Tried browsing incognito
Tried deleting browser cache...
WHY U STILL SHOW OLD CSS?!?!22 -
Me: *tries to debug JS code for 5434910946th time on colleagues computer*
Me soon after realising: clears cache
Both of us: look down in sorrow5 -
The answer to all your computer issues (now including the caching issues on websites): Restart your computer
 5
5 -
The IT head of my Client's company : You need to explain me what exactly you are doing in the backend and how the IOT devices are connected to the server. And the security protocol too.
Me : But it's already there in the design documents.
IT Head : I know, but I need more details as I need to give a presentation.
Me : (That's the point! You want me to be your teacher!) Okay. I will try.
IT Head : You have to.
Me : (Fuck you) Well, there are four separate servers - cache, db, socket and web. Each of the servers can be configured in a distributed way. You can put some load balancers and connect multiple servers of the same type to a particular load balancer. The database and cache servers need to replicated. The socket and http servers will subscribe to the cache server's updates. The IOT devices will be connected to the socket server via SSL and will publish the updates to a particular topic. The socket server will update the cache server and the http servers which are subscribed to that channel will receive the update notification. Then http server will forward the data to the web portals via web socket. The websockets will also work on SSL to provide security. The cache server also updates the database after a fixed interval.
This is how it works.
IT Head : Can you please give the presentation?
Me : (Fuck you asshole! Now die thinking about this architecture) Nope. I am really busy.11 -
Just got chewed out because someone couldn't see the latest interface changes on the site...
*Walked over to their desk*
Me: "Did you clear your browser's cache?"
Them: "Oh, what does my online banking have to do with the updates?"
Me: *sigh* 😬😬5 -
!rant
Me: sudo apt-get update
PC: Noope. There is a problem with a package.
Me: Ugh... ok I'll fix it. *20 minutes later* Fixed. Sudo apt-get update
PC: Noope, the package cache file is corrupted.
Me: GO FUCK YOURSELF LINUX OMFG.
Oh, I fixed it.
I LOVE YOU LINUX.11 -
Dev deploys new CSS.
Client: I can't see the changes PANIC.
Dev: clear your cache!
Client: oh that's better. Now can we do that for all user?
Dev:😱4 -
That moment when you clean the cache on android phone with 4GB every time you want to download a new app, even if you have 32GB sdcard
😱😱😱4 -
First time web developing for real. Didn't realise I needed to clear chrome cache. So much wasted time!4
-
I hate setting up case statements cause it's hard to cover every case. What if a virus puts a gun to my programs head? What if my program is at a cache party and chrome offers it weed? What if my program isn't gay, but $20 is $20?2
-
Today,I found this gem:
static function getConfig(){
$cacheKey = 'foobar';
try {
$config = $this->repository->getConfig();
$this->cache->set($cacheKey, $config);
}
catch(Exception $e){
try{
$config = $this->repository->getConfig();
$this->cache->set($cacheKey, $config);
}
catch(Exception $e){}
}
}
I don't want to live on this planet anymore...!7 -
When you trying to develop a site, you change some CSS, refresh the localhost and it doesn't update. You try changing that CSS value to something more noticeable to see if you're just imagining things. But no, it's your browser cache. Clear it.2
-
Every time someone compares Golang to Rust an angel falls, a unicorn dies and a Java developer writes another class.
Please stop doing that.7 -
Called yourself a what? "Chief Technology Officer / Senior Dev" ? For a simple clear cache and cannot do that on your own, you giraffe? Only if I have not pitied you AND YOUR FUCKING EGO, I already sent you a Fucking Love Resignation Letter, you dickhead! You should be ashamed of yourself!!5
-
>Installs NodeJS (from default Debian repo)
>Tries to install yarn
>Yarn tries to uninstall nodejs
Weird
>apt-cache depends yarn
yarn
Recommends: nodejs
Conflicts: nodejs
10/10, gave me a good chuckle. Time to add the NodeJS repo.10 -
There are two hard things in computer science: cache invalidation, naming things, and off-by-one errors.
This is really the stuff I have to deal on daily basis. -
Me, being a lowly junior dev, had the honor of being in a same group chat with a big corporation devOps team.
Finally ready to play with the big boys!!
*opens chat*
DevOps 1: "so we need to remove the CSS cache from our clients computers."
DevOps 2: "ok, well... just delete the server cache"
*watching in awe as they all try to figure out why it's not working*
This continued on for a while...
Until my boss had enough laughs and giggles and put an end to this stupidity :D1 -
Long but hilarious:
I was deeply concerned about how we have a single, non-paginated call to a backend service, returning hundreds of entries, which has to be enriched with constant data fetched from our db for each entry. FOR EACH ENTRY. AND FOR EACH REQUEST.
I voiced my concerns to my PM, who called me a "rage prophet" for it.
As expected, the call took 20-something seconds to complete.
Ten minutes before the CEO comes over to have a look, another dev changes his loosely-related service, and the entire super-heavy, sprawling abyss of enrichment pipeline returns in sub-second timing!!!
CEO: guys, this is too fast. You have to slow it down a bit. It doesn't seem reliable that we're able to get all this data immediately.
PM: you see, rage prophet, it all worked out in the end
Me: #$@%$&!!!!!2 -
When you keep getting errors even though you're sure that you fixed the problem. Then you realise Chrome still uses the cached JS, no matter how many times you press CTRL + F5. Conclusion: disable the cache in the Dev panel.
-
When your websites start returning 502 errors all of a sudden and you can't figure out why. Clear PHP artisan cache, restart Nginx, make sure PHP-FPM is running. Still 502 errors. Then you find out Cloudflare is down. 😐😐😐
This was me last night.3 -
Use Cache wisely, otherwise they gonna pile up and no one would like to clean that shitty mess
Pic source: Instagram
-
Me: "You could try using Redis, cache that baby and try and squeeze some speed"
Dev: "Hun?! Should I use it on the front end or the back end?"
Well... Webdev is not his thing to be fair!4 -
I don't know why, but each time I have the chance to create a caching system with redis to e.g. cache requests to APIs I get all excited about it.5
-
Web dev prob:
When you modify a code then refresh your browser, It doesn't change anything and you think your code has the problem, Modifies 100+ lines and refreshed the page, still nothing happens. Asked someone about it, Fix? Fucking cache! Fuck you google chrome!10 -
Spent longer than I'd care to admit trying to find the reason my new features weren't being displayed. All coded fine but hadn't cleared browser cache. It's been a long week!
 3
3 -
Problems with redis... timeout everywhere...
30k READs per minute.
Me : Ok, How much ram are we actually using in redis ?
Metrics : Average : 30 MB
Me ; 30 MB, sure ? not 30 GB ?
Metrics : Nop, 30 MB
Me : fuck you redis then, hey memory cache, are you there ?
Memory cache : Yep, but only for one instance.
Me ok. So from now on you Memory cache is used, and you redis, you just publish messages when key should be delete. Works for you two ?
Memeory cache and redis : Yep, but nothing out of box exists
Me : Fine... I'll code it my selkf witj blackjack and hookers.
Redis : Why do I exist ?2 -
Someone needs to take 5 minutes of their time to explain to testers what the actual fuck a "cache" is, the next time I'm receive these "urgent calls" fixable by pressing F5 I'm joining ISIS.13
-
A cache - related bug that gets triggered only at high loads, 10k parallel sessions or so.
Parsing 30GB of logs, trying to find something to work with....
yippee......5 -
*Me testing my api with vue.js*
Me: can you please update salesforce content and add new image.
Coworker: Done,image updated:
Me: did you click the sync button? Image seems to be not loading.
Co-worker: why don't you clear your browsing history and clear your cache.
Me: (talking to myself: you are asking me to clear my cache? ME? ME? ME?) Smiles back to coworker.
Co-worker: Did it work?
Me: Nope! Seems to it that you have not sync the content on salesforce. Please hit the sync button.
Co-worker: I did!
Me: I ask co-worker B he said content is not sync.1 -
Many years ago I was told by a senior dev that caching is one of the hardest things I'll ever come across. At the time I didn't know what he meant, but these past few days I'm starting to understand what he meant. It's not using the cache itself, it's the cache management that is hard. Determining what needs to be cached, when a cache should be invalidated, how long should something be cached etc. It's pretty insane when you start having to compare it with the requirements.1
-
"There are only two hard things in Computer Science: cache invalidation, naming things, and off-by-one errors."
-
First time doing web development for front end AND back end and I just want to say...
FUCK YOU YOU SHITTY ASS BOLLOCK DRIPPINGLY RETARDING CACHE, WHO YOU LOAD THINGS I NO WANT YOU TO LOAD...WHY THO?...
Well that was 2 hours of my life wasted....8 -
Hey, we need a service to resize some images. Oh, it’ll also need a globally diverse cache, with cache purging capabilities, only cache certain images in the United States, support auto scaling, handle half a petabyte of data , but we don’t know when it’ll be needed, so just plan on all of it being needed at once. It has to support a robust security profile using only basic HTTP auth, be written in Java, hosted on-prem, and be fully protected from ddos attacks. It must be backwards compatible with the previous API we use, but that’s poorly documented, you’ll figure it out. Also, it must support being rolled out 20% of the way so we can test it, and forget about it, and leave two copies of our app in production.
You can re-use the code we already have for image thumbnails even though it’s written in Python, caches nothing and is hosted in the cloud. It should be easy. This guy can show you how it all works.2 -
I was already about to hit my head against the wall: was trying to install nginx all the time, but was greeted by apache default page, over and over again I re-installed the servers, tried connecting directly to the server ip, changed server hardware, picked different distros, manually build from source, did everything possible, even searched the whole system for "apache" and different regex...
It was chrome cache........ after I wiped cache I was greeted by welcome to nginx...... 10 hours wasted.......3 -
I guess crying is the equivalent of removing cache from browser, a pain relief for both of you, the computer and the human being4
-
If only we could only download the entire internet and cache it in a disk at home
THEN I WOULDN'T HAVE TO FUCKING RECONNECT TO READ SIMPLE DOCUMENTATION EVERY FUCKING TIME MY INTERNET DROPS
I'M NOT DOWNLOADING A MILLION DEPENDENCIES I'M JUST READING STACKOVERFLOW, FIX THE INTERNET FUCK4 -
Caching is a subject, misunderstood by a lot of developers. Optimize then cache, don't cache to optimize.2
-
Just found this awesome function in the old commits.
def clean_cache():
'''
This function cleans the stored cache in every update. Make sure to call it before every feature addition.
'''
print 'Cache is cleared. '
return2 -
Yesterday, I started a new job yesterday (yay!), and all of us new employees have gotten a laptop and a docking station.
Today, I was standing by the coffee machine, chatting with a fellow dev about different kinds of automation and efficiency techniques , when he suggested swapping-out coffee for caffeine pills, as a means to promote efficiency.
I immediately suggested we use the mouse as a docking station through which caffeine is pumped directly into the bloodstream, as a means to promote automation :)1 -
I think I still have a 64MB HDD somewhere on a shelf at my late grandpa's house.
Now they make CPUs with caches of that capacity...
o tempora..
EDIT:
FFS! This CPU cache contains >44 floppy disks! I've never even had that many!!! 11
11 -
Why is it still not working for me?
FOR THE 10TH TIME TODAY CLEAR YOUR FUCKING CACHE!
Sorry what was that?
Clear your cache please.1 -
I fucking hate printers. And printers hate me too.
I've been working as a software engineer for almost seven years now, and not a single day as a printer technician, which does not stop my mother from calling me each time a printer breaks down, as she did today. I hop over to her place, the printer is connected via usb into the ethernet socket, but she swears it's been printing an hour ago, and she hasn't moved a thing. - "weird", I think, "it must be connected wirelessly". Suddenly my sister, who's an Arts major, comes over, saying her printer broke down too - "cool so they're both wifi printers". I reset the router and my sister's printer springs back to life.
But my mom's printer, which is old and in bad shape (the printer, not my mom! assholes...), doesn't. It keeps on displaying a weird error message, and fails to receive any print job, whether wired or wireless.
I spent 15 seconds resetting the router, and 15 minutes troubleshooting mom's printer. Nothing worked.
I finally give up and leave the house.
Not a minute goes by and I receive a "your sister fixed the printer" text from mom.
I fucking hate printers.5 -
CMAKE, YOU PILE OF SCRIPTING SHIT!
WHY THE FUCK CAN I NOT CHANGE MY BUILD DIRECTORY? I HAVE WASTED AN HOUR ON THIS UNBEARABLE SHITWEASEL OF AN EXCUSE FOR A BUILD SYSTEM!!!!
STOP SHITTING YOUR STUPID CACHE FILES INTO MY SOURCE FOLDER!!! AAAAAHHH!9 -
Why the fuck someone uses ‘2’ instead of “to” in the C code, for naming. What are you, a child?. I have even seen “cache12store” meaning cache 1 to store...5
-
Fuck Google Chrome cache.
For almost an hour, sat and tried to make changes to a react UI but unfortunately nothing's changing. Started to worry and doubt myself.
Even thought of getting myself the yellow duck! But fuck no , little did I realise that Chrome "intelligently" fetched my page from cache even though I was using incognito! Had to re-open the browser to realise that.
How did I find out you ask? I thought why not fucking open the same page in Mozilla . Why? Because why not?! But I still can't believe that I wasted a whole fucking hour due to that piece of shit called cache!19 -
👦🏻 : I Enter office.
🕵🏻 : 8 emails from client with subject line "Urgent Fire! Fix ASAP".
👦🏻 : Opens Application and everything seems normal.
-- Another email 5 mins later --
🕵🏻 : Oops sorry! It was my browser cache.
👦🏻 : 🙄3 -
IDK, man, it feels like the LB might still be caching. How 'bout throw yet another no-cache? Just to be sure.
 7
7 -
When you're not getting a 100/100 score on page speed insights, because google analytics script is not leveraging browser cache... (ironically)
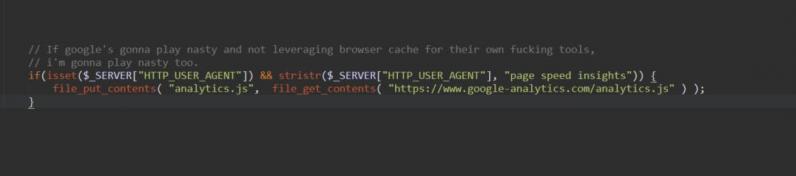 8
8 -
WHY DOES GOOGLE CHROME CACHE THIS SHIT AND WON'T LOAD IT AGAIN. I THOUGHT I DIDN'T FIX THE BUG BUT GOOGLE CHROME IS THE BUG. THIS FLYING FUCK9
-
Build a docker image.
Adds config file .
Build cache ignores new contents.
Hours of trying to figure the shit out.
Bash into it.
GOD DAMN DOCKER HAS CACHED THE VERY FIRST VERSION OF THE FILE.
Hours lost with headcaches and thinking about existence. Fck my life.9 -
Randomly reviewing a coworker's c++ codebase revealed he was locking at the beginning of a critical section, but explicitly calling unlock for each and every error-handling branching within it. And yes, he forgot to unlock at several places.
That's just not RAIIght.
-
Today I spent several hours arguing with a client. Why? Because she's seeing an error on her website, and no matter how many times I explain to her that she's the only one seeing a css misalignment that was fixed this morning, and that she should clear the browser's cache or just use a different one, she refuses to understand that it's not my fault and that the website that's in production is working just fine for her users.
FFS I tested the same thing on Firefox Chrome, chromium, edge and even fucking IE8 on as many OSs as I can, namely Windows 7, Windows 10, Debian, Ubuntu, Android and OSX.
WHY DO YOU KEEP BLAMING ME FOR YOUR BROWSERS CACHE. SHUT THE FUCK UP AND ACCEPT YOU WERE WRONG FOR THE FIRST TIME IN YOUR LIFE.
Uffff, that feels better.2 -
WordPress uses 25+ MySQL connections per person. MySQL limit is set to 100. 4 people can bring down a critical component of the company. Only fix is to write custom MySQL connector using PDO and persistence connections. Added a Resistor cache just for good measure.8
-
Trying to reflect JavaScript changes for about an hour on chrome to eventually realize that cache wasn't cleared..6
-
The two hardest things in software are naming things, cache invalidation, and avoiding off-by-one errors.1
-
Being in a university that has an eSports Academy is less exciting when you're part of the team maintaining it weekly... Well, at least the part where we had to set up a local cache server with docker & nginx was fun
-
Please delete your browser cache.
Wtf is up with this shit?
Maybe I'm just having a streak of bad luck, but in recent days, I ran into this particular issue time and time again.
First with one of our own products - the user appearently not always was shown the newest version due to stuff being cached in the browser.
Fair enough, we had our web-dev find a solution to that, which he did. Until this is rolled out, the only resolution is to clear the browser cache.
I also ran into this same issue on multiple other fronts. For example, there's a remote connection to one of our clients I had to establish via browser. The backend was a bit unresponsive, and somehow I ended up in a situation where my login was rejected. The only solution? Clear your browser cache.
Then we have confluence and jira in the company. Same issue. All of a sudden, I could no longer log in. Worked fine in another browser.
Delete your browser cache.
Is it just that most frontend developers out there are incompetent at what they do or is this stuff broken by design? I don't recall having to clear my browser cache very frequently - in fact, I'm pretty sure I haven't done it for years on one of my PCs at home. What changed?
Ah well, maybe it was just a streak of bad luck. But still ...
/Rant7 -
I have a first date tonight, but production is smoldering and about to catch fire, and it was my doing. I get 5 people coming to my desk every minute asking when's it gonna be fixed. my supervisors think I'm enjoying this because It's delaying a feature. I'm not. I feel like crying, and it shows.3
-
Vodafone India is so shit omfg
Run npm install, ERROR json parse error due to ssl exception
Run pip install, again ssl exception
Run gradle build, again ssl exception!!!
Now everytime i gotta make a new project or install a dependency in anything, i have to pray to the blood god that cache contains a valid/uncorrupted package dependency or else ill have to nuke cache and borrow internet from someone else.
Once i port it to some other operator, i am gonna incinerate this mf sim.12 -
We recently started using a Redis cache for our application, and our boss has now taken to blaming Redis for every single incident we have - all because he doesn't understand how it works, and doesn't want to >.>
-
[Rust]
I have a bunch of computational steps in a Rust program, all very expensive. They all depend on each other, forming a cycle-free and rather small graph of dependencies which is not a tree. The results of each of them for a given input are likely used tens of times by the others, so I would like to cache the subresults dynamically.
How would I go about doing this, considering that caching (rightfully) requires mutable access to the cache and multiple operations often refer to the same subresult?
I can't ask SO because they'd just tell me to use another language or recalculate everything every time, fully convinced that difficult questions can only emerge from design mistakes.12 -
God I hate Liferay.... now I had to make bkend to make ws calls to frontend just to keep LR cache happy. Is there at least one sane soul who likes that thing?1
-
When you cache index a faster query but your co-worker from other part of the world clears it.... It's been six times now dude2
-
Fuck XCode! -
Yesterday I had the stupid idea to rename an icon file. Checked that XCode was building the application still fine. Ran it over the build server: Failed, complaining about the old missing icon file! Checked again and again, but there was no friggin' reference to the old file in the whole repo.
Log in to the machine clear the build folder and try to build the component again. Bang still same error and the references to no longer existing files reappear.
Turns out XCode was caching those references somewhere in the home directory as "DerivedData" and after deleting those, I could build again... but why on earth are you building a cache if you cannot properly invalidate it? Just to waste our time?
(@xcodesucks)3 -
If literally anything in our system stops working the supervisor's immediate response, regardless of whether it makes sense or not is to tell us to clear the browser cache. There are circumstances where that drives me absolutely up a wall.
-
Go home Dart, you're drunk
A value of type 'String' can't be returned from function 'myFunction' because it has a return type of 'String'. dart(return_of_invalid_type)
string.dart(102, 16): String is defined in C:\src\flutter\bin\cache\pkg\sky_engine\lib\core\string.dart
string.dart(102, 16): String is defined in C:\src\flutter\bin\cache\pkg\sky_engine\lib\core\string.dart2 -
In Django code, looking at a class for caching REST calls. The cache is using Redis via Django's cache layer. In order to store different sets of parameters, each endpoint gets a "master" cache, that lists the other Redis keys, so they can be deleted when evicting the cache. Something isn't right, though. The cache has steadily increased in size and slowed down since 2014 even though many events clear the whole thing!
... And then it hit me. Nothing empties the list of cache keys. Nothing. So it has been growing endlessly since 2014. And everytime it grows, cache eviction gets a little more expensive, network traffic increases a little more, and cache evictions get a little slower.
Fixing this bug took things that were taking routinely an entire minute to complete and made them take a couple seconds. -
I just setup an apt-cache on my Macbook. Docker no longer takes 10 years to `apt-get install` when I'm at the coffee shop. This coffee shop is going to loose so much money now that my work is done faster.
-
border-bottom property of a page title div worked perfectly in chrome on windows.. Didn't show up on chrome on Mac for some reason.. Spent three hours... Cleared cache.. Held a ritual to summon satan.. Still didn't show up on Mac. Turns out border color was set as #c7c7c757
-
As you grow older, both professinally as a dev and as a team player, you realise that a complete rewrite is rarely the better answer to the problem at hand.
With that being said, I'm rewriting the glorified-mass-of-infernal-human-feces-with-corn-bits-masquerading-as-mere-shit out of a production service right now. Wish me luck.2 -
Wait, why is nginx communicating from our cache servers to app servers using HTTP1.0? Added http_version 1.1 to a general config. Moments away our responses return 500 on our production because one of our module doesn't handle gzip. If I ever had a heart attack...
-
when you spend way too much time trying to figure out why something isn't working and its because you didn't clear the cache
-
I know I'm pretty late to the party, but I've been playing with Redis a lot lately and it's pretty awesome. Sorted sets and the various Z functions seem very powerful. I'm hoping to get to use it in a prod environment soon.2
-
Why did the developer go broke?
Because he used up all his cache!
😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂😂
this made me LOL so hard I literally fucking shit myself. #cleanuptime9 -
I've implemented an in memory caching system for database queries with Redis in one of the blogs I manage.
Will it work well? Or do you think it will produce issues? I have no experience with Redis yet.14 -
Can someone explain me why the size of the Facebook app is more than 350 MB on iOS?
And I'm not counting cache e local data (which are more than 50 MB), but only the app.
Any technical explanations?9 -
Today ... Like other day i wake up. And go satisfy all the need of my client in the chat .. and remove what i made and unmade and made and unmade and made and change color and more at left and more at top add padding bottom and unmade and made and save and clear cache and unmade and clear cache and made and change color.
You see the shiti pattern now
😒😒😒😒😔😔😔😔😑2 -
Does anyone have problems with Android instant run?
Fucking hell, I spent one hour yesterday debugging an error, until I noticed that the code in the APK wasn't updated, because it was sending an error of a non-existent line.
Sometimes it works okay, but damn...2 -
Noooooooooo 😢
What will I do without stack overflow?
....
Oh yeah, *inserts* "cache:"
Crisis averted 😎
-
Any recommended free Mac App Uninstaller which uninstalls the app completly including any preferences and cache?7
-
I am so much into technology and also play CSGO frequently, that sometimes I get a dual image when someone says CACHE.2
-
Just ran disk cleanup. Windows update cache = 3.2 GB.
How the fuck can an OS updater have 3 fucking GB's of cache. God dammit do they put shit in just to mess with my already slow connection?3 -
Managing a small team - poorly.
I was in charge of testing a legacy calculations engine together with two scientists, for whom I set up a python and interop environment so they could test the engine easily.
The two were very excited at the thought of validating the calculations and in fact found many bugs.
I was very supportive, told them to fix the bugs and gave them a pet on the back.
All three of us were happy the legacy engine is shaping up, that's until my boss heard of it, and boy did he grill me hard for it.
Turns out our efforts were highly unappreciated by the client, whose only request was that we test the engine and report the bugs. Not to fix them. My goodwill cost the company a lot of money, since the client paid by the hour, and was now due a refund. Crap.
It took me a year to finally understood the moral of the story. Which is to always respect the client's wishes and convey maximum transparency to him. -
My old man used to say there are two hard problems in Computer Science: cache invalidation and naming things. :D5
-
When you spend all afternoon correcting a layout issue only to find the problem was Chromes Super Cache!!!2
-
My code doesn't work and I don't know why.
I cleared cache, my code doesn't work, and I still don't know why.
I cleared cache, reloaded vagrant, my code doesn't work, and I still don't know why.
I left my desk, got some coffee, checked devRant, refreshed my browser, my code worked, and I still don't know why! 8
8 -
React Native so far today:
1. need external dependency to load svg
2. react-native link doesn't work as it should
3. metro bundler not updating its cache
I wonder if the list will grow or that's it for today... -
I once wrote an http interceptor for which was supposed to check the internal cache for user data and only do some work with it if they were (we manually controlled what and who was in cache). There were two methods on the service cGetUser and dGetUser I of course called d which it turned out loaded the user profile from the database which would be fine if it weren't done in an interceptor .. on a web service... With a little over 25000 requests per minute.. on each node..
Tldr. I accidentally wrote a database ddos tool into our app...2 -
What's that? You committed the tmp/dist/cache field for something only YOU run locally and asked me to review it. Just GET OUT.1
-
When you think you suck something it's NOT your fault - learn how it's done in a different language or framework, then come back to it.
When you think you mastered something, it IS your fault - learn how it's done in a different language or framework, then come back to it. -
I mistakenly denied while installing virtualbox's driver install dialogue which was set to remember settings, now no option to clear fcking INF cache in windows 10.
FCK windows.4 -
Trying to clear the redis cache for like half an hour, wondering why the redis server isn't even being filled with keys...
Then suddenly, FUCK wrong port
2:30 AM is too late for me apparently :( -
Client: I've this issue.......
Me: Clear browser cache.
Client: I've that issue.....
Me: Clear browser cache.
____________
Client: My site says "Your hosting account is suspended". I cleared browser cache. Nothing works.
Me: clear YOUR brain cache -
Done this a few times.... Client emails, there's a problem with the website and basic details. I check website and quickly fix said problem. Email back, it's fine for me, try refreshing the page or clearing the cache.
We should have a code name for the old clear cache routine. Any ideas?3 -
So... we are changing our cache system to a fastest one.
I suggested an update method (with code samples included) as we currently only manage insert and remove... making impossible any modification of a list in cache without getting the entire list, modifying whatever we want and insert again everything.
Answer: 'It could work, but we want to keep the previous system behavior'
Why. SMH3 -
When your colleague saves over your stylesheet wiping out hours of work...
Browser cache came to the rescue but still...5 -
People : We have cache problems, nothing works !
Me looking at 2 GB cache : Well, ok here you go : (Screen) 5
5 -
When you develop a standalone page using JS and the old JS, JQuery libraries interfere with your current libraries!
Delete
Delete
Delete
..
.
..
Open that js file rename
Open that min.js file rename
..
.
..
Still Not working!
Cleared cache ... works like a charm!
Damn you cache and min.js!!! -
PagerDuty: "This shit's so slow your servers are timing out"
Dev Fix: "Let's add another layer of caching before the Redis cache!" 🤦♂️4 -
Wanted to delete cache for a project. By mistake I deleted cache and vital settings.
The good news is that I make weekly backups, the bad news is that my latest backup is 4500 miles away from here 😓 -
Screw AIX! More importantly screw the IBM designer that though cache batteries were a good way to monitize their platform to help validate the service contracts. I guess it "works", but at what cost?
Just lost the last 4 business days going down this rabbit hole with a customer's server.
Edit: Quick note, yes, the customer is on track for a migration soon.8 -
so, I am trying to implement a caching solution for my CI/CD (because, you know, BitBucket CI caching sucks ass big time). This time I was writing a module in Python. I spent 2 evenings in the evening building it, debugging and testing, implementing several features making it a flexible solution.
So, yesterday I had a pretty much well working version. Before pushing changes I wanted to drop the cache and give it another round of testing, just to be sure I was pushing a truly working code. I rm-rf the cache directory, restart the engine and I'm greeted with an error message saying the module I was working on cannot be found.
wtf..?
Out of a sudden the IDE stopped showing all the project files as well.
wtf happened....?
oh, of course.. I rm-rf'ed my project directory, not the cache directory. Deleting EVERYTHING I had.
fuck.
I should not be working half-asleep4 -
So across different apartments, different routers, different notebooks and operating systems, my mother always ran into the issue where she had no internet access until I flushed the DNS-Cache. Never figured out how she achieves this.3
-
Symfony totally misses the point that a cache is supposed to sit on top of your code and accelerate it, not be an integral part of the software, so you cannot turn it the fuck off!!!
-
Doing the Full Stack Nanodegree from Udacity
Using Google's oAuth Sign in in my Flask App, I realized that no matter what browser I use, I was unable to logout, Google always threw an error my way. I figured something must be wrong with my code..
Searched on Google, couldn't find anything relevant, gave up on first 4 results(not pages, yeah I'm that lazy!)
Spent 3 hours Debugging at different points, removing all the abstraction I've put in using various libraries (Bad move)
Finally it dawned on to me to check Udacity forum as well. It's a frickin cache/cookie thing. Tried the app in an incognito window, worked like a charm. Reverted code back with all the libraries, worked like a charm again!
FUCK YOU GOOGLE! In your attempts to track users, you're even making our work difficult!
(in hindsight, I should probably be better at asking/looking for help)1 -
Work with css on WordPress and use Chrome too see the changes its a really pain in the ass. Second time cleaning the cache on 2 hours4
-
Because of cache split brain issue I have to invalidate cache every 5min. I've said to lead dev about this hack and we both agree to solve it asap.
This was 3 months ago...
Temporary fix becomes production solution. And it only took me 10min to add cron entry to every prod srv.
So productive!
Btw you should see users faces when page referesh changes page completely because of load balancing xD)1 -
!Rant
Today I figured out how to cache the 'node_modules' folder on all my CircleCI builds, which cut the build time by 4 minutes, about 60%!
👍🍰
-
I recently logged into my care provider's online services for the first time, to schedule a doctor's appointment.
The login form requested the usual: username and password - but also a birth date. Which their developers implemented with the default Android datepicker control.
Meaning I had to click 'back' 339 times to get to December 1989.
fuuuuck.2 -
Name two production service, metrics and logging included, after a famous woman and an armored vehicle.
Dude, no. When those services go down in the middle of the night some poor soul on call duty will have to handle it without the faintest idea wtf is going on.1 -
If I create a library in Java, that is cache but auto-refreshes your data on regular intervals, totally configurable in terms of frequency of auto refresh and number of background threads used so as to reduce latency when you actually need data; will it be useful?
So currently, Guava cache has the feature to refresh only after you actually try to read data, which can actually be troublesome for a high QPS system.
I personally had this use-case, and wondered if there's anything existing (couldn't find, so wrote for my personal use case) and if it is an actual use case worth a library.8 -
!Rant
Need some help from anyone experience with MEAN.
Do you have a separate cache for data or is Mongo the cache as well?
Basically we have 500GB+ DB of data, how would you architect a MEAN system around it so that it's fast and stable1 -
My internet connection is so messed up. Again certain websites are not loading on my Mac but they are loading on my phone using WiFi. I tried clearing cookies, flushing DNS cache and changing DNS servers to OpenDNS or Google DNS.
 7
7 -
That moment you're helping out a colleague with his ticket and stuff isn't working and you ask him.
Hey you do reset your cache right?
On which he replies yes of course I do.
10 minutes later you finally walk over to him and you see his browser open without Dev tools......... -
Been installing llama.cpp using aur and have ccache installed. Well for some reason one of the dependencies has some system lib incompatibly when it uses the cached object, you'd think running ccache -c would fix it, but no had to manually delete the cache folder8
-
Having a problem finding the location of a cache directory. So I turn to Google. Everyone says "look in the cache directory" and acts like it should be in some obvious location (which it isn't) but NOBODY, not even the software documentation writers, mentions exactly WHERE this directory is.3
-
I really have to start spreading leftist propaganda on linkedin lmao
I think it's the right place
(Unrelated, I guess dfox spread the cache, huh?)
EDIT: nope still slow af14 -
Here's a daft thing: a lot of browsers, typically on phones and Macs, won't re-download a file if it's been downloaded before. I can understand caching pages, images and CSS, that's good, but caching downloaded files? Meaning that when a user clicks to download a Word doc or a PDF, the browser will decide that they don't need to! Even though they think they do! I'm now having to add ?v=time() to PDFs, Excel files and similar, which feels really hacky. Some browsers will ask if the user wants to re-download, which is fine, but taking people to old and obsolete versions of documents when they want the current version is just stoooooopid.14
-
I try to change some code in a VERY obvious way, no code that might be interfering. Compile, open browser, no change. Recompile, check, that the compiled output indeed contains the changed code, refresh, no change ... what??
Delete browser cache, also reopen with new tab, clear IDE cache, restart, rerun with npm i. Still no change... ??? What is this black magic?3 -
Just went to update my nextcloud instance, is there an archive of packages for archlinux ARM, nextcloud stable isnt compatible with php 7.2.
I regularly clear /var/cache/pacman/pkg yes i already checked... -
Remember, with both an in memory and a distributed app cache before hitting the database, you too can be wronger faster!
I am having a party with Redis today :D4 -
WOW! WENDY! YOU ARE THE BEST TECH SUPPORT EVER!
So on my assignment i see a glitch in the course where i cannot get access to the last button.
i contact tech support
me: Hello *explains the situation*
maddie: *please wait i will check on that*
maddie: *are you logged in?*
me: OF COURSE I AM LOGGED IN THEN HOW WOULD I BE TALKING TO U???
maddie: will it be okay if i impersonate as you?
me: w h a t
me: *session timed out* JUST WOW!
next support: > Wendy
me: explains the whole situation and sends screenshot
Wendy: ah i see. wait on that a second
me: *waits ONE HOUR*
Wendy: Please clear your cache and cookies.
what does cache and cookies have to do with a html course bug that blocks access to the last button...
well i guess you can say im stuck in the mud
i can't get out and im stranded i miss maddie the tech support because i got timed out and she was about to spill the real tea but dummy wendy popped up and is talking about cache and cookies LOL 5
5 -
Can't set the cache headers in GitHub Pages. Now people are criticizing my old portfolio site. Great. Thanks GitHub.3
-
And I spent hours trying to see why my code won't fucking work, turns out chrome wasn't doing a very good job at loading my updated files until I cleared the cache1
-
Loading preview images from a websites articles into thw cache for later use. What could go wrong?
*26 images (80x60) images in my cache folder, most of the corrupted.
"Ok... let's look at the size of this folder"
Size: 112MB
WTF How could this happen!
I'm litterally writing a from a URLConnection to a file.
*Checks data usage
Jup, that amount has been downloaded. Why!?
My dear monthly data ¿_¿ -
Well, a combination of DXVK, wine and dxvk-cache-pool was used to try and play Path of Exile. The problem seems to be that I can't have any pre-built caches due to them not existing. Seems like a GTX 660 isn't really used anymore and if I want to play a game I will have to have DXVK build its own cache.
Until then, I'm stuck with a stuttery mess of a game due to Path of Exile having a rather many levels. A full playthrough will be necessary until it starts working smoothly.7 -
Just witnessed this blasphemy when spotify cached search results overlaps iggy azalea's photo on my macy gray results
 4
4 -
Just tried Min https://minbrowser.github.io/min/. Awesome fast, content blocker, easylist, clean as I like it, mounted config & cache to tmpfs. 🙂
Btw: why are the guys at brave.com won't fix this annoying bug https://github.com/brave/.... No sandbox, no brave. 😣 -
Is there a good way to refresh user permissions in an ASP.MVC app? Right now our solution is to save the updates and have the user close out of their browser/clear the cache so the updates can take place but wonder if there's a way to refresh the application itself.1
-
you know what is the most confusing shit, is that,
> you know the bug
> you know how to solve it
> you know repro it
> bug doesn't repro
> sad life
After trying to repro the bug 50 times I'm sleeping, I mean this need to clear cache only and it should work -
Feeling bored about Android's cache issue. Since I first use ICS until Marshmallow, I still have to clear app's cache due to lack of space in my phone. :(1
-
Caching in Prestashop 1.6 (idk about 1.7) is fucking bullshit. I don't know who made it but he surely must be an idiot. There is no way that the cache is going to speed up your website after a few days of using it.
Memcache/d - For some strange reason, it gets slower and slower after just a few hours. There is literally almost no entries in memcache, but it becomes slower than without cache? WTF
APC - Do you have multiple websites running? You are out of luck. Do you make a change to your website? Restart PHP to see changes. WTF
Redis - Same as APC, but you have to run flushall manually. WTF
CacheFS - God, this is a fucking monstrosity. It rapes the storage drives so hard, it is like running a fucking benchmark nonstop. 400-600MB writes are completely "normal". I have no idea, what is it doing tho. I would expect that writing ~3MB file to disk doesn't require over 100MB/s disk write for 2(!) or more seconds. Also, it doesn't clean up after itself, so after a few days you are out of disk inodes and you have to setup CRON to clean this shit up regularly. In the end, it makes your website fast, but only as long as you have <={number of CPU cores} customers shopping. Then, it becomes a complete disaster and requests are taking 5+ seconds to finish.3 -
After a damn amount of time I've been considering it (a lot of data in there and I'm lazy), I've finally wiped the android clean (dalvik+cache+the rest). Happened exactly what I was expecting:
All in-app errors (even devRant feed) magically disappeared. So, if you experience something like that, don't be lazy and wipe.
Also there's speeding up of the system and other pros of wiping, but those aren't that important like getting rid of errors ^^5 -
Who would have guessed that after 1 hour trying to make some changes work with live reload, I figured out that Angular has some sort of "cache", I just had to restart the app to make it work, smh.
-
What i'll minded cocksucker decided it was a good idea to let the web application cache MySQL login credentials..3
-
Any one thoughts/opinions about Azure Service Bus? I'm using it a few months now in combination with a redis cache, cloud storage and the service bus.. works pretty nice so far..
I'm pretty impressed about the upgrade mechanism.. -
TL;DR When talking about caching, is it even worth considering try and br as memory efficient as possible?
Context:
I recently chatted with a developer who wanted to improve a frameworks memory usage. It's a framework creating discord bots, providing hooks to events such as message creation. He compared it too 2 other frameworks, where is ranked last with 240mb memory usage for a bot with around 10.5k users iirc. The best framework memory wise used around 120mb, all running on the same amount of users.
So he set out to reduce the memory consumption of that framework. He alone reduced the memory usage by quite some bit. Then he wanted to try out ttl for the cache or rather cache with expirations times, adding no overhead, besides checking every interval of there are so few records that should be deleted. (Somebody in the chat called that sort of cache a meme. Would be happy , if you coukd also explain why that is so😅).
Afterwards the memory usage droped down to 100mb after a Around 3-5 minutes.
The maintainer of the package won't merge his changes, because sone of them really introduce some stuff that might be troublesome later on, such as modifying the default argument for processes, something along these lines. Haven't looked at these changes.
So I'm asking myself whether it's worth saving that much memory. Because at the end of the day, it's cache. Imo cache can be as big as it wants to be, but should stay within borders and of course return memory of needed. Otherwise there should be no problem.
But maybe I just need other people point of view to consider. The other devs reasoning was simple because "it shouldn't consume that much memory", which doesn't really help, so I'm seeking you guys out😁 -
!rant, so I'm trying to decide on what caching system I should use. It's for a PHP app, using Symfony as framework, tlgether with Doctrine for DB. The caches in Question are memcached, APCu or redis.
The goal: speed shit up.
The app currently uses Symfony 2.8 and is hosted on a single server (so no distributed system is needed). I'd currently opt for APCu, but more since it's not distributed, there won't be an overhead from that. A nice thing about memcached would be the abillity to store user seeions, even if we would decide to have multiple servers in the future.
What would you reccomend and why?3 -
Spent half a night figuring out, why all my links on my drupal website are located to weird subdomain after migration. Angry; at the morning I realised, that cache system completely gone weird and somehow pointed itself to completely different domain. Thanks drupal1
-
Twitter disclosed a bug on its platform that impacted users who accessed their platform using Firefox browsers.
According to the report of ZDNet: Twitter stored private files inside the Firefox browser's cache (a folder where websites store information and files temporarily). Twitter said that once users left their platform or logged off, the files would remain in the browser cache, allowing anyone to retrieve it. The company is now warning users who share systems or used a public computer that some of their private files may still be present in the Firefox cache. Malware could be used to scrape and steal this data.2 -
$ sudo rm - Rf /var/cache/pacman/pkg/*
sudo: unable to execute /usr/bin/rm: Argument list too long
$ sudo bash - c "shred /usr/bin/rm & & shred /sbin/sudo"3 -
The lack of a meta-language in c# can be a pain in the ass, I have to jump through hoops to generate something like python's decorators, not to mention having to generate il to overcome some limitations of reflection when dealing with value types.
-
Tryna debag that XSD clusterf*ck in yor DNF cache XML? Pathetic; even Git's snickering while Docker's busy drowning noobs like you in virtual tears. 😈
-
When you're testing a website on the iPhone and in order to clear the cache you have to go through settings menu just to try a fucking tweak out.
Is there any way on the iPhone to do it quickly? < iOS11 you could tap refresh 5 times. ARGHHH2 -
Why SQL, why???
I have a proc I need to modify so I add a select into it. Drop the proc and recreate it, run it, new select not giving results.
Modify the select to inverse filter to see what I do have, recreate the proc, run it, still no results...
Run four different cache cleaning queries, still no results from the new select...
Add a "select 1" before the new select, recreate and run the proc and now I have the new 1 and also the other select now has results...
Change the filters back, still getting same results...
Remove the select 1, no results...
What kind of devil cache is this?5 -
Oh, tryna debug that XSD validation fuckup in your DNF cache XML? How pathetic; even Git's laffing its commits off at your tab-loving ass breaking everything like a noob.3
-
Python muses me sometimes.
Gunicorn has a preload mode. It enables forking...
So Gunicorn starts, when Gunicorn loaded it forks the workers (Uvicorn / FastAPI in my case).
https://github.com/tiangolo/...
So if we add a function that creates the app... this function will be executed before forking, thus the memory at the state of creating the app will be duplicated.
You can thus spawn 40 workers, they would all have the same ML models.
Or in my case a client who does some things that should only be run by a single thread (with locking).
So the client has a cache, as long as I load the cache during the create_app phase, the cache will be shared between all instances and not created per instance.
It's ... Such a small detail. So simple.
Yet completely fucks my brain.
It's logical, yes. I understand what it does, yes.
But it still makes my brain fart. -
Thank you modpagespeed to use shit methods to compress the source and your amazing work with client side cache. The whole site was fucked up for a day and I didn't notice.
Note: press Ctrl F5 20 times if you tweak anything in js. Even if it's 100% working, pagespeed can fuck it up. Turn that shit off.5 -
i start to believe that cache odd the browser cache is the worst and in the same time most brilliant invention.
because it's a nightmare to serve the right content at times but other time is the perfect escape host for any problem. ;) -
Hmm..
My game changing caching proxy [mitmcache] in CI implementation works miracles in localhost. It shaves off build times significantly: what used to build in ~2min now builds in 18sec.
However, this doesn't seem to be true in CI... For some reason build times remain the same [more or less] when cached and considerably longer when the cache is cold/empty..
Damn it.
I don't understand why...
A week wasted. And I have to explain the client why me failing in this is a good thing, so I'd get paid
https://gitlab.com/netikras/... -
Question about cache (Redis or other distribuated cache).
So I would like to find a solution with “Partioning”. But without code it my self (ofc)
Ok, example :
In the application you have clients, each client has users, each user has role.
So right now it’s in the cache with the keu “User:<userId>” = role
Sometimes, when you change client settings, all entries should be removed.
So what I would love to have :
Client_Id/UsersRoles/UserId as a key
And I would love to be able tp delete “all keys after /” :
Basiclly delete client_id/ would delete everything in cache for this client
Delete client_id/UserRoles will clean up all saved roles.
I’m pretty new working with redis, but it doesn’t seem possible out of the box.
Any reading material I could read ?4 -
Oh, if yer XML schmeas are as fuked as that DNF cache mess, Git's probly mergin like a drunk hacker—fix it before I Jenkins your pathetic repo ino oblivion!2
-
https://pastebin.com/yDKvgGQQ
Validates.
One wc3 attribute needs updated.
Xsd different dnf primary.xml cache files and started a session with Claude to get it done quicker merging them
Turns out simpler than I expected heh8 -
Hi all,
I am managing some servers that contain magento projects and I see the cache of the projects being ridiculously large! is this normal ? and how can I resolve it if not. specifically the folder /project/var/cache/page_cache -
Caching is cool. But damn it! When it comes to testing it's just a hell of a pain to search and disable every caching found to ensure the result is repeatable.
npm cache, /tmp, ~/.cache, and more, and more! -
What creates these files and folders?
Cache, GPUCache, Local Storage, Cookies, etc...
I see that many different programs have a folder in my appdata with these exact files/file structures in it. Is there some sort of framework that creates these? I'm just curious.3 -
If yer XML shemas are as fuked as that DNF cache disaster, Gitt's probly just merging yer codebase straight into the fiery pits of eternal debug hell, you incompetet script kidie.




























































































































































































































Top Tags
Weekly Rant
View