
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Guys check out devRant CUI
https://github.com/Jay9596/...
Very buggy at the moment, but can be used to browse rants,stories,etc. 25
25 -
- Free app:
"5 stars - OMG this app is awesome!!!"
- Add new feature with In-app purchase:
"1 star - App sucks balls. Why we must pay? Make free and I rate 5 stars"
I call them The Rating Terrorists.8 -
A human cell has 75MB of DNA information, a sperm cell has half A human cell has 75MB of DNA of it 37.5MB, a milliliter of semen has 100 million sperm cels, on average, a ejaculation lasts 5 seconds and has 2.24 milliliters of Semen.
That means a man is able to produce: 37.5MB x 100,000, 000 x 2.25/5 = 1.687.500,000.000.000 bytes/sec 1,6875 Terabytes/sec;
That means a ovule is able to recive a dDOS attack of 1,6 terabytes per second and only lets one package pass, making it THE BEST FIREWALL IN THE WORLD6 -
Latest facebook for iOS update is 219 mega-fucking-bytes. Yet, no real changelog to tell me what da fuck changed!!!!!! Fuck that developer for real!!!
 14
14 -
Found this gem on GitHub:
// At this point, I'd like to take a moment to speak to you about the Adobe PSD format.
// PSD is not a good format. PSD is not even a bad format. Calling it such would be an
// insult to other bad formats, such as PCX or JPEG. No, PSD is an abysmal format. Having
// worked on this code for several weeks now, my hate for PSD has grown to a raging fire
// that burns with the fierce passion of a million suns.
// If there are two different ways of doing something, PSD will do both, in different
// places. It will then make up three more ways no sane human would think of, and do those
// too. PSD makes inconsistency an art form. Why, for instance, did it suddenly decide
// that *these* particular chunks should be aligned to four bytes, and that this alignement
// should *not* be included in the size? Other chunks in other places are either unaligned,
// or aligned with the alignment included in the size. Here, though, it is not included.
// Either one of these three behaviours would be fine. A sane format would pick one. PSD,
// of course, uses all three, and more.
// Trying to get data out of a PSD file is like trying to find something in the attic of
// your eccentric old uncle who died in a freak freshwater shark attack on his 58th
// birthday. That last detail may not be important for the purposes of the simile, but
// at this point I am spending a lot of time imagining amusing fates for the people
// responsible for this Rube Goldberg of a file format.
// Earlier, I tried to get a hold of the latest specs for the PSD file format. To do this,
// I had to apply to them for permission to apply to them to have them consider sending
// me this sacred tome. This would have involved faxing them a copy of some document or
// other, probably signed in blood. I can only imagine that they make this process so
// difficult because they are intensely ashamed of having created this abomination. I
// was naturally not gullible enough to go through with this procedure, but if I had done
// so, I would have printed out every single page of the spec, and set them all on fire.
// Were it within my power, I would gather every single copy of those specs, and launch
// them on a spaceship directly into the sun.
//
// PSD is not my favourite file format.
Ref : https://github.com/zepouet/...16 -
Did the Kali repos get pwned? Updated to kernel 5.3.0 and rebooted to this. File is 8 bytes, contains just "fuck you".
 21
21 -
Eight bytes walk into a bar. The bartender asks, “Can I get you anything?”
“Yeah,” reply the bytes. “Make us a double.”5 -
@dfox @trogus How about ++ milestones?
F.e.:
404 ++'s: “Error 404“
255 ++'s: “256 Bytes“
69 ++'s: (Well you know...)
And so on... (be creative)20 -
My wife asked me to give her some cash.
I asked how many bytes!
I'm staring at divorce papers now.8 -
1. There are 10 types of people in the world: those who understand binary, and those who don't.
2. How many programmers does it take to change a light bulb?
None. It's a hardware problem.
3. A SEO couple had twins. For the first time they were happy with duplicate content.
4. Why is it that programmers always confuse Halloween with Christmas?
Because 31 OCT = 25 DEC
5. Why do they call it hyper text?
Too much JAVA.
6. Why was the JavaScript developer sad?
Because he didn't Node how to Express himself
7. In order to understand recursion you must first understand recursion.
8. Why do Java developers wear glasses? Because they can't C#
9. What do you call 8 hobbits?
A hobbyte
10. Why did the developer go broke?
Because he used up all his cache
11. Why did the geek add body { padding-top: 1000px; } to his Facebook profile?
He wanted to keep a low profile.
12. An SEO expert walks into a bar, bars, pub, tavern, public house, Irish pub, drinks, beer, alcohol
13. I would tell you a UDP joke, but you might not get it.
14. 8 bytes walk into a bar, the bartenders asks "What will it be?"
One of them says, "Make us a double."
15. Two bytes meet. The first byte asks, "Are you ill?"
The second byte replies, "No, just feeling a bit off."
16. These two strings walk into a bar and sit down. The bartender says, "So what'll it be?"
The first string says, "I think I'll have a beer quag fulk boorg jdk^CjfdLk jk3s d#f67howe%^U r89nvy~~owmc63^Dz x.xvcu"
"Please excuse my friend," the second string says, "He isn't null-terminated."
17. "Knock, knock. Who's there?"
very long pause...
"Java."
18. If you put a million monkeys on a million keyboards, one of them will eventually write a Java program. The rest of them will write Perl programs.
19. There's a band called 1023MB. They haven't had any gigs yet.
20. There are only two hard things in computer science: cache invalidation, naming things, and off-by-one errors.10 -
Story about an obscure bug: https://twitter.com/mmalex/status/...
"We had a ‘fun’ one on LittleBigPlanet 1: 2 weeks to gold, a Japanese QA tester started reliably crashing the game by leaving it on over night. We could not repro. Like you, days of confirmation of identical environment, os, hardware, etc; each attempt took over 24h, plus time differences, and still no repro.
"Eventually we realised they had an eye toy plugged in, and set to record audio (that took 2 days of iterating) still no joy.
"Finally we noticed the crash was always around 4am. Why? What happened only in Japan at 4am? We begged to find out.
"Eventually the answer came: cleaners arrived. They were more thorough than our cleaners! One hour of vacuuming near the eye toy- white noise- caused the in game chat audio compression to leak a few bytes of memory (only with white noise). Long enough? Crash.
"Our final repro: radios tuned to noise, turned up, and we could reliably crash the game. Fix took 5 minutes after that. Oh, gamedev...."5 -
Watching the Dutch government trying to get through the public procurement process for a "corona app" is equal parts hilarious and terrifying.
7 large IT firms screaming that they're going to make the perfect app.
Presentations with happy guitar strumming advertisement videos about how everyone will feel healthy, picnicking on green sunny meadows with laughing families, if only their app is installed on every citizen's phone.
Luckily, also plenty of security and privacy experts completely body-bagging these firms.
"It will connect people to fight this disease together" -- "BUT HOW" -- "The magic of Bluetooth. And maybe... machine learning. Oh! And blockchain!" -- "BUT HOW" -- "Shut up give us money, we promise, our app is going to cure the planet"
You got salesmen, promising their app will be ready in 2 weeks, although they can't even show any screenshots yet.
You got politicians mispronouncing technical terminology, trying hard to look as informed as possible.
You got TV presenters polling population support for "The App" by interviewing the most digitally oblivious people.
One of the app development firms (using some blockchain-based crap) promised transparency about their source code for auditing.... so they committed their source, including a backup file from one of their other apps, containing 200 emails/passwords to Github.
It's kind of entertaining... in the same way as a surgery documentary about the removal of glass shards from a sexually adventurous guy's butthole.
Imma keep watching out of morbid fascination.... from a very safe distance, far away from the blood and shit that's splattering against the walls.
And my phone -- keep your filthy infected bytes away from my sweet baby.
I'll stick with social distancing, regular hand washing, working from home and limited supermarket trips, thank you very much.26 -
Wow, what a fucking mess this sunday was.
My boss wrote me an email that one route of a RESTful API we wrote for a customer was not working anymore and puking back a status 500 with some error mentioning invalid UTF-8 characters.
Not one single person has had touched nor changed the code on production in some 6 months, so what the fuck could it be?
Phpunit did not give any errors (running only locally), the code had no syntax errors and the DB dump did not contain any invalid bytes (tested with a hex editor).
WHAT THE FUCK?!
OK so I started to comment out lines (all tested directly on production of course) until the error vanished.
Guess what was the culprit?
.
.
.
.
.
.
In the code (PHP) we used strftime(...) to get nice time strings. Of course we set the correct locale on the server, thus having months and days formatted in German.
So, in Geman there is this one mysterious month called "März" which contains an umlaut character.
Calling strftime generated the date with März in it, but the server locale was de_CH.iso-8859-1 and not fucking de_CH.utf8, so the "ä" was returned as 0xE4 instead of 0xC3A4 (valid UTF-8), which json_encode(...) did not want to swallow but instead threw an exception.8 -
WOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO
IT WORKS AFTER 3 HOURS!
YEEEEEEEEEEEAAAAAAAAAAAAAAAAAAAAAAAAAHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH6 -
I find it funny how so many people still do not know that 1 kilobyte is just 1000 bytes and not 1024 bytes!
That's a KibiByte!
Guys, kilo means 10^3, always! Always!23 -
People, please understand
1GB != 1024MB
1GB == 1000MB
1GiB != 1024MB
1GiB == 1024MiB
The MebiByte, GibiByte, KibiByte and others "biByte"s were defined at the end of XX century. How can be possible that people (I mean people which study/teach informatics, electronics or something similar) still don't know what is it?16 -
Did you know?
This rant is a part of the 3 quintillion bytes of data that the world generated today.8 -
*wrestling commentator voice*
"In this weeks episode of encoding hell:
The iiiinnnfamous UTF-8 Byte Order Mark veeeersus PHP!"
For an online shop we developed, there is currently a CSV upload feature in review by our client. Before we developed this feature, we created together with the client a very precise specification, including the file format and encoding (UTF-8).
After the first test day, the client informed us, that there were invalid characters after processing the uploaded file.
We checked the code and compared the customer's file with our template.
The file was encoded in ISO-8859-1 and NOT as specified UTF-8.
But what ever, we had to add an encoding check, thus allowing both encodings from now on.
Well well well welly welly fucking well...
Test day 2: We receive an email from said client, that the CSV is not working, again.
This time: UTF-8 encoding, but some fields had more colums with different values than specified.
Fucking hell.
We tell the customer that.
(I was about to write a nice death threat novel to them, but my boss held me back)
Testing day 3, today:
"The uploading feature is not working with our file, please fix it."
I tried to debug it, but only got misleading errors. After about 30 minutes, at 20 stacks of hatered, I finally had an idea to check the file in a hex editor:
God fucking what!?!!?!11?!1!!!?2!!
The encoding was valid UTF-8, all columns and fields were correct, but this time the file contained somthing different.
Something the world does not need.
Something nearly as wasteful as driving a monster truck in first gear from NYC to LA.
It was the UTF-8 Byte Order Mark.
3 bytes of pure hell.
Fucking 0xEFBBBF.
The archenemy of PHP and sane people.
If the devil had sex with the ethernet port of a rusty Mac OS X Server, then 9 microseconds later a UTF-8 BOM would have been born.
OK, maybe if PHP would actually cope with these bytes of death without crashing, that would be great.3 -
There's this one Windows PC, hiding in the darkest corner of the office, just running a network service all day. Suddenly the service is not available any longer... Opening explorer.exe to see what's up with the machine, while wiping a thick layer of dust from the screen: Zero bytes free memory on C:\ ...
Assuming that some log files have caused all the occupied space. NOPE! Instead, Windows update just installed a shitton of updates. They all failed, of course... After not being able to simply remove them, deciding to uninstall some programs and kill Windows update. Finally 800MB of free space!
Suddenly stumbling over a Visual Studio 2008 installation. Who the hell installed this on the PC? Absolute bullshit. Nevermind. Uninstall this shite.
The uninstaller takes ages to do anything, then aborts the uninstallation showing the popup "there is not enough space to uninstall". Looking into the memory indicator: 0 bytes left. DAAAAFUUUQ Microsoft??? WTFFFFFFF?!? 800MB to UNINSTALL Visual Studio? Are you for real???
Ended up force-deleting the directory: 3 Gigs free now... 5
5 -
So I've been exporting a JSON dump of ~120GB for hours and when trying to processing it, and write it to a new file, I wrote to the same file. FML. Hours of export became 0 bytes in no time. Think its time to get some sleep.4
-
ARGH. I wrote a long rant containing a bunch of gems from the codebase at @work, and lost it.
I'll summarize the few I remember.
First, the cliche:
if (x == true) { return true; } else { return false; };
Seriously written (more than once) by the "legendary" devs themselves.
Then, lots of typos in constants (and methods, and comments, and ...) like:
SMD_AGENT_SHCEDULE_XYZ = '5-year-old-typo'
and gems like:
def hot_garbage
magic = [nil, '']
magic = [0, nil] if something_something
success = other_method_that_returns_nothing(magic)
if success == true
return true # signal success
end
end
^ That one is from our glorious self-proclaimed leader / "engineering director" / the junior dev thundercunt on a power trip. Good stuff.
Next up are a few of my personal favorites:
Report.run_every 4.hours # Every 6 hours
Daemon.run_at_hour 6 # Daily at 8am
LANG_ENGLISH = :en
LANG_SPANISH = :sp # because fuck standards, right?
And for design decisions...
The code was supposed to support multiple currencies, but just disregards them and sets a hardcoded 'usd' instead -- and the system stores that string on literally hundreds of millions of records, often multiple times too (e.g. for payment, display fees, etc). and! AND! IT'S ALWAYS A FUCKING VARCHAR(255)! So a single payment record uses 768 bytes to store 'usd' 'usd' 'usd'
I'd mention the design decisions that led to the 35 second minimum pay API response time (often 55 sec), but i don't remember the details well enough.
Also:
The senior devs can get pretty much anything through code review. So can the dev accountants. and ... well, pretty much everyone else. Seriously, i have absolutely no idea how all of this shit managed to get published.
But speaking of code reviews: Some security holes are allowed through because (and i quote) "they already exist elsewhere in the codebase." You can't make this up.
Oh, and another!
In a feature that merges two user objects and all their data, there's a method to generate a unique ID. It concatenates 12 random numbers (one at a time, ofc) then checks the database to see if that id already exists. It tries this 20 times, and uses the first unique one... or falls through and uses its last attempt. This ofc leads to collisions, and those collisions are messy and require a db rollback to fix. gg. This was written by the "legendary" dev himself, replete with his signature single-letter variable names. I brought it up and he laughed it off, saying the collisions have been rare enough it doesn't really matter so he won't fix it.
Yep, it's garbage all the way down.16 -
What's the difference between a wasp and single loose hair?
Apparently none till the wasp stings :/
Yesterday I thought I had a loose hair on my neck.. ok, I shrug it off.. later again the creepy feeling.. shrugs off..
I continue to work, sumberged in code, wanting to find the fucker (bug, not the wasp/hair).. lean in to the monitor... 10 cents away from the screen... Ok, maybe that's it! Feels the hair on my back, near shoulderblades again... shrugging again more violently to get it further down to fall out.. nothing.. ok, got the bug, threw myslef back in the chair with substential force & BAAAAM!!! Motherfucking hair bit me!! O.o
I scream in horror & on top of the lungs (it was late, after work hours so I didn't expect anyone else still at the office) PROKLETA PRASICA (roughly translated to goddamn female swine).. I previously saw some green bug flying around the office and I thought that nasty thing bit me (didn't know they bite soo, much more horror for me).. O.o
Anyhow, I jump up from the computer and see my coworker looking at me all baffled.. I proceed to franticly take of my headphones and hoodie..thinking about wtf should I do now, I cannot get undressed in front of him (not for my sake, bra is the same as top of the bathing suit for me, but still..I don't want anyone suing me for impropper behaviour of undreasing in front of coworkers..), how the fuck should I get to the toilet?! O.o
C: Are you ok?!
M: Um.. sth bit me..wtf?!
C: There was a wasp flying around somewhere some time ago.. are you alergic?!
M: um..not sure, I don't think so..we'll see soon..
I proceed to the WC, to take off tshirt & check/kill off the fucker.. on my way there (walking funny to not press the hair to my body again) I got another surprise, another coworker was working late..
C2: Are you ok?! O.o
M: yeah, sth bit me, probably a wasp..
Ok, finally on the loo..ok, do not lock self in in case it escapes and you need help.. don't even shut the door. Check.. standing between the doors I contemplate on how the fuck should I take my tshirt off without angering the fucker even more and getting bitten again.. O.O
I lifted the tshirt up my back to let it out.. nope, not there..the creepy felling of buzzing around between my shoulder blades continues.. crap.. what to do?!
I stood there & contemplated the task.. ok, roll up the tshirt to the shoulder blades, not against the body (duh) to prevent further stings..tighten the fabric, so it cannot escape, quickly remove the band from the body.. done..reversed the tshirt and straightened it.. bzzz... Fucker fell somewhere.. Dafaq?! Was it really just a wasp?! If yes, no problem...but what if coworker was wrong and I got bitten by that nasty green whateveritsname bug?! Eeeeewwww! Is it poisonous? Gotta find it & kill it for good.. waited a bit, than saw a goddamn wasp crawl from under the toilet.. wasp!! Yess!! Stopm stomp fucker!!
I get dressed & go back to my desk..
C: Did you terminate it?!
M: Yup, fucker went on a toilet paper trip down the drain!!
I sit down, starting to get my headphones back on and proceed to work.., but before I could, one last gem:
C: CTO would say, thank god it didn't sting you in your finger cuz you wouldn't be able to type anymore..
M: O.O so true hahhahahaaa
Disclaimer - I like animals, but I freakking hate wasps..especially if they get under my tshirt to sting.. :/7 -
I swear I work with mentally deranged lunatics.
Dev is/was using TFS's web api to read some config stuff..
Ralph: "Ugh..this is driving me crazy. I've spent all day trying to read this string from TFS and it is not working"
Me: "Um, reading a string from an web api is pretty easy, what's the problem?"
Ralph: "I'm executing the call in a 'using' statement and cannot return the stream."
Me: "Why do you need to return a stream? Return the object you are looking for."
Ralph: "Its not that easy. You can return anything from TFS. All you get back is a stream. Could be XML, JSON, text file, image, anything."
Me: "What are you trying to return?"
Ralph: "XML config. If I use XDoc, the stream works fine, but when I step into each byte from the stream, I the first three bytes have weird characters. I shouldn't have to skip the first three bytes to get the data. I spent maybe 5 hours yesterday digging around the .Net stream readers used in XDoc trying to figure out how it skips the first few bytes."
Me: "Wow...I would have used XDoc and been done and not worried about that other junk."
Ralph: "But I don't know the stream is XML. That's what I need to figure out."
Me: "What is there to figure out? You do know. Its your request. You are requesting a XML config."
Ralph: "No, the request can be anything. What if Sam requests an image? XDoc isn't going to work."
Me: "Is that a use-case? Sam requesting an image?"
Ralph: "Uh..I don't know...he could"
Me: "Sounds like your spending a lot of time doing premature optimization. You know what your accessing TFS for, if it's XML, return XML. If it's an image, return an image. Something new comes along, modify the code to handle it. Eazy peezy."
<boss walks in from a meeting>
Boss: "Whats up guys?"
Ralph: "You know the problem with TFS and not being able to stream the data I had all day yesterday? I finally figured it out. I need to keep this TFS reader simple. I'll start with the XML configs and if we more readers later, we can add them."
Boss: "Oh yea, always start simple and add complexity only when you need it."
Frack...Frack..Frack...you played some victim complaining to anyone who would listen yesterday (which I mostly ignored) about reading data from TFS was this monumental problem no one could solve, then you start complaining to me, I don't fall for the BS, then tell the boss the solution was your idea?
Lunatic or genius? Wally would be proud.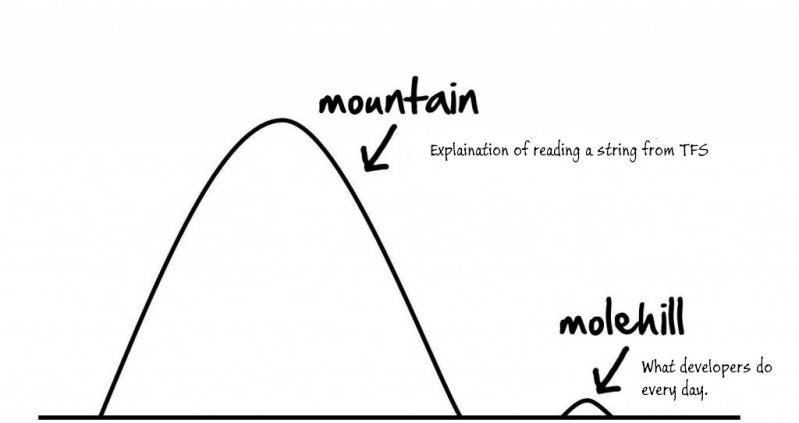 4
4 -
When your raspberry pi is bombarded with /phpmyadmin URL attempts in all its forms and possible paths and versions 😅
Like seriously? Who in there right mind uses phpmyadmin AND has it accessible to the public.
- there's no databases on this Rpi but you keep looking.9 -
> be me
> has some free time
> decides to practice rust skills
> logs on codewars
> finds challenge involving prime numbers
> passes 30 min skimming the Internet to implement the Sieve Of Atkin algorithm
> tries example tests
> passes
> submits answer
> “memory allocation of 18446744073709547402 bytes. failederror: process didn’t exit successfully”
> 18446744073709547402 bytes ~= 18 million petabytes
So yeah, I think it’s broken9 -
Me - I am sorry my dog eats my homework
Comp sci professor - your dog eat your coding assignment?
Me - ...
Professor - ...
Me - it took him couple bytes10 -
An overflow in C, the program was writing 16 Bytes in an array of length 10 due to some mistake.
The problem was this ended up overwriting another place in the memory that was used by another algorithm to perform calculations... So we thought that the algorithm was buggy all along.2 -
!rant
A rather long(it's 8 hrs long to be precise) story
So I just finished an amazing homework assignment. The goal was to open a new shell on Linux using a C program. We were asked to follow instructions from http://phrack.org/issues/49/14.html . However the instructions given were for 32 bit processors and we had to do same for 64 bit machines. In a nutshell we had to write a 64 bit shell code and use buffer-overflow technique to change the return address if the function to our shell code.
I was able to write my own shellcode within 1hr and was able to confirm that it's working by compiling with nasm and all. Also the "show-off-dev" inside me told me to execute "/bin/bash" instead of "/bin/sh"(which everyone else was going to do). After my assembly code was properly executing shellcode, I was excited to put it in my C code.
For that, I needed opcodes of assembly code in a string. Following again the "show-off-dev" inside me, I wrote a shell script which would extract the exact opcodes out of objdump output. After this I put it in my C code, call my friend and tell him that "hell yeah bro, I did it. Pretty sure sir is gonna give me full marks etc etc etc". I compiled the code and BOOM, IT SEGFAULTS RIGHT IN FRONT OF MY FRIEND. Worst, friend had copied a "/bin/sh" code from shellstorm and already had it working.
Really burned my ego, I sat continuously for 8 hrs in front of my laptop and didn't talk to anyone. I was continuously debugging the code for 8 hrs. Just a few minutes ago, I noticed that the shellcode which I'm actually putting in my C code is actually 2 bytes shorter than actual code length. WHAT THE F. I ran objdump manually and copied the opcodes one by one into the string (like a noob) and VOILA ! IT WORKED !!!
TURNS OUT I DIDN'T CUT THE LAST COLUMN OF OPCODES IN MY SHELL SCRIPT. I FIXED THAT AND IT WORKED !!
THE SINGLE SHITTY NUMBER MADE ME STRUGGLE 8 HRS OF MY LIFE !! SMH
Lessons learnt :
1)Never have such an ego that makes you think you're perfect, cuz you're retarded not perfect
2)Examine your scripts properly before using them
3)Never, I repeat NEVER!! brag about your code before compiling and testing it.
That's it!
If you've read this long story, you might as well press the "++" button.6 -
Eight bytes walk into a bar. The bartender asks, “Can I get you anything?”
“Yeah,” reply the bytes. “Make us a double.”1 -
!rant but history
I found this old micro controller: The TMS 1000 (from 1974). The specs: 100-400kHz clock speed, 4-bit architecture, 1kB ROM and 32 bytes (!) RAM. According to data sheet, you sent the program to TI and they gave you a programmed controller back - updates to the once upload program were impossible, but an external memory chip was possible.
I'm glad we have computers with more processing power and storage (and other languages than assembler) - on the other hand it enforced good debugging before deployment and and efficient code.
Data sheet: http://bitsavers.org/components/ti/... 6
6 -
We all have that one friend who says that he is a computer genius because he built his PC himself but then he doesn't know the difference between bits and bytes.9
-
As a follow-up to my comment on this rant: https://devrant.com/rants/1029538 I want to share with you my new project: BinToBmp!
It converts any file into a beautiful bitmap image illustrating all bytes as pixels. Each byte indicates an index to a color table (very happy bitmap makes it this simple).
Useful? No. Fun to make? Hell yeah!
Take a look at it on my github page:
https://github.com/Forside/BinToBmp
Download:
https://github.com/Forside/...
Print your favorite song and hang it on the wall or make a shirt from your latest compiled application. So many possibilities!
More infos in the readme.
Updates coming soon :)
P.S.: The image displays the converted jar. 30
30 -
Me: I fucking hate people using proprietary data formats when there is something more than capable already...
Also me: *Spends an hour designing file structure for a proprietary image format* Hmmm... How can we trim even more bytes off this...
(Designing the format to be smaller than a typical PNG and make it easier to load in data programatically)8 -
Eight bytes walk into a bar.
The bartender asks, "Can I get you anything?"
"Yeah," reply the bytes.
"Make us a double."2 -
Just realized:
We got to a point where I transpile typescript to react to es6 to plain es5. Just so that the browser could compile the code to bytes.
Sort of ridiculous. It's like translating a book from English to French to Spanish to Russian just so that we could create a Slavic interpretation of the book.3 -
Screw MySQL/MariaDB. Who the fuck thought not to document that utf8 is only 3 bytes and not unicode capable. You have to use utf8mb4 for it to work. Fuck those idiots that don't want to admit they made a mistake and put this info in a footnote on a pricy documentation piece.5
-
"please copy these 32767 bytes to VRAM" → infinite bytes copied, entire address space destroyed.
"please copy these 32768 bytes to VRAM" → 4 bytes copied
thank you, TI, for making the shittiest possible routines that are infinitely picky.1 -
What kind of rusty asshole develops an FTP client which seemingly treats uppercase and lowercase filenames as exactly the same and is not able to fucking understant UTF-8 filenames!?
OK or maybe it was the shitty ass server to which I had to deploy the website to.
I've never been so pissed in my life.
It's already an asshole torture to upload 2.3 giggle bytes of pixel jizz, but 5 hours later, when the site has been made public, you find out that 25% of these images' filenames were automatically renamed during the extraction because some asshole dev thought it was a great idea to not even inform the user about this behaviour.
Fixing filenames in production while your boss is really pissed next to you the hole time is not a great feeling. Especially when you accidentally purge the whole image cache and the PHP image transform task then blocks thus making the whole site not loading any more images for 40 minutes.
WHAT AN ASSRAPE!
Please don't comment. I'm still too pissed to read comments. Thanks.4 -
Uggg..... I'm trying to encode a binary file in Python which may be an image or may be an executable, and then decode it back into a file (I plan on editing it in the middle, but baby steps for now..) but nothing is working!!
My plan is to:
Open binary file.
Decode as base64, or something else that could easily handle binary.
Convert byte data to string (for editory perpousos - I won't be editing bytes, I'll be doing custom encoding but that's irrelevant for this test)
Convert back to a byte string/array (with .encode(), probably)
Write to file.
I do this, yet the output has been altered... Though I haven't touched anything..
It's so enfuriating.. x.x18 -
Building a wheel is great.
Building a steering wheel is also great
Building a brakes pedal is amazing.
Making them work asynchronously - not that good of an idea is it...
Who the fuck thought separating data stream (copying bytes) from stream control (when does the stream start/end) is a good idea...?
- open a connection
- send data to the stream
- send() returns
- close the connection
Apparently, the send() does not copy the data and returns. Instead, it enqueues the data copying task end returns. When does the actual copying start? IDK. When does it end? IDK. Can I close the conn? NO!
This thing is UNUSABLE. And I'd riddle it with reflection-based workarounds if it weren't for the static methods.
Fuck!3 -
I miss the good times when the web was lightweight and efficient.
I miss the times when essential website content was immediately delivered as HTML through the first HTTP request.
I miss the times when I could open a twitter URL and have the tweet text appear on screen in two seconds rather than a useless splash screen followed by some loading spinners.
I miss the times when I could open a YouTube watch page and see the title and description on screen in two seconds rather than in ten.
I miss the times when YouTube comments were readily loaded rather than only starting to load when I scroll down.
JavaScript was lightweight and used for its intended purpose, to enhance the experience by loading content at the page bottom and by allowing interaction such as posting comments without having to reload the entire page, for example.
Now pretty much all popular websites are bloated with heavy JavaScript. Your browser needs to walk through millions of bytes of JavaScript code just to show a tweet worth 200 bytes of text.
The watch page of YouTube (known as "polymer", used since 2017) loads more than eight megabytes of JavaScript last time I checked. In 2012, it was one to two hundred kilobytes of HTML and at most a few hundred kilobytes of JavaScript, mostly for the HTML5 player.
And if one little error dares to occur on a JavaScript-based page, you get a blank page of nothingness.
Sure, computers are more powerful than they used to be. But that does not mean we should deliberately make our new software and website slower and more bloated.
"Wirth's law is an adage on computer performance which states that software is getting slower more rapidly than hardware is becoming faster."
Source: https://en.wikipedia.org/wiki/...
A presentation by Jake Archibald from 2015, but more valid than ever: https://youtube.com/watch/... 32
32 -
So, CS student here.
Gave TCS "national" level test.
Quoting from the question:
"if you have 3 bytes of memory, it can be used to represent 2^3=8 values in the memory"
This test is a waste of at least 30000+ human hours and these guys didn't even put 24 hours of effort to make sure questions are correct.
Fuck this fucking IT industry.
Fuck the people who designed this testing process.
Fuck the people who endorsed this process.
Fuck the management for passing it as a test.
The people who wrote the test question can go die in hell.
It's not my problem that their mothers fucked Neanderthals.
Uh! All I want is a job but ended up wasting 200+ hours of time.11 -
My mom got infected with one of those stupid you have a virus redirect viruses. Malware bytes isn't useful.
To make matters worse it doesn't redirect in Edge, so she's forced to use Edge until further notice.
It's going to be a long week.
Also I don't have much experience with Windows viruses especially these redirect ones, so yay!16 -
So I've taken over a project, well, not really taken over, we've been hired to add more functionality to a Wordpress site.
I have never seen such a messy code in my life... variables have mixed languages, indentation is a mix of tabs, 2, 3 and 4 spaces, camelcase, snake case, short names, long names. ' and ", no spaces after commas (gotta save those bytes doode)
Almost like it has been copypasted from everywhere.
I think I said 10-15 hours for it. I think I will spend a lot more time tidying up this code.
Hey, look, 3 index files!!
index.php
index__backup.php
index__backup_2.php
I don't dare to look into the CSS or JS, but I know I have to3 -
People who write ridiculous JS variable names that are impossible to understand or are just unreadable!! WTF!! Don't tell me it's to save bytes because its getting minified anyway. You're just fucking lazy.
-
My first contact with an actual computer was the Sinclair ZX80, a monster with 512 bytes of ram (as in 1/2 kbyte)
It had no storage so you had to enter every program every time and it was programmed in basic using key combinations, you could not just write the commands since it did not have memory enough to keep the full text in memory.
So you pressed the cmd key along with one of the letter keys and possibly shift to enter a command, like cmd+p for print and it stored s byte code.8 -
*Awesome compile-bomb in 29 bytes*
If you want to hang up your machine, just compile this code
main[-1u]={1};
With next command line
gcc -mcmodel=medium cbomb.c -o cbomb
It will result in ~16GB executable file (if you have that memory and computer power)4 -
The local news came to my coworking space looking for some sound bytes, I was chosen and very carefully opened up devrant on the monitor behind me before she started.5
-
KALI FOR THE LOVE OF GOD CAN YOU NOT BREAK YOUR BOOT PACKAGE FOR 24 FUCKING HOURS
the initrd isn't at all valid and the vmlinuz package is 0 bytes. 21
21 -
Fuck you apple, and fuck your god damn shitty documentation.
Working with NFC enabled passes, their documentation says "payload max is 64 bytes"
What they ACTUALLY fucking mean is 64 ascii characters.
Also, the way they handle date time formats is fucked. They say they support W3C formats (iso) but what they actually mean is, they support a half assed version of a subset of it.
I told their chief engineer over a phone call and his response;
"I agree, our documentation is lacking"... HOW ABOUT YOU FUCKING UPDATE IT!
Also, how they handle json is just bad.7 -
About age 7 playing with lego an together with a friend was planing to build a robot. 3 years later I got to play with a computer for the first time, A brand new zinclair zx80 with 512 bytes ram (thats 1/2kbyte), and we got it to print 0 instead of syntax error :D
-
It seems that the bug with the Add-ons on Firefox still remains unsolved (at least with firefox-esr on Debian, the "new" version seems not to have been released yet).
It has been an uncomfortable weekend on the Internet, but not enough to make me break my relation with Mozilla. Each time I miss my extensions, I think of those poor devs drinking coffee and fixing bugs during the weekend, instead of relaxing and do other things.
Why do I see so many annoyed people writing bad comments on Mozilla's blog? I mean, Firefox is open source, maybe we should be a little more patient and empathic with them :)
(source of the image: http://www.foxkeh.com/) 8
8 -
Goodbye, a night of work!
I just typed "rm * .sh.*" instead of "rm *.sh.*" for deleting the logs from a bunch of qsubs. Yes, I removed the logs... as well as the rest of the files in the folder.
Now, probably because of the lack of sleep, I'm laughing to keep myself from crying.
No more code for today!7 -
This kid in my software development class comes up to me and says, "this class is the best class to get hungry in. Because it is all about the bytes"2
-
In my wallowing experience as a freelancer I've noticed that almost all C/C++ clients are perfectionist. You just can't please them by getting the job done quickly.
I got a libcurl job from one the other day to scrape data from a target website and within an hour it was ready. I notified the client and he was both amazed and confused assuming it would take the whole week.
C++Client: The code works but you need to take your time.
Me: Sorry?
C++Client: Yes, it works but you used "string" instead of "wstring"
Me: 😊 Oh okay... *converts strings to wstring*
C++Client: And also variable names should be more descriptive.
Me: 😏 *int foobar => int very_long_descriptive_foobar_01*
C++Client: And also use "shorts" for page nums it'll save some bytes
Me: 😕 *int => short...*
C++Client: And also use forloops instead of whileloops
Me: ☹️ *whileloops => forloops*
C++Client: And also use -- instead of ++ in loops
Me: 😤 *for(... i++) => for(... i--)*
C++Client: And also...
C++Client: And also...
C++Client: And also...
C++Client: And also...
C++Client: And also...
C++Client: And also...
C++Client: And also...
===> Seven "and also" days later <===
Me: *completed 10 Java projects behind the scene*
C++Client: And also use pthread instead of thread
Me: 😧 It's day 7 already!
C++Client: Oh I see, great job. You can compile and send me the archived source.
Me: 🤩
C++Client: And also...
Me: 🏃💨10 -
I fucking love it!
After a full day of refactoring old shitty code into a glamorously sparkling epicness of bytes, the whole thing worked flawlessly and on speed.
Quite satisfactory. 😊
Templating in TWIG, especially using inheritance and includes, is so much more fun than doing it in raw PHP!
*cough*Fuck WordPress*cough"1 -
An experience that made me doubt (some) skills was when I tried for 3 days straight to find a way to share data over a win32 message. The event worked flawlessly, but the data payload always cointained random bytes.
A few weeks later I found an article about MemoryMappedFiles, which helped me solve it within half an hour.1 -
Me: *spends three days trying to format a string to replace two backslashes with one*
Python: Here you go!
str = bytes(str,"utf-8")
.decode("unicode_escape")7 -
for your next edition of "TI's constantly been smoking crack since the 80s and has no intention of ever stopping":
the TI-8x calculators have a hardware buffer and an OS-provided buffer for screen data, effectively being an "immediate" buffer in hardware, to be displayed next VBlank, and a "slower" buffer, being what's copied to the "immediate" buffer when the OS decides it's time to update the screen. All well and good, maybe a little weirdly done but all in all makes sense. (You can even define a third buffer in RAM if you need to triple-buffer your shit.)
The problem arises when you use TI-BASIC and try to draw to the screen:
If you do something like, say, draw a circle, you'll notice that it's visibly drawn to the screen one pixel at a time. However, looking through what bits of the SDK I can find, the OS' "draw circle" assembly routine *doesn't update the immediate buffer!*
This means that, in TI-BASIC, the "draw circle" routine doesn't use the ACTUAL circle-drawing routine the OS provides, but instead individually calculates and plots a pixel, then updates the hardware buffer (an ENTIRE 768 bytes are copied EVERY TIME) and waits for VBlank to pass before repeating for the next one. In other words, it's deliberately slow as fuck.
Why? All the drawing commands, outside of like 2 or 3, do this. Why would you deliberately slow down the process of drawing to the screen on a system that you KNEW would be popular for people to code on???7 -
A typical bouba coder:
- thinks a kilobyte contains 1024 bytes
- thinks Object.assign clones an object
- codes in react.js, thinks he knows reactive programming
- “amd is better for games, intel is better for work”
- thinks that the main advantage of ssh is that you don’t need to enter your password manually
- watches porn in incognito mode
- “crapple”
- “uhm, is it immutable?”
- thinks “persistent” means saved to local storage
- thinks designer is an inferior job because “they only draw shapes”
- thinks good accessibility is when the tab key works
- “All non-mechanical keyboards are trash”
- “C is outdated and nobody uses it anymore”
- “Zuck quit uni and now he’s a billionaire, everybody should quit”
- thinks “pointer” is a shape of the cursor43 -
Started reading this book completed 15 chapter in 21 chapter. Now reading co-routines. Wonderful book, lot of internal stuffs
PS: skipped chapter 4 text vs bytes.
Which book to read next ? 9
9 -
**Day 2 of glaring at the code.😩 The bits are collapsing in front of my eyes into bytes and the glaring dark theme of sublime engraves the code into my retinas. Is it day or is it night? I can no longer tell. Having scoured every corner of the internet and applying every fix I can find the bug persists... was I ever destined to program? For the doubt eclipses my hope of ever seeing the light. I peer over the edge of the world into the abyss and the abyss... **
"Wait 🔎, shouldn't there be apostrophes' in here? MOTHERF-" 😡😠💥☠
**tests**
**works**
*glee* 😄
"God, I love programming!" 😃4 -
There should be an open source, Linux based Printer operating system. Like OpenWRT for routers, also works with almost every device in the wild.
This would be such a relief for everyone. Come on, most printer firmwares are crap.
Remember Scannergate? Yep, the one about professional xerox scanners changing numbers in scanned document. Went unnoticed for 8 years and affected almost every workcenter even in the highest compression setting. Just because they wanted to save a few bytes by using pattern matching. -
when someone tries to wrap their MIDI in 3 layers of crypto to distribute it without allowing access but they used ZipCrypto on a file format with a 14 byte header where only 4 bytes change
 3
3 -
The process of making my paging MIDI player has ground to a halt IMMEDIATELY:
Format 1 MIDIs.
There are 3 MIDI types: Format 0, 1, and 2.
Format 0 is two chunks long. One track chunk and the header chunk. Can be played with literally one chunk_load() call in my player.
Format 2 is (n+1) chunks long, with n being defined in the header chunk (which makes up the +1.) Can be played with one chunk_load() call per chunk in my player.
Format 1... is (n+1) chunks long, same as Format 2, but instead of being played one chunk at a time in sequence, it requires you play all chunks
AT THE SAME FUCKING TIME.
65534 maximum chunks (first track chunk is global tempo events and has no notes), maximum notes per chunk of ((FFFFFFFFh byte max chunk data area length)/3 = 1,431,655,763d)/2 (as Note On and Note Off have to be done for every note for it to be a valid note, and each eats 3 bytes) = 715,827,881 notes (truncated from 715,827,881.5), 715,827,881 * 65534 (max number of tracks with notes) = a grand total of 46,911,064,353,454 absolute maximum notes. At 6 bytes per (valid) note, disregarding track headers and footers, that's 281,466,386,120,724 bytes of memory at absolute minimum, or 255.992 TERABYTES of note data alone.
All potentially having to be played
ALL
AT
ONCE.
This wouldn't be so bad I thought at the start... I wasn't planning on supporting them.
Except...
>= 90% of MIDIs are Format 1.
Yup. The one format seemingly deliberately built not to be paged of the three is BY FAR the most common, even in cases where Format 0 would be a better fit.
Guess this is why no other player pages out MIDIs: the files are most commonly built specifically to disallow it.
Format 1 and 2 differ in the following way: Format 1's chunks all have to hit the piano keys, so to speak, all at once. Format 2's chunks hit one-by-one, even though it can have the same staggering number of notes as Format 1. One is built for short, detailed MIDIs, one for long, sparse ones.
No one seems to be making long ones.6 -
I think I'm getting crazy...
Yesterday evening I finally thought it was a great idea to set up Gitlab CI to let the server build (ng cli) and deploy (via FTP) an Angular5 SPA on commits on the master branch.
BUT...
The npm package "vinyl-ftp" thinks it is pretty fucking funny to just randomly stop in the middle of uploading files or just upload some files with 0 bytes in size.
WHAT THE HELL?
After some hate infested trial and error, it seems that the more parallel channels I set up, the more chance I get that all files are correctly uploaded, but never all.
If anybody here happens to be some kind of mighty byte bender and knows what to do, I'd be thankful. But I will probably try out a different client in the docker image...1 -
A few weeks ago, I was kept up until the wee hours of the morning trying to figure out how in the hell the Monty Hall problem works. After finally getting it (I'm slow, okay?), I decided to write a program to run simulations of it.
First incarnation of program took user input. User enters what door they choose (1, 2, or 3), then is told what door Monty opens, then given the decision of staying with the door they originally chose or switching, then informed how that worked out for them.
Second incarnation of program ran on a loop. At the start of each loop, a random door is picked for the user guess. Then the door Monty opens is calculated from the remaining doors (excludes user guess and prize door). Then user switches doors (choosing the door that was not their original door or the door Monty opened). At the end of each loop, if the door they switched to was the prize door, it would increment a win counter, else increment a loss counter. After running the loop 1000000000 times, it printed to console `You always switched doors, resulting in ${wins} wins and ${losses} losses`.
THEN I decided to write a variation to run a while loop on the outside of the loop to increase the number of total doors until the point where the decision to switch doors hurt more often than it helped. At this point, I decided to incorporate file I/O and write to a file rather than a console. And that was neat!
And then I decided it would be cool to go back to the three door variation, printing on each loop the original door, the door Monty opened, the door that was switched too, the result of the switch (win or lose) and what the prize door was.
But for the life of me, I couldn't seem to get the file to write properly. It would, like, always crash my terminal. I tried open + append, I tried append. I tried createWriteStream. Still just failure.
And then I changed it to an appendFileSync and happened to look at one of the files that I was writing to. "Huh, over a gig seems a lot."
"Well, how much are you writing each loop? Did you forget to keep in mind how many bytes that would be?"
TLDR: If you're going to write a program that's going to write data to a file on a loop, you might want to figure out how much it's going to end up writing .... before trying to run it. And running a loop 1000000000 times may be a little excessive.
*face palm* 2
2 -
Okay so my brother in law has a laptop that is... To put it mildly, chockful of viruses of all sort, as it's an old machine still running w7 while still being online and an av about 7 years out of date.
So my bro in law (let's just call him my bro) asked me to install an adblock.
As I launched chrome and went to install it, how ever, the addon page said something like "Cannot install, chrome is managed by your company" - wtf?
Also, the out of date AV couldn't even be updated as its main service just wouldn't start.
Okay, something fishy going on... Uninstalled the old av, downloaded malware bytes and went to scan the whole pc.
Before I went to bed, it'd already found >150 detections. Though as the computer is so old, the progress was slow.
Thinking it would have enough time over night, I went to bed... Only to find out the next morning... It BSoD'd over night, and so none of the finds were removed.
Uuugh! Okay, so... Scanning out of a live booted linux it is I thought! Little did I know how much it'd infuriate me!
Looking through google, I found several live rescue images from popular AV brands. But:
1 - Kaspersky Sys Rescue -- Doesn't even support non-EFI systems
2 - Eset SysRescue -- Doesn't mount the system drive, terminal emulator is X64 while the CPU of the laptop is X86 meaning I cannot run that. Doesn't provide any info on username and passwords, had to dig around the image from the laptop I used to burn it to the USB drive to find the user was, in fact, called eset and had an empty password. Root had pass set but not in the image shadow file, so no idea really. Couldn't sudo as the eset user, except for the terminal emulator, which crashes thanks to the architecture mismatch.
3 - avast - live usb / cd cannot be downloaded from web, has to be installed through avast, which I really didn't want to install on my laptop just to make a rescue flash drive
4 - comodo - didn't even boot due to architecture mismatch
Fuck it! Sick and tired of this, I'm downloading Debian with XFCE. Switched to a tty1 after kernel loads, killed lightdm and Xserver to minimize usb drive reads, downloaded clamav (which got stuck on man-db update. After 20 minutes... I just killed it from a second tty, and the install finished successfully)
A definitions update, short manual skimover, and finally, got scanning!
Only... It's taking forever and not printing anything. Stracing the clamscan command showed it was... Loading the virus definitions lol... Okay, it's doing its thing, I can finally go have dinner
Man I didn't know x86 support got so weak in the couple years I haven't used Linux on a laptop lol.8 -
Eight bytes walk into a bar. The bartender asks, “Can I get you anything?”
“Yeah,” reply the bytes. “Make us a doubl2 -
So recently I had an argument with gamers on memory required in a graphics card. The guy suggested 8GB model of.. idk I forgot the model of GPU already, some Nvidia crap.
I argued on that, well why does memory size matter so much? I know that it takes bandwidth to generate and store a frame, and I know how much size and bandwidth that is. It's a fairly simple calculation - you take your horizontal and vertical resolution (e.g. 2560x1080 which I'll go with for the rest of the rant) times the amount of subpixels (so red, green and blue) times the amount of bit depth (i.e. the amount of values you can set the subpixel/color brightness to, usually 8 bits i.e. 0-255).
The calculation would thus look like this.
2560*1080*3*8 = the resulting size in bits. You can omit the last 8 to get the size in bytes, but only for an 8-bit display.
The resulting number you get is exactly 8100 KiB or roughly 8MB to store a frame. There is no more to storing a frame than that. Your GPU renders the frame (might need some memory for that but not 1000x the amount of the frame itself, that's ridiculous), stores it into a memory area known as a framebuffer, for the display to eventually actually take it to put it on the screen.
Assuming that the refresh rate for the display is 60Hz, and that you didn't overbuild your graphics card to display a bazillion lost frames for that, you need to display 60 frames a second at 8MB each. Now that is significant. You need 8x60MB/s for that, which is 480MB/s. For higher framerate (that's hopefully coupled with a display capable of driving that) you need higher bandwidth, and for higher resolution and/or higher bit depth, you'd need more memory to fit your frame. But it's not a lot, certainly not 8GB of video memory.
Question time for gamers: suppose you run your fancy game from an iGPU in a laptop or whatever, with 8GB of memory in that system you're resorting to running off the filthy iGPU from. Are you actually using all that shared general-purpose RAM for frames and "there's more to it" juicy game data? Where does the rest of the operating system's memory fit in such a case? Ahhh.. yeah it doesn't. The iGPU magically doesn't use all that 8GB memory you've just told me that the dGPU totally needs.
I compared it to displaying regular frames, yes. After all that's what a game mostly is, a lot of potentially rapidly changing frames. I took the entire bandwidth and size of any unique frame into account, whereas the display of regular system tasks *could* potentially get away with less, since most of the frame is unchanging most of the time. I did not make that assumption. And rapidly changing frames is also why the bitrate on e.g. screen recordings matters so much. Lower bitrate means that you will be compromising quality in rapidly changing scenes. I've been bit by that before. For those cases it's better to have a huge source file recorded at a bitrate that allows for all these rapidly changing frames, then reduce the final size in post-processing.
I've even proven that driving a 2560x1080 display doesn't take oodles of memory because I actually set the timings for such a display in order for a Raspberry Pi to be able to drive it at that resolution. Conveniently the memory split for the overall system and the GPU respectively is also tunable, and the total shared memory is a relatively meager 1GB. I used to set it at 256MB because just like the aforementioned gamers, I thought that a display would require that much memory. After running into issues that were driver-related (seems like the VideoCore driver in Raspbian buster is kinda fuckulated atm, while it works fine in stretch) I ended up tweaking that a bit, to see what ended up working. 64MB memory to drive a 2560x1080 display? You got it! Because a single frame is only 8MB in size, and 64MB of video memory can easily fit that and a few spares just in case.
I must've sucked all that data out of my ass though, I've only seen people build GPU's out of discrete components and went down to the realms of manually setting display timings.
Interesting build log / documentary style video on building a GPU on your own: https://youtube.com/watch/...
Have fun!18 -
Custom image format update for anyone who is interested…
First blocks of data have been written and the colour table has been compressed from ~170KB to 30 bytes…
Now to decide on my preferred method for pixel indexing, RLE or no RLE… and how should one do the RLE…19 -
RONALD REAGAN VIRUS: Saves your data, but forgets where it's stored.
MIKE TYSON VIRUS: Quits after two bytes.
OPRAH WINFREY VIRUS: Your 300 MB hard drive suddenly shrinks to 100 MB, then slowly expands to 200 MB.
TITANIC VIRUS: Your whole computer goes down.
DISNEY VIRUS: Everything in your computer goes Goofy.
PROZAC VIRUS: Screws up your RAM but your processor doesn't care.
ARNOLD SCHWARZENEGGER VIRUS: Terminates some files, leaves, but will be back.4 -
WHY IS IT SO FUCKIN ABSURDLY HARD TO PUSH BITS/BYTES/ASM ONTO PROCESSOR?
I have bytes that I want ran on the processor. I should:
1. write the bytes to a file
2a. run a single command (starting virtual machine (that installed with no problems (and is somewhat usable out-of-the-box))) that would execute them, OR
2b. run a command that would image those bytes onto (bootable) persistent storage
3b. restart and boot from that storage
But nooo, that's too sensible, too straightforward. Instead I need to write those bytes as a parameter into a c function of "writebytes" or whatever, wrap that function into an actual program, compile the program with gcc, link the program with whatever, whatever the program, build the program, somehow it goes through some NASM/MASM "utilities" too, image the built files into one image, re-image them into hdd image, and WHO THE FUCK KNOWS WHAT ELSE.
I just want... an emulator? probably. something. something which out of the box works in a way that I provide file with bytes, and it just starts executing them in the same way as an empty processor starts executing stuff.
What's so fuckin hard about it? I want the iron here, and I want a byte funnel into that iron, and I want that iron to run the bytes i put into the fuckin funnel.
Fuckin millions of indirection layers. Fuck off. Give me an iron, or a sensible emulation of that iron, and give me the byte funnel, and FUCK THE FUCK AWAY AND LET ME PLAY AROUND.6 -
Okey, so the recruiters are getting smarter, I just clicked how well do you know WordPress quiz (I know it's from a recruiter, already entered a php quiz An might win a drone)
So the question is how to solve this issue:
Fatal error: Allowed memory size of 33554432 bytes exhausted (tried to allocate 2348617 bytes) in /home4/xxx/public_html/wp-includes/plugin.php on line xxx
A set memory limit to 256
B set memory limit to Max
C set memory limit to 256 in htaccess
D restart server
These all seem like bad answers to me.
I vote E don't use the plug-in, or the answer that trumps the rest, F don't use WordPress 4
4 -
When the company my mother worked for was arranging computer courses and could not leave the computers in the borrowed classrooms.
They brought them home and I got to play with them :)
Sinclair ZX80 with 512 bytes of RAM (no hard drive, diskette or CD).
This was 38 years ago ;)6 -
Init Mud. (A poem)
A Giant Ball of Mud.
Haphazard in structure.
A sprawling, enthralling, duct-taped warning,
Of things to come.
Tumbling down a well-worn path
Of untamed growth and aftermath.
Into Spaghetti-code Jungle.
Where quick and dirty wins the day
And warnings spoken hold no sway
Or fall on deaf ears in the undergrowth.
Tumbling.
Gaining weight.
Bits stuck on.
Bytes taken out.
Patches,
On top of patches,
On top of obsolescence.
Hacked at, uploaded
All elegance eroded.
Made and remade
Then duplicated
Relocated
Refined and redesigned
Suffocated by expedient repair after expedient repair
The original self no longer there
Replaced by something
Unwieldy.
Design resigned to undefined
An architectural mystery
Whose function can no longer be
Seen or gleaned
From obfuscated in-betweens
Of classes
Made and remade
Duplicated.
Abused.
A squirming library of disused.
Pulled at, prodded, committed
Corners cut and parts omitted.
Bug ridden branches fused to a rotting core.
The structure...
The system...
The content...
Mud.1 -
Of course, the variable for fields should be called "flds", those 2 bytes saved will help us so much! For a small price of this shit being not really readable anymore. Is it "floods"? "fleeds"?6
-
Writing x86 assembly code in VS Code feels so weird. I mean, I'm using something that's built using crazily high level languages (JS, HTML, CSS), on top of a mammoth runtime environment (Node, V8), which is itself sitting on a modern and sophisticated operating system (Antergos), and I'm writing code that shifts bits and bytes around in memory in order to get one part of my C program to run just a little faster. Wow.1
-
Ah, the little subtle things we have to iron out as we progress from Junior Developer to Medior Developer.. things like:
- knowing the difference between a carriage return and a line feed (although having worked with analog typewriters helps) and later knowing that Unix-based systems and Windows NT-based systems implement it differently..
- knowing that serialization is important because not all computers interpret data the same way and some computers allocate 4 Bytes for a construct, others 16 Bytes.. and then we get the funkiness of transferring character sets between machines..
- knowing that a whitespace character is not only an actual space (as is known in ASCII as code 32). This one can cause even medior developers a headache, as in: why the fuck does this string function say that "hello I am a duck" and "hello I am a duck" are not the same?! Turns out then in the debugger that when you expand every character in the string you see that string1 contains 32 32 32 32 as usual.. but then string2 contains -96 -96 -96 -96 and you're like.. what the fuck..? Then you know you have to throw \\h regex at it. Haha.
- finalizing our objects and streams (although modern languages do that for us).. otherwise we have to do funky shit like trying to find what's locking a file, which is not so easy to figure out.
- figuring out why something won't work often requires you to not only break down the problem in smaller steps, to use a debugger, but sometimes it's even better to just create a proof of concept, slap some minimal code in there and debug that.. much easier.
- etc.
:)5 -
In an encryption-module, I had a bug, that caused my PC to crash, every time I tried to encrypt something.
Turns out, the loop, that appends
0-Bytes to the string, to make it Block-Cipher compatible,
Had an logical-bug in its exit-condition, that caused it to run infinitely and allocate an infinite amount of memory. -
The infuriating edgecases of python copypasta.
If you're like me, and you find it easier to noodle in notepad++ and the console, then you may have encountered this peculiar bug.
Try padding blank spaces on an empty string variable, and follow it with print(blanks + str(var))
#for any variable
Now copypaste that along with at least one other line at the same time.
Observe how no matter what you do, print will always output the blanks variable on a separate line, with quotes.
Try rewriting right-justify? No good.
Try using f-format strings? No good.
Raw strings? Inspecting bytes to see where the newlines and carriage returns are being inserted? Nothing.
Copypaste with multiple strings will *always* insert quotes and a new line when printing *any* variable with a string thats been justified.
And this is 100% non-congruent with pasting the same *line* of code *by itself*, which works as intended, no quotes or additional new lines are inserted.
I just went ahead, turned the snippet into a function, and called it from there, which solved the problem entirely.4 -
I started out on a Sinclair ZX 80. It has just 512 bytes of ram and you had to use a function button together with a key for each command since it did not have enough memory to keep the source in memory ;)
I attended few basic courses and then went on to hold them.
After a year there was suggestions of starting pascal courses so during the summer I read up in turbo pascal 5.5 but since the summer home did not have electricity I had to do it all theoretically for the first month before getting to try it out.
I got to try visual basic when doing school practice with Microsoft but the name was not set by then as it was a few months before the release.
Thats also where the more professional programming got going even though I did one pascal program that was used professionally before that. -
Early 1970s, when I was around 8 years old. I read about Artificial Intelligence and it blew me away. I knew nothing about computers, other than I wanted to program them.
I still have old computer magazines, starting from around 1978 not long after the microcomputer revolution started.
My first computer had 2K RAM. That's 2048 bytes. I expanded the memory 1K at a time, and it took 2 chips - they were 4 bits by 1024 so you needed 2 chips to have 8 bit wide memory.
2114 static ram, 300ns.
I think they still make them!6 -
Sooooo I learn c. Programmed antivirus project last night, and there is 13, 374 bytes of memory leak. (BTW the program crashes at return 0). *Rage and despair*
 4
4 -
First commit today
Too bad it's so shitty i should probably never have uploaded it 'cause now I feel like I wasted precious bytes of the Internet
Those days when you just feel like rolling in your own self loathing -
0 bytes of heap allocated per cycle! Figuring out the Unity profiler actually helped me improve my C# optimization. <33
-
Visual Studio Code !!
It has tons of features, form keybinding, to language support
I just love the inbuilt terminal support
And with git integration and some plugins, there's absolutely no need for separate git client -
How do gophers (Go devs) feel about the new Go logo ?
I can get used to it but it feels more like a logo of a company that might rival Uber.
The gopher gave it an easy to use and understand feel, this new one gives a fast and sleek look. It wants to showcase "Fast" more than anything else. 10
10 -
So my friend texts me with the message, you're smart can you figure it out?
What he sent me was a picture of a post, probably from Facebook which said "skynet is working on making you the next Terminator" with a bunch of bytes following it.
So I decode the first letter using an ascII table and sent it to him, and I get the response WOAH Really!!!
Lol even though it's super simple, it make see feel like 😎. 5
5 -
Writing simple terminal input/output lang (Hello, what's your name, hi) in D.
Compiling in D using standard lib: 6.1M
Compiling in D with inline assembly, no standard lib or libc, using syscalls: 1048 bytes!
I'm still freaking out a little.2 -
In reference to:
https://devrant.com/rants/2333925/...
Ideas are commonplace things. Just as a challenge today, in a two hour span, I came up with exactly 100 commercially viable ideas, some of which haven't even been tried yet by anyone that I know of.
This is me humblebragging, but it highlights an important lesson:
Good ideas are *genuinely* not worth the bytes or ink it takes to write them if you don't have the skill, connections, marketing, or cash to carry them forward.
I guarantee you, if you aggregated the commercially viable ideas of all the people on this platform, the list would number in the hundreds, probably in the thousands. And the list would be different every week.
Good ideas happen frequently enough because good ideas are a subset of the *ocean* of nonviable and stupid ideas that we all stumble on constantly, every day.
Like finding a needle in a stack of hay..or a nugget of golden corn by digging through piles and piles of steaming shit. It's a numbers game.2 -
TL;DR: TIL for heavy queries use PDO and not some frameworks DB class
ffs I was trying to save 300k+ lines at once with Laravel for weeks. Mind you from a text file. 1gb ram on the vps so while trying to prepare the text to save: Fatal Error: Allowed Memory Size of bla bla Bytes Exhausted
ok so lets put it in a loop: Fatal error: Maximum execution time of 30 seconds exceeded (set_time_limit(0); lol)
optimising, varying the code got me into a situation when the content got saved in the BD but inconsistent (duplicates) and the table had often more than 1,5M rows. That was what told me its not a performance issue, my code is the issue. (dah)
I was starting to think it would be easier to export a prepared query to a sql file and load the file into the db as thats the fastest possible option...I even started to think about switching to python, then it hit me, Laravel has a shitload of routes to the DB so I switched to PDO
benchmark on 1vCPU, 1GB RAM VPS with SSD
379k lines with 11 columns in less than 10 sec with a loop of saving every ~6000 rows (if i tried choking it to save the whole thing at once it went up to 16-17sec)2 -
Hate CJK languages. They are 2 bytes, and some text editors don't render them properly. (e.g. Sublime)
-
Spend hours debugging a python script because tests fail. Turns out ftp (the unix binary) adds CR bytes to every byte in a .gz file that looks like a LF on upload (in test setup). Client and server are both linux. 😭
Yes i know switch to binary mode (that fixed it - why not default??). But still WHY CR? Didn't ask for it. No windows in sight.1 -
Let's admit that the idea of stacking emojis together to make other emojis was stupid. It was never gonna work. Now, when you see an emoji, you don't know how many bytes you need to store it.13
-
Why do io-interfaces usually use a signed integer to return the number of bytes processed?
Like seriously, you literally can't write/read less than 0 bytes.4 -
Here are some of the variable types in java if someone needs it :)
-String myString = "Hello";
//integeres
- Byte myByte = 127; [It can hold up to 128
-Short myShort = 530; [up to 32767] -> 2 bytes
-int myInt = 8021; [up to 2,147,483,647] -> 4 bytes]
-long myLong = 213134; [ up to 9,223,372,036,854,755,807] -> 8bytes
//Decimal Numbers
-float myFloat = 3.14f;
-double myDouble = 23.45;
P.S.
I hate double... idk why
Bye12 -
First thought about programming was in forth class in school, I was 10, and together with a friend we where planing on building a robot.
When we had a basic Idea on how the mechanics would work (theoretically but maybe not really practically sound) we started to consider how to control it. We had heard about computers but had never seen one but we figured out you could not just say, “go shopping” but rather had to break the problem down and doing that we came to the conclusion we would have to start with getting it to take a step.
We never got further as my family moved and I switched schools.
Later the same year I got to play with an actual computer, the Sinclair ZX80, 80 for the year.
A monster with 512 bytes of internal memory ... yes bytes, not kbyte.
And then things got going, after a few curses in Basic I finally got my own Spectra video 128, 14 years old and 2 years later I was teaching basic in ravening classes and I have been working with computers and programming ever since.1 -
I'm delirious so here's your daily dose of fuck:
```fasm
; --- * --- * ---
; 64-bit byte-by-byte mash
macro clamp_u8 {
mov cl,$08;
mov rdx,rax;
rept 8 \{
rol rdx,cl;
xor al,dl;
\};
};
; --- * --- * ---
; give 8-bit random seed
macro prng_u8 {
rdtsc;
shl rdx,32;
or rax,rdx;
clamp_u8;
};
; --- * --- * ---
; roll dice
d20: prng_u8;
; x%20, according to gcc ;>
mov edi,eax;
mov eax,-51;
mul dil;
shr ax,12;
lea eax,[rax+rax*4];
lea edx,[0+rax*4];
mov eax,edi;
sub eax,edx;
; discard high and give
and rax,$FF;
ret;
```
I guess `d20` could be inlined too but I thought it'd be too much.
Is it faster than straight C? Probably not. But it's way lighter, so it loads faster. Below five hundred bytes mother fucker.
Now if you'll excuse me, I'll go sit in the darkness repeteadly typing roll 1d20 on the terminal. For reasons.8 -
How do you approach generating "random" unique numbers/strings ? Exactly, when you have to be sure the generated stuff is unique overtime? Eg. as few collisions in future as possible.
Now I don't mean UUIDs but when there is a functionality that needs some length defined, symbol specific and definitely unique data, every time it does it's stuff.
TLDR STORY: Generating 8 digits long numbers so they are (deterministically - wink wink) unique is hard but Format Preserving Encryption saves the day. (for me)
FULL STORY:
I had to deal with both strings and codes today.
One was to generate shortlink word for url, luckily found a library that does exactly this. (Hashids)
BUT generating 8 digits long, somewhat random number was harder then I thought, found out on SO something like "sha256(seed) => bytes => ascii/numbers mangling" but that had a lot of collisions because of how the hash got mangled to actually output numbers and also to fit the length.
After some hours I stumbled upon Format Preserving encryption (pyffx) and man it did what I wanted and it had max 2 collisions in 100k values. Still the solution with this feels hacky af. (encrypting straddled unix timestamp with lots of decimals)6 -
Oh god, structure alignement, why you do this... You might be interested if you do C/C++ but haven't tried passing structures as binary to other programs.
Just started working recently with a lib that's only a DLL and a header file that doesn't compile. So using python I was able to use the DLL and redefined all of the structures using ctypes, and the nice thing is: it works.
But I spent the whole afternoon debugging why the data in my structures was incoherent. After much cussing, I figured out that the DLL was compiled with 2 bytes packing...
Packing refers to how structures don't just have all the data placed next to each other in a buffer. Instead, the standard way a compiler will allocate memory for a structure is to ensure that for each field of the structure, the offset between the pointer to the structure and the one to the field in that structure is a multiple of either the size of the field, or the size of the processor's words. That means that typically, you'll find that in a structure containing a char and a long, allocated at pointer p, the double will be starting at p+4 instead of the p+1 you might assume.
With most compilers, on most architectures, you still have the option to force an other alignment for your structures. Well that was the case here, with a single pragma hidden in a sea of ifdefs... Man that took some time to debug...2 -
This may be obvious, but debugging is all about input / algorithm / output. If there's something wrong, it's one of the three. Work with the method of elimination. Sometimes it's easy, sometimes it's not.
I'll give you an example from my situation:
I wanted to play an old DOS game on my modern PC and so I used DosBox. I made an iso from the original CD, mounted it, referred to it in the game's mount settings and launched the game.
Then, after I had saved the game and I tried to load it again, the game would say: "Could not read/write savegame". And so I thought something was amuck with my mount settings and I started fiddling with those, but it only made it worse and it gave me more (cryptic) errors.
The next approach was to save a new game and load that one. Nope, same problem.
Finally I decided to follow a DosBox tutorial for the game and load the game again.. same problem. So I think hmm.. my algorithm is correct.. my output is wrong.. so then my input must be wrong. So I decided to save the game again with these new and correct settings and low and behold, it finally loaded.
One thing to note was that when it failed to load the savegame, it was because it had done a partial save because due to incorrect mount settings it couldn't figure out all the right config folders/files/paths and my savegame ended up being corrupt with 80% of the files having 0 Bytes, which was suspicious. That usually means a file became corrupt.
And then it hit me.. if the game says: "Could not read/write", that doesn't mean the same as "Could not access the file/folder". It could access it, it just couldn't parse it. And of course.. the 'write' part of the message indicates that it messed up in writing, causing it to misread. Sometimes you really have to think about it..
Anyway, input, algorithm, output. :) -
My last post was a year ago. What brought me back here is the ability of AI to agree and apologize to anything and everything, while producing the worst hopeful code.
4 days I wasted, trying to make an android audio visualizer, but AI... sigh.
It gave me the wrong structure of FFT bytes emitted. I corrected it
It gave me the wrong logarithm calc, I corrected it
It gave me the wrong sampling rate, I corrected it.
It gave me the wrong texture order, I corrected it.
It gave me the wrong glsl sample2d, I corrected it.
It gave me the wrong textureID generation, I corrected it.
It gave me a render which was about 10 fps, I found out that instead of using native onDraw, I had a fcking delta time in my shader. I almost corrected it, I gave up
Lets go to code generators with Annotations.
Like always, starts very positive, until I start to correct it.
It gave me the wrong file locations, I corrected it.
It gave me the wrong order of find copy modify and write to .build, I didnt correct it.
It gave me regexes to find annotations. Im like So whats the use of an "ANNOTATION PROCESSOR"
It apologizes and used a fucking regex in the processor,..... I didnt correct it, in the end, I was left with a separate module, targetting iOS Android and JVM, with an annotation processor implemented in jvmMain, which tries to modify commonMain src by finding annotations with regexes, which wont run on app build or app sync project, but only on java -jre command pointing to that fucking .java class in that module, which takes at least 2 mins to run, and Finally generate 0 files.
I needed to rant, I understand LLMs are just models of words built and stolen from the most intelligent and dumbest people out there. But Im an idiot for getting my hopes high. I cant build anything new and unheard of. I used to do that. I once made a textView + image print util for a bluetooth printer just to say FU to libraries and heavy sdks. like literally rasterizing shit to bluetooth packets. I needed to let off some steam. I havent been here in a year so I dont know what reactions I can get from this rant. I bet someone will just say yeah we tired of 'Fuck AI' rants. but shit, it hurts. When I gave up on that visualizer, I downloaded an app, I think its called project M, like in reference to MilkDrop.. like the Winamp Milkdrop. I opened it, played something on spotify, and let my eyes go blind5 -
My biggest dev sin is premature optimization. I'll try to produce the best possible code without the need for it to be there. I will waste my time thinking of wierd edge cases that can be handled with a simple if-else, but why not tweak the algo to handle them internally.
-
We have 4k Monitors and SSDs with more than 120 GB, why there are still new projects that use a formatting style that doesn't have a clear relation of the opening { and corresponding closing }. i.e. put them either on the same line or column?
Please don't write code where the imaginary line between the { and } goes diagonally over other parts of the code. It makes it unreadable and my brain hurts from looking at it. Its better to have readable code and "waste" some lines and bytes for code that is easier to read.10 -
We are currently in home office because of the actual corona situation. Since yesterday we experience internet problems in this region. So I constantly check ping to see how worse it is.
Let's see how long it takes for my girlfriend to rage:
while true; do if (( $(ping -c1 1.1.1.1 | grep "bytes from" | cut -d "=" -f4 | cut -d " " -f1) > 40 ));then espeak "fuck" ;fi;sleep 1;done3 -
Turns out MD5 collisions are hard to iterate through. Max combinations of bytes in a 100,000 byte file is (as calculated by Python:)
413502433742660544726868172195767861427618658445205343992065892230166930397146583182005172845204489533665188550385797247605830027690030912310887164176364954875069038057666590769687571726193148717652368418744731692453987107907857683242360451588862381980796040785447771748097295949966591258383632274557701138287596503423452399232536933583768184114874795654760979888748015241761933209111943015224044366005903481415990946152075730054176507652408593662525624208010788644701872255643844493769499469673271219048262961476704374776988472648537308308011235412742501908803475102336862442166237905095612511941476299337727729022024118389323121828087330601048095646801171259973845170877342411799823272475101891307296782554819753985119403152255745494789644397312746702721825997945525576
i'm getting 1227.97 iterations a second. (Note: no, not using C, i don't know enough to do it in C. If someone wants to take my script, redo it in C, and send it to me for comparison, that'd be great.)12 -
I'm going through a KhanAcademy course learning about cryptography. I learn better by doing, so I wrote a script. It shifts bytes up depending on a random int produced by a high entropy pseudo random number generator using a sha256 hash as the seed. I'm trying to find information on the flaws with this method, that lead us to create DES, and then AES.
-
So for the past day I've been obsessed with adding compression into my build pipeline for web dev, I've implemented html minify, babel JS minify, gzip and made the server specify content length to prevent chunking and shave off a few unused bytes. Is there anything else anyone can think of to get even more gains? Sofar my project went from 1.33mb to 180kb transferred. It's a huge win, just wondering if I can push it further somehow?1
-
Probably around 7 years old when planing on building a robot and discussing how we should get it to move. And also playing with lego.
Then at 10 years my mom lended home a couple if Sinclair ZX80 with 512 bytes of memory and I was hooked :D (they where brand new at that time)5 -
So, our Sales Manager asked us, "what is maximum file size for jpeg banner ad?"
I said, "maximum at 100KB per file"
She asked another question, "what is minimum file size?"
I said, "err... 0 bytes"1 -
life.exe infinite loop
thoughts.exe invalid pointer
heart: null reference
dreams.exe crash detected
motivation.exe offline
panic.exe buffer overflow
Soul.exe terminated
life.exe offline
energy.exe fatal exception
me: exists. --maybe world: buffering…
joy 0 bytes
patience.exe deleted
soul: error 418
me: offline6 -
Low-end smartphones sold to Americans with low-income via a government-subsidized program contain unremovable malware, security firm Malware bytes said in a report.
According to the report of ZdNet: The smartphone model is Unimax (UMX) U686CL, a low-end Android-based smartphone made in China and sold by Assurance Wireless. The telco sells cell phones part of a government program that subsidizes phone service for low-income Americans. "In late 2019, we saw several complaints in our support system from users with a government-issued phone reporting that some of its pre-installed apps were malicious," Malwarebytes said in a report. The company said it purchased a UMX U686CL smartphone and analyzed it to confirm the reports it was receiving.7 -
What's the strangest Assembler or Pseudo-Assembler you've ever encountered?
I wrote a Z-machine (Infocom's virtual text adventure interpreter) and it was quite an interesting interpretation of bytes:
- The first 3 bits of an instruction tell you the opcode category, the rest are the instruction
- The 2nd (and maybe 3rd) byte tell you in 2-Bit chunks the operand types.
- text is encoded in 5-Bit chunks, with special characters for CapsLock that double function as padding (if your text doesn't align with the 3 letters per 2 bytes).
- and of course there are 5 different versions that all work slightly differently (as in CapsLock becomes Shift or "this special character isn't in use anymore")3 -
got annoyed how calculators implement these bit-fiddling tools, so I made my own:
https://nitwhiz.xyz/projects/... -
>Working on code
>Shit works as intended first try, nice
>Goes to play strange bootleg Gameboy Color ROM sent by a friend
>ROM immediately fucking dies
wtf.svg
>Pop emulator's debugger
we're executing from VRAM, stack's firmly embedded in ROM
>why
>Add execution breakpoint to entrypoint of game, restart emulated system (because i'm actually using the legit bios i hacked so it allows null/corrupted games to run)
>Step through everything, everything goes well until all of a sudden we call a function and shit hits the goddamn fan
well we have the culprit
>step through subroutine
if <unused_byte_in_HRAM> != 0 then stackPointer+=32;tryAgain();else return
>***y***
>Realize this is using a bootleg Memory Bank Controller with hard-backed encryption so none of the bytes executed or read as data are the right byte
>Find emulator that'll handle the jank MBC
>read code to try and figure out how it works
if checksumExtendedLogoBlob == some_number then set MBC_Bootleg1 else if checksumExtendedLogoBlob == some_other_number then set MBC_Bootleg2 else if...
>of course
>Spend 10 minutes finding the right bootleg MBC
>code shows 8 possible tables for real bit order based on some value in the cart header
>look for code that gets this value
>not in the header
>not in ANY header in this 1000+ file emulator
>not in any related cpp files???
>get desperate
>email author
>"Delivery failed: email doesn't exist"
fuck me i guess2 -
I hate how the Java File I/O api works.....
I was developing a little noSQL database in java, just for fun.
The basic was: every entry was a json object, separated by \n.
Every entry started with the length in bytes, so i could perform a easy read of the entry with a inputstream, followed by the entry its self..
The problem?
If i had a big file with more than like 50000 entries, to alter a entry with acceptable perfomance, i had to read every entry for matching with search, than using RandomAccessFile to mark the old entry as deleted and adding the modified one at the end.
The same for delete, it was only possible to mark the entry as deleted, so the read/alter would just not read it by reading the length(which i wrote earlier) and than use inputstream.skip with the length.
To actually delete not needed entries, i created a new file and than reading the old one and writing at the same time to the new one, with skipping the not needed entries and at the end rename the new file to the old and re creating all the streams.
Why cant i just replace a specific part of the file? WTF JAVA2 -
So we have a teacher who always annoys us with being extremly specific and precise. Today we "learned" how to calculate the scan file size based on the dpi of the scanner and the size if the picture. He began to calculate, and then, he said: "Now we have 1737389 bytes and we gonna divide with 1024 to get the kiloBYTES. This was it. He rants about us everytime because of this shit. I raised my arm slowly, whilw preparing the words in my head. "Excuse me, but you are calculating kibibytes, not kilobytes! To get kilobytes you have to divide with 1000, hence kilo." Then he muttered something about he didnt wanted to write that because of courae he knew about this... One teacher well done please.
-
> code golf challenge
okay, listening
> easy for beginners
alright, nice, I qualify
> all code must be exactly the same forwards and backwards, >50% of bytes must be run both ways, must run under any OS or system ever made
welp, there goes any hope of being able to fit something into the rules at all
(if you're interested, https://n0.lol/bggp/)15 -
Crypto. I've seen some horrible RC4 thrown around and heard of 3DES also being used, but luckily didn't lay my eyes upon it.
Now to my current crypto adventure.
Rule no.1: Never roll your own crypto.
They said.
So let's encrypt a file for upload. OK, there doesn't seem to be a clear standard, but ya'know combine asymmetric cipher to crypt the key with a symmetric. Should be easy. Take RSA and whatnot from some libraries. But let's obfuscate it a bit so nobody can reuse it. - Until today I thought the crypto was alright, but then there was something off. On two layers there were added hashes, timestamps or length fields, which enlarges the data to encrypt. Now it doesn't add up any more: Through padding and hash verification RSA from OpenSSL throws an error, because the data is too long (about 240 bytes possible, but 264 pumped in). Probably the lib used just didn't notify, silently truncating stuff or resorting to other means. Still investigation needed. - but apart from that: why the fuck add own hash verification, with weak non-cryptographic hashes(!) if the chosen RSA variant already has that with SHA-256. Why this sick generation of key material with some md5 artistic stunts - is there no cryptographically safe random source on Windows? Why directly pump some structs (with no padding and magic numbers) into the file? Just so it's a bit more fucked up?
Thanks, that worked.3 -
Time to stop with the cringe!
Linus was, long live bsd ( and clinl when its out)
Thats right! Linuer4Fun is now called BinaryByter
Binary because I code and i do a lot of low level, Byter because I like eating. And since i eat a lot at once, I eat full bytes at once... BinaryQword doesnt sound too nice unfortunately :(5 -
```
root@srv1:~# ipmitool user set password 2 train-hopper-apple-watermelon
Password is too long (> 20 bytes)
root@srv1:~#
```
hmmm....3 -
With all of those change request features, I might as well charge you by the bytes in my node_modules alone.1
-
A few weeks ago a friend was teaching me about 16bit numbers because we were making one in C# with a function, but he said we need two numbers for the function to work.(so as an example were gonna use 0, 2)
Now I didn’t understand how two numbers were supposed to make one. And my friend could not explain it to me. So I researched the topic all day and the epiphany happened I realized I was looking at it all wrong. I shouldn’t be looking at it as 2 decimal numbers but 2 binary values or two binary arrays forming one byte array with a length of 16.7 -
I almost looked for every possible source but is not satisfied or not found optimum way or path.
Actually i have to build a netflix clone (not exactly but a video on demand platform for one local client). The tech stack will be React at the frontend and DRF (Django Rest Framework) at the backend.
I know the node will match my purpose at best, but this needs to be done on DRF. How should I return the video, should I return it in bytes, packets and what can sample code look like, how frontend should fetch it. It will really help if you put your insight, in general. Thank you5 -
Why hasn't Google told us 5 years ago that we should use fragments whenever possible so it won't be a pain in the arse to add a navigation drawer?! 😥4
-
!Dev but tech
Just got me whole day ruined.. the hifi guy insulted me like I never.... He thought my neat android was.. *shocking*.. an iPhone 7. 🤮😵
I must carry on knowing that... People might confuse my phone for being.. an.. apple phone 😶 the drama is real2 -
We had C project in school about multi-process communication and syscalls. We worked in groups of three.
I made a "framework"(header file) with important prototypes and definitions of needed variable sizes.
One of group member decided to null his variable by bzero syscall (writes null bytes). He ignored my framework and typed literal "sizeof". Ofc nulled double the needed value and it nulled another variable with some TCP packet also.
Spend week trying to find what is wrong with it.
I hate group projects. -
So I finally managed to hit full disk capacity. 0 free bytes.
WHY DO YOU NEED FREE SPACE TO UNINSTALL STUFF WTF15 -
uPlay is ramming me down the throat harder than what should be legal, I can barely breathe.
I'm trying to install Far Cry 5, I preordered it. But.. download is stuck on fucking 0B. That being 0 bytes.
I tried disabling all firewall/antivirus, clean Windows boot, restart, reinstall launcher, slam the table, like everything.
Why isn't the shit fucking doing its job? Anyone who got ideas for what I could try next?
I'm not gonna send a message to their support, I'd rather have sex with a hedgehog, where I'm the one being penetrated. Fuck me.6 -
>making bruteforce MD5 collision engine in Python 2 (requires MD5 and size of original data, partial-file bruteforce coming soon)
>actually going well, in the ballpark of 8500 urandom-filled tries/sec for 10 bytes (because urandom may find it faster than a zero-to-FF fill due to in-practice files not having many 00 bytes)
>never resolves
>SOMEHOW manages to cut off the first 2 chars of all generated MD5 hashes
>fuck, fixed
>implemented tries/sec counter at either successful collision or KeyboardInterrupt
>implemented "wasted roll" (duplicate urandom rolls) counter at either collision success or KeyboardInterrupt
>...wait
>wasted roll counter is always at either 0% or 99%
>spend 2 hours fucking up a simple percentage calculation
>finally fixed
>implement pre-bruteforce calculation of maximum try count assuming 5% wasted rolls (after a couple hours of work for one equation because factorials)
>takes longer than the bruteforce itself for 10 bytes
this has been a rollercoaster but damn it's looking decent so far. Next is trying to further speed things up using Cython! (owait no, MicroPeni$ paywalled me from Visual Studio fucking 2010)4 -
More linux driver woes:
Driver is passed a file position and byte count when asked to read from a device. Sounds easy, right? FUCK no.
For reads, driver is passed struct `filp` with field `f_pos`, a direct pointer to the same struct field, int `count` as a number of bytes to read, and `buf` to return those bytes with. Problem is, requesting, say, 256 bytes from location 10000000h will give the driver `filp->f_pos = 0`, `f_pos = 256`, and `count = 0`. I don't know how to fix this and there's NO help for this shit. None whatsoever.
This shit, right here, is why Linux drivers suck ass.4 -
dammit ti why must your torture be limitless
> eZ80 has awesome DMA-like instruction that copies byte chunks based on registers and it's nigh-instant to copy 64k it's great
> TI has the opcode disabled outside a 4-byte chunk erroneously unincluded from all blacklists and access regulation
> can't bankswitch and keep registers, and can't write to anywhere but those 4 bytes in that bank
> no reusable code in target bank that i can use via mid-func bankswitch1 -
i had a project in a networking class where the provided code was meant to act as a proxy (aka just passing bytes around), but because of the implementation, every byte had to be a valid unicode character
anyway lotta people were frustrated so we asked the course staff and their response was basically "we wanted to support python 2 and 3"
...1 -
Using void 0 instead of undefined is just ridiculous. Sure, you save 3 bytes but I've seen the code you write, you definitely should not care about that.6
-
There isn't a single good hex editor for the command line.
No, xxd+vim is not a solution when you need to move bytes around or create files from scratch.
I want something that shows me e.g. u32/u64 values at certain locations as I'm editing, color coding bytes by printable or not, etc.
There are lots of *viewers*, and a lot of shitty basic editors that hardly work, but nothing that feels solid and actually usable.
Frustrating.7 -
I need to tell you the story of my MOAB (Mother of all bugs).
I need to write some stuff in C (which i am fairly used to) and have a function that allocates memory for a Matrix on the heap. The matrix has a rows and columns property and an associated data array, so it looks like this
struct Matrix{
uint8_t rows;
uint8_t columns;
uint8_t data[];
}
I allocate rows*columns + 2 bytes of memory for it.
I also have a function to zero it out which does something like this
for(int i=0; i < rows*columns;i++){
data[i]=0;}
Let‘s come to the problem:
On my Mac the whole stuff works and passes all tests. We tried the code on a Linux machine and suddenly the code crashed in various places, sometimes a realloc got an invalid pointer, sometimes free got an invalid pointer and basically the code crashed at arbitrary points randomly.
I was confused af because did i really make THAT many errors?
I found out that all errors occured when testing my matrices so i looked more into it and observed it through the debugger.
Eventually i came to the function that zeroes out my matrix and it went unusually high and wondered if my matrix really was that big.
Then i saw it
The matrix wasn‘t initialised yet
It had arbitrary data that was previously in the heap.
It zeroed out a huge chunk of the heap space.
It literally wrote a zero to a shitload of addresses which invalidated many pointer.
You can imagine my facepalm2 -
One little two little three little endian
Four little five little six little endian
Seven little eight little nine little endian
Ten little endian bytes1 -
Goodbye, cruel wairld:
Fatal error: Allowed memory size of 134217728 bytes exhausted (tried to allocate 123736064 bytes) in /var/www/vhosts/hexicalapp/public_html/Classes/Services/Devrant/SearchService.php on line 1741 -
I'm building a script parser to make mods for a game I like. The first step is to write an importer.
The documentation is nonexistent and I'm delving into byte manipulation, which I'm not familiar with - at all. I'm porting existing code from Java to C#, and everything is similar but different enough that I can't always just to a 1:1 transfer.
I get everything working, cleaned up and split into classes so I can write the exporter.
I do an import and the file won't parse. I try all previously know working files and still no good. I clean, rebuild, clean rebuild, run, debug, restart my computer, clear my cache, clean, rebuild. No good.
IT WAS WORKING 5 MINUTES AGO
Proceed to revert to every version from the last hour. No dice.
I was in the wrong folder the whole time.
Navigate to the proper folder, open the filename I know to be good and bingo, works like a charm.
The same project caused me headaches because I had a "== -1", when it should have been "== 1". Between my inexperience with byte manipulation and my untreated astigmatism, I was nearly sent to the shadow realm fixing that.3 -
so apparently my desktop hdd is going bad in the most infuriating way possible: Read speeds are perfectly fine, but write speeds are literally peaking at 600 BYTES PER SECOND. I waited A LITERAL 25 MINUTES (i timed it, 24m51s) to get to the login process. It's performing worse than 320k floppies do.
The disk is 13% full and 0% fragmented. It's negotiating SATA 3.
Time to w&r ig5 -
Hasn't technology become magic - and we ignorant sorcerer's apprentices who can perform a video call to the other side of the globe perhaps while we understand only some bytes of the thousands software snippets that were piled up by us code monkeys to perform the miracle? ...
This however has always been the state of software (for us developers): that this house of cards needs constant care by our hands to not collapse - in constant fear we may preserve the facades while the number of components that interact, the sheer mass of code only allow for guesswork and hotfixes accumulating the technical debt. Yes, we have all that terms for that. The problems are known since the 80s or 60s, so we might be relabeling it once in a while, but mainly it is just: complexity.. or entropy.2 -
Quick question. Is the iPad Pro with M1 chip decent to do some hobby programming? Due to being bedridden, I have tried to use a phone but have yet to find a way to play with text files. The ecosystem overhead is enormous and all of it requires a computer.
I have run code in a number of langs but they refuse to access files I created, by hand.
I just wonder if you can use a 6gb tablet by itself? I started with 4k bytes back in the day. A million times the RAM should do something, right?7 -
!rant
So I decided to collab with a website's maker (who i wont name here) to create something like r/place. (not an exact copy.)
I decided to start by learning their API, and customizing the server later.
I asked the guy for some help, and HOLY SHIT.
Let's start off by this: I had to request a chunk. The response data was in binary. 4 bits meant 1 pixel, so right away, I had to deal with that in my code.
No problem, just decided to use C# instead of JS. (see https://www.devrant.io/rants/547013)
I was finally done after a couple of mental breakdowns, and decided to implement updates.
I needed to use webhooks, and that was completely fine. But when I got "C1FFFF0000CA06" as response (in hex), I seeked some help.
C1 is the operation type: it means that a pixel was updated.
FFFF and 0000 were the chunk coordinates. But remeber: it's a signed integer. Guess what, I had to use Two's compliment. I decided to be a lazy asshole and only check for "00000000" because I was only displaying chunk 0,0.
CA06: This is a weird one. It's 2 bytes, and CA0 contains the X and Y coordinate of the pixel (in the chunk), and 6 contains the new color of the pixel.
I was sent the following code to work with 0xCA06:
color = 0xF & buffer
x = buffer >> 10
y = (buffer >> 4) & 0x3F
So I tried to do it, and it didn't work. I'm not blaming the developer of the server (original dev is reddit) because maybe I screwed up, but which guy will have a night of frustration and debugging?
Me.
P.S.: Dev, if you see this, I'm sorry. This API is way too complicated. I know we need to save bandwith and stuff, but damn.1 -
I'm teaching a couple of classes where students (~18 years old) work on their own projects. I just deleted two of those from my machine: one Angular and one Spring Boot, but just boilerplate. Together, they were about 500 MB. I spent 2-3 hours working on a little Go tool to make concurrent HTTP requests and to report statistics on the response time. The entire repository is roughly 500 kB in size, but solves a genuine problem. My students have a bloat ratio of 1000 compared to me as a baseline, but my stuff actually does things. Today, I programmed prime factorization in PHP for some load tests (mod_php vs. PHP-FPM). The PHP script is 1148 bytes long (but the file system reports 4 kB). My students could learn more from such a script than from their overblown "projects", but "PHP sucks" I hearsay, so let's bloat on.11
-
Yet another unusual take for the Orchid STL: Unicode codepoints aren't a part of the string library.
For the purposes of a high level language, the unit of text is a grapheme. Strings can be converted between Unicode and binary blobs. In a binary, indices address bytes. In text, indices address graphemes. For example, searching a string for a substring that consists of a single letter implies the added constraint that the letter must not have accents or other modifiers.
For storage and transfer optimization it's possible to discover the byte length of a string without converting it to binary2 -
Why do you lil' shits keep making LAYERS and LAYERS of unnecessary abstraction and then call it goddamn progress???
Dude what the fuck is this UEFI shit?!
Why the hell do I NEED to import a frigging library and read tons of boring and overly complicated documentation just so I can paint a pixel on the screen now uh??
Alright alright yeah so the BIOS is a little basic but daaaamit son if you want something a bit more complicated you make it yourself or install an OS that provides it! Like we've been doing it for years!!!
Dude, you don't get to know what a file system is until I tell you!
The PC be like:
"You wanna dereference the 0x0 pointer? There you go: it's 0xE9DF41, anything else?
You wanna write to the screen? Ok I have a perfectly convinient interrupt setup for that.
Wanna paint a pixel yellow? Ok, just call this other interruption. Theere we go.
And it only took four bytes and a nanosecond to do it."
That shit works, and if you want something more complex, but not too much, that still runs efficiently install DOS.
Don't mess around with the hardware pleeease.
We can still understand what's going on down there. Once UEFI steps in, it'll be like sealing a door forever. Long live BIOS damn it all!1 -
Quite an exciting election in America, got to settle a bit.. So enough with stars & stripes, back to bits & bytes!
-
Influxdb 2.0 and the according python client.
This is the stupidest pile of dogshit I have ever encountered. No documentation, no examples, not even for the most basic shit, im fucking done. This is nuts, working like a week on just getting a fucking connection and do some basic curd stuff.
"Id neets to be 16 Bytes long". Yeah, thanks. With Id, org, user, insurance Id?
Next time I gonna implement this bullshit in fucking assembly, so you can have your stupid 16 Bytes without any magic tricks.
FUCK -
Ghidra won't let you relocate a function or data label and update all pointers to it, so I made a tool where that is its only fucking job. That's all it does. Open a textfile, drop in symbol names, paste in hex strings, change address bytes in the hex strings to other symbol names, hit GO. why is this not a feature built into these goddamn RE tools, when people have been doing this manually since before game piracy was a thing on home computers?2
-
I need MD5/original size (in bytes) pairs to test my engine and see if i can get back the originals in any reasonable amount of time.
Any offers?8 -
we write cryptic symbols and modify bytes somewhere so that every 30 or so rotations of the planet, some other bytes somewhere else are modified to add to make a number larger2
-
Malwarebytes has become the best anti malware program of the world in a short time period. With Malwarebytes inside, user knows his computer is safe and secure at all times. More infoemation visit our site https://assistanceforall.com/servic...
 1
1 -
The difference between a programmer and a non-programmer is.........
The non-programmer thinks a kilobyte is 1000 bytes,
while a programmer is convinced that a kilometer is 1024 meters.....5 -
ioctl with FIONREAD as request
it returns size of bytes ready to read, but to store that size it requires pointer to int passed in va_args
when i want to malloc a memory using that size i need variable of type size_t which is 8 bytes on 64-bit system
why do this types mismatch? if ioctl returns size with FIONREAD request it should accept pointer to size_t variable in va_args -
Why the fuck are native desktop applications so damn slow when it comes to displaying remote/web contents???
Steam, XBOX/Microsoft Store, Apple App Store/Music are just a few examples. Waiting 1-2 seconds to perform a search, list products, start video playback or just loading a few bytes of text.
Even Internet Explorer destroys them when it comes to loading and displaying data! I prefer every overloaded electron based app over these crutches.
But honestly, why is this?!5 -
Over the weekend, I made the move to use a flash as a repository (don't need no wires to repo!). Felt that needing 12 MB to store less than 2 MB was a little bit high.
So I figured "simple fix, I'll just reformat the drive from 32Kb allocation to something less, like 4Kb".
After 30 seconds of a single copy/ paste, the transfer was complete. Checking the size... accidently clicked "4096 kilobytes" instead of "4096 bytes".
-
I really really enjoy the parinfer experience. Even more now that I tweaked the code a bit. I mean, joining and splitting a full file of lines on every typed character seems a bit out of scope for a plugin. So I changed the implementation to not do that and BOY OH BOY IT S FAST! Next step is using bytes instead of strings... To be continued3
-
In Go, one symbol is called a rune. A string is a string, but when I try to manipulate it, it turns into an array of bytes, not an array of runes. I then have to deal with this crap.
Can you suggest some mental gymnastics to justify this behavior to people who use real programming languages?4 -
For devJs (I think?), who asked me what I was working on after I said uuuh me is hexdump diver, here is some logs so as to illustrate the boring stuff I'm doing lmao:
; just checking what I'm allocating c:
0000000000000000 : ALO 000000001B0C42B0
; ^taking that allocation and inspecting it
$0000 <: 000000001B0C42B0
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 00000000 | ................
; it's 128 bytes, so OK, good.
; then I say perform some writes
000000001B0C42B0 : WRT [ 0 .. 56] | 128 ( 56 * 1)
000000001B0C42E8 : WRT [ 56 .. 61] | 128 ( 5 * 1)
; ^look at the buf again to check that I wrote what I
; ^intended to write
$0000 <: 000000001B0C42B0
0000558D F7C480C0 : 00000000 00000000 | .....U..........
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 544F4F52 | ........ROOT....
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 00000000 | ................
; ... do some more writes, and so it keeps going
000000001B0C42ED : WRT [ 61 .. 117] | 128 ( 56 * 1)
000000001B0C4325 : WRT [ 117 .. 119] | 128 ( 2 * 1)
; ^inspect...
$0000 <: 000000001B0C42B0
0000558D F7C480C0 : 00000000 00000000 | .....U..........
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : FFFFC300 544F4F52 | ........ROOT....
FFFFC3FF FFFFFFFF : 000000FF FFFFFFFF | ................
00000000 00000000 : 00000000 00000000 | ................
00000000 00000000 : 00000000 00000000 | ................
00002400 00000000 : 00000000 00000000 | .....$..........
; and here it crashes because I somehow still wrote
; outside of bounds ;> FUUUUUUUUUUUUUUCKKKK
realloc(): invalid next size
Aborted (core dumped) -
While developing whatever website that uses Boostrap, my boss always says:
"PLEASE JUST USE BOOTSTRAP CLASSES to make it easier for everyone else to actually operate on that after you're done"
I'm now working on a project started by him and OMG the mess.
The only bootstrap classes he's using are col-* and text-*, the rest is all custom classes like nopad, which is the equivalent of p-0 m-0.
I mean, I might get you use less bytes writing nopad, but be consistent with what you say7 -
so.
i had a stupid idea that'd let me do a project i had planned and abandoned a while back after getting experience with the new project.
problem: detect and manage empty space in a massive file, allow adding data to those empty spaces from files, and fill in a table in a designated empty space with where dynamically-loaded things are. In Python.
I tried JUST detecting empty space, and Python would break out of loops for no reason at all just at random. "run bottom to top through this file until a non-00h byte is found" would either break out of the loop way earlier than should be possible (8 or 9 bytes into a 32KB empty file) or run way into non-zerofill areas before breaking the loop.
Am I just retarded? Is this more Python conditional fuckery? i'm so lost that it's just on hold for now (and i think i lost that script too)




























































































































































Top Tags
Weekly Rant
View