
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Dev manager: great news guys. We’ve built a new tool to do automated testing on apps. We’ve gotten rid of the old Appium solution we were using and built this new one.
Me: why not just use the inbuilt native stuff? Click to record works really well.
Manager: nah we thought it would be more flexible to build it ourself.
Me: ... ok ... moving on ... how does it work?
Manager: well this new .jar, you download it, pass in a config file, setup up your simulator and appium and the jar will do everything for you.
Me: ... wait you said you hate Appium? Now you’ve built a wrapper around it? And it doesn’t even set everything up, you’ve to do it all by hand?
Manager: oh we had too, would be too much effort to replace it. Don’t worry we can now write all our tests in .yaml config files instead of using Appium.
Me: so we’ve lost the ability of auto-complete and type ahead, everyone has to upskill on a new tool, it offers no new features over what’s available out of the box and we’ll have to deal with new bugs and maintenance and stuff our self ... because we need more flexibility?
Manager: oh don’t worry. The guy who built it is staying here. He’s going to deal with bug fixes and add features. He’s only one guy, but he’s really sharp, it’ll be great for us and the team.
Me: ... ... ...
*audible noise of soul breaking*
Me: ... ok thank you. I’ll look into this new tool3 -
Took me a week to realize that "!rant" just means "not rant".
I thought it was some sort of post front-matter that was no longer supported by the app (like a Duck Duck Go "bang").
😅7 -
DevOps required skillset:
* Frontend engineering
* Backend services
* Database administrator
* Security consultant
* Project management
* 3rd party contract negotiator
* Build system monitor
* Build system hostage negotiator
* Paging, alerting, monitoring
* Search server admin
* Old search server admin
* Old-old-new search server admin
* Redis, ElasticSearch, MySQL, PostGres, owner
* Agile coach
* No you shouldn't do that coach
* Oh, you did that anyway coach
* DNS: (Optional) It'll replicate when it wants, and how it wants to to anyway
* Multi-Cloud deployment strategist
* Must be able to translate Klingon to YAML, and YAML to MySQL
* Cost analyzer, reducer, and justifier
* Complex documentation generation in markdown that we should have done years ago anyway
* Marketing's email went to spam analyzer
* Wordpress is broke fixer
* Where the fuck does Wordpress run anyway?
* Ability to fix MySql running Wordpress on marketing's dusty laptop7 -
Last Friday i convinced my boss it was mission critical to have an IntelliJ Idea subscription for my workstation...
I mostly push yaml files to git... 😁 and i regret nothing...9 -
Let's start 2023 !
WHO THE FUCK imagined that having language like YAML is a good idea ??
Fuck you and your spaces. No editor produce any decent errors messages except "Your spaces are wrong".
When you edit an Azure debops pipeline, it's just 5 min ti do thing, 35 minuites to figure ou where to add/remove spaces.
NO, I WILL NOT read 25 pages of documentation to add a single step into pipeline.
Fuck YAML !29 -
I fucking hate YAML!!! Whoever thought a fucking whitespace delimited file was a good idea should......
</rant>
Ahh that's better; back to learning Ansible.20 -
SICK AND TIRED OF READABILITY VS. EFFICIENCY!!!!!!!
I HAD TO SEPARATE A 4 LOC JSON STRING, WHICH HAD AN ARRAY OF A SINGLE KEY-VALUE PAIRS (TOTAL OF 10 OBJECTS IN THE ARRAY).
ITS READABLE IF YOU KNOW JSON. HOW HARD IS TO READ JSON FORMAT IF YOU GET YOUR STYLE AND INDENTATION PROPERLY?!?
SO I HAD TO
BREAK THE POOR FREAKING JSON APART TO A FUCKING DIFFERENT YAML FILE FORMAT ONLY SO I CAN CALL IT FROM THERE TO THE MAIN CONTROLLER, ITERATE AND MANIPULATE ALL THE ID AND VALUES FROM YAML BACK TO MATCH THE EXPECTED JSON RESPONSE IN THE FRONT END.
THE WHOLE PROCESS TOOK ME ABOUT 15 MINUTES BUT STILL, THE FUCKING PRINCIPLE DRIVES ME INSANE.
WHY THE FUCK SHOULD I WASTE TIME AT AN ALREADY WORKING PIECE OF CODE, TO MAKE IT LESS EFFICIENT AND A SLIGHTLY BIT MORE READABLE?!? FML.5 -
I dunno why, but my brain is just not weird to like syntactic whitespace.
Things like yaml, python and coffeescript...as much as I like Python...i just can't stand being forced to deal with whitespace.7 -
Me and that other guy who has a braincell: Okay so we made this simple object mapping code so that you have the option to use YAML or environment variables, because they're both awesome UwU (we use YAML for testing, then variables for container prod deployments).
Some dude who picked up the project: meh, lets ditch that, dotenv and get rid of the object mapping, because I like to do the pain manually.
AND THIS DUDE NEVER EVEN BOTHERED TO READ THE CODE CLAIMING HIS IS BETTER WTF
It took us enough testing and cofusion to get Object Mapping right and this guy just bastardizes work we've done for the past 2 years claiming "it sucks"
What a bloody bellend.7 -
Can we please stop using a file structure (YAML, JSON, XML etc) and just changing the file extension and calling it a new file type?
Stop trying to make your software/framework sound more complicated by saying this shit, if you use something, own it and don't try to mask it...
And mini rant over...11 -
love-hate relationship with Python semi-rant
The year is 2020.
I have already grown accustomed to the idea that in order to do ML without worrying too much about having to completely jump through hoops with the tech stack I have chosen that I would have to settle with Python, which I like.....for small scripts that don't do much other than piping data around or doing simple admin tasks, that is generally our use of Python at work.
For anything bigger I would prefer something else. Not because I find anything inherently horrible in Python, I find it to be a nice language overall, that has made it possible for many to find a passion inside of the world of development and possibly an interesting in overall engineering and computer science principles. Much respect Python, good game Guido VR, what you did changed the world.
But it is that damn whitespace that gets me, the need to use it as a way to properly write blocks, I just can't make myself like syntactical whitespace no matter what I do. I can do without static typing, shit I did it for the longest time with JS way tf before Node and Typescript were a thing, and I have done it before PHP's attempt at having type hints, which still leave much to be desired. Ruby(imho) the most elegant language around doesn't have it and that is fine really, it does not bother me as much, if mypy gets powerful and widely adopted enough it will then be a non-issue.
But another thing that the 4 languages i mentioned before have is non-existent syntactical whitespace......I just can't stand it.
So, why am I saying all of this nonsense? Today I wanted to recreate a conda environment and landed on the use of YAML............which has syntactic whitespace and I lost my shit.
I seldom bitch about languages and technologies, shit, I used VBScript before, not only did I get paid handsomely for it, but I fucking enjoyed it(probably cuz I am a masochist).
But two things I cannot abide: VBA and syntactic whitespace.
Once I get enough knowledge for it I will push for the same level of tooling in Python to be ported to Scala.
Thank you for coming to my whiny post about something as small as bitching about syntactic whitespace.8 -
DevOps Engineer - Entire position exists primarily because Developers don't want to write YAML files7
-
Server configuration file formats...
some use custom text file
some use ini files,
some use xml..
some use json..
some use yaml..
some use toml..
How many file formats I need to learn!!!9 -
Today was a good day.
I was told to use in-house BitBucket runners for the pipelines. Turns out, they are LinuxShellRunners and do not support docker/containers.
I found a way to set up contained, set up all the dependencies and successfully run my CI tasks using dagger.io (w/o direct access to the runner -- only through CI definition yaml and Job logs in the BitBucket console).
Turns out, my endeavour triggered some alerts for the Infra folks.
I don't care. I'm OOO today. And I hacked their runners to do what I wanted them to do (but they weren't supposed to do any of it). All that w/o access to the runners themselves.
It was a good day :)))))
Now I'll pat myself on my back and go get a nice cup of tea for my EOD :)3 -
Took a devops position for a friend who needed help managing a small datacenter.
Five months of writing nothing but yaml for ansible. I'm about to go mad...1 -
Devops (By Azure) is so stupid.... (I won';t even start of YAML, it will be a 10pages rant).
me : Ok I have 5 projects, each has it's own Azure conexxion for deploy.
Me : Can I do just ONE shared connexion ?
Devops : Yes. You need to click 150 buttons and it's done !
Me : Ok. /* doing actions */
Me : Ok ready !
Me : Project 1 do your release pipeline !
project 1 : Sure, just wait 5 minutes.
5 minutes later
Project 1 : All good.
Me :Ok now sharing test ! Project 2 : do your pipeline !Project 2 : Sure ! It's strated !
Me : Ok I'll go take a beer
... 1 hour later..
Me : project 2 ? PROJECT 2??!!!
Me : fine... going into logs.
Message : You must accept the shared conexion from Project 1 before pipeline can run
Me : WTF ? I literally just SHARED it to project 2,3,4,5 !!!
Why that idiot check ?!
One thing is sure, I hate devops more than I hate JavaScript.5 -
See that dip in JSON in 2018? It's countered by a slight rise in YAML. According to this article, it's because of all CI and Docker services. Can't think of many reasons to use YAML above e.g. JSON.
https://theregister.co.uk/AMP/2018/... 20
20 -
YAML configuration is more difficult to do than the actual programming itself.
JSON and ini files are way better.18 -
Trying to automate gitlab deployment with Ansible. It runs but freaking keeps failing on task. Reconfigure the gitlab server. Without helpful output!
After 2 days bashing and commenting line after line the answer reveals.
True != true Fuuucc...1 -
FUCK YOU AMAZON! Stop telling me my configuration yaml file contains a tab... THE FUCKING FILE DOES NOT EVEN EXIST!
-
YAML files are one of the worst type I have ever seen until now. Fuck that shit. And fuck that indentation.3
-
white space being used significantly/meaningfully for syntax like python or yaml is a horrendous idea in my opinion
how awful is my take10 -
Hi Everybody,
Here by I introduce you the new Java Script framework and package manager that is going to change your life forever. We have considered all the problems developers are facing during their everyday career. We use latest techniques used in configuration files (xml, yaml, json, etc.), package managers (npm, gulp, yawn, etc) and other frameworks (require-js, vuejs, reactjs, etc) into consideration to bring you a framework that has them all together in ONE BIG PACKAGE! HAHAHAHAAHAAA!
Nope. I'm just kidding :-D1 -
Unpopular opinion.
TOML sucks
* it does not claim to care about indentation but it actually does
* nested datastructures are a nightmare, especially 'inline' for 'readability'
* oh fuck me everything must be "double quotes"
* booleans always lowercase, there is no "truthy" here.
* Tables are not intuitive at all.
And all this from working with it first time because I had the silly idea to modernize a python project to use pyproject.toml
Oh and don't get me started on pyproject.toml files. The documentation sucks!6 -
JetBrains Fleet sucks!
It's absolutely gorgeous but it sucks, technically. I mean did nobody try to edit a YAML file with 2 spaces indent in there during development??
I wasn't even able to open a fucking project with it one time. And why in gods name does it go full macos with it's design?
Loving their IDEs, but da fuck's going on with this?14 -
TIL Github renders markdown YAML frontmatter as nested markdown tables! Awesome as lightweight structured data documentation tool
 1
1 -
When starting projects, following semver.org quickly gets out of hand. Nothing is "backwards-compatible"
0.0.0 gitignore
0.1.0 prints arguments
1.0.0 prints text of web requests
2.0.0 prints parsed web requests
3.0.0 prints filtered requests
4.0.0 prints using yaml
5.0.0 logs to file
5.0.1 catch error
5.1.0 interactive2 -
I've just wasted 2 hours fixing an issue with a GitLab CI YAML definition, all because of a single colon:
echo "Detected changes: compiling new locks"
I swear to god, whoever thought it is a good idea to use YAML for CI scripts should rot in hell.15 -
I never liked YAML. But lately, I'm starting to dislike it more and more.
I mean, wtf is that?
- digest YAML input -- a valid YAML
- digest JSON input -- a valid YAML
A language that embeds another language.
Can it be any more confusing..?
Sure it can. the
```
script:
- echo "John said: hello there"
```
will fail YAML linter, because, even though I used quotes, yaml sees `echo "John said` as an object key
I think I'm yet to find more nonsense with YAML. And eventually, I'll grow to hate it.8 -
when CodeClimate reports it 2.0 GPA but your colleagues says it's good code-wise and styling wise...
turns out I didn't have the YAML override -
I hate yaml; finding that one wrong indentation level that makes everything goes to hell while still being perfectly parseable is a nightmare. Brackets were created for a reason, please don't throw away that.5
-
I'm such a fucking idiot
I'm setting up an api and to prevent unwanted fields or circular dependencies from showing up I define what fields should appear in a few serialization yaml files.
These files define what fields should appear in a given context. The default context for every field is to always show the id, and only a call to /posts will give you all the fields of the posts for example. This means that if you retrieve a comment with a linked post, the post will only show up as an id, but the comment will have all its fields.
I've been struggling with a stupid problem for 2 hours, I could verify that the yaml files were loaded in, all entities had such a file and the configuration was exactly according to the docs.
Guess why my api calls still caused circular errors?
Because I forgot to do the $view->setContext$this->defaultContext); call that determines what context should be used for the response.
FUCK ME WHY DID IT TAKE SO FUCKING LONG TO FIGURE THAT OUT OMG
Google you say? Ofcourse I hunted google results! But I was unknowingly part of an XY problem and was looking for what the problem wasn't >:(
At least it works now, ugh1 -
Ok, guys, which configuration format is your favorite? (something like toml, ini, json, yaml, etc)28
-
I upgraded a Linux server one time and data that was serialized in yaml stopped being parsed properly.
It turns out the libyaml people decided to change how hashes were handled, which made any previous hashes come back as blank.
A whole database of valid data in dev was coming back invalid in prod. It was maddening.
It took a day to figure out the problem and how to update the data to the new format in rails.
I now serialize in json.11 -
TIL, YAML was originally named Yet Another Markup Language and then renamed to YAML Ain’t Markup Language.
Nice. -
Spent a little more than an a hour trying to figure out why an octopus deployment tool isn't picking up my project definitions.
Called a colleague to help me, as I explain the situation to him I find out that I created *.yaml files instead of *.yml
Wtf brain! Y u do this brain?1 -
Today i chartered new realms for me.
I created a new hyper-v vm on the company windows servers and added a 5th instance to it, but instead of running another windows server i installed an ubuntu 18.04 (cause i am a bit familiar with debian from my raspberry pi)
we have two servers, one which runs the 4 vms and a replica. I first had the new vm on the main server but it occured me to move it instead to the unusued replica machine. That kinda worked..i did a planned failover but the main server isnt configured to be the replica..and even when activating that it didnt work. This is weird.
For the moment i ignored that and proceeded to install nginx, mariadb and php 7.2..basically the lemp stack. I managed to setup nginx and a static ip adress for the machine (which was different from how i remembered it to do (in 18.04 its not done with the network conf but a yaml file).
in the end i added two different virtual servers, one for actual use and one for dev stuff (with phpmyadmin running for instance), listening on port 80 and some random other port.
as a test i brought a mediawiki onto the Port 80 server and it worked.
on monday i have to figure out how to implement the wildcard certificate i have for our company domain (internal dns simply routes intranet.company.com to the local server vm)
i am mighty proud cause all my experience with linux was with a raspberry pi so far and i am fairly certain i did it right and without shortcuts this time. (unlike my raspberry experience)
just wanted to share
(i also sweated a lot of blood when editing the hyper v settings as i did not set up the server in the first place)
((i also installed xrdp and a mate desktop, but i am less proud of that, but sometimes seeing folders graphically helps me)) -
Hey Java Devs, Snakeyaml is trolling us all. For their parser you must use spaces for indentation.
We say TAB, they say TOO BAD. #ForcedConvention1 -
A very long rant.. but I'm looking to share some experiences, maybe a different perspective.. huge changes at the company.
So my company is starting our microservices journey (we have a 359 retail websites at this moment)
First question was: What to build first?
The first thing we had to do was to decide what we wanted to build as our first microservice. We went looking for a microservice that can be used read only, consumers could easily implement without overhauling production software and is isolated from other processes.
We’ve ended up with building a catalog service as our first microservice. That catalog service provides consumers of the microservice information of our catalog and its most essential information about items in the catalog.
By starting with building the catalog service the team could focus on building the microservice without any time pressure. The initial functionalities of the catalog service were being created to replace existing functionality which were working fine.
Because we choose such an isolated functionality we were able to introduce the new catalog service into production step by step. Instead of replacing the search functionality of the webshops using a big-bang approach, we choose A/B split testing to measure our changes and gradually increase the load of the microservice.
Next step: Choosing a datastore
The search engine that was in production when we started this project was making user of Solr. Due to the use of Lucene it was performing very well as a search engine, but from engineering perspective it lacked some functionalities. It came short if you wanted to run it in a cluster environment, configuring it was hard and not user friendly and last but not least, development of Solr seemed to be grinded to a halt.
Elasticsearch started entering the scene as a competitor for Solr and brought interesting features. Still using Lucene, which we were happy with, it was build with clustering in mind and being provided out of the box. Managing Elasticsearch was easy since there are REST APIs for configuration and as a fallback there are YAML configurations available.
We decided to use Elasticsearch since it provides us the strengths and capabilities of Lucene with the added joy of easy configuration, clustering and a lively community driving the project.
Even bigger challenge? Which programming language will we use
The team responsible for developing this first microservice consists out of a group web developers. So when looking for a programming language for the microservice, we went searching for a language close to their hearts and expertise. At that time a typical web developer at least had knowledge of PHP and Javascript.
What we’ve noticed during researching various languages is that almost all actions done by the catalog service will boil down to the following paradigm:
- Execute a HTTP call to fetch some JSON
- Transform JSON to a desired output
- Respond with the transformed JSON
Actions that easily can be done in a parallel and asynchronous manner and mainly consists out of transforming JSON from the source to a desired output. The programming language used for the catalog service should hold strong qualifications for those kind of actions.
Another thing to notice is that some functionalities that will be built using the catalog service will result into a high level of concurrent requests. For example the type-ahead functionality will trigger several requests to the catalog service per usage of a user.
To us, PHP and .NET at that time weren’t sufficient enough to us for building the catalog service based on the requirements we’ve set. Eventually we’ve decided to use Node.js which is better suited for the things we are looking for as described earlier. Node.js provides a non-blocking I/O model and being event driven helps us developing a high performance microservice.
The leap to start programming Node.js is relatively small since it basically is Javascript. A language that is familiar for the developers around that time. While Node.js is displaying some new concepts it is relatively easy for a developer to start using it.
The beauty of microservices and the isolation it provides, is that you can choose the best tool for that particular microservice. Not all microservices will be developed using Node.js and Elasticsearch. All kinds of combinations might arise and this is what makes the microservices architecture so flexible.
Even when Node.js or Elasticsearch turns out to be a bad choice for the catalog service it is relatively easy to switch that choice for magic ‘X’ or component ‘Z’. By focussing on creating a solid API the components that are driving that API don’t matter that much. It should do what you ask of it and when it is lacking you just replace it.
Many more headaches to come later this year ;)3 -
After couiple of hours (Yes, apprently it's insane how hard is to add a new NIC to a linux machine and make it start on boot), I finally got my connexion working !
Story :
Server has original MB 1Gbits card. Internet connexion is 1.1 Gbps. So 1Gb card only picked at 940 Mbits download
I bought a 2.5 Gb card (new nic)
Pluged it in : Nothing
Couple of ifconfig -a etc, bring device UP : Yeah working !
Reboot : Nothing
/etc/interfaces : nothing
And why it's not eth0 and eth1 etc as before but some thing cryptic like enp3s0.
Well, at least now everything working (Apperently there is a new "network plan" config file in yaml... what a waste, DO FUCKING JSON YOU RETARDS)
Ping is awsome tho ! Same cable on windows Machine, I get 5 ms.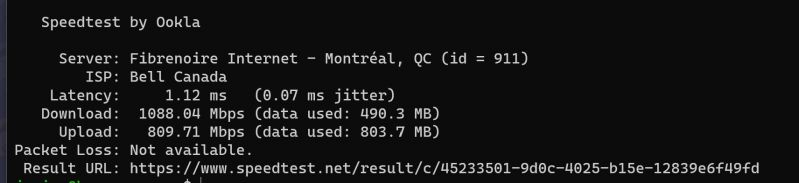 4
4 -
This is an actual transcript...
Since it's way too long for the normal 5000 characters, hence splitting it up...
Infra Guy: mr Dev, could you please give some rational for update of jjb?
Dev: sparse checkout support is missing
Infra Guy: is this support mandatory to achive whatever you trying to do?
Dev: yes
Infra Guy: u trying to get set of specific folder for set of specific components?
Dev: yes
Infra Guy: bash script with cp or mv will not work for you?
Dev: no
Infra Guy: ?
Dev: when you have already present functionality why reinvent the wheel
Dev: jenkins has support for it
Dev: the jjb is the bottle neck
Infra Guy: getting this functionality onto our infra would have some implications
Dev: why should I write bash script if jenkins allows me to do that
Dev: what implications ??
Infra Guy: will you commit to solve all the issues caused by new jjb?
Dev: you show me the implications first
Infra Guy: like a year ago i have tried to get new jjb <commit_url>
Infra Guy: no, the implications is a grey area
Infra Guy: i cant show all of them and they may hit like in week or eve month
Dev: then why was it not tackled
Dev: and why was it kept like that
Infra Guy: few jobs got broken on something
Dev: it will crop up some time later
Dev: if jobs get broken because of syntax
Dev: then jobs can be fixed
Dev: is it not ???
Infra Guy: ofc
Infra Guy: its just a question who will fix them
Dev: follow the syntax and follow the guidelines
Dev: put up a test server and try and lets see
Dev: you have a dev server
Dev: why not try on that one and see what all jobs fails
Dev: and why they fail
Dev: rather than saying it will fail and who will fix
Dev: let them fail and then lets find why
Dev: I manually define a job
Dev: I get it done
Infra Guy: i dont think we have test server which have the same workload and same attention as our prod
Dev: unless you test how would you know ??
Dev: and just saying that it broke one with a version hence I wont do it
Infra Guy: and im not sure if thats fair for us to deal with implication of upgrading of the major components just cause bash script is not good enough for u
Dev: its pretty bad
Infra Guy: i do agree
Infra TL Guy: Dev, what Infra Guy is saying is that its not possible to upgrade without downtime
Infra Guy: no
Dev: how long a downtime are we looking at ??
Infra Guy: im saying that after this upgrade we will have deal with consequences for long time
Infra Guy-2: No this is not testing the upgrade is the huge effort as we dont have dev resources to handle each job to run
Dev: if your jjb compiles all the yaml without error
Dev: I am not sure what consequences are we talking of
Infra Guy: so you think there will be no consequences, right?
Dev: unless you take the plunge will you know ??
Dev: you have a dev server running at port 9000
Infra Guy: this servers runs nothing
Dev: that is good
Dev: there you can take the risk
Infra Guy: and the fack we have managed to put something onto api doesnt mean it works
Dev: what API ?
Infra Guy: jenkins api
Infra Guy: hmmm
Dev: what have you put on Jenkins API ??
Infra Guy: (
Dev: jjb is a CLI
Infra Guy: ((
Dev: is what I understand
Dev: not a Jenkins API
Infra Guy: (((
Dev: (((((
Infra Guy: jjb build xmls and push them onto api
Infra Guy: and its doent matter
Dev: so you mean to say upgrading a CLI is goig to upgrade your core jenkisn API
Dev: give me a break
Infra Guy: the matter is that even if have managed to build something and put it onto api
Infra Guy: doesnt mean it will work
Dev: the API consumes the xml file and creates a job
Infra Guy: right
Dev: if it confirms to the options which it understands
Dev: then everything will work
Dev: I am actually not getting your point Infra Guy
Infra Guy: i do agree mr Dev
Dev: we are beating around the bush
Infra Guy: just want to be sure that if this upgrade will break something
Infra Guy: we will have a person who will fix it
Dev: that is what CICD is supposed to let me know with valid reasons
Dev: why can't that upgrade be done
Infra Guy: it can be done
Infra Guy: i even have commit in place3 -
i am terrible at using swagger autogenerated code, yaml and swagger files
dont fucking false positive pass, tell me if theres indenting wrong
also why the fuck wont you generate the code im trying to get you to generate
i fucking hate you so much, ive done this once before what am i doing wrong now -
I am going to start a random stuff from dev life diary just for your annoyance… cause I’m bored (and kind of want to see how long I can be bothered to keep shit like this going)
So, work day 1 for 2022. Wrote TS and YAML. Yay, IaC is fun. Also, no one has bothered me with dms or calls or any such shite today, which is the way I like it. Leave me be, mofos!
Should still bother to prepare all the shit for tomorrow’s PoC spec planning workshop… what a chore. Couldn’t be bothered, I’d much rather someone else did the specs and I could skip to design and implementation. But I guess this is yet another context where I have to do it all myself. Woo hoo…2 -
Protip:
If you start every YAML file with 400 spaces, you can check whether two keys are on the same level by shift-scrolling until one is at the left edge of the screen.1 -
Salt is awesome, no questions about that. YAML is giving me headaches, but it's my fault and eventually I'll get used to it. But this being my first encounter with jinja, WHO THE HELL THOUGHT THIS PIECE OF CRAP DESERVES TO LIVE! Instead of writing python inside {% %} you have to write kinda pseudo python and I just spend over hour trying to build list inside for. Yes, great idea, scoping fors, and lets make it hard to escape scoping, beacause it would be a shame if somebody COULD ACTUALLY DO SOMETHING USEFULL. I though several times of using different renderer, but I want to keep my code readable and mainrainable and in the end I found a workaround, but still, Jinja, YOU SUCK!4
-
I come from a simple html, css background with a bit knowledge in php and some simple cms.
Decided to use a modern cms to learn something new... -
Making distributed scheduler that queue and run tasks on containers or other executors in future and also pulls new tasks from defined git repositories.
Tasks are added based on simple yaml configuration.
Need that for my side projects that gather data from multiple sources from time to time.
k8s looks to heavy for that and airflow can’t be configured like I want it to be so I started writing my own on Monday.
Nearly finished poc version.2 -
Using CodeWriter (the one from windows store) since a few days for small tasks (like editing an xml or yaml etc) and i like it.
Yep vim guys, u hate me now, but idc ^^ -
The Ankmocker Package for flutter
Mock your api offline by specifying the fields of your class as well their types.
You can also generate standalone data to test the limits of your UI
Installation very easy because it is a simple file that you just copy and paste in your project
No yaml required
No dependencies
Work with all versions of dart
Github link
https://github.com/Afrographic/...
Don't forget to share and support the project if you find it useful.
Happy coding 🙂 1
1 -
PowerShell - Why do you need separate modules for reading and writing YAML? Spent half a day trying to merge to GitHub projects to support ConvertFrom-YAML and ConvertTo-YAML
-
So I recently started a new position as a Node JS dev, and on my first day I've been assigned to the DevOps team... The offer and the interview had me believe I was going to be actually writing code not config and yaml files5
-
So this is more like an accident rather than a dissapointment but the thing goes like this.
I make multivariant stacks with vagrant, shell script loaded as stated in yaml config and every bit and piece done from there the only times it disapointed me was the first time i lost it and when i got asked to make it tomcat compatible, not that the person really needed tomcat but just because i called it a stack initialiser it must have tomcat support. -
F***ing GitHub Actions.
I just wanted to make Snapcraft builds of my game with CI and instead I'm fiddling around with YAML syntax because for some reason everything got formatted incorrectly.
Also I have no way of testing the workflow locally to save me commits. So I have to wait five minutes each time to find out that I yet again somehow mucked up the script and it couldn't snap the executable.7 -
is laravel app really enjoyable to write ?
i started as a laravel dev. the known story , all code in controllers etc. As i started to improve, fortunately i changed company, and worked with a symfony project. A symfony that looked like java. hundreds of classes, tests, yaml injections , objects for requests, for everything.
I thought that i missed the old laravel days, and i took an extra job on laravel again. I was soooo wrong.
It was not only that the code of the previous dev was inferior to what i am now used, it is that i have to be with an open documentation all the time. Even if the project is in the same version that i have used to earlier (an old one).
You have to check all the time the model settings, the migration, the magic tricks of model mass insert, the castings, the validation rules, why the tests are not finding some routes, why this, why that, how it is written this.
Excuse me, but i think the fun and easiness is far from what they say and what i thought it was. I start to change my mind and believe that inserting the request to a simple php object is more controllable than the gandalf tricks that laravel is doing, and you cannot know if it is worth your time to test it . And more importantly, you do not have to look at the cookbook, all the time@@@5 -
I'm gonna do it, no one can stop me! I will do it now, I will create yet another file format using YAML for Biblical software!!2
-
I've been thinking about ways to improve my workflow for my personal projects.
I'm getting to grips with continuous integration and deployment etc, but I want to also automate, or at least semi automate my changeling generation.
I don't like using any sort of gitlog shenanigans, and I quite like the girls way of doing it.
I.e you run a script which generates a yaml file with your changeling info in, and then all the files are written into the changelog.md file.
How do you guys handle the generation of your changelings?3 -
Ok... I am defeated I don't know what else to try...
Do you guys have any experience with ansible vault? I have my SSH password stored on a vault. It's referenced in my host file like this:
-----START SNIPPET-----
[LCL:vars]
ansible_ssh_pass='{default_pass}'
[LCL]
myhost ansible_user=my username
-----END SNIPPET-----
default_pass is stored as a yaml variable in passed.yml that I supply using --extra-vars '@passwd.yml'
When I enter my vault password I get an exception 'non hexadecimal digit found'.
The password is right for the vault, the vault file is in PWD .... I cannot find anything helpful.
Any ideas?1 -
Anyone herr tried API Platform?
I know I know. Generic ass name but that is what the framework is called.
Its in php, it contains a lot of goodies from(try and guess...no?? Ok I'll tell ya) the Symfony platform(go figure right) so if you are familiar with Laravel or well....Symfony then I guess that you will be good to go. I ain't...so fuck me because I only know Laravel.
Either way the concepts are very simple. Configs is donde almost entirely with YAML, i dunno how to feel about that, not used at writing routes on yaml, but the framework is thus far quite powerful. About to test jwt auth so wish me luck!4 -
#Suphle Rant 6: Deptrac, phparkitect
This entry isn't necessarily a rant but a tale of victory. I'm no more as sad as I used to be. I don't work as hard as I used to, so lesser challenges to frustrate my life. On top of that, I'm not bitter about the pace of progress. I'm at a state of contentment regarding Suphle's release
An opportunity to gain publicity presented itself last month when cfp for a php event was announced last month. I submitted and reviewed a post introducing suphle to the community. In the post, I assured readers that I won't be changing anything soon ie the apis are cast in stone. Then php 7.4 officially "went out of circulation". It hit me that even though the code supports php 8 on paper, it's kind of a red herring that decorators don't use php 8 attributes. So I doubled down, suspending documentation.
The container won't support union and intersection types cuz I dislike the ambiguity. Enums can't be hydrated. So I refactored implementation and usages of decorators from interfaces to native attributes. Tried automating typing for all class properties but psalm is using docblocks instead of native typing. So I disabled it and am doing it by hand whenever something takes me to an unfixed class (difficulty: 1). But the good news is, we are php 8 compliant as anybody can ask for!
I decided to ride that wave and implement other things that have been bothering me:
1) 2 commands for automating project setup for collaborators and user facing developers (CHECK)
2) transferring some operations from runtime to compile/build TIME (CHECK)
3) re-attempt implementing container scopes
I tried automating Deptrac usage ie adding the newly created module to the list of regulated architectural layers but their config is in yaml, so I moved to phparkitect which uses php to set the rules. I still can't find a library for programmatically updating php filed/classes but this is more dynamic for me than yaml. I set out to implement their library, turns out the entire logic is dumped into the command class, so I can neither control it without the cli or automate tests to it. I take the command apart, connect it to suphle and run. Guess what, it detects class parents as violations to the rule. Wtflyingfuck?!
As if that's not bad enough, roadrunner (that old biatch!) server setup doesn't fail if an initialization script fails. If initialization script is moved to the application code itself, server setup crumbles and takes the your initialization stuff down with it. I ping the maintainer, rustacian (god bless his soul), who informs me point blank that what I'm trying to do is not possible. Fuck it. I have to write a wrapper command for sequentially starting the server (or not starting if initialization operations don't all succeed).
Legitimate case to reinvent the wheel. I restored my deleted decorators that did dependency sanitation for me at runtime. The remaining piece of the puzzle was a recursive film iterator to feed the decorators. I checked my file system reader for clues on how to implement one and boom! The one I'd written for two other features was compatible. All I had to do was refactor decorators into dependency rules, give them fancy interfaces for customising and filtering what classes each rule should actually evaluate. In a night's work (if you're discrediting how long writing the original sanitization decorators and directory iterator), I coupled the Deptrac/phparkitect library of my dreams. This is one of the those few times I feel like a supreme deity
Hope I can eat better and get some sleep. This meme is me after getting bounced by those three library rejections
-
My colleague is trying out docker for the first time. He is installing stuff so that he can add the same steps to gitlab yaml. I will like to see his reaction when he will start the container next time.
Waiting now and hoping that he will save the container. -
Trying to migrate an app from Dropwi Card to Spring Boot but can't get the YAML config read in correctly.
It's not reading the objects/lists/maps
Just treating each line as a key value.
Spring Boot says it sorts YAML configs and one seen some projects use this without issue.
But don't know how to turn it on.
Tried a lot of @*Config* all over the project but doesn't work.
Eventually just checked what Main.java loaded in the App context and well basically it never parsed it correctly...3 -
Was generating a JSON based config manually to be used by a script another dev wrote - only to be criticized for using the text editors built in formatter. Evidently lining up the colon separating key value pairs is a thing.
If readability was so important to you why the fuck did you decide on using JSON as a configuration format? Especially when you could have gone with YAML or better yet INI (flat key/value pairs) style config.

































































Top Tags
Weekly Rant
View