
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Everyone here ranting about a fucking missing semicolon. I can't remember the last time a missing semicolon was the issue...
You wanna know what's REALLY BALL-BUSTING????
WHEN THE FUCKING 10 y/o LEGACY CODEBASE, CODED BY FUCKING PHP WORDPRESS SCRIPTERS WHO THOUGHT THEY COULD BUILD AN ENTERPRISE SHIT CAUSE ZF2 "LOOKS EASY" AND THEN FILL IT UP WITH SPAGHETTI, IS SO BAD WRITTEN THAT IN ORDER FOR THE PAGE TO RENDER YOU ACTUALLY ****HAVE**** TO DISABLE ERROR REPORTING SO WHENEVER A FUCKING ERROR HAPPENS ON THE TEMPLATE RENDER COMPONENT OF ZEND FRAMESHIT 2, YOU'RE LEFT WITH A FUCKING BLANK PAGE AND NOTHING IS LOGGED TO THE LOG FILE, SO YOUR ONLY OPTION IS DIE() DEBUGGING LINE BY LINE ON THE 1300 LINES PHTML FUCKFEST OF A VIEW THEY HAVE.
MISSING SEMICOLON? YES PLEASE, GIVE ME MORE OF THAT SHIT37 -
Yesterday, in a meeting with project stakeholders and a dev was demoing his software when an un-handled exception occurred, causing the app to crash.
Dev: “Oh..that’s weird. Doesn’t do that on my machine. Better look at the log”
- Dev looks at the log and sees the exception was a divide by zero error.
Dev: “Ohhh…yea…the average price calculation, it’s a bug in the database.”
<I burst out laughing>
Me: “That’s funny.”
<Dev manager was not laughing>
DevMgr: “What’s funny about bugs in the database?”
Me: “Divide by zero exceptions are not an indication of a data error, it’s a bug in the code.”
Dev: “Uhh…how so? The price factor is zero, which comes from a table, so that’s a bug in the database”
Me: “Jim, will you have sales with a price factor of zero?”
StakeholderJim: “Yea, for add-on items that we’re not putting on sale. Hats, gloves, things like that.”
Dev: “Steve, did anyone tell you the factor could be zero?”
DBA-Steve: “Uh...no…just that the value couldn’t be null. You guys can put whatever you want.”
DevMgr: “So, how will you fix this bug?”
DBA-Steve: “Bug? …oh…um…I guess I could default the value to 1.”
Dev: “What if the user types in a zero? Can you switch it to a 1?”
Me: “Or you check the factor value before you try to divide. That will fix the exception and Steve won’t have to do anything.”
<awkward couple of seconds of silence>
DevMgr: “Lets wrap this up. Steve, go ahead and make the necessary database changes to make sure the factor is never zero.”
StakeholderJim: “That doesn’t sound right. Add-on items should never have a factor. A value of 1 could screw up the average.”
Dev: “Don’t worry, we’ll know the difference.”
<everyone seems happy and leaves the meeting>
I completely lost any sort of brain power to say anything after Dev said that. All the little voices kept saying were ‘WTF? WTF just happened? No really…W T F just happened!?’ over and over. I still have no idea on how to articulate to anyone with any sort of sense about what happened. Thanks DevRant for letting me rant.13 -
I changed my Wi-Fi name to Syntax Error and made some changes to the configuration. I wanted to disable the admin page at the 2.4Ghz connection, but I got kicked out at 5Ghz as well. So I couldn't log in anymore and resetting the router didn't helped.
So I called the ISP if they can restore it to factory settings, but the guy on the phone didn't understand a thing I said. He said to me: "Sir I don't exactly understand what u say, but I can see an Syntax Error. Do you want me to fix it." And I laughed and I laughed.. I told him that's the Wi-Fi name but ofcourse he didn't got the joke. I called again and got someone else on the phone. He's resetting the router in a one minute call.
Had some fun this morning.10 -
Sent an email out in work informing everyone that we had pushed updates out to all Windows PC's.
Got the following phone call 10 minutes later:
"Hi, I can't log into the banking account app on my iPhone. Did you do something to it with your updates?"
"Nope. They were PC updates."
"Well, I'm sorry but you're wrong. It must be you! It was working yesterday."
"Again, it's not us. What's the error message you're getting on your app?"
"Invalid password"
".....then could it just be that you're entering an invalid password?"
"No, I know the password. I only changed it yesterday!"
"So it was working before you changed the password?"
"That's what i said!
I'm telling you, it's your updates."
"Okay but before we go 'troubleshoot' it, how about ringing your bank firs-"
"Oh look, it doesn't matter if you don't want to help, I don't have time for this!
I'll ring your boss and he'll uninstall the updates for me and fix the app." *hangs up*13 -
Not mine but an error message in a game when you're trying to logout:
"You're currently not logged in. Please log in to log out."
Logically valid though1 -
It's maddening how few people working with the internet don't know anything about the protocols that make it work. Web work, especially, I spend far too much time explaining how status codes, methods, content-types etc work, how they're used and basic fundamental shit about how to do the job of someone building internet applications and consumable services.
The following has played out at more than one company:
App: "Hey api, I need some data"
API: "200 (plain text response message, content-type application/json, 'internal server error')"
App: *blows the fuck up
*msg service team*
Me: "Getting a 200 with a plaintext response containing an internal server exception"
Team: "Yeah, what's the problem?"
Me: "...200 means success, the message suggests 500. Either way, it should be one of the error codes. We use the status code to determine how the application processes the request. What do the logs say?"
Team: "Log says that the user wasn't signed in. Can you not read the response message and make a decision?"
Me: "That status for that is 401. And no, that would require us to know every message you have verbatim, in this case, it doesn't even deserialize and causes an exception because it's not actually json."
Team: "Why 401?"
Me: "It's the code for unauthorized. It tells us to redirect the user to the sign in experience"
Team: "We can't authorize until the user signs in"
Me: *angermatopoeia* "Just, trust me. If a user isn't logged in, return 401, if they don't have permissions you send 403"
Team: *googles SO* "Internet says we can use 500"
Me: "That's server error, it says something blew up with an unhandled exception on your end. You've already established it was an auth issue in the logs."
Team: "But there's an error, why doesn't that work?"
Me: "It's generic. It's like me messaging you and saying, "your service is broken". It doesn't give us any insight into what went wrong or *how* we should attempt to troubleshoot the error or where it occurred. You already know what's wrong, so just tell me with the status code."
Team: "But it's ok, right, 500? It's an error?"
Me: "It puts all the troubleshooting responsibility on your consumer to investigate the error at every level. A precise error code could potentially prevent us from bothering you at all."
Team: "How so?"
Me: "Send 401, we know that it's a login issue, 403, something is wrong with the request, 404 we're hitting an endpoint that doesn't exist, 503 we know that the service can't be reached for some reason, 504 means the service exists, but timed out at the gateway or service. In the worst case we're able to triage who needs to be involved to solve the issue, make sense?"
Team: "Oh, sounds cool, so how do we do that?"
Me: "That's down to your technology, your team will need to implement it. Most frameworks handle it out of the box for many cases."
Team: "Ah, ok. We'll send a 500, that sound easiest"
Me: *..l.. -__- ..l..* "Ok, let's get into the other 5 problems with this situation..."
Moral of the story: If this is you: learn the protocol you're utilizing, provide metadata, and stop treating your customers like shit.21 -
Finally got a 200 response back from the server! Woo!
I've spent two days trying to get this to work (see my earlier rant). but yay! finally working!
So I log the response body just to revel in its lovely glow.... only to notice an error message saying "INVALID_INPUT".
WHAT THE CRAP.
200 FOR AN ERROR RESPONSE?
COME ON.4 -
Victory!
Today I finally closed a 'Nessy' bug (A scary bug you can't reproduce typically only sighted by one person). Below is my response...
"There were no errors in the error logs because writing to the error log was causing the error." 5
5 -
Manager: Hey how come you left so many comments on my PR?
Dev: Well you’ve just recently learned how to code so there’s going to be a lot of things to learn beyond what you’ve picked up in your online coding tutorials. Don’t worry it’s only minor things like you put everything all in one function, left outdated comments in the code, have if statements 4 levels deep, have a console.log after every line of code some of which log .env variables, skipped error handling, cast to “any” a bunch instead of using more specific types, didn’t write any tests and some unrelated tests are now failing due to a circular dependancy.
Manager: THAT IS SO DISRESPECTFUL!!APPROVE MY PR IMMEDIATELY. IT WASN’T EVEN EASY FOR ME TO CREATE THE PR, NOW I HAVE TO MAKE AN UPDATE!? YOU’RE THE DEV, YOU SHOULD FIX IT NOT ME!! NEVER COMMENT ON ANY OF MY PRS AGAIN.9 -
I've had many, but this is one of my favorite "OK, I'm getting fired for this" moments.
A new team in charge of source control and development standards came up with a 20 page work-instruction document for the new TFS source control structure.
The source control kingpin came from semi-large military contract company where taking a piss was probably outlined somewhere.
Maybe twice, I merged down from a release branch when I should have merged down from a dev branch, which "messed up" the flow of code that one team was working on.
Each time I was 'coached' and reminded on page 13, paragraph 5, sub-section C ... "When merging down from release, you must verify no other teams are working
on branches...blah blah blah..and if they have pending changes, use a shelfset and document the changes using Document A234-B..."
A fellow dev overheard the kingpin and the department manager in the breakroom saying if I messed up TFS one more time, I was gone.
Wasn't two days later I needed to merge up some new files to Main, and 'something' happened in TFS and a couple of files didn't get merged up. No errors, nothing.
Another team was waiting on me, so I simply added the files directly into Main. Unknown to me, the kingpin had a specific alert in TFS to notify him when someone added
files directly into Main, and I get a visit.
KP: "Did you add a couple of files directly into Main?"
Me:"Yes, I don't what happened, but the files never made it from my branch, to dev, to the review shelfset, and then to Main. I never got an error, but since
they were new files and adding a new feature, they never broke a build. Adding the files directly allowed the Web team to finish their project and deploy the
site this morning."
KP: "That is in direct violation of the standard. Didn't you read the documentation?"
Me: "Uh...well...um..yes, but that is an oddly specific case. I didn't think I hurt any.."
KP: "Ha ha...hurt? That's why we have standards. The document clearly states on page 18, paragraph 9, no files may ever be created in Main."
Me: "Really? I don't remember reading that."
<I navigate to the document, page 18, paragraph 9>
Me: "Um...no, it doesn't say that. The document only talks about merging process from a lower branch to Main."
KP: "Exactly. It is forbidden to create files directly in Main."
Me: "No, doesn't say that anywhere."
KP: "That is the spirit of the document. You violated the spirit of what we're trying to accomplish here."
Me: "You gotta be fracking kidding me."
KP grumbles something, goes back to his desk. Maybe a minute later he leaves the IS office, and the department manager leaves his office.
It was after 5:00PM, they never came back, so I headed home worried if I had a job in the morning.
I decided to come in a little early to snoop around, I knew where HR kept their terminated employee documents, and my badge wouldn't let me in the building.
Oh crap.
It was a shift change, so was able to walk in with the warehouse workers in another part of the building (many knew me, so nothing seemed that odd), and to my desk.
I tried to log into my computer...account locked. Oh crap..this was it. I'm done. I fill my computer backpack with as much personal items as I could, and started down the hallway when I meet one of our FS accountants.
L: "Hey, did your card let you in the building this morning? Mine didn't work. I had to walk around to the warehouse entrance and my computer account is locked. None of us can get into the system."
*whew!* is an understatement. Found out later the user account server crashed, which locked out everybody.
Never found out what kingpin and the dev manager left to talk about, but I at least still had a job.13 -
I'm trying to sign up for insurance benefits at work.
Step 1: Trying to find the website link -- it's non-existent. I don't know where I found it, but I saved it in keepassxc so I wouldn't have to search again. Time wasted: 30 minutes.
Step 2: Trying to log in. Ostensibly, this uses my work account. It does not. Time wasted: 10 minutes.
Step 3: Creating an account. Username and Password requirements are stupid, and the page doesn't show all of them. The username must be /[A-Za-z0-9]{8,60}/. The maximum password length is VARCHAR(20), and must include upper/lower case, number, special symbol, etc. and cannot include "password", repeated charcters, your username, etc. There is also a (required!) hint with /[A-Za-z0-9 ]{8,60}/ validation. Want to type a sentence? better not use any punctuation!
I find it hilarious that both my username and password hint can be three times longer than my actual password -- and can contain the password. Such brilliant security.
My typical username is less than 8 characters. All of my typical password formats are >25 characters. Trying to figure out memorable credentials and figuring out the hidden complexity/validation requirements for all of these and the hint... Time wasted: 30 minutes.
Step 4: Post-login. The website, post-login, does not work in firefox. I assumed it was one of my many ad/tracker/header/etc. blockers, and systematically disabled every one of them. After enabling ad and tracker networks, more and more of the site loaded, but it always failed. After disabling bloody everything, the site still refused to work. Why? It was fetching deeply-nested markup, plus styling and javascript, encoded in xml, via api. And that xml wasn't valid xml (missing root element). The failure wasn't due to blocking a vitally-important ad or tracker (as apparently they're all vital and the site chain-loads them off one another before loading content), it's due to shoddy development and lack of testing. Matches the rest of the site perfectly. Anyway, I eventually managed to get the site to load in Safari, of all browsers, on a different computer. Time wasted: 40 minutes.
Step 5: Contact info. After getting the site to work, I clicked the [Enroll] button. "Please allow about 10 minutes to enroll," it says. I'm up to an hour and 50 minutes by now. The first thing it asks for is contact info, such as email, phone, address, etc. It gives me a warning next to phone, saying I'm not set up for notifications yet. I think that's great. I select "change" next to the email, and try to give it my work email. There are two "preferred" radio buttons, one next to "Work email," one next to "Personal email" -- but there is only one textbox. Fine, I select the "Work" preferred button, sign up for a faux-personal tutanota email for work, and type it in. The site complains that I selected "Work" but only entered a personal email. Seriously serious. Out of curiosity, I select the "change" next to the phone number, and see that it gives me four options (home, work, cell, personal?), but only one set of inputs -- next to personal. Yep. That's amazing. Time spent: 10 minutes.
Step 6: Ranting. I started going through the benefits, realized it would take an hour+ to add dependents, research the various options, pick which benefits I want, etc. I'm already up to two hours by now, so instead I decided to stop and rant about how ridiculous this entire thing is. While typing this up, the site (unsurprisingly) automatically logged me out. Fine, I'll just log in again... and get an error saying my credentials are invalid. Okay... I very carefully type them in again. error: invalid credentials. sajfkasdjf.
Step 7 is going to be: Try to figure out how to log in again. Ugh.
"Please allow about 10 minutes" it said. Where's that facepalm emoji?
But like, seriously. How does someone even build a website THIS bad?12 -
Dev: “Ughh..look at this –bleep- code! When I execute the service call, it returns null, but the service received a database error.”
Me: “Yea, that service was written during a time when the mentality was ‘Why return a service error if the client can’t do anything about it?’”
Dev: “I would say that’s a misunderstanding of that philosophy.”
Me: “I would say it’s a perfectly executed example of a deeply flawed philosophy.”
Dev: “No, the service should just return something that tells the client the operation failed.”
Me: “They did. It was supposed to return a valid result, and the developer indicated a null response means the operation failed. How you deal with the null response is up to you.”
Dev: “That is stupid. How am I supposed to know a null response means the operation failed?”
Me: “OK, how did you know the operation failed?”
Dev: “I had to look at the service error logs.”
Me: “Bingo.”
Dev: “This whole service is just a –bleep-ing mess. There are so many things that can go wrong and the only thing the service returns is null when the service raises an exception.”
Me: “OK, what should the service return?”
Dev: ”I don’t know. Error 500 would be nice.”
Me: “Would you know what to do with error 500?”
Dev: ”Yea, I would look at the error log”
Me: “Just like you did when the service returned null?”
<couple of seconds of silence>
Dev: “I don’t know, it’s a –bleep-ing mess.”
Me: “You’re in the code, change it.”
Dev: “Ooohhh no, not me. The whole thing will have to be re-written. It should have been done correctly the first time. If we had time to do code reviews, I would have caught this –bleep- before the service was deployed.”
Me: “Um, you did.”
<a shocked look from Dev>
Dev: “What…no, I’ve never seen this code.”
Me: “I sat next to Chuck when you were telling him he needed to change the service to return null if an exception was raised. I remember you telling him specifically to pop-up an error dialog ‘Service request failed’ to the user when the service returned null.”
Dev: “I don’t remember any of that.”
Me: “Well, Chuck did. He even put it in the check-in comments. See…”
<check in comments stated Dev’s code review and dictated the service return null on exceptions>
Dev: “Hmm…I guess I did. –bleep- are you a –bleep-ing elephant? You –bleep-ing remember everything.”
<what I wanted to say>
No, I don’t remember everything, but I remember all the drive-by <bleep>-ed up coding philosophies you tried to push to the interns and we’re now having all kinds of problems I spend waaaaay too much time fixing.
<what I said, and lied a little bit>
Me: “No, I was helping Nancy last week troubleshoot the client application last week with the pop-up error. Since the service returned a null, she didn’t know where to begin to look for the actual error.”
Dev: “Oh.”1 -
Overheard a phone call between the Senior Network Engineer and a contracted Printer-company at 9am this morning. Photocopier was giving a 'functional error' message on-screen and not printing;
N.E:
I logged this call last
Thursday afternoon. Thats 1.5 days of the photocopier not working on our busiest site! Where's the engineer??
.... yes, that's the error message.
Yes, i can log into it, you should have the IP address from the call.
Yes, it's obviously pinging too.
Yes.... we've power-cycled the printer multiple times...
yes, tried that too...
yes, I've unplugged the network cable as well... left it for 15 minutes.
... sorry. What?
What did you say?
Are you f***ing kidding me?
Would you also like me to rub the side of the f***ing machine, and say a prayer while I'm at it??
*takes a deep breath*
Fine, I'll do that but when it doesn't work, i want someone out on the site before lunchtime today!
*slams phone down angrily*
N.E to me as he stomps out of the office;
He wants me to get the user to unplug the network cable and do a power cycle. How the f**k is that going to help? Idiots! Don't know why we have a contract with them, i could do a better job!!!
*comes back into office 5 minutes later*
Me: did it fix it?
NE: yeah. Damn.
*leaves room again to make apologetic phonecall*2 -
Hilariously cool error.
I mean, not everyday your editor tells you to meditate or sing you a bob Dylan’s song, right?
That’s a nice touch atom. 2
2 -
Some days I feel like I work in a different universe.
Last night our alerting system sent out a dept. wide email regarding a high number of errors coming from the web site.
Email shows the number of errors and a summary of the error messages.
Ex. 60 errors
59 Object reference not set to an instance of an object
1 The remote server returned an unexpected response: (413) Request Entity Too Large
Web team responds to the email..
"Order processing team's service is returning a 413 error. I'll fill out a corrective action ticket in the morning to address that error in their service. "
Those tickets are taken pretty seriously by upper mgmt, so I thought someone on the order processing team would point out the 1 error vs. 59 (coming from the web team's code).
Two hours go by, nobody responds, so I decide to jump into something that was none of my business.
"Am I missing something? Can everyone see the 59 null reference exceptions? The 413 exception only occurred once. It was the null reference exceptions that triggered the alert. Looking back at the logs, the site has been bleeding null reference exceptions for hours. Not enough for an alert, but there appears to be a bug that needs to be looked into."
After a dept. managers meeting this morning:
MyBoss: "Whoa..you kicked the hornets nest with your response last night."
Me: "Good. What happened?"
<Dan dept VP, Jake web dept mgr>
MyBoss: "Dan asked Jake if they were going to fix the null reference exceptions and Jake got pissed. Said the null reference errors were caused by the 413 error."
Me: "How does he know that? They don't log any stack traces. I don't think those two systems don't even talk to one another."
<boss laughs>
MyBoss:"That's what Dan asked!..oh..then Jake started in on the alert thresholds were too low, and we need to look into fixing your alerting code."
Me: "What!? Good Lord, tell me you chimed in."
MyBoss: "Didn't have to. Dan starting laughing and said there better be a ticket submitted on their service within the next hour. Then Jake walked out of the meeting. Oh boy, he was pissed."
Me: "I don't understand how they operate over there. It's a different universe.
MyBoss: "Since the alert was for their system, nobody looked at the details. I know I didn't. If you didn't respond pointing out the real problem, they would have passed the buck to the other team and wasted hours chasing a non-existent problem. Now they have to take resources away from their main project and answer to the VP for the delay. I'm sure they are prefixing your name right now with 'that asshole'"
Me: "Not the first, won't be the last."2 -
I wrote a database migration to add a column to a table and populated that column upon record creation.
But the code is so freaking convoluted that it took me four days of clawing my eyes out to manage this.
BUT IT'S FINALLY DONE.
FREAKING YAY.
Why so long, you ask? Just how convoluted could this possibly be? Follow my lead ~
There's an API to create a gift. (Possibly more; I have no bloody clue.)
I needed the mobile dev contractor to tell me which APIs he uses because there are lots of unused ones, and no reasoning to their naming, nor comments telling me what they do.
This API takes the supplied gift params, cherry-picks a few bits of useful data out (by passing both hashes by reference to several methods), replaces a couple of them with lookups / class instances (more pass-by-reference nonsense). After all of this, it logs the resulting (and very different) mess, and happily declares it the original supplied params. Utterly useless for basically everything, and so very wrong.
It then uses this data to call GiftSale#create, which returns an instance of GiftSale (that's actually a Gift; more on that soon).
GiftSale inherits from Gift, and redefines three of its methods.
GiftSale#create performs a lot of validations / data massaging, some by reference, some not. It uses `super` to call Gift#create which actually maps to the constructor Gift#initialize.
Gift#initialize calls Gift#pre_init (passing the data by reference again), which does nothing and returns null. But remember: GiftSale inherits from Gift, meaning GiftSale#pre_init supersedes Gift#pre_init, so that one is called instead. GiftSale#pre_init returns a Stripe charge object upon success, or a Gift (and a log entry containing '500 Internal') upon failure. But this is irrelevant because the return value is never actually used. Pass by reference, remember? I didn't.
We're now back at Gift#initialize, Rails finally creates a Gift object using the args modified [mostly] in-place by all of the above.
Another step back and we're at GiftSale#create again. This method returns either the shiny new Gift object or an error string (???), and the API logic branches on its type. For further confusion: not all of the method's returns are explicit, and those implicit return values are nested three levels deep. (In Ruby, a method will return the last executed line's return value automatically, allowing e.g. `def add(a,b); a+b; end`)
So, to summarize: GiftSale#create jumps back and forth between Gift five times before finally creating a Gift instance, and each jump further modifies the supplied params in-place.
Also. There are no rescue/catch blocks, meaning any issue with any of the above results in a 500. (A real 500, not a fake 500 like last time. A real 500, with tragic consequences.)
If you're having trouble following the above... yep! That's why it took FOUR FREAKING DAYS! I had no tests, no documentation, no already-built way of testing the API, and no idea what data to send it. especially considering it requires data from Stripe. It also requires an active session token + user data, and I likewise had no login API tests, documentation, logging, no idea how to create a user ... fucking hell, it's a mess.)
Also, and quite confusingly:
There's a class for GiftSale, but there's no table for it.
Gift and GiftSale are completely interchangeable except for their #create methods.
So, why does GiftSale exist?
I have no bloody idea.
All it seems to do is make everything far more complicated than it needs to be.
Anyway. My total commit?
Six lines.
IN FOUR FUCKING DAYS!
AHSKJGHALSKHGLKAHDSGJKASGH.7 -
Yesterday the web site started logging an exception “A task was canceled” when making a http call using the .Net HTTPClient class (site calling a REST service).
Emails back n’ forth ..blaming the database…blaming the network..then a senior web developer blamed the logging (the system I’m responsible for).
Under the hood, the logger is sending the exception data to another REST service (which sends emails, generates reports etc.) which I had to quickly re-direct the discussion because if we’re seeing the exception email, the logging didn’t cause the exception, it’s just reporting it. Felt a little sad having to explain it to other IT professionals, but everyone seemed to agree and focused on the server resources.
Last night I get a call about the exceptions occurring again in much larger numbers (from 100 to over 5,000 within a few minutes). I log in, add myself to the large skype group chat going on just to catch the same senior web developer say …
“Here is the APM data that shows logging is causing the http tasks to get canceled.”
FRACK!
Me: “No, that data just shows the logging http traffic of the exception. The exception is occurring before any logging is executed. The task is either being canceled due to a network time out or IIS is running out of threads. The web site is failing to execute the http call to the REST service.”
Several other devs, DBAs, and network admins agree.
The errors only lasted a couple of minutes (exactly 2 minutes, which seemed odd), so everyone agrees to dig into the data further in the morning.
This morning I login to my computer to discover the error(s) occurred again at 6:20AM and an email from the senior web developer saying we (my mgr, her mgr, network admins, DBAs, etc) need to discuss changes to the logging system to prevent this problem from negatively affecting the customer experience...blah blah blah.
FRACKing female dog!
Good news is we never had the meeting. When the senior web dev manager came in, he cancelled the meeting.
Turned out to be a hiccup in a domain controller causing the servers to lose their connection to each other for 2 minutes (1-minute timeout, 1 minute to fully re-sync). The exact two-minute burst of errors explained (and proven via wireshark).
People and their petty office politics piss me off.2 -
The reason why I changed my username ( I'll just be honest here )
I was working on a website. I noticed that entries were submitting yesterday but today new entries were not showing up on database. It was like my database refused to insert new rows but there was no new error in log. I kept trying for almost half an hour, read all the answers on stackoverflow, read docs, tried different methods. Nothing worked. I was fucked up. Completely fucked up.
In frustration, I just stared my database for 10 mins without a single blink, and then I noticed this thing 'showing 25 out of 78 rows'
(-_-)
I clicked on 'show all'
AAAAAAND
I felt retarded.
Okay I can give an excuse that last time I saw a database was a year ago, but still.. how retarded you need to be to not see this FUCKIN 'SHOW ALL' when it is on the TOP of the FUCKIN TABLE!!6 -
This code isn't working right, better check the log...
ERROR: There was an error.
Alright, cool, chill. Thanks for the top notch error handling. 👌2 -
So apparently due to an extremely talkative x input driver and an error in a certain app, I've been running an emergent keylogger on my computer for half a year. On every keypress event, the driver would call the app, the app would segfault, the driver would log the incident including the event to /var/log and then crash, and the app would restart the worker. I noticed this when I started wondering why /var/log is over 100GB in size.12
-
As usual finished the task just an hour before demo meeting. That hour is for transportation. Obviously I didn't test nor rehearse.
As usual, in to 2 mins of demo and greeted by error page.
As usual
1) stay the fuck calm
2) this features was already demo-ed and fixed and went fine few weeks ago
3) what the fuck happen now
4) stay the fuck calm, smile.
5) "ah please give me one minute, I forgot to clean up some stuff while working on new features"
6) shit shit. read the error message and log
7) oh I did refactor some files last week. Reorganized the files and folders for better structure and easier understanding. Thought I corrected every occurrences. Obviously I missed few.
8) ssh to the server while screen is still showing on projector
9) dig into the file quick
10) stay the fuck calm
11) fix
12) refresh
13) sorry all good, so I was saying ....
Well finally it's done for today and going back to office. After all it went ok. 👌2 -
1. Fucking MySQL database clusters.
There's nothing fun about MySQL clusters. Sometimes they start producing deadlock errors for no apparent reason... well, there's probably a reason, but it's never a transparent easy to find reason.
What was even less fun is that those errors took down a Sentry server. When your error log server goes down through ddos from your database messages, it's time to rethink your setup.
2. Wiring up a large factory with $2 arduino clones, each with a $2 esp8266 wifi chip, with various sensors for measuring flow of chemical solutions (I wanted cheap real time monitoring as an early warning system next to periodic sampling).
The scaling issue was getting over 500 streaming wifi signals to work in a 55c moist slightly corrosive atmosphere with concrete and steel everywhere, and getting it all into a single InfluxDB instance for analysis.12 -
Legacy code.
Honestly though, this is some of the better legacy code I've worked with at this company. It's a nifty alert system wherein you can trigger sending messages to subscribers of that alert via whatever means (phone/email) they've entered.
I'll save you the technical analysis of its internals, but suffice to say it's actually pretty nice, with good separation of concerns, internal logic hidden away, dead-simple public interface, etc. documentation is kinda crap, but it exists (!), so that's a nice change.
but.
For some unknown and bloody bizarre reason, the thing breaks when a user wants both sms AND email notifications. Either by themselves work totally fine, but both together? nonono. Email alerts give ArgumentErrors, so something internal isn't correct, and SMS alerts complain about uninitialized Twilio::Error constants.
but.
they both work fine otherwise?
also, the two notification preferences aren't stored on the same object anywhere. if a user wants both, the user creates two AlertContact objects with different info, and when performed, the Alert basically iterates over these and does its thing for each, so there is no knowledge shared between them. totally should work the same regardless.
idfgi.
ALSO.
AND THIS PART REALLY PISSES ME OFF.
WHEN THERE'S AN ERROR, THIS THING DOESN'T LOG IT. IT STRINGIFIES THE ERROR OBJECT (basically just extracting the message) AND INSERTS THAT INTO THE DATABASE INSTEAD. WHAT THE CRAP.
So, I don't get a stack trace, line number, or anything. just the basic error message. instead of my alert text. because of course that makes sense and totally helps debugging.
aklsjfak;sldfj.
legacy code.5 -
If you're an aspiring web dev, get comfortable using the command line.
Amazing how many new starters can't restart a service or tail an error log.
I'm not saying it to be a dick, it's just 101 stuff that'll save you loads of time.1 -
The website for our biggest client went down and the server went haywire. Though for this client we don’t provide any infrastructure, so we called their it partner to start figuring this out.
They started blaming us, asking is if we had upgraded the website or changed any PHP settings, which all were a firm no from us. So they told us they had competent people working on the matter.
TL;DR their people isn’t competent and I ended up fixing the issue.
Hours go by, nothing happens, client calls us and we call the it partner, nothing, they don’t understand anything. Told us they can’t find any logs etc.
So we setup a conference call with our CXO, me, another dev and a few people from the it partner.
At this point I’m just asking them if they’ve looked at this and this, no good answer, I fetch a long ethernet cable from my desk, pull it to the CXO’s office and hook up my laptop to start looking into things myself.
IT partner still can’t find anything wrong. I tail the httpd error log and see thousands upon thousands of warning messages about mysql being loaded twice, but that’s not the issue here.
Check top and see there’s 257 instances of httpd, whereas 256 is spawned by httpd, mysql is using 600% cpu and whenever I try to connect to mysql through cli it throws me a too many connections error.
I heard the IT partner talking about a ddos attack, so I asked them to pull it off the public network and only give us access through our vpn. They do that, reboot server, same problems.
Finally we get the it partner to rollback the vm to earlier last night. Everything works great, 30 min later, it crashes again. At this point I’m getting tired and frustrated, this isn’t my job, I thought they had competent people working on this.
I noticed that the db had a few corrupted tables, and ask the it partner to get a dba to look at it. No prevail.
5’o’clock is here, we decide to give the vm rollback another try, but first we go home, get some dinner and resume at 6pm. I had told them I wanted to be in on this call, and said let me try this time.
They spend ages doing the rollback, and then for some reason they have to reconfigure the network and shit. Once it booted, I told their tech to stop mysqld and httpd immediately and prevent it from start at boot.
I can now look at the logs that is leading to this issue. I noticed our debug flag was on and had generated a 30gb log file. Tail it and see it’s what I’d expect, warmings and warnings, And all other logs for mysql and apache is huge, so the drive is full. Just gotta delete it.
I quietly start apache and mysql, see the website is working fine, shut it down and just take a copy of the var/lib/mysql directory and etc directory just go have backups.
Starting to connect a few dots, but I wasn’t exactly sure if it was right. Had the full drive caused mysql to corrupt itself? Only one way to find out. Start apache and mysql back up, and just wait and see. Meanwhile I fixed that mysql being loaded twice. Some genius had put load mysql.so at the top and bottom of php ini.
While waiting on the server to crash again, I’m talking to the it support guy, who told me they haven’t updated anything on the server except security patches now and then, and they didn’t have anyone familiar with this setup. No shit, it’s running php 5.3 -.-
Website up and running 1.5 later, mission accomplished.6 -
Worst hack/attack I had to deal with?
Worst, or funniest. A partnership with a Canadian company got turned upside down and our company decided to 'part ways' by simply not returning his phone calls/emails, etc. A big 'jerk move' IMO, but all I was responsible for was a web portal into our system (submitting orders, inventory, etc).
After the separation, I removed the login permissions, but the ex-partner system was set up to 'ping' our site for various updates and we were logging the failed login attempts, maybe 5 a day or so. Our network admin got tired of seeing that error in his logs and reached out to the VP (responsible for the 'break up') and requested he tell the partner their system is still trying to login and stop it. Couple of days later, we were getting random 300, 500, 1000 failed login attempts (causing automated emails to notify that there was a problem). The partner knew that we were likely getting alerted, and kept up the barage. When alerts get high enough, they are sent to the IT-VP, which gets a whole bunch of people involved.
VP-Marketing: "Why are you allowing them into our system?! Cut them off, NOW!"
Me: "I'm not letting them in, I'm stopping them, hence the login error."
VP-Marketing: "That jackass said he will keep trying to get into our system unless we pay him $10,000. Just turn those machines off!"
VP-IT : "We can't. They serve our other international partners."
<slams hand on table>
VP-Marketing: "I don't fucking believe this! How the fuck did you let this happen!?"
VP-IT: "Yes, you shouldn't have allowed the partner into our system to begin with. What are you going to do to fix this situation?"
Me: "Um, we've been testing for months already went live some time ago. I didn't know you defaulted on the contract until last week. 'Jake' is likely running a script. He'll get bored of doing that and in a couple of weeks, he'll stop. I say lets ignore him. This really a network problem, not a coding problem."
IT-MGR: "Now..now...lets not make excuses and point fingers. It's time to fix your code."
IT-VP: "I agree. We're not going to let anyone blackmail us. Make it happen."
So I figure out the partner's IP address, and hard-code the value in my service so it doesn't log the login failure (if IP = '10.50.etc and so on' major hack job). That worked for a couple of days, then (I suspect) the ISP re-assigned a new IP and the errors started up again.
After a few angry emails from the 'powers-that-be', our network admin stops by my desk.
D: "Dude, I'm sorry, I've been so busy. I just heard and I wished they had told me what was going on. I'm going to block his entire domain and send a request to the ISP to shut him down. This was my problem to fix, you should have never been involved."
After 'D' worked his mojo, the errors stopped.
Month later, 'D' gave me an update. He was still logging the traffic from the partner's system (the ISP wanted extensive logs to prove the customer was abusing their service) and like magic one day, it all stopped. ~2 weeks after the 'break up'.8 -
Windows troubleshooting:
- Works on my system, therefore it's not an issue.
- Must be a hardware error.
- Obviously it's just cheap hardware.
- Have you tried turning it off and on again?
- Here's some obscure error code that leads nowhere.
- Have you tried "sfc /scannow"?
AS IF SFC IS A FUCKING SILVER BULLET!!!
- Our Indian support chap from answers.microsoft.com will help you.
RRRREEEEEEEEEEEEE!!!!!!!
Solution: quietly weep and reinstall your system.
Linux troubleshooting:
- There are good quality log files.
- You can run the program from the command-line and read both stdout and stderr from it.
- You can usually run the program with high verbosity options to help you track down the error.
- Even daemons can have their commands spawned from a dedicated shell, to see why they failed.
- Usually it's a configuration error and you can easily edit the configuration file.
- More often than not, the program will tell you why it failed.
Solution: usually easy to find.
I fucking love Windows. Because you know, it's so easy to troubleshoot and the support is so great!!!2 -
I had a huge epiphany on Friday... not all developers enjoy coding.
Discovered when they brought down 2 of our environments, well told them what was wrong with the changes in their code that caused the environments to break, gave them links directly to the file in the gitlab repo that needed to be updated, and...
They fucking went home. The change would’ve taken all of about 30-45 seconds to update and they fucking left.
This person’s team lead come storming in pissed off because her manager is furious about 2 environments going down and preventing everyone else from being able to deploy their changes.
We provide the exact same details to the team lead about what needs to be changed, and advise that her team member took off....
30 mins later, her manager is storming up to us (devops/sre) livid as hell.
Explain the situation for a third time... manager is like, why can’t you guys fix it?
Look here you dense motherfuckers, we can fix the code. We can be the plumbers that clean up your shit. But what value do you gain as a developer if you don’t understand how the systems work and you keep pushing shit in?
Made the changes, fixed the environments, done right? Wrong.
The original developer made more changes not knowing what would happen and thoroughly fucked the environments again.
This dumb-fucking dumpster fire of a dude then sends us a slack message. “It’s down again, can you fix it?”
Our manager steps in and tells us to send him a link to the logs and have him fix it himself!
Thank goodness we have a badass manager.
Send logs, send repo file links (again), and send line numbers in the logs to try and help just a bit more. Dude goes almost the whole day without fixing it, environments are down, other devs are pissed, we throw this dude to the wolves. His manager starts to head over and was about to talk with my team lead when our manager steps out of his office and tells him the in’s and out’s of the situation and that our job isn’t to play log parser/error fixer for the developers. This dude that’s breaking the environments needs to be the one to fix the issue and his team lead should be aware of the problems and should have been able to correct his errors before it ever came to us.
The amount of hand-holding we do is ridiculous.
(Disclaimer, this one guy making some mistakes doesn’t sound too bad, but this is actually a common occurrence for like 40% of all of our developers)
We literally have interns still in college running circles around some of our full time devs. I know I’m not a developer, but for anyone that’s new-ish to developing, when you see shit like that please don’t lose hope. Those ass-hats got into programming purely for a paycheck, not because of passion.
Stick with it and your greatness will know no bounds 👍
As for you craptastic dipstick lickers, FUCK YOU!!! Go back to school and learn how to give a damn.4 -
I've found and fixed any kind of "bad bug" I can think of over my career from allowing negative financial transfers to weird platform specific behaviour, here are a few of the more interesting ones that come to mind...
#1 - Most expensive lesson learned
Almost 10 years ago (while learning to code) I wrote a loyalty card system that ended up going national. Fast forward 2 years and by some miracle the system still worked and had services running on 500+ POS servers in large retail stores uploading thousands of transactions each second - due to this increased traffic to stay ahead of any trouble we decided to add a loadbalancer to our backend.
This was simply a matter of re-assigning the IP and would cause 10-15 minutes of downtime (for the first time ever), we made the switch and everything seemed perfect. Too perfect...
After 10 minutes every phone in the office started going beserk - calls where coming in about store servers irreparably crashing all over the country taking all the tills offline and forcing them to close doors midday. It was bad and we couldn't conceive how it could possibly be us or our software to blame.
Turns out we made the local service write any web service errors to a log file upon failure for debugging purposes before retrying - a perfectly sensible thing to do if I hadn't forgotten to check the size of or clear the log file. In about 15 minutes of downtime each stores error log proceeded to grow and consume every available byte of HD space before crashing windows.
#2 - Hardest to find
This was a true "Nessie" bug.. We had a single codebase powering a few hundred sites. Every now and then at some point the web server would spontaneously die and vommit a bunch of sql statements and sensitive data back to the user causing huge concern but I could never remotely replicate the behaviour - until 4 years later it happened to one of our support staff and I could pull out their network & session info.
Turns out years back when the server was first setup each domain was added as an individual "Site" on IIS but shared the same root directory and hence the same session path. It would have remained unnoticed if we had not grown but as our traffic increased ever so often 2 users of different sites would end up sharing a session id causing the server to promptly implode on itself.
#3 - Most elegant fix
Same bastard IIS server as #2. Codebase was the most unsecure unstable travesty I've ever worked with - sql injection vuns in EVERY URL, sql statements stored in COOKIES... this thing was irreparably fucked up but had to stay online until it could be replaced. Basically every other day it got hit by bots ended up sending bluepill spam or mining shitcoin and I would simply delete the instance and recreate it in a semi un-compromised state which was an acceptable solution for the business for uptime... until we we're DDOS'ed for 5 days straight.
My hands were tied and there was no way to mitigate it except for stopping individual sites as they came under attack and starting them after it subsided... (for some reason they seemed to be targeting by domain instead of ip). After 3 days of doing this manually I was given the go ahead to use any resources necessary to make it stop and especially since it was IIS6 I had no fucking clue where to start.
So I stuck to what I knew and deployed a $5 vm running an Nginx reverse proxy with heavy caching and rate limiting linked to a custom fail2ban plugin in in front of the insecure server. The attacks died instantly, the server sped up 10x and was never compromised by bots again (presumably since they got back a linux user agent). To this day I marvel at this miracle $5 fix.1 -
!!oracle
I'm trying to install a minecraft modpack to play with a friend, and I'm super psyced about it. According to the modpack instructions, the first step is to download the java8 jre. Not sure if I actually need it or not, but it can download while I'm doing everything else, so I dutifully go to the download page and find the appropriate version. The download link does point to the file, but redirects to a login page instead. Apparently I need an oracle account to download anything on their site. stupid.
So I make an account. It requires my life story, or at least full name and address and phone number. stupid. So my name is now "fuck off" and I live in Hell, Michigan. My email is also "gofuckyourself" because I'm feeling spiteful. Also, for some reason every character takes about 3/4ths of a second to type, so it's very slow going. Passwords also cannot contain spaces, which makes me think they're doing some stupid "security" shenanigans like custom reversible encryption with some 5th grade math. or they're just stupid. Whatever, I make the stupid account.
Afterwards, I try to log in, but apparently my browser-saved credentials are wrong? I try a few more times, try enabling all of the javascripts, etc. No beans. Okay, maybe I can't use it until I verify the email? That actually makes some sense. Fine, I go check the throwaway inbox. No verification email. It's been like five minutes, but it's oracle so they probably just failed at it like everything else, so I try to have them resend the email. I find the resend link, and try it. Every time I enter my email address, though, it either gives me a validation error or a server error. I try a few mores times, and give up. I try to log in again; no dice. Giving up, I go do something else for awhile.
On a whim later, I check for the verification email again. Apparently it just takes bloody forever, but it did show up. Except instead of the first name "Fuck" I entered, I'm now "Andrew", apparently. okay.... whatever. I click the verify button anyway, and to my surprise it actually works, and says that I'm now allowed to use my account. Yay!
So, I go back to the login page (from the download link) and enter my credentials. A new error appears! I cannot use redirects, apparently, and "must type in the page address I want to visit manually." huh? okay, i go to the page directly, and see the same bloody error because of course i do because oracle fucking sucks. So I close the page, go back to the download list, click the link, wait for the login page redirect (which is so totally not allowed, apparently, except it works and manual navigation does not. yay backwards!), and try to log in.
Instead of being presented with an error because of the redirect, it lets me (try to) log in. But despite using prefilled creds (and also copy/pasting), it tells me they're invalid. I open a new tab container, clear the cache (just to be thorough), and repeat the above steps. This time it redirects me to a single signon server page (their concept of oauth), and presents me with a system error telling me to contact "the Administrator." -.- Any second attempts, refreshes, etc. just display the same error.
Further attempts to log in from the download page fail with the same invalid credentials error as before.
Fucking oracle and their reverse Midas touch.10 -
WHAT THE ACTUAL FUCKING FUCK MICROSOFT?!!
I go to log into my laptop:
me: *enter the pin*
Windows: Error
me: Ok let's try the password...
Win: WRONG PASSWORD!
me: *checking my password manager* Nope, pretty sure that's correct... Ok, whatever let's try to reset it.
me: *generates new password and resets the password for the account*
Windows: You can now log in
me: *enters the new password*
Windows: WRONG PASSWORD!
me: that's weird... let's try that again
Windows: WRONG PASSWORD!
me: Ok... reset once more *I enter the same password I generated before*
Windows: ThAt Is An OlD pAsSwOrD
me: *getting really pissed* FINE, GODDAMIT, HERE, NEW PASSWORD
Windows: You can now log in
me: *enters the new new password*
Windows: wRoNg PaSsWoRd!
jdjsjcjj+3+@!o(€;#@!(&(1!!#((#(€_"jsjeucjcjfdjosdifhshabxnfnxjsosoguwqlqqlall#7@+1(
aaaaaáaaaaaaaaaaaaaaaaaaaaaaaaaa
FUCK FUCK FUCK FUCK FUCK FUCK FUCK
YOU FUCKING INCOMPETENT CUNTS AT MICROSOFT!!!!!1!!!!!!!
I'M GONNA FUCKING TEAR YOU INTO THOUSAND PIECES AND THEN RUN YOU THROUGH A SHREDDER!!
YOU MOTHERFUCKING IDIOTIC CUNTS
FREAKING DEGENERATES22 -
Real fact: 1999
IT: IT, how can I help?
MrB: I'm Butcheek. This program is shit, I can't even log-in!
IT: oh.. Ok Mr. Butcheek, let’s see if I can help...
MrB: of course you can: fix this shitty program and made me log in!
IT: I’ll try to do my best to assist you, can you...
MrB: I just want to log in! Can you speak my language? This new program is ridiculous, I wonder why you IT guys changed the old one, it was a mess but at least I could log in...
IT: I'm sorry you are experiencing this problem, but to assist you I need to know exactly what's the problem
MrB: I CANT LOG IN!!!
IT: ok, I understand this, but can you please provide some more information? Do you receive any particular error messages?
MrB: it says “wrong password” but it's not true!
IT: Ok, that's strange. Look, I'm resetting your password and then you will try again. At the first log in you will be asked to change it again, ok?
MrB: just be quick, I can't waste any more time on this!
IT: sure... Ok done. Please, can you try again? The password is “butcheek”
MrB: it asks for the username. What am I supposed to write here?
IT: “butcheek”
MrB: oh... Ok. And what's the password?
IT: “butcheek”
MrB:... No... Wait... Ok, “butcheek” is the password but what's the username?
IT: “butcheek”!
MrB: you don't understand, I have to put both username AND password!
IT: I know! “butcheek”! For both username AND password!
MrB: so I have to write “butcheek”-”butcheek”?
IT: yes, “butcheek”-”butcheek”!
MrB: so... “butcheek”...twice? Sounds weird... are you sure?
IT: yes I'm sure! However, you can choose either to write “butcheek” twice or “ASS” once, if you prefer...4 -
Today, I suddenly received a "build error" email for master on a project that I am working on with my grp.
So I panicked and opened the log to see who messed up. This is what I see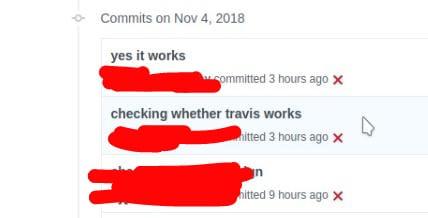
-
Recently wrote a script that would check 2 years worth of images, crop them, and resize to different sizes as changes to front end required those.
Eventually the script went into an infinite loop and crashed the whole CMS.
The worst part was that my manager was on a date and I had to call him back into office, since his laptop was still at the office.
The actual problem wasn't the loop.. I forgot to check if file actually exists before cropping... Error log size was 10gb!1 -
What features would you want in a logger?
Here's what I'm planning so far:
- Tagged entries for easy scanning of log file
- Support for indenting to group similar sequential entries
- Multiple entry types (normal, info, event, warning, error, fatal, debug, verbose)
- Meta entries, so the logger logging about itself, e.g. disk i/o failures.
- Ability to add custom entry types, including tag, log-level, etc.
- Customizable timestamp function
- Support for JS's async nature -- this equates to passing a unique key per 'thread'; the logger will re-write all the parent blocks for context, if necessary. if that sounds confusing, it's okay; just trust that it makes sense.
- Caching, retries, etc. in the event of disk i/o issues.
- Support for custom writers, allowing you to e.g. write logs to an API rather than console or disk.
How about these features?
- Multiple (named) logs with separate writers (console, disk, etc.)
- Ability to individually enable/disable writing of specific entry types. (want verbose but not info? sure thing, weirdo!)
- Multiple writers per log. Combined with the above, this would allow you to write specific entry types (e.g. error, warning, fatal) to stderr instead of stdout, or to different apis.
- Ability to write the same log entry to multiple logs simultaneously
What do you think of these features?
What other features would you want?
I'm open to suggestions!17 -
So I just wanted to log back into windows. Typed in the password. Wrong password...
Then I tried being super accurate while typing and also checked keyboard layout, etc. Still, wrong password.
Then I noticed that the letter p is not working. Shit, keyboard seems to be broken.
On screen keyboard -> p is not working...
What the hell? What kind of error is this?
NT Kernel code has to be something like this:
if(timeSinceLastError > someValue)
keyboard.p.enable = false;
I guess you could also replace the keyboard error with some random error.
If you encounter this, restart Windows.3 -
Did a bunch more cowboy coding today as I call it (coding in vi on production). Gather 'round kiddies, uncle Logan's got a story fer ya…
First things first, disclaimer: I'm no sysadmin. I respect sysadmins and the work they do, but I'm the first to admit my strengths definitely lie more in writing programs rather than running servers.
Anyhow, I recently inherited someone else's codebase (the story of my profession career, but I digress) and let me tell you this thing has amateur hour written all over it. It's written in PHP and JavaScript by a self-taught programmer who apparently discovered procedural programming and decided there was nothing left to learn and stopped there (no disrespect to self-taught programmers).
I could rant for days about the various problems this codebase has, but today I have a very specific story to tell. A story about errors and logs.
And it all started when I noticed the disk space on our server was gradually decreasing.
So today I logged onto our API server (Ubuntu running Apache/PHP) and did a df -h to check the disk space, and was surprised to see that it had noticeably decreased since the last time I'd checked when everything was running smoothly. But seeing as this server does not store any persistent customer data (we have a separate db server) and purely hosts the stateless API, it should NOT be consuming disk space over time at all.
The only thing I could think of was the logs, but the logs were very quiet, just the odd benign message that was fully expected. Just to be sure I did an ls -Sh to check the size of the logs, and while some of them were a little big, nothing over a few megs. Nothing to account for gigabytes of disk space gradually disappearing.
What could it be? I wondered.
cd ../..
du . | sort --sort=numeric
What's this? 2671132 K in some log folder buried in the api source code? I cd into it and it turns out there are separate PHP log files in there, split up by customer, so that each customer of ours (we have 120) has their own respective error log! (Why??)
Armed with this newfound piece of (still rather unbelievable) evidence I perform a mad scramble to search the codebase for where this extra logging is happening and sure enough I find a custom PHP error handler that is capturing (most) errors and redirecting them to these individualized log files.
Conveniently enough, not ALL errors were being absorbed though, so I still knew the main error_log was working (and any time I explicitly error_logged it would go there, so I was none the wiser that this other error-catching was even happening).
Needless to say I removed the code as quickly as I found it, tail -f'd the error_log and to my dismay it was being absolutely flooded with syntax errors, runtime PHP exceptions, warnings galore, and all sorts of other things.
My jaw almost hit the floor. I've been with this company for 6 months and had no idea these errors were even happening!
The sad thing was how easy to fix all the errors ended up being. Most of them were "undefined index" errors that could have been completely avoided with a simple isset() check, but instead ended up throwing an exception, nullifying any code that came after it.
Anyway kids, the moral of the story is don't split up your log files. It makes absolutely no sense and can end up obscuring easily fixable bugs for half a year or more!
Happy coding.6 -
No one fucking knows how to handle/raise errors.
I feel like this is the least talked topic in all fucking programming industry. This shit needs to be tought even more than the fucking SOLID, DRY, KISS, YAGNI and other kinds of buzzwords that fancy devs love tossing left and right.
Basically everyone just does "whatever you dumb error just dont bother me". They will just log/return null/ignore the errors and be in their oblivion with bugs propagating upstream the call stack.
"Throwing errors you say? Ew, why do you want to produce more errors?". Yeah, right, just stick another log/return null/or ignore the fact that the monke calling your function with bullshit arguments.
"But bro it's so difficult and time consuming and it would never happen!" Yes, you fucker! Yes! Programming IS fucking difficult if you want reliable systems! Did you not know that!? Well now you do! Go and fucking learn it!
FUCK!11!1!!22 -
So we have an API that my team is supposed send messages to in a fire and forget kind of style.
We are dependent on it. If it fails there is some annoying manual labor involved to clean that mess up. (If it even can be cleaned up, as sometimes it is also time-sensitive.)
Yet once in a while, that endpoint just crashes by letting the request vanish. No response, no error, nothing, it is just gone.
Digging through the log files of that API nothing pops up. Yet then I realize the size of the log files. About ~30GB on good old plain text log files.
It turns out that that API has taken the LOG EVERYTHING approach so much too heart that it logs to the point of its own death.
Is circular logging such a bleeding edge technology? It's not like there are external solutions for it like loggly or kibana. But oh, one might have to pay for them. Just dump it to the disk :/
This is again a combination of developers thinking "I don't need to care about space! It's cheap!" and managers thinking "100 GB should be enough for that server cluster. Let's restrict its HDD to 100GB, save some money!"
And then, here I stand trying to keep my sanity :/1 -
- Why isn't this script working
- Review Error Log
"Incorrect Syntax: line 122"
- There is no line 122
**3 Hours Pass
- Damn had an old broken version of the script still running in the background 😐🔫 -
Day 3 of getting this god forsaken react app to launch!!
My fucking god you cock suckers make life difficult.
Npm install - they say
Npm start - that say
Npm - go swallow my god awful error log and fix all these dependencies
Npm - here's a dependency that didn't install but I need it
Npm - what do you mean your not using a fucking Mac with sass files!
C0D4 - I'm this.close() to fucking stabbing someone!12 -
Boss: "So I'm taking the next week off. In the mean time, I added some stuff for you to do on Gitlab, we'd need you to pull this Docker image, run it, setup the minimal requirement and play with it until you understand what it does."
Me: "K boss, sounds fun!" (no irony here)
First day: Unable to login to the remote repository. Also, I was given a dude's name to contact if I had troubles, the dude didn't answer his email.
2nd day: The dude aswered! Also, I realized that I couldn't reach the repository because the ISP for whom I work blocks everything within specific ports, and the url I had to reach was ":5443". Yay. However, I still can't login to the repo nor pull the image, the connection gets closed.
3rd day (today): A colleague suggested that I removed myself off the ISP's network and use my 4G or something. And it worked! Finally!! Now all I need to do is to set that token they gave me, set a first user, a first password and... get a 400 HTTP response. Fuck. FUCK. FUUUUUUUUUUUUUUUUUUUCK!!!
These fuckers display a 401 error, while returning a 400 error in the console log!! And the errors says what? "Request failed with status code 401" YES THANK YOU, THIS IS SO HELPFUL! Like fuck yea, I know exactly how t fix this, except that I don't because y'all fuckers don't give any detail on what could be the problem!
4th day (tomorrow): I'm gonna barbecue these sons of a bitch
(bottom note: the dude that answered is actually really cool, I won't barbecue him)5 -
Project Leader is explaining to teammate how their UI will call my API and it'll run asynchronously in the background. UI guy asks: about error handling? I said the callback listener will be notified if anything goes wrong. I ask the PL, what next? just log and forget about it (that's my sarcasm)? How would anyone know this has failed?
PL says: good point and can worry about this later. Lets first focus on getting things to work.
You know later never comes. Well, except when the customer reports a problem. Its like every disaster movie you've ever seen before -
The feeling when random dudes downvote a question, because a guy who finally earned some points on SO dared to format the code with `<code>`<br> He pasted code, log, even explained a little bit and ~500 point guy even flags it like _unclear_ although there's clearly visible import error.
I mean... as an answerer or moderator, I'd be damn ashamed for such behavior! I have absolutely no problem kick a person with words + explanation in my answer or comment, so that (s)he remembers to ask better questions and feels bad about that, because nooby questions are already answered so many times there.
But to downvote because of formatting even if you have a permission to edit and a flag for low quality or because you can't read ~40 lines of log makes you just a retard and hurt the whole remaining community of guys like me who find time to sit there and answer questions to help another people.7 -
I call this one the tester than knew too much.
Note: The server the tester is running on has a hard drive that is breaking down...
Tester: Remember the error I talked to you about yesterday?
Me: Yeah, what about it?
Tester: Well the server hasn't recovered yet and I haven't restarted anything...
Me: Well the application itself hasn't crashed so our monitoring application doesn't seem to notice that the service is in a bad state. The error seems only to have brought down certain threads within the application.
Tester: No, I think there is a different issue here and has nothing to do with that error, the application is still doing things.
*tails the log*
Tester: See?
Me: As I said some things are still running and are unaffected by the error.
Tester: NO! It has to be caused by the other error I had a week ago where my file got corrupted. As we said I removed the file, restarted it and it worked again, but had the same problem a day later...
Note: The problem is not related, this time the application is running out of file descriptors
Me: Well... If the problem is the same it would have complained about the file descriptors then aswell, not an I/O error.
Tester: Nope, I think you are wrong!
Me: ¯\_(ツ)_/¯
FML 3
3 -
tl;dr:
The Debian 10 live disc and installer say: Heavens me, just look at the time! I’m late for my <segmentation fault
—————
tl:
The Debian 10 live cd and its new “calamares” installer are both complete crap. I’ve never had any issues with installing Debian prior to this, save with getting WiFi to work (as expected). But this version? Ugh. Here are the things I’ve run into:
Unknown root password; easy enough to get around as there is no user password; still annoying after the 10th time.
Also, the login screen doesn’t work off-disc because it won’t accept a blank password, so don’t idle or you’ll get locked out.
The lock screen is overzealous and hard-locks the computer after awhile; not even the magic kernel keys work!
The live disc doesn’t have many standard utilities, or a graphical partition editor. Thankfully I’m comfortable with fdisk.
The graphical installer (calamares) randomly segfaults, even from innocuous things like clicking [change partition] when you don’t have a partition selected. Derp.
It also randomly segfaults while writing partitions to disk — usually on the second partition.
It strangely seems less likely to segfault if the partitions are already there, even if it needs to “reformat” (recreate) them.
It also defaults to using MBR instead of GPT for the partition table, despite the tooltip telling you that MBR is deprecated and limited, and that GPT is recommended for new systems. You cannot change this without doing the partitions manually.
If you do the partitions manually and it can’t figure out where to install things, it just crashes. This is great because you can’t tell it where to install things, and specifying mount points like /boot, /, and /home don’t seem to be enough.
It also tries installing 32bit grub instead of 64bit, causing the grub installer to fail.
If you tell it to install grub on /boot, it complains when that partition isn’t encrypted — fair — but if you tell it to encrypt /boot like it wants you to, it then tries installing grub on the encrypted partition it just created, apparently without decrypting it, so that obviously fails — specific error: cannot read file system.
On the rare chance that everything else goes correctly, the install process can still segfault.
The log does include entries for errors, but doesn’t include an error message. Literally: “ERROR: Installation failed:” and the log ends. Helpful!
If the installer doesn’t segfault and the install process manages to complete, the resulting install might not even boot, even when installed without any drive encryption. Why? My guess is it never bothered to install Grub, or put it in the wrong place, or didn’t mark it as bootable, or who knows what.
Even when using the live disc that includes non-free firmware (including Ath9k) it still cannot detect my wlan card (that uses Ath9k).
I’ve attempted to install thirty plus times now, and only managed to get a working install once — where I neglected to include the Ath9k firmware.
I’m now trying the cli-only installer option instead of the live session; it seems to behave at least. I’m just terrified that the resulting install will be just as unstable as the live session.
All of this to copy the contents of my encrypted disks over so I can use them on a different system. =/
I haven’t decided which I’m going with next, but likely Arch, Void, or Gentoo. I’d go with Qubes if I had more time to experiment.
But in all seriousness, the Debian devs need some serious help. I would be embarrassed if I released this quality of hot garbage.
(This same system ran both Debian 8 and 9 flawlessly for years)15 -
Today was a manic-depressive kind of day. Spent the morning helping some developers with getting their code to run a stored procedure to drop old partitions, but it wasn't working on their end. It was a fairly simple proc. But working with partitions is a little like working with an array. I figured out that they were passing the wrong timestamp, and needed to add +1 to delete the right partition. Got that sorted out, and things were good. Lunch time.
After lunch I did some busy work, and then the PO comes up at about 2PM and says he's assigned some requests to me. The first was just attaching some scripts. Easy. The second, the user wants a couple of schemas exported ... at 6PM. I've been in the office since 6:45AM.
While I'm setting up some commands to run for the data export, a BA walks up and asks if I'm filling in for another DBA who is out for a few weeks. Yep. There's a change request that hasn't been assigned, and he normally does the work. I ask when it's due. Well, the pre-implementation was supposed to be done in the morning, but it wasn't, and we're in the implementation window ... half way through. I bring up the change task, and look at. Create new schema and users. That's all it says. The BA laughs. I tell I need more to go on. 10 minutes later he sends an email with the information. There's only two hours left in the window, and I can only use half of it, because the production guys have to their stuff, and we're in their window. Now I'm irritated, because I'm new to Oracle, and it's an unforgiving mistress. Fortunately, another DBA says he'll do it, so that we can get it done in time. But can't work it either, because Dev DBAs don't have access to QA, and the process required access for this task. Gets shelved until the access issue is resolved. It's now after 4:15PM. I'm going to in traffic with that 6PM deadline.
I manage to get home and to the computer by 5:45PM. Log in. Start VPN. Box pops on screen. Java needs to update. I chose skip update. Box pops up again. It won't let me log in until Java is current. Passed.
I finally get logged in, and it's 6:10PM. I'm late getting the job started. I pull up Putty and log into the first box, and paste my pre-prepared command in the command line and hit error. Command not found. I'm tired, so it's a moment to sink in. I don't have time for this.
I log into DBArtisan and pull up the first data base, use the wizard to set the job, and off it goes. Yay. Bring up the second database, and have enter the connect info. Host not found. Wut? Examine host name. Yep, it's correct. Try a different method. Host not found. Go back to Putty. Log in. Past string. Launch. Command not found. Now my brain is quitting on me. Why now? It's after 6:30PM. Fiddle with some settings, reset $Oracle home. Try again. Yay. It works. I'm done. It's after 7PM.
There is nothing like technology to snatch the euphoria of a success away from you. It's a love-hate thing, but I wouldn't trade it for anything else. I'm done. Good night.3 -
The feeling when everything works so smooth, but one little bug appears and you're like:
*covers the error log*
I don't see you, you little misery of mine... ^^
-
So I'm doing some OpenGL stuff in C++, for debugging I've created a macro that basically injects my error check code after every OpenGL API call. Basically I don't want any of the code in release builds but I want it to be in debug. Also it needs to be usable inline and accept any GL function return type. From what I can tell I've satisfied all requirements by making the macro generate a generic lambda that returns the original function call result but also creates a stack object that uses the scope to force my error check after the return statement by using the destructor.
Basically I can do:
Log(gl(GetString(...));
gl(DeleteShader(...));
Etc where the GL call can be a function parameter or not.
So my question is, is the code shown in the picture the best way to achieve my goals while providing the behaviour im going for? 13
13 -
A client is like: Help! We got a 500 in our wordpress administration panel and there is no error in the log, it must be your infrastructure at fault!
So I calmly replied to them that wordpress handles its errors on its own, and without the appropriate debug flags enabled, doesn't log it anywhere. Even mentioned that a PHP app can change the error handler no problem, and linked them to both, PHP and Word press docummentation.
Didn't hear from them since.2 -
These script kiddies fuck with my error metrics! I want 0 !
I swear I'll find them! Even enabled IP log for every request contain “.php”.
Needless to say, app is not even in PHP and PHP isn’t even present on server 12
12 -
I am beginning to hate the relationship between email and my clients. I never thought it would come to the point where email is the worst communication platform I've ever used because some of my clients simply don't know how to use it properly.
I have one client who never uses the subject header in his emails. This makes conversational threads very difficult to follow, and I can't just scan the inbox I have for him. I have to actually do searches on my emails just to find recent conversations.
For some reason nobody knows how to start a new email thread. I have multiple clients that will just take the last email that I sent them, regardless of what it's about, and start a new conversation completely unrelated to the other email by hitting"reply". I end up with email threads that are 60 to 100 emails long and contain many different subjects, which again makes it hard to find anything. Never mind that they've usually put two or three important attachments, or username password combinations, or other valuable information in there amongst all the noise.
Worst of all, I have a few clients and co-workers who insist on starting a new email thread whenever anything about a particular issue comes up. This means that just today I have five separate email threads about the same goddamn issue from the same damn person. Am I supposed to respond to each thread with the same damned information? One of these people is supposed to be both a media consultant and an SEO expert and really should know better. Also, if you do actually send me an email with a subject like "the robot.txt error", please don't give me one sentence about that and five paragraphs about what color you'd like the background to be. That's ridiculous. How the hell am I supposed to find that later? Especially since we already discussed this in the other email that sitting in my inbox.
I swear I am setting up a bug tracking system simply so that my clients can log in and leave me bug reports, and feature requests, and will stop filling up my poor email boxes with what amounts to piles and piles threads that I have to sort through.
For a person who suffers with a form of ADD this is extremely frustrating. Why is it so difficult for my colleagues and clients to write good emails with good subject lines, and reply to the right damn emails?
Am I just being too anal, or does this bother others as well?16 -
I use a library and it gives me some strange error message. No problemo, just file an issue on GitHub asking the maintainer if I'm plain stupid or the lib actually has a flaw. As it was a question, I have not posted a dump and all the shit.
Maintainer responds with a snarky comment about his crystal ball being broken and I have to submit a log, a dump, debug information and a bunch of other stuff.
Well, what choice do I have, I collect all the requested information, create a wall of text comment, all nicely formatted.
And the issue ends here. Myths say, the maintainer got asked to join Elvis on Mars.
I mean, why do you ask all the shit from me in a unprofessional manner just to stop answering? Just say "I have no clue why it behaves like this" and I know whats playin. But that's just ... sad.5 -
Had an internet/network outage and the web site started logging thousands of errors and I see they purposely created a custom exception class just to avoid/get around our standard logging+data gathering (on SqlExceptions, we gather+log all the necessary details to Splunk so our DBAs can troubleshoot the problem).
If we didn't already know what the problem was, WTF would anyone do with 'There was a SQL exception, Query'? OK, what was the exception? A timeout? A syntax error? Value out of range? What was the target server? Which database? Our web developers live in a different world. I don't understand em. 1
1 -
me vs marketing guy, again
me: yeah, the database server is not responding, so you cannot log in to post your blog, wait for it to get online.
MG: But, the website is online.
me: web host and database server are two distinct things, they are not the same, *share a screenshot of the error*
MG: Oh okay.
Literally 3 hours later this fucking idiot sends an email and I quote.
"Hi Dev,
@CTO FYI, Someone has removed this code So there is some tracking issue on it.
Please add below google analytics code on the website.
Note: Copy and paste this code as the first item into the <HEAD> of every web page that you want to track. If you already have a Global Site Tag on your page, simply add the config line from the snippet below to your existing Global Site Tag.
<!-- Global site tag (gtag.js) - Google Analytics -->
<script async src="https://googletagmanager.com/gtag/..."></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'UA-xxxxxxxx-1');
</script>
"
The fucking issue was of him not being able to post his shitty blog, and he shares an email like this, FOR FUCK'S SAKE!2 -
I gave this so called web developer username and password to ssh into our server. This is his reply:
"Hey we tried to log into your server. We are getting permission error. Please fix that"
Me: Sure, can you tell me how are you trying to connect?
"We tried to ssh like this: ssh root@xxx.com"
Me (in my mind): WHY THE FUCK ARE YOU USING ROOT FOR!?!9 -
TL;DR - the doctor is a lazy cunt and I hope he steps on a lego.
We’ve got a user authentication portal for all the users in our network. Well, we have it set to where you can only have two active log ins on two different machines, anything else will give the error message “you need to log out elsewhere” or whatever it is...
This god damn doctor has been told to log out several times and still calls us to ask why it’s “not working”.
I just received a call because the lazy cock sucker didn’t want to walk from the clinic to the hospital to sign out, are you fucking kidding me you lazy fucking ass hole? It’s not my job to be your mother fucking slave dude, get the fuck up and do it yourself!
I’ll take a lot of shit from anyone but when you refuse to retain the information to preform your job and want someone else to do it because you’re too fucking lazy, that’s when we’ve got problems.
I hope you step on a fucking LEGO.
I’m heavily medicated so if this doesn’t make sense I... don’t care. -
App fails, Check logs...No error logged. Check source code and debug....
And then you see following piece of code....
try{
//Code to hit an API
}catch(Exception ex){
/*DO NOTHING. Not even log stack trace*/
}7 -
This just happened....
Tester: My cluster is not working properly!!!
Me: What's wrong?
Tester: I don't know. I've checked all the logs available on the entire cluster. All i know is that node 1 and 7 is broken.
*ssh into the cluster*
node1
# less /var/log/<affected application log>.log
*no errors here everything is working properly*
node7
# less /var/log/<affected application log>.log
*goes down to the bottom and scrolls up a few lines*
<insert massive error here>
Checked all the logs eh? 3
3 -
saddest day of my life when system log gives me this
failed with status [ERROR]! - see null for further information1 -
When you make a mistake and try to fix it, but you can't remember how to spell amend...
git commit --ammend
error: unknown command `amend'
git commit -ammend
[branch-name] mend
Huh?
git log
commit #
mend
Created a new commit with message 'mend'. Now to clean this all up and go get some sleep!2 -
TL;DR: Google asked me to PROVIDE a phone number to verify connection from a new device, on the said device.
Yesterdayto log into my work Google account from my personal laptop to check emails, calendars update and so on. I opened up a private navigation window, went to Google sign-in page, entered my credentials, all is well.
Google then decided to "verify it's me" and prompted me to PROVIDE a phone number (work account without work phone means no phone number set up) so that they can send a verification code to the number I just provided to make sure the connection is legit.
Didn't want to do that, clicked "use another method" and got asked to fill the last password I remember, which would be my current password thanks to my trusty password manager. After submitting, I'm prompted with an error saying I have to contact my admin to reset my password because they can't log me in with my CURRENT password.
I ain't gonna do that, so went back to login page, provided my phone number, got the code, filled in the code, next thing I know I'm browsing through my emails.
What the duck? Could have been anybody giving any phone number. So much for extra security.
Also don't care that they have my phone number, the issue is more about the way used to obtain it: locking me out of my account and having no other way of logging in.6 -
So we have a portal for all our University courses, where the professors also upload the presentations, etc.
Professor sends Email: Please participate in this questionnaire.
*clicks link*
"Please log in to continue"
*logs in*
Error (while I am already logged in): "Please log in to continue"
????
No wonder some people nick name the thing stupid. <.< -
Fucking Square Enix Website is just a huge pile of shit. NOTHING WORKS!
Wanna change your password? Nah sorry an error occured.
Wanna change your username? Nah sorry I'll just show you a loading symbol forever.
Wanna add a game to your collection? Nah sorry the "add" button is on fucking holiday and doesn't do anything.
Wanna change your avatar? Nah sorry I'll just redirect you and don't do anything.
Most amazing part is where you log in, then get redirected to the home page but it still shows the "Log in" button. Then you click on that "Log In" button and wosh! Home page reloads and tada! You're logged in!
Seriously who let this code into production? Also I know that you're using GraphQL now, due to an error message. Thank you!
Fucking bullshit...6 -
Long meeting with a coworker presenting a huge, complicated system to track changes to configuration files.
Basically, whenever someone needs to change a config file, this person is supposed to manually enter an entry to a changelog file, and the build system is supposed to give an error if the person forgets to update the changelog.
At the end of the 1 hour long presentation, I raise my hand and say: "we are already using git for our config files, look:
$ git log <filename>
here you can see the list of changes to the file. What you describe is already available, no need to reinvent it."
Long akward silence in the room.
The presenter: "okay, I will look into that. Any other questions?"
Haven't heard about that project since then.1 -
The Windows SDK was failing to install because the version of vcredist was newer then it needed.
The setup simply failed without saying anything about that. I had to see the log and find out that vcredist failed to installed with error code 5100 and find that out from Google how to fix that.
Why is MS like this? Why not just say that your vcredist version is too new for this program? Just unistall it and it will be fixed?
I just wasted 2 hours behind this. If my work never needed it I would never even think about using this.1 -
A service had/has been logging hundreds of errors in the development environment and I reached out to the owning process mgr that the error was occurring and perhaps a good opportunity to log additional data to help troubleshoot the issue if the problem ever made its way to production. He responded saying the error was related to a new feature they weren't going to implement in the backing dev database (TL;DR), and they know it works in production (my spidey sense goes off).
They deployed the changes to production this morning and immediately starting throwing errors (same error I sent)
Mgr messaged me a little while ago "Did you make any changes to the documentation service? We're getting this error .."
50% sure someone misspelled something in a config, but only thing they are logging is 'Unable to parse document'. Nothing that indicates an issue with the service they're using.2 -
>Be client
>Have an issue with incredibly slow webpage load time
>Blame memcache issues
So... I look into the problem. Yes, the page either loads up fast, or times out. So, into the logs I go. Webserver is fine (except the timeout), PHP though... Error log is fine (just notices), but slow log shows the issue is the database (of course... its always the database... ugh)
So, checking the database, there is one ugly query that seems to be an issue. 5 joins and a huge where condition.
So I run EXPLAIN on the query and... Proceed to bang my head against the wall.
OF COURSE ITS SLOW YOU FU******, NONE OF YOUR TABLES HAVE ANY INDEXES.
What do they expect when the database has to always go down the whole table and do everything in memory, until it runs out and has to dump it all on disk and work with it there.
Ugh... Some clients... -
I am currently looking for a DAW (Digital Audio Workstation), because my music projects are starting to get a little too complex for Audacity.
So I started looking for a good, easy-to-learn, ideally free program, and quickly learned that Avid now has a free version of Pro Tools called First.
So I go to their site and fill out the registration form to get the download. In addition to creating an account with Avid, you also need to create one with iLok, which apparently has something to do with how they manage their licenses. Kinda overkill for a free program, but okay...
I download the program (about 3gigs...), install it and try to start it. It gives me an error message about missing some service. Okay? I'm confused because I notice that an 'Application Manager' service has appeared in my tray, and when I open that I can log into my new account just fine. But it still doesn't work.
There's a link in the error message to the iLok website, and it looks like ai need to dowload and install another component. Why didn't that get installed with the program if it's required?
Hmm...
So I go to the iLok site, download it and install it. Pro Tools First still won't start. I realize that the PTF installer asked me to reboot, which I didn't do because: a) I always have a lot of windows open, and b) How often is a reboot ACTUALLY required? Why would you need to reboot?
So I (begrudgingly) reboot, and now the program seems to start initializing... but then it throws an error message about some plugin that it can't load because it doesn't work for the 64 bit version. Then... why are you even looking for it?
And then it says something like: 'I can't handle that, I'm just gonna shut down'.
What?
I try starting it again. Same error appears, but then it gets past it this time... Only to throw another error message about something else it can't load, and therefore it must shut down.
Deep breath.
Third time is the charm, the program actually made it to the project create/load screen! Huzzah!
So I look around a bit, but don't do much. It doesn't seem too intuitive to me, so I start watching some tutorials on YouTube from Avid themselves. It's a little late by now, so I don't get my hands dirty that day.
Next time I want to try out the program I start it up, still get error messages, but it does seem to initialize okay. But then the 'Create project' button doesn't react when I press it.
It turns out that the program takes a looong time to log in to the avid account, even though the manager service is running and logged in...
When it finally logs on I create a new blank project, but it doesn't ask me where to save it to. I see there is a counter saying 1/3 and looking around I find some info about 'cloud based projects'.
It would seem that this program only supports saving projects to the cloud, and you get only 3 projects total. Three. THREE?
Ahem...
I add an instrument track to my new project and select the one and only plugin, which is a synth. I don't see the plugin window, like in the tutorials I watched. I fiddle around with the windows, but I only manage to get the layout fucked up. There's a handy 'Window' menu, but none of the options resets the view. The main window is now sporting a WINDOWS FUCKING 7 BORDER! And partially blocking the view of the top menu.
Blaaargh!
Frustrated, I shut the program down and restart it. I now select one of the project templates (after waiting for it to LOG IN AGAIN!) in the hope that I might have a bit more luck with that starting point.
But when the template has loaded, out of nowhere, the program goes from maximized to windowed mode! And the fucking Win7 border is back again, still messing with the main menu!
FFS!
I get the sucker maximized again and select one of the synth tracks, and Lo and Behold! The synth plugin window actually shows up! But of course there is no sound produced when I play, neither with the keyboard or my midi keyboard.
Oh no, that would have been too easy.
I see some the meters moving when I play, but no sound is produced. I check the options menu, but find out nothing useful except for the fact that the program only support 48kHz sample rate. That's pretty disappointing when you have a 192kHz/24bit soundcard.
I'm done. This piece of shit software is NOT for me. It's bloated, complicated to sign up for and install, extremely limited and buggy as hell!
The final insult is that it takes 5 minutes to uninstall because there is no uninstall option in the so-called 'Application Manager' (of course fucking not!), and doing it through Programs & Features there are 5 (FIVE!!) different apps and services to uninstall, one by one.
0/10, would not recommend.11 -
How on earth are there people in their second year of a computer science course who are unable to understand how to read build errors. It's honestly not that hard, just look at the fucking build log and see where the error is and what type of error it is, but yet they don't bother reading the log and say that their "compiler is broken" when their 5 line code won't work.
If this was still first year I'd understand since many of the class didn't have much programming knowledge, but if you're in your second year and you struggle with this (that too for a Hello World script) it looks like you aren't even bothered and just expect the computer to magically understand what you mean.3 -
Couldn't log in to my university campus website.
This is the error I got. :/
Better than "Something happened", I guess. 2
2 -
That's it, where do I send the bill, to Microsoft? Orange highlight in image is my own. As in ownly way to see that something wasn't right. Oh but - Wait, I am on Linux, so I guess I will assume that I need to be on internet explorer to use anything on microsoft.com - is that on the site somewhere maybe? Cause it looks like hell when rendered from Chrome on Ubuntu. Yes I use Ubuntu while developing, eat it haters. FUCK.
This is ridiculous - I actually WANT to use Bing Web Search API. I actually TRIED giving up my email address and phone number to MS. If you fail the I'm not a robot, or if you pass it, who knows, it disappears and says something about being human. I'm human. Give me free API Key. Or shit, I'll pay. Client wants to use Bing so I am using BING GODDAMN YOU.
Why am I so mad? BECAUSE THIS. Oauth through github, great alternative since apparently I am not human according to microsoft. Common theme w them, amiright?
So yeah. Let them see all my githubs. Whatever. Just GO so I can RELAX. Rate limit fuck shit workaround dumb client requirements google can eat me. Whats this, I need to show my email publicly? Verification? Sure just go. But really MS, this looks terrible. If I boot up IE will it look any better? I doubt it but who knows I am not looking at MS CSS. I am going into my github, making it public. Then trying again. Then waiting. Then verifying my email is shown. Great it is hello everyone. COME ON MS. Send me an email. Do something.
I am trying to be patient, but after a few minutes, I revoke access. Must have been a glitch. Go through it again, with public email. Same ugly almost invisible message. Approaching a billable hour in which I made 0 progress. So, lets just see, NO EMAIL from MS, Yes it appears in my GitHub, but I have no way to log into MS. Email doesnt work. OAuth isn't picking it up I guess, I don't even care to think this through.
The whole point is, the error message was hard to discover, seems to be inaccurate, and I can't believe the IRONY or the STUPIDITY (me, me stupid. Me stupid thinking I could get working doing same dumb thing over and over like caveman and rock).
Longer rant made shorter, I cant come up with a single fucking way to get a free BING API Key. So forget it MS. Maybe you'll email me tomorrow. Maybe Github was pretending to be Gitlab for a few minutes.
Maybe I will send this image to my client and tell him "If we use Bing, get used to seeing hard to read error messages like this one". I mean that's why this is so frustrating anyhow - I thought the Google CSE worked FINE for us :/
-
I'm trying to deploy an Azure Function via Visual Studio. VS gives me this error:
Publish has encountered an error.
Publish has encountered an error. We were unable to determine the cause of the error. Check the output log for more details.
A diagnostic log has been written to the following location:
"C:\Users\myusername\AppData\Local\Temp\tmp16F8.tmp"
Let's check the log then!
"Microsoft.WebTools.Shared.Exceptions.WebToolsException: Publish has encountered an error. We were unable to determine the cause of the error. Check the output log for more details. "
Fucking piece of crap1 -
GIT COMMMIT LOG VERSION 011
-------------------------
4cc7d0d Derp, asset redirection in dev mode
6b6e213 Lock S-foils in attack position
1e44549 I am even stupider than I thought
2f6bec9 You should have trusted me.
891851a To those I leave behind, good luck!
3367d77 Update .gitignore
46d6b0f Merging the merge
b12f6fe First Blood
0598e4f 8==========D
9151ff4 Finished fondling.
3a0ec1e ...
8358c20 c&p fail
bc1e834 magic, have no clue but it works
31bb17a I don't get paid enough for this shit.
21edb91 :(:(
7a71610 Stephen rebase plx?
2060661 Copy-paste to fix previous copy-paste
21ac5d2 Handled a particular error.
2dedd90 pam anderson is going to love me.
c3d4c83 omg what have I done?
d38bafd Herping the derp derp (silly scoping error)
e461773 Merge pull request #67 from Lazersmoke/fix-andys-shit Fix andys shit
1faf82b Is there an award for this?
1f6e3f3 Feed. You. Stuff. No time.
6f0097d I'm too old for this shit!
133179e I'm just a grunt. Don't blame me for this awful PoS.
d3e5202 harharhar
57d9a7c THE MEM TEST FUNCTION YOU ARE LOOKING FOR, IS HERE. SAY THANKS FOR THIS COMMIT MESSAGE -
I explained last week in great detail to a new team member of a dev team (yeah hire or fire part 2) why it is an extremely bad idea to do proactive error handling somewhere down in the stack...
Example
Controller -> Business/Application Logic -> Infrastructure Layer
(shortened)
Now in the infrastructure layer we have a cache that caches an http rest call to another service.
One should not implement retry or some other proactive error handling down in the cache / infra stack, instead propagate the error to the upper layer(s) like application / business logic.
Let them decide what's the course of action, so ...
1) no error is swallowed
2) no unintended side effects like latency spikes / hickups due to retries or similar techniques happens
3) one can actually understand what the services do - behaviour should either be configured explicitly or passed down as a programmed choice from the upper layer... Not randomly implemented in some services.
The explanation was long and I thought ... Well let's call the recruit like the Gremlin he is... Gizmo got the message.
Today Gizmo presented a new solution.
The solution was to log and swallow all exceptions and just return null everywhere.
Yay... Gizmo. You won the Oscar for bad choices TM.
Thx for not asking whether that brain fart made any sense and wasting 5 days with implementing the worst of it all.5 -
Bittrex is "amazing"...
I had lost my 2FA a long time ago (as my phone fried) and missed the account ferification deadline which caused my account to get disabled. Off we go to support!
0. Nothing to rant about at this point. I just created an account in their zendesk, logged in and logged a ticket to reset my 2FA and reactivate my account. They asked me for info, I provided it to them and got my 2FA disabled. Hooray!
1. I then asked to reenable my account. They sent me a link to restart the verification process. I open up that link and log in. I'm asked to upload some photos. I select requested photos from my galery and hit [UPLOAD]. An error pops up saying that smth wrong happened and I need to reload that site and reupload my photos. After page refresh they are telling me they are validating my uploaded info (w/o any way to resubmit my info, which, according to the error seen below, was not successfully submitted in the first place)...
2. So I reach out to the support guy again. Guess what he replies! He says he's sorry but he cannot help me any more and I need to create a NEW ACCOUNT in their support site with the same email <???!!!???>
3. I try to log in to the support portal and my access no longer works. MY ACCOUNT HAS BEEN DELETED! WTF!!!
4. I do as I'm told and create a new acc with the same email. Now I can log back in. So I'm raising a new ticket saying I still cannot finish my verification process due to the same error. It looks like it's going to be a fun ride with them so I can't wait to see what they'll reply.2 -
FUCK YOU FUCKING AZURE FUCKING FUNCTIONS:
EITHER LIMIT MY NUMBER OF TCP CONNECTIONS (before violently crashing)
or
FORCE ME TO USE THE GODDAMN PORT-PISSING, BARELY-MULTITHREAD-USABLE, SETTINGS-IGNORING EXCUSE OF A PATHETIC BUILT-IN HTTPCLIENT ON FUCKING CRACK (Seriously .net people fix that shit).
But not both... both are not okay!
If your azure function just moderately uses outgoing Http requests you will inevitably be fucked up by the dreaded connection exhaustion error. ESPECIALLY if using consumption plans.
I Swear, every day i am that much closer to permanently swearing off everything cloud based in favor of VM's (OH BUT THEN YOU HAVE TO MAINTAIN THE VM's BOO HOO, I HAVE TO BABYSIT THE GODDAMN CLOUD INFRASTRUCTURE AS WELL AT LEAST I CAN LOG IN TO A VM TO FIX SHIT, fuck that noise)
I am in my happy place today. At least I'm having great success diving into minecraft modding on the side, that shit is FUN!1 -
I've been skimming this slightly outdated "Learning Android" O'Reilly text and I found the error log levels to be colorful enough to be amusing...
 4
4 -
Look in a fu**ing log files...There you will find answers for almost 90% of "oh, i have some error" problems.2
-
The best/worst code comments you have ever seen?
Mine:
//Upload didn't work, have to react:
system.println('no result');
//$Message gives out a message in the compiler log.
{$Message Hint 'Feed the cat'}
//Not really needed
//Closed source - Why even comments?
//Looks like bullshit, but it has to be done this way.
//This one's really fucked up.
//If it crashes, click again.
asm JMP START end; //because no goto XP
catch {
//shit happens
}
//OMG!!! And this works???
asm
...
mov [0], 0 //uh, maybe there is a better way of throw an exception
...
mov [0], 0 //still a strange way to notify of an error
// this makes it exiting -- in other words: unstable !!!!!
//Paranoic - can't happen, but I trust no one.
else {
//please no -.-
sleep(0);
}
//wuppdi
for (int i = random(500); i < 1000 + random(500 + random(250)); i++)
{
// Do crap, so its harder to decompile
}
//This job would be great if it wasn't for the f**king customers.
//TODO: place this peace of code somewhere else...
// Beware of bugs in the code above; I have only proved it correct, not tried it.
{$IFDEF VER93}
//Good luck
{$DEFINE VER9x}
{$ENDIF}
//THIS SHIT IS LEAKING! SOMEONE FIX IT! :)
/* no comment */5 -
So today was interesting.
I had to extract the domain from an email address and compare the domain to a hard coded whitelist, nothing difficult, fuck takes 2 min really.
Except the project starts throwing 500 errors for no god damn reason, like seriously, I double check syntax, nope looks fine, run pho's syntax checker on the file
# php -l /path/to/file.php
Nope says it's all good.
Checks error log on server -> no log
OoooooooooKay then.
Comments out the few lines, saves, errors gone.
remove comments, error comes back.
Do this a few times, and magically the fucking thing stops throwing errors, now I haven't actually changed anything, and I know this project is so fragile I don't know how it stays running at times but fuck me this is a painful joke.6 -
A dev found a bug I created where I set a SQL parameter name to @OrderID instead of the expected @Order. The standard is @OrderID, there is one stored proc where it's @Order.
Oops...I didn't catch it because the integration test didn't cover that area of the code. My mistake...I should have checked...I take complete responsibility for the screw up.
He let me know by email..
"When refactoring, from now on check the stored procedure parameters, there are a few that don't follow the standard."
I was like "from now on..."? ...wow....bold comment from someone responsible for code that doesn't check for nulls, doesn't log errors, and relies on exceptions for flow control. You wouldn't even have known about the error if I didn't modify your code to log the error (the try..except returned false)
I really wanted to reply ...
"Fixed. From now on, when you come across those easily found bugs, go head and fix it, write a test, and move on. Don't send a condescending email to me, my boss, your boss, all the DBAs, and the entire fracking order processing team. Thanks."
But..I thanked him for finding and letting me know...we're a team..blah blah blah..
Frack..people suck.1 -
Wow or wtf to these banks API. was integrating an API for a service which accept JSON input.
Okay fair enough, that would be fine
Spent an hour writing code(purescript) most of time spent was on writing Types based on the API doc. after that okay let me test the API it failed.
I was what happened? So tested the API from postman with the payload from the doc, it worked. What how?
used a JSON diff to compare the payload from postman and the log. Looked same to me after spending few hours checking what is wrong with it .trying changing value to pasting the body of the log request in postman and trying everything failed.
Later went to the original working payload provided by them and changing the order. It started throwing error. I was like wait what?
It must be only on there UAT. created a payload with production creds and hoping to our production server (they have IP whitelist) ran the curl with proper payload as expected it worked. Later for same payload changed the order or one key and tried it failed.
Just why????
I don't want to create a JSON with keys on specific order. Also it's not even sorted order.4 -
Fucking fuck shit monkeycocksucking gargling wtf!
I was getting some stuff done in my accounting software and it bugged me that the fields were dark and the fonts as well, thus seeing fucking shit. This was clearly a bad choice of a gtk3 dark theme, thus i switched to the fucking default adwaita, suddenly gnome session crashes.
Ok, i just log out and log back in.
Logout.... Nothing happens.... Ctrl-alt-backspace , nothing happens (and i knew i enabled that in the settings)
Ok let's do it a bit more forceful and restart the display manager... Gdm starts... I insert my credentials... It fucking crashes.
WTF!!!
I desperately try to debug it, xsession error msg'es? Nope. Something in /var/log/messages? Nope. Something, anything at all, nope sherlock nopedinope!
About to go batshit crazy, purging and reinstalling all of gnome, thibking that, what ever setting lust have broke it, it will be fixed now.
No fucking fuck desktop!!!
I lost my nerve and replaced gdm with lightdm, and i finally, after three hours wasted on my machine, i get my gnome desktop back... But in a state of mess! Extensions don't work and make it crash again, user themes? Nope, go fuck yourself with plain default.
I'm really losing my shit, business is almost non-existant, and now ly FUCKING desktop refuses to work like i want to. Everything is fucking broken to shits !!
I'm gon a go to my gf, and relax a little, at least i still have a working laptop.
Question is, for how long???
Fml4 -
Simple but useful..
Wrote a greasemonkey script to convert url text to hyperlinks..
Reduced lots of time in finding the log url from the error response..
Helping me in debugging faster.. -
Anyone else hates this kind of statements:
if ( doSomething() != SUCCESS ) {
//log error
}else {
//continue doing other stuff
}
I simply find that confusing. This is much better:
If ( doSomething == SUCCESS ){
//continue doing other stuff
}else {
//log error
}
Maybe just my opinion.17 -
If you're going to have your package write into the SSIS log "please check the SSIS log for details" when your package throws an error
Kindly throw yourself off a cliff.
WRITE THE FUCKING ERROR TO THE FUCKING LOG.
If I'm reading the log, I'm already CHECKING THE FUCKING LOG. So I don't need the log to tell me to check the log.1 -
SO MAD. Hands are shaking after dealing with this awful API for too long. I just sent this to a contact at JP Morgan Chase.
-------------------
Hello [X],
1. I'm having absolutely no luck logging in to this account to check the Order Abstraction service settings. I was able to log in once earlier this morning, but ever since I've received this frustratingly vague "We are currently unable to complete your request" error message (attached). I even switched IP's via a VPN, and was able to get as far as entering the below Identification Code until I got the same message. Has this account been blocked? Password incorrect? What's the issue?
2. I've been researching the Order Abstraction API for hours as well, attempting to defuddle this gem of an API call response:
error=1&message=Authentication+failure....processing+stopped
NOWHERE in the documentation (last updated 14 months ago) is there any reference to this^^ error or any sort of standardized error-handling description whatsoever - unless you count the detailed error codes outlined for the Hosted Payment responses, which this Order Abstraction service completely ignores. Finally, the HTTP response status code from the Abstraction API is "200 OK", signaling that everything is fine and dandy, which is incorrect. The error message indicates there should be a 400-level status code response, such as 401 Unauthorized, 403 Forbidden or at least 400 Bad Request.
Frankly, I am extremely frustrated and tired of working with poorly documented, poorly designed and poorly maintained developer services which fail to follow basic methodology standardized decades ago. Error messages should be clear and descriptive, including HTTP status codes and a parseable response - preferably JSON or XML.
-----
This whole piece of garbage is junk. If you're big enough to own a bank, you're big enough to provide useful error messages to the developers kind enough to attempt to work with you. 2
2 -
Fuck XCode! -
Yesterday I had the stupid idea to rename an icon file. Checked that XCode was building the application still fine. Ran it over the build server: Failed, complaining about the old missing icon file! Checked again and again, but there was no friggin' reference to the old file in the whole repo.
Log in to the machine clear the build folder and try to build the component again. Bang still same error and the references to no longer existing files reappear.
Turns out XCode was caching those references somewhere in the home directory as "DerivedData" and after deleting those, I could build again... but why on earth are you building a cache if you cannot properly invalidate it? Just to waste our time?
(@xcodesucks)3 -
2 hour meeting to brainstorm ideas to improve our system health monitoring (logging, alerting, monitoring, and metrics)
Never got past the alerting part. Piss poor excuses for human being managers kept 'blaming' our logging infrastructure for allowing them to log exceptions as 'Warnings', purposely by-passing the alerting system.
Then the d-head tried to 'educate' everyone the difference between error and exception …frack-wad…the difference isn't philosophical…shut up.
The B manager kept referring to our old logging system (like we stopped using it 5 years ago) and if it were written correctly, the legacy code would be easier to migrate. Fracking lying B….shut the frack up.
The fracking idiots then wanted to add direct-bypass of the alerting system (I purposely made the code to bypass alerting painful to write)
Mgr1: "The only way this will work is if you, by default, allow errors to bypass the alerting system. When all of our code is migrated, we'll change a config or something to enable alerting. That shouldn't be too hard."
Me: "Not going to happen. I made by-passing the alert system painful on purpose. If I make it easy, you'll never go back and change code."
Mgr2: "Oh, yes we will. Just mark that method as obsolete. That way, it will force us to fix the code."
Me: "The by-pass method is already obsolete and the teams are already ignoring the build warnings."
Mgr1: "No, that is not correct. We have a process to fix all build warnings related to obsolete methods."
Mgr2: "Yes. It won't be like the old system. We just never had time to go back and fix that code."
Me: "The method has been obsolete for almost a year. If your teams haven't fixed their code by now, it's not going to be fixed."
Mgr1: "You're expecting everything to be changed in one day. Our code base is way too big and there are too many changes to make. All we are asking for is a simple change that will give us the time we need to make the system better. We all want to make the system better…right?"
Me: "We made the changes to the core system over two years ago, and we had this same conversation, remember? If your team hasn't made any changes by now, they aren't going to. The only way they will change code to the new standard is if we make the old way painful. Sorry, that's the truth."
Mgr2: "Why did we make changes to the logging system? Why weren't any of us involved? If there were going to be all these changes, our team should have been part of the process."
Me: "You were and declined every meeting and every attempt to include your area. Considering the massive amount of infrastructure changes there was zero code changes required by your team. The new system simply worked. You can't take advantage of the new features which is why we're here today. I'm here to offer my help in any way I can with the transition."
Mgr1: "The new logging doesn't support logging of the different web page areas. Until you can make that change, we can't begin changing our code."
Me: "Logging properties is just a name+value pair dictionary. All you need to do is standardize on a name and how you add it to the collection."
Mgr2: "So, it's not a standard field? How difficult would it be to change the core assembly? This has to be standard across all our areas and shouldn't be up to the developers to type in anything they want."
- Frack wads smile and nod to each other like fracking chickens in a feeding frenzy
Me: "It can, but what will you call this property? What controls its value?"
- The look I got from both the d-bags I could tell a blood vessel popped.
Mgr1: "Oh…um….I don't know…Area? Yea … Area."
Mgr2: "Um…that's not specific enough. How about Page?"
Mgr1: "Well, pages can cross different areas, and areas cross different pages…what do you think?"
Me: "Don't know, don't care. It's up to you. I just need a name."
Mgr2: "Modules! Our MVC framework is broken up in Modules."
DevMgr: "We already have a field for Module. It's how we're segmenting the different business processes"
Mgr1: "Doesn't matter, we'll come up with a name later. Until then, we won't make any changes until there is a name."
DevMgr: "So what did we accomplish?"
Me: "That we need to review the web's logging and alerting process and make sure we're capturing errors being hidden as warnings."
Mgr1: "Nooo….we didn't accomplish anything. This meeting had no agenda and no purpose. We should have been included in the logging process changes from day one."
Mgr2: "I agree, I'm not sure why we're here"
Me: "This was a brainstorming meeting as listed in the agenda. We've accomplished 2 of the 4 items. I think we've established your commitment to making the system better. Thank you all for coming."
- Mgr1 and 2 left without looking at me or saying a word.1 -
How come something works absolutely perfectly in dev but not in prod?
I was making a desktop app in election js and everything is working perfectly. No problem at all. But then I create the installer/distributable and nothing shows on the screen. And out of curiosity, I wanted to see the error log and it shows an unknown error, I didn't even know from what thing the error is being generated. And after I fixed that, another problem came with Asana Api. I mean, if it's a public API, why do you have to block it with cors? I hate cors!
And after all of it, there's more to it. I mean, why can't you just show the errors in dev?4 -
So, the Network I was on was blocking every single VPN site that I could find so I could not download proton onto my computer without using some sketchy third-party site, so, being left with no options and a tiny phone data plan, I used the one possible remaining option, an online Android emulator. In the emulator running at like 180p I once again navigated to proton VPN, downloaded the windows version, and uploaded it to Firefox send. Opened send on my computer, downloaded the file, installed it, and realized my error, I need access to the VPN site to log in.
In a panic, I went to my phone ready to use what little was left of data plan for security, and was met with no signal indoors. Fuck. New plan. I found a Xfinity wifi thing, and although connecting to a public network freaked me out, I desided to go for it because fuck it. I selected the one hour free pass, logged in, and it said I already used it, what? When?, So I created a new account, logged in, logged into proton, and disconnected, and finally, I was safe.
Fuck the wifi provider for discouraging a right to a private internet and fuck the owner for allowing it. I realize how bad it was to enter my proton account over Xfinity wifi, but I was desperate and desperate times call for desperate means. I have now changed my password and have 2fa enabled.1 -
I like my log messages to indicate automatically where in the code something happened, so that I can easily identify where a message originated from while tracking down problems.
In C/C++ this is nice and easy - write a logging routine, wrap it in macros for the different log levels and have that automatically output __FILE__, __LINE__ etc.
I wanted to do something similar in NodeJS, as I'd found myself manually writing the file name in the log message and then splitting functionality out into new files and it became a mess.
The only way I found to be able to do this was to create an "Error" object and access the "stack" member of it. This is a string containing a stack backtrace, suitable for writing to console/file. I just wanted the filename/line/routine.
So I ended up splitting the string into lines, then for each of the lines, trimming the surrounding spaces (or tabs?), and parsing them to see if the stack entry is inside my logger module. The first entry outside of that module must therefore be the thing that called it, so I then parse out the routine or object and method, filename and line number.
It's a lot of clumsy work but the output is pretty neat. I just wish it were simpler!2 -
I'm working as an intern in a company and i have another intern that i must supervise (it like internception) .here is my daily nightmare :
- To start this intern never google something she copy paste from my code and if she got an error she send me a screenshot . Once the error message clearly said "cannot call function from array" and even that she didn't know what's the problem (she was supposed to it on array items)
-Before we started working together she spent a week complaining that a sending email function didn't work for her so the manager called me to check what's her problem. She had an antivirus that blocked request via ssl port.all i had done is open the log file and read the errors.
- She had a function should iterate over an array and for each item check a condition this is a part of what she wrote :
For ($i=0;count($categories);$i++){
if ($getrelativepath=null)
{
....etc other stuff she copy pasted.
Ps: the name of the function that she must call on array items is getRelativePath
- she wrote once
$response=array();
for (...){
array_push($response,$data[$i]);
return $response;}
She thought the function can iterate and return response at the same time.
- we are working on a website and she told me she doesn't know how to code Javascript and jquery (she think it's a language) and she never knew what ajax is.
- without mentioning the hundreds of empty spaces and multiple empty divs in html .
This year she'll become a computer science engineer .6 -
Win10: your password has expired.
Me: ok *click*
Win10: oh btw I forgot which account has its password expired, so you have to write the account name
Me: ... Okay
Me: *resets password, then clicks next*
Win10: let me empty that form and let you redo everything without me showing you an error
Me: ....... Okay
Me: *same info*
Win10: sorry, can't find user "username"
Me: Ok you know what fuck off I'm restarting you
Win10: but I... *ded*
...
Win10: Hello Phlisg, please log in normally as usual
Me: what the fuck
---
Disclaimer: I use Linux, osx and windows ;)1 -
SAP Ariba.
Imagine you can test newly created catalogs, but on error you only receive an error ID, which you have to send to a support email to get the acual error message, but support only responds after maybe 2 weeks if you're lucky.
How hard can it be to implement a log viewer next to your catalog testing forms. -
Developer just emailed our team a complaint that our logging assembly was resulting in their poor test coverage and they sent a change request to give them the ability to mock the underlying log provider (ex. from the event log to ‘something else’).
Looked at their tests, and they are testing whether or not the .Log was executed (on an exception, if the .Log method was not executed, the test failed), which seemed a bit worthless because we’ve already got coverage in our unit tests.
We had a meeting to discuss the issue.
Me: “I’m OK with changing the logging code if it’s necessary, but I want to understand why.”
DevA: “Logging errors is crucial to the database transaction. If someone removes the logging, the tests should fail.”
Me: “If someone removes the error logging on purpose, then they likely have an agenda and will remove the test validation too. It wouldn’t be an accident.”
DevA: “That’s not my problem. They will have to deal with HR.”
Me: “We purposely prevented someone from intercepting the logging just for that purpose. Your test code already covers the business rule, testing the logging seems out of place. That would like writing a test to make sure the System.IO.File.ReadAllText actually reads all the text from a file. You kinda assume a few smart Microsoft engineers already wrote tests for that.”
DevA: “Yea, I guess that would be silly.”
Got cc’ed an email a little bit ago from DevA to his boss..
“We’re not going to be able to change logging assembly. This may have some impact on our overall test coverage as those lines of code will not get testing coverage. You will have to let the DevMgr know we will not meet our test coverage goals.”
WTF!1 -
When my boss thinks doing anything is better then doing nothing...
I have to explain to my boss for the Nth time already that doing random tests and things will not replicate a PRODUCTION network issue that seem caused by particular factors at a particular time and location.
And that the best way to trace is for whatever is raising the issue to log the exact time and error so the problem can be traced through all the steps...
FML.....1 -
Yesterday was a horrible day...
First of all, as we are short of few devs, I was assigned production bugs... Few applications from mobile app were getting fucked up. All fields in db were empty, no customer name, email, mobile number, etc.
I started investigating, took dump from db, analyzed the created_at time stamps. Installed app, tried to reproduce bug, everything worked. Tried API calls from postman, again worked. There were no error emails too.
So I asked for server access logs, devops took 4 hrs just to give me the log. Went through 4 million lines and found 500 errors on mobile apis. Went to the file, no error handling in place.
So I have a bug to fix which occurs 1 in 100 case, no stack trace, no idea what is failing. Fuck my job. -
Today after longer vacation I came back to work.
Edit: wrote this rant long time ago, but never finished. Was too pissed.
Some easy meetings, then wanted to start on an easy job.
Just migrating some things from bash regex voodoo to proper tools like JQ.
Finished in roughly 1 h. Lovely.
Made some tea, ate some cookies.
Set up dev environment, found no documentation what so ever, got it running after half an hour.
Annoying, but ok.
Then I tried my scripts...
They worked... Except they didn't.
Console log empty, response code 200 with state: GENERATE_NO_FILES.
Eh. Fuck you. Just fuck you.
Fixed the logging configuration, which was broken since uhm... 2 years plus?
Well... Another half another hour gone...
Kinda pissed now.
Still script return failed...
Poking and trying to sprinkle debug all over that shit cause everything seems ... An incohesive, inconsistent diarrhea.
3 hours later...
Made the ticket to rewrite it.
I did nothing wrong at all.
The API just has no workflow at all. The
*seperate* API calls have to be in an **specific** order - as otherwise the generation will fail, as the prerequisites for the generation are not fulfilled.
Yeah. Completely logical. Especially not to give out any kind of warning or an error message like requirements not met, blablabla.
I drank that evening 2 six packs of beer. I was raging mad....
Then gave that shit to another manager, as I never want to touch that nuclear waste again....
How can someone be so brain damaged -.-1 -
God I fucking hate macs.
I got a mac at work. I tried to install ubuntu, with rather questionable results (unfortunately, I expected that) - so I tried to get mac work for me the way I like a system to work. I needed to download slack, simple enough, right? Ha, you wish. It's gotta be done through Apple store, so I went to create an Apple ID inside the Apple Store form. And, well, it just errored out on the submission. Great start. I went then to the settings and created an account there, great success, went back to Apple Store. Unfortunately being logged in at the system level doesn't mean you are logged in to the store. So, I went to log in to the store, simple enough, right? No, nothing's simple with Apple. After logging in I got a message that the Apple ID has not yet been used with Apple Store and that I need to review the account's setting. So, I click the "review" button and... I'm presented with a log in form. Yep, a perfect log in loop. I can't log in because I can't review the account but I can't review the account because I can't log in. Fun :)
You can't just go to the web admin panel for your account to review it for Apple Store, that would too be too easy. After a bit of searching I've found an answer on StackOverflow. You need to log in to iTunes. Through a fucking MUSIC APP. To install a free application from the store you need to log in to a music app. Yes, we're all mad here.
Then, after finding out that to be able to use side buttons on my mouse I need an app that I need to manually restart every time I restart the machine and that I need to have an app to fucking transfer files from an android I need another fucking app, because reading a storage of a linux-based system would be too standards compliant - something in me broke. I found out that installing windows on a mac is officially supported.
Supported doesn't mean that it's easy. I tried to install it trying different solutions from SO, but each time I would get an error that Windows couldn't modify the boot partition. Turns out that even wiping the drive and reinstalling OSX doesn't remove residual files on a boot partition and Windows installer is not allowed to modify them. It took me hunting into some shady looking site to actually find this answer. I have no fucking idea how long it all took me, but, finally, great success, Windows, WSL, side buttons working, I can even install slack from an installer. I just wish I could have those hours of my life back.12 -
The story of how I knew I did the right thing leaving the start up I was an employee of.
It was a great place to work when I started, we had a plan and we were are working hard to make it. But pretty soon I realised that things weren't 100%. We kept altering the product and focusing on the wrong things. Our backlog grew faster than it was completed.
Pretty soon a launch planned in April was pushed back over and over again, until we finally released in November, and instead of being first on the market we were last.
We pivoted hard and I didn't believe in the new product so I quit.
The last week on the job I was finishing up some stuff and when our PO (who also was a programmer)was deploying the things I had done to production something went wrong. Now I had just integrated *his* new authorization service and I had a hunch it wasn't deployed. But he sent a message over slack with a bunch of code alterations that was the "problem". Along with some passive aggressive words about how I wasn't professional and didn't take ownership of the product.
I only added an error log that asked if the authorization service was deployed, and 10 minutes later he came up and said good job, no mention of what was fixed between now and then.
I have no regrets leaving that place. -
Apparently, calling a function recursively for 18572 times isn't a great idea.
And apparently, too many log statements can stop a script.
Otherwise, I am getting a stackoverflow error if I remove log statements.2 -
So I created a little script for my mother because otherwise she had to combine 70 spreadsheets manually, I just couldnt sit there and do nothing. So I wrote a simple Python script in like 30 mins, decided that it needed a GUI because in the end it is for my mother. So wrote a GUI and partly learnt PyQt during that in an hour, which was all working fine.
Then I got to the point where I actually had to hand it over to my mother, preferably as an executable so that there is no hassle at all. So found this tool, Pyinstaller which seems to work great. Created an executable with all the dependencies and stuff in a single file, it worked on my win10 machine (because I developed on Linux of course). So I distributed it to her and she immediately gets an error. Of course there is no description and stuff because I made it a simple program, no log files and such. But fortunately she told me that it errorred when she wanted to run it, so I knew it had to be due to the executable.
Turns out she is still using windows 7 at work, which of course is different that windows 10 and here I am at 11pm, installing updates on a fresh windows 7 machine just to create a new build in that environment and make it work on her machine.
Fuck you, windows update. I swore to never see that ugly ass progress bar again, but yet here I am. Send halp.
I am almost just at the point where Im going to teach my mother how to run a python application from the command line because wheels are actually available for all python dependencies (instead of compiling them)!
Are there better python executable creators out there for wincrap?3 -
Task: Deploy MinIO in k8s cluster
Me: deploys the first docker image found on google: bitnami/minio
MinIO: starts
Me: log in
MinIO: Fuck you! There's a cryptic error: Expected element type <Error> but have <HTML>
Me: spends half a day trying out different vendors, different versions, different environments (works on local BTW)
Me: got tired, restored the manifest to what it was at the beginning. Gave it the last try before signing off
MinIO: works 100%
wtf... So switching it back and forth fixed the problem, whatever it was. Oh well, yet another day.6 -
Pentesting for undisclosed company. Let's call them X as to not get us into trouble.
We are students and are doing our first pentest at an actual company instead of assignments at school. So we're very anxious. But today was a good day.
We found some servers with open ports so we checked a few of them out. I had a set of them with a bunch of open ports like ftp and... 8080. Time to check this out.
"please install flash player"... Security risk 1 found!
System seemed to be some monitoring system. Trying to log in using admin admin... Fucking works. Group loses it cause the company was being all high and mighty about being secure af. Other shit is pretty tight though.
Able to see logs, change password, add new superuser, do some searches for USERS_LOGGEDIN_TODAY! I shit you not, the system even had SUGGESTIONS for usernames to search for. One of which had something to do with sftp and auth keys. Unfortunatly every search gave a SQL syntax error. Used sniffing tools to maybe intercept message so we could do some queries of our own but nothing. Query is probably not issued from the local machine.
Tried to decompile the flash file but no luck. Only for some weird lines and a few function names I presume. But decompressing it and opening it in a text editor allowed me to see and search text. No GET or POST found. No SQL queries or name checks or anything we could think of.
That's all I could do for today. So we'll have to think of stuff for next week. We've already planned xss so maybe we can do that on this server as well.
We also found some older network printers with open telnet. Servers with a specific SQL variant with a potential exploit to execute terminal commands and some ftp and smb servers we need to check out next week.
Hella excited about this!
If you guys have any suggestions let us know. We are utter noobs when it comes to this.6 -
I've just spent the last hour or so banging my head against a brick wall trying to figure out why I'm unable to retrieve some data via AJAX even though I know data is being returned as I can see it in my error log.
Turns out the permission system I wrote a few days ago actually works and because I didn't specify a permission it automatically denied my user from retrieving the data. One thing I forgot to add was an error message to tell me when I don't have sufficient permission to do something. Adding a message could have just saved me a lot of time :/1 -
Trying to use authenticate a JWT token from an Azure service, which apparently needs to use Azure AD Identity services (Microsoft Entra ID, Azure AD B2C, pick your poison). I sent a request to our Azure admin. Two days later, I follow up, "Sorry, I forgot...here you go..."
Sends me a (small) screenshot of the some of the properties+GUIDs I need, hoping I don't mess up, still missing a few values.
Me: "I need the instance url, domain, and client secret."
<hour later>
T: "Sorry, I don't understand what those are."
Me: "The login URL. I assume it's the default, but I can't see what you see. Any shot you can give me at least read permissions so I can see the various properties without having to bother you?"
T: "I don't see any URLs, I'll send you the config json, the values you need should be in there."
<10 minutes later, I get a json file, nothing I needed>
<find screenshots of what I'm looking for, send em to T>
Me: "The Endpoints, what URLs do you see when you click Endpoints?"
<20 minutes later, sends me the list of endpoints, exactly what I'm looking for, but still not authenticating the JWT>
Me: "Still not working. Not getting an error, just that the authentication is failing. Don't know if it's the JWT, am I missing a slash, or what. Any way I can get at least read permissions so I don't have to keep bugging you to see certain values?"
T: "What do you need, exactly?"
Me: "I don't know. I don't know if I'm using the right secret key, I can't verify if I'm using the right client id. I feel like I'm guessing trying to make this work."
T: "What exactly are you trying to get working?"
<explain, again, what I'm trying to do>
T: "That's probably not going to work. We don't allow AD authentication from the outside world."
Me: "Yes we do. Microsoft Teams, Outlook, the remote access services. I can log into those services from home using my AD credentials."
T: "Oh yea, I guess we do. I meant what you are trying to do. Azure doesn't allow outside services to authenticate using a JWT. Sorry."
FRACK FRACK FRACK!!
Whew! Putting the flamethrower away.
Thanks devrant for letting me rant.3 -
Boss: I don't want centralized error logging
Me: But we have 50+ client sites running the same web app, why the fuck wouldn't we?
Boss: What if the database is offline, then we wouldn't be able to log exceptions
Me: *beats head against desk*1 -
Spent over an hour on a shell script that wasn't working properly. I use it, works perfectly. Every time cron executes, does nothing, not even log an error.
It took me that long to realize that the user I was getting the cron to run on didn't have permission to write to my log file... You would think I'd realize this when my error scripts didn't log...
(on that note, the Bandit games at OverTheWire have been awesome refresher on getting back into the swing of linux - highly recommend) -
I'm developing a new (just for fun) programming language and I'm wondering what features I should add next? These features are already implemented:
- Printing text
- Variables
- user-input
- Datatype conversion (String, Int, Float, Bool, List, Dictionary)
- lists/arrays
- dictionaries
- Sorting
- Shuffling
- random numbers & choices
- Math stuff like: log, abs, floor, ceiling, sin, etc...
- Time & Date
- Working with files
- If-else statements
- Ternary operators
- Loops (for & while)
- Functions
- Classes
- Error handling
- Importing libraries & other scripts
- Arrow/callback functions
- Escaping (\)
is there anything you often use missing?11 -
You know what I had to deal with
A bunch of these shit
try{
//Shitty cluster fuck excuse for java
//code
}catch(Exception e){
}1 -
You know that time when somebody had a problem with a system you wrote years ago, and it has taken you an hour to try to remember how to even call it, because the documentation and code didn't get migrated from svn to git, and the svn server has been shut down for some reason, and the admin is out today, and the last time you had the code was three machines ago, so you're trying to gleam what needs to be done to just call the stupid thing from log files set to 'error'?
That time is now. -
<<prev. #wk235 advices>>
~ Study the Error log deeply, Google each line if needed. Don't give up.
~ Learn by doing. Don't just read/watch.
~ Practice breaking down the problem statement first in different components and hierarchies. Don't jump into coding right away.
~ Write some, review some. Don't put off review for later.
~ Even if you don't exactly follow the best security practices - always ensure that your program is safe for use. Especially for user-inputs, etc, pay attention.
~ Never distribute code with passwords/keys written in it.
~ Don't hard code stuff, use Config file, environment variables, etc.
~ Try to automate repetitive stuff like build and deploy etc
~ Save and backup you code.
~ No one knows everything, also, today's knowledge gets outdated tomorrow. Continuous learning is synonymous with this field.
<<next #wk235 advices>>1 -
Attempting to deploy my web application using Heroku. It throws me error code H14 so I add scale web=1 to the web dyno per their documentation. I get this console log thrown at me after attempting to deploy.
I'm starting to get pissed. I may end up just dumping this and deploying my node.js/java application straight to my Linux server.
Edit: Or better yet start learning to use this Docker thing I keep hearing about. 5
5 -
junior developer raises an issue saying that there's an application deployment error on one of their dev clusters.
sysadmin asks them to go back and look at the error logs and come back with the problem.
they come back saying, "No space left on device"
sysadmin takes a look at server. finds this : 5
5 -
You can really tell a lot about a coder from their build log. Especially the actual compile error reasons.
Yes, I'm talking about you who duct-tapes solutions for others to clean your mess up later when your hack falls apart , you dirty ba****d! -
## Learning k8s
Okay, that's kind of obvious, I just have no idea why I didn't think of it..
I've made a cluster out of a rpi, a i7 PC and a dell xps lappy. Lappy is a master and the other two are worker nodes.
I've noticed that the rpi tends to hardly ever run any of my pods. It's only got 3 of them assigned and neither of them work. They all say: "Back-off restarting failed container" as a sole message in pod's description and the log only says 'standard_init_linux.go:211: exec user process caused "exec format error"' - also the only entry.
Tried running the same image locally on the XPS, via docker run -- works flawlessly (apart from being detached from the cluster of other instances).
Tried to redeploy k8s.yaml -- still raspberry keeps failing.
wtf...
And then it came to me. Wait.. You idiot.. Now ssh to that rpi and run that container manually. Et voila! "docker: no matching manifest for linux/arm/v7 in the manifest list entries."
IDK whether it's lack of sleep or what, but I have missed the obvious -- while docker IS cross-platform, it's not a VM and it does not change the instructions' set supported by the node's cpu. Effectively meaning that the dockerized app is not guaranteed to work on any platform there is!
Shit. I'll have to assemble my own image I guess. It sucks, since I'll have to use CentOS, which is oh-so-heavy compared to Alpine :( Since one of the dependencies does not run well there..
Shit.
Learning k8s is sometimes so frustrating :)2 -
I feel like writing or telling people about the time I jumped from Windows 7 Ultimate and jumping to Windows 10. (I'm not against 10, but I'm never updating after what had happened to me)
It all starts when none of my games will play due to a possible issue with my graphics card. I look up "3D source game bug" and not many results pop up. I go on Microsoft's Qna areas and ask this question but to my surprise nothing they say would make sense. "Clean the pins of your graphics card, make sure you verify the games on Steam". I verified the games and they checked out as perfectly fine. I don't have access to my graphics card because this is a laptop, sadly not a tower.
Two months pass and my computer is already showing signs of stress, like it didn't want to live in a sense. It was three times slower than when I was on Windows 7 and it was unallocating areas of my main hard drive where I could make virtual hard drives.
Instantly I start looking up Linux distros and find Linux Mint. 17.3 was the current version at the time. I downloaded it and burned it onto a DVD-rom and rebooted my computer. I loaded into the disc and to my surprise it seemed almost like Windows 7 apart from the Linux part. I grab my external hard drive and partition it to hold the Linux distro and leave it plugged in incase Windows 10 does actually fail.
On December 19, a few months after Windows 10 had released. I start my laptop to try and continue my studies in video game development. But to my surprise, Windows 10 had finally crashed permanently. The screen flickered blue and black, and an error box saying Loginui.exe failed to start. I look at it for a solid minute as my computer had just committed suicide in a sense.
I reboot thinking it would fix the error but it didn't. I couldn't log in anymore.
I force shutdown the laptop and turn it back on putting it into safe mode.
To my surprise loginui.exe works and I sign in. I look at my desktop, the space wallpaper I always admired, the sound files, screen shots I had saved.
I go into file explorer and grab everything out of my default hard drive Windows was installed on. Nothing but 400gb got left behind and that was mainly garbage prototypes I had made and Windows itself. I formatted my external hard drive and placed everything on it. Escaping Windows 10 with around 100GB of useful data I looked at the final shutdown button I would look at.
I click it and try to boot into normal Windows 10. But it doesn't work. It flickers and the error pops up once more.
I force it to shutdown and insert the previous Linux Mint disc I made and format the default hard drive through Linux. I was done. 10 gave me a lot of shit. Java wouldn't work, my games has a functional UI but no screen popped up except a black abyss and it wouldn't even let me try to update my graphics card, apparently my AMD Radeon 5450 was up to date at the AMD Radeon 5000's.
I installed Linux Mint and thinking the games would actually play I open steam and Launch Half-Life 2 to check if Linux would be nicer to me than Windows 10 had been.
To my surprise the game ran. The scene from Highway 17 popped on screen and the UI was fully functional. But it was playing at 10-15fps rather than the usual 60-70fps. Keep look at my drivers and see my graphics card isn't in use. I do some research and it turns out I have a Hybrid Laptop.
Intel HD Graphics and an AMD Radeon 5450 and it was using the Intel and not the AMD. Months of testing and attempts of getting the games to work at high frame rates pass and the Damn thing still functions at a low terrible fps. Finally I give up. I ask my mom for a Windows 7 disc and she says we can't afford it. A few months pass and I finally get a Windows 7 installation disc through money I've saved up. Proudly I put it into my optical disc drive and install it to my main hard drive deleting Linux completely. I announced to all my friends my computer was back in working order and I install everything I needed, Steam, Skype, Blender, and Unity as well as all my games. I test Half-Life 2 and it's running exceptionally smoothly, I test Minecraft at max settings and it's working beautifully. The computer was functioning properly once again and my life as a developer started as I modeled things and blender, learned beginners C# and learned a lot of Batch. Today the computer still runs at a great speed and I warn others of what happened to me after I installed Windows 10 to my machine if they are thinking of switching from 7 or 8 on an older machine.
Truly the damage to my data cannot be undone. But the memory of the maintenance, work, tests, all are a memory of how Windows 10 ruined me and every night before the one year anniversary of Windows 10's release, I took out the battery of my laptop and unplugged it from the a.c. power, just so Windows 10 doesn't show it's DLLs, batch scripts, vbs scripts, anything on my computer. But now, after this has happened and I have recovered, I now only have a story to tell5 -
Fk you Google!
My Samsung note 10 screen went dead near a week ago... it's a secondary line so waiting for parts wasn't the end of the world.
Ofc the screen (curved and incl a fingerprint reader thatd be a major pain to not replace) was integrated to the whole front half... back panel glued, battery, glued immensely and with all other parts out, about 6mm space only at the bottom to get a tool in to pry it out.
New screen (off brand) ~200... all genuine parts amazon refurb ~230... figured id have some extra hardware for idk what... i like hardware and can write drivers so why not.
Figured id save a bit of time and avoid other potentially damaged (water) components to just swap out the mobo unit that had my storage.
Put it back together, first checked that my sim was recognised since this carrier required extraneous info when registering the dev... worked fine... fingerprint worked fine, brave browser too...
Then i open chrome. It tells me im offline... weird cuz i was literally in a discord call. My wifi says connected to the internet (not that i wouldn't have known the second there was a network issue... i have all our servers here and a /28 block... ofc i have everything scripted and connected to alert any dev i have, anywhere i am, the moment something strange happens).
Apparently google doesnt like the new daughter board(i dislike the naming scheme... its weird to me)... so anything that is controlled by google aside from the google account that is linked to non-google reliant apps like this... just hangs as if loading and/or says im offline.
I know... itll only take me about the 5-10m it took to type this rant but ffs google... why dont you even have an error message as to what your issue is... or the simple ability to let me log in and be like 'yup it's me, here's your dumb 2fa and a 3rd via text cuz you're extra paranoid yet dont actually lock the account or dev in any way!'
I think it's a toss up if google actually knows that it's doing this or they just have some giant glitch that showed up a couple times in testing and was resolved via the methods of my great grama- "just smack it or kick it a few times while swearing at it in polish. Like reaaaally yelling. Always worked for me! If not, find a fall guy."6 -
A common walkthrough with Laravel deployment:
1.) Error 403
2.) Internal server error 🤔
3.) bad require paths in index.php....
4.) Whooops something went wrong.. What?.... Look at log file with 2MB size
5.) View not found1 -
One time, i would put a random stacktrace / error log containing fake server credentials/ card info etc on a page/ action letting those "hackers" waste their time digging into it.. only to found out that the server is just a repo of (i would like to say porn butthats still a win situation) useless things1
-
I give up. I am having trouble understanding Go lang *, & stuff.
attached code does print what fmt.Println has, but the function calling: FindByID is throwing invalid memory address or nil pointer when it attempts to use the result of the code.
Can someone please explain where I'm wrong?
Error log blames the line of "if" condition even though fmt does print its output to console 16
16 -
Dude GoogleAuth is pure nonsense magic. On one line you get your auth-instance from gapi.auth2.init..
But then you render the auth-button with a static method aka gapi.signin2.render (which has some kind of success and error handlers, but don't worry, they fire randomly, they won't help you debug this api mess)
SOME-FUCKING-HOW this static signin2.rendershit knows of your auth2 instance and it works. But actually it makes no sense and is just a big mess of api-calls. Google, get your shit together, this ain't pretty.
Oh and forget your informative console.log.. this shit will get erased everytime you try something because of "Navigated to https://accounts.google.com/o/...". why ever the fuck this clears the console even tho it doesn't affect the top window. So preserve that fucking log and drown in a mass of bullshit.
In the end, as it is with everything, it somehow works. But FFS that's some weird api design Google has going on..4 -
The task: Catch and log this specific error in this one function.
Me: While I'm here, let me just -
git: 12 files changed2 -
So to give you a feel for what evil, clusterfuck code it was in: this projects largest part was coded by a maniac, witty physicist confined in the factory for a month, intended as a 'provisional' solution of course it ran for years. The style was like C with a bit of classes.. and a big chunk of shared memory as a global mud of storage, communication and catastrophe. Optimistic or no locking of the memory between process barriers, arrays with self implemented boundary checks that would give you the zeroth element on failure and write an error log of which there were often dozens in the log. But if that sounds terrifying already, it is only baseline uneasyness which was largely surpassed by the shear mass of code, special units, undocumented madness. And I had like three month to write a simulator of the physical factory and sensors to feed that behemoth with the 'right' inputs. Still I don't know how I stood it through, but I resigned little time afterwards.
Well, lastly to the bug: there was some central map in that shared memory that hold like view of the central customer data. And somehow - maybe not that surprisingly giving the surrounding codebase - it sometimes got corrupted. Once in a month or two times a day. Tried to put in logging, more checks - but never really could pinpoint the problem... Till today I still get the haunting feeling of a luring memory corruption beneath my feet, if I get closer to the metal core of pure C.1 -
Magento Debugging Horror!
Changing lots of things in magento with no problem. Continuing development for quite sometime. Suddenly decide to clear cache to see affect of a change on a template in frontent. Suddenly magento crashes! There's no error message. No exception log. No log in any file anywhere on the disk. All that happens is that magento suddenly returns you to the home page!
Reverting all the changes to the template. Clear the cache. Nope! Still the same! Why? Because the problem has happened somewhere in your code. Magento just didn't face it, because it was using an older version of your code. How? Because magento 2 even caches code! Not the php opcache. Don't get me wrong. It has it's own cache for code, in a folder called generated. Now that you cleared all the caches including this folder, you just realized that, somewhere something is wrong. But there is no way for you to know where as there is absolutely no exception logged anywhere!
So you debug the code, from index.php, down to the deepest levels of hell. In a normal php code, once the exception happens, you should see the control jumps to an exception handler, there, you can see the exception object and its call stack in your debugger. But that's not the case with magento.
Your debugger suddenly jumps to a function named:
write_close();
That's all. No exception object. No call stack. No way to figure out why it failed. So you decide to debug into each and every step to figure out where it crashes. The way magento renders response to each request is that, it calls a plugin, which calls a plugin loop, which calls another plugin, which calls a list of plugins, which calls a plugin loop, which calls another plugin.....
And if in each step, just by accident, instead of step through, you use the step over command of your debugger, the crash happens suddenly and you end up with the same freaking write_close() function with no idea what went wrong and where the error happened! You spend a whole day, to figure out, that this is actually a bug in core of magento, they simply introduced after your recent update of magento core to the latest STABLE version!!! It was not your mistake. They ruined their own code for the thousandth of time. You just didn't notice it, because as I said, you didn't clear the `generated` folder, therefore using an older version of everything!
Now that after spending 7 hours figuring out what has failed with absolutely no standard way of debugging and within a spaghetti of GOTO commands (Magento calls them plugin), why not report it to github? So you report it with a pull request. This also takes 1 hour of your time. Just to next day get informed that your pull request is rejected because another person already fixed the bug and made the same pull request. It was just not on the latest stable version yet!
So you decide to avoid updating magento as much as possible. Because you know that the next Stable version will make your life and career unstable. But then the customer complains that the Admin Panel is warning him of using old Magento version which might pose SECURITY THREATS! -
Am I the only one to hate Google drive window's client? It Is far slower than OneDrive/Dropbox. If you work inside the drive you could lose shit, If you remove a file window says it can't be removed but after the error message he does it and If you log out the client..It removes the virtual drive with your files on😑😑 what the fuck Google, what the fuck7
-
Started out as an intern at my current employer, after a few months they made me create an invoicing system...
I should have said no.
I've had a lot of bugs with it in the past, but the data-loss one has been because I send a SOAP call to our (third party) accounting system and only if I get an ERROR do I log it....
Apparently, when you put line 1 before line 0, you get a warning, but no data is processed...
Had to write a script that updated 4 months of invoice data in one go, without errors, took me a fucking week...
Lesson learnt boys and girls, never let an intern make the fucking invoicing system!3 -
Learning to troubleshoot issues with vms. Had to break a vm with a script I was given and then fix it. Docs I was given said x error should be in y log. I check the log; nope. Check the other logs for other possible errors mentioned; nope. Turns out something else broke instead and before of the thing I was supposed to break. Rip me
-
Damned XAMPP doesn't want to run MySQL. Can't access phpmyadmin on local machine. Fixed localhost problems now it shows me 404! Edited all ports in config files for Apache, killed some tasks working on that port, stopped running some services - still nothing. Now found out there are some db files missing for MySQL via error log so I need to fix that plus 404 on my localhost. Don't feel like I'm close to solve all that. Half of a day wasted with no results. I need a cold shower and a gallon of coffee.1
-
Motherfucking peace of shit....
Dont know to whom I should direct this to .
Was creating a new login page for web app using Quasar(vue.js). Since my application have 2 different types of user, which also have different UI, and functionality.
One is written in vanilla ( and is quiet heavy) and the other one in vuejs ( though earlier it was written in vanilla too ). Login page too was written in vanilla which was working fine.
Now just yesterday I finished a prototype for the third type of user, which is also written in vuejs. Now I decided to re create login page using vuejs. Quiet small and easy to do. Finished it yesterday itself. Now since today's morning I am trying to configure it so that it this piece of shit just let me log in. It was authentication and verifying but not letting me log in.
( On server after authentication, I set cookies/token on clients browser and auto reload the page, so during next request to server/ or during reload, server will read the cookie/token and send the specific admin panel to user)
Prick. Dick.
It was setting cookie, but not at the '/' path. Mother fucker.
It was setting cookie to the path I was sending login credentials ( which was different from '/', I.e.- /login/verify=password )
So it was setting cookie/token at '/login/verify=password'.
Even tried setting path for cookie at server. Read everything on internet. MF nothing worked. All I came across was, 'this is CORS' .... 'this is CORS'. Assholes, if it were CORS', how then I am able to make request to server and getting response without error
Only a hour ago, when I made get request to '/login/verify=password' I figured out, cookie is being sent to server for this path only. Then did some changes at server, so to send login credentials to '/'. Now that shit is working
Fucking waste of time. Wasted more than 6 hours. Asshole.
Btw, if you can suggest a better way to login, then please. -
Worst support experience so far: German ISP sent their cheap default router which I opted for, hoping that I didn't need to rent a costly FitzBox. Provider activates the connection, everything fine, but slow and unstable on my Linux laptop only. Try using their website, their support chat etc. as they made it very hard to even open a support ticket. I gather all the information, ping, traceroute, netstat, logfiles, router settings, broadband measurement etc. and finally manage to open a support ticket of my issue adn they say they will send an engineer to my place in about 4 days. I stay at home that day and wait for the whole day, nothing happens!
I get back to them, even get a phone call after waiting about 1h in the waiting queue, only to listen to someone tell me that the appointment had been cancelled as the ticket had already been closed. WTF! They said they measured my connection and could not reproduce any error. Did not even mention my lengthy log files etc. It took my own research and another hint that there is an incompatibility with that specific router and some specific devices so I should really replace their cheap router with a FritzBox device. What they also did not tell, that you dont need to rent their branded FritzBox, there are cheap second hand models from another ISP that you can reconfigure by simply chosing another ISP in a dropdown list that contains every popular German ISP. But why are they popular? You can only choose between the different bad ones, that's why they don't seem to make an effort.2 -
There's nothing quite like an app force closing for no apparent reason, and no error log info.
Just spent an hour figuring out that one of the device I test on doesn't like linking GLSL shader programs if it contains a loop even know every other devices I've tested on are totally fine with it. 😑 -
What a mess ^^
From one moment to another unit-tests on my local machine stopped working.
There was a PHP fatal error, because of insufficient memory.
Actually, there was a ducking "unit"-test of a controller action "log".
This action returns the content of the projects log file...
Since this log file grew over the time, PHP tried to assert the response of the controller action which was sized about 400MB.
C'moooooon guys!
What were your thoughts behind this bullshit? ^^ -
Deadline was 2-3 days for product launch and doing distributed transactions was not an opinion as it requires heavy modifications.
I was doing money transfer app between one transactional system and one not transactional system so the way I did it was :
1. transfer money from one system to my app that was using Akka STM ( software transactional memory)
2. try to transfer money to second system
3. transfer money back on failure
There was no database, no state only transactional log as installing database would require to much time and paper work.
Sometimes transfer back failed so we need to look back at logs and search for money, it was quite easy cause there was error and there were not so many failed transactions like this.
About one or two in a month and everyone accepted that.
I started to write some sort of reconciliation thread but then was assigned to other work and it worked like this for couple of years transferring couple millions worth of transactions.1 -
Love this kind of humor, coworkers output into a log on errors begins with "Found Unidentified Critical Keyerror". Took a while before I noticed the genius message in this error! My colleague deserves a cookie!1
-
New authentication system for a new type of login, I try to log in
Error everytime I try.
So I wait a little, like 10 min (the server is quite picky, thought it was it).
And then I try with another co-worker.
Login blocked.
Motherf-- -
Other build tools:
Here is a plugin, use it . Be done.
Scala Build Tool aka SBT:
Build your own plugin.
Everything is scala...
You can create by the way funny endless loops when using the wrong syntax - yet it might compile successfully. And then when you load the plugin, it works. Till it is evaluated - lazy evaluation for the fun.
Error messages are at best cryptic.
*If* you manage to get a working plugin and *if* it runs...
Surprise. Surprise.
You might need to parse the log output of SBT.
Another funny surprise: Log output isn't configurable. You can configure the log level. That's it.
So after a lot of pain stakingly putting together a fucking shitty plugin, you can now grind the rest of your brain with ...
sed.
Cause yeah. You can now use regex to parse an sbt build log and extract the necessary information.
:)
...
So....
Are we there?
Mwahahahhaa.
Only if you haven't forgotten to either disable colored output for SBT... Or take an extra mile with e.g. less -R.
Otherwise you have ASCII control characters in your file. :-)
After getting that shit to work, you now have finally a parseable build log.
Just took days instead of hours.
But that's SBT. :-)6 -
Customer: your app is not returning all the objects in my bucket
Support: check console log 500 server error, ssh into box check logs exhausted memory limit.
Sudo vim /etc/php.ini search memory limit
Update to a high number restart Apache sit back and think fuck did I set it to high will it blow up my server.
Only time will tell!!! Sorted out the issue until the next user with millions of objects in their buckets -
Microsoft, please stop the incomprehensible work vs. school account stuff and if you want to mail me a login code, then please actually do send an email. What's wrong with Microsoft Teams and office always giving its users headaches already when trying to log in?
A customer sent me a "FindTime" link, something like Calendso / Calendly, but "powered" by Microsoft Office. Seems that their power is off again, like ever so often. Microsoft: "can't access your account: You can't sign in here with a personal account. Use your work or school account instead."
Okay, go to bing, and search your error message. Try to use bing page to log in to my account: Microsoft: "We emailed a code." (No you didn't. At least I never received anything. And, yes, I did check my spam folder!) Microsoft: "Other ways to sign in: use Microsoft Authenticator".
me: "dear customer, please feel free to pick any time and date that matches your preference, as the FindTime link has been impossible to use".
How can Microsoft make me feel so dumb again, after more than 20 years as a developer? Have they ever heard about usability?10 -
i have not been able to get a single error message to show up for hours. not one console log or warning.
i’m ok.
……
mmmmmmmmMMMMM
AAAAAAAAAAAAUUGHJHGHHGCGGVBVVGFUCKIGNFUCKPIECEOFSHITAFGJHFD5 -
Urgh... No exceptions in Rust annoys me. Now you only have the choice between "this didn't work please handle this error, thank you ^-^" and "you fool, prepare for annihilation". So basically if anything remotely serious happens your programs dead and there's nothing you can do about it. I don't get why people have this hate for exceptions. Everytime a new language gets made it's always either "ew it has exceptions" or "it's so nice it doesn't even have exceptions". NOOO! They can deal with serious situations in the best possible way and they can be statically checked (so no "but they're so complex and unpredicable" stuff please). If you can expect an exception they shouldn't be used in the first place (eventhough they are absolutely no less good than Option returntypes or whatever, just different) but in cases when it's impossible to predict an error they really shine. And not having them makes your language worse. If a device driver accesses illegal memory it should throw an exception, so instead of the computer shitting the bed, first the offending function has a chance to resolve the problem at it's root, then a few functions up the call stack, the general control functions of the device drivers can handle it and restart the operation if applicable, and even if the driver fails to handle it, the OS can jump in and restart the driver, log an error and do whatever. It's absolutely beautiful: This hierarchical ramp from near the accident site to more high level operations code ensures the error can be caught at the right level of abstraction without introduction a lot of boilerplate. If everything fails and nobody can handle it *then* the program or kernel or whatever can panic.4
-
Am I in developer hell already? A shitty project is about to come to an end (hopefully), or should I rather say: It needs to come to an end. But I am still quite lost in how to deal with it, hence procrastinating on it - making the deadline come closer and with it the realization that I'll probably have to rewrite almost everything. I'm not sure how, but I do know that the current code is a dumpster fire.
Basically what I need to do is dealing with the APIs of different payment providers/gateways (like PayPal, AmazonPay). For most cases I'll get a payment ID from the shop and need to act on it later, e.g. capture the authorized money in the case of a credit card transaction or do refunds (without user interaction, unless there is an error). Now at first I put something together where I try to abstract the payment information into two tables:
orders{1}<->{0..n}payments
payments{1}<->{1..n}paymentDetails
Unfortunately trying to abstract the different payment methods and to squeeze them (and their different possible stati and functions) in these tables was not very successful, it's a total mess with magic numbers, half-broken behavior and without any consideration for partial payments/captures or unfinished requests (i.e. if there is an exception before the response is dealt with, there is no indication that anything has ever been sent). Also the current amount is calculated through the history of the paymentDetails table, which basically works differently for each payment type.
How to fix this mess in a way that I'll still have a job by next week?
I'm trying to improve the db schema first, as I think my biggest problems are lying there. Through some research I've come across a recommendation for making payment type specific subtables (with a magic number/string in the main table to prevent having to look up all subtables). That way I can record what I send and receive without having to abstract it too much, so I'll have an acceptable transaction log. The paymentDetails table can be removed (necessary fields go to the payments table). The payments table gets multiple fields for the amount (differentiating between open, authorized, captured, processing and refunded values) and always reflects the current status.
Tables:
payments
paymentRequestsPaypal
paymentRequestsAmazonpay
paymentRequestsXyz
I think I'm going in the right direction here. hm. Maybe there's some light at the end of this long, dark tunnel. Or a train. I'll have two days to find out.6 -
I've just spent 4 hours trying to fix a bug on prod. that can be fixed in 30 secs. At the end I remembered that I should check the error log. FML (error reporting turned off, logs only)
-
Wanted to add a simple log entry when a model changes state in a certain way.
Unit tests pass, functional tests pass, manual tests through application GUI pass.
But for some fucking reason the single line logging call I added results in an error 500 when the application is accessed through a REST API.
Going to have a fun day tomorrow debugging this shit. -
I try to log in via SSH to a remote server. In the beginning all is well. It asks for my password, so I enter the password. Next thing: connection closed by the remote server.
So I wonder what the problem might be... I guess that perhaps I forgot to specify the username. Indeed when I try the 2nd time with my user name added in front of the host name - it works just fine.
But why is there no error message? Why not tell the user what's wrong? "User name is required". Can't be that hard?
Sometimes I see stuff and it just blows my mind why on Earth some things function so poorly. SSH exists for dozens of years yet the error message is not there -> it's guessing time.11 -
What the hell is the point of this small projects team spending 2-3 months on developing extensive logging system for an internal application for inside and outside customers to use if your application isn’t going to log any of the fucking errors. Sure you write the failure status to the database, but it just says failure with an even more vague explanation than microsoft’s errors. “An error occurred”. No shit, that’s why I’m looking in the logs and database to debug the application to get these files on their merry way so our company can stay in compliance with the state, feds, and not pay out the wazzoo in fines. All our other applications state where the error occured such as “failed to connect to the email server”, why can’t this one.
-
trying for three hours to understand why an error occurs. adding one log statement. reloading. everything works... 😡3
-
How should I name NPM package which works as console log for errors, but throws user to stack overflow page with error massage included in the link?
Found a meme here at DevRant in which this idea was presented, haha.12 -
Fucking Ruby.
Installed my new job's codebase on my machine and it's fucked everything.
While trying to get the database working, someone's dropped my User table, so I can't log in as 'Josh' anymore.
Now I can't compile scss assets without a fucking gem error.
I'M IN A PYTHON ENVIRONMENT, FUCK OFF!
GRR.1 -
how do you deal with the situations where you have no clue what happened in production ??
we have a Spark job and suddenly the job execution stopped in the middle without any error log. after sometime it started working again and all the master and workers were fine at that time.
now client wants RCA for that. 😟3 -
I spent 2-3 days on debugging code written in assembly script. Apparently, you need to initialise an array using new method otherwise it re-uses the previous array from the same scope and it has created infinitely large array. Just wtf.
And I got error like "wasm blah blah blah blah blah blah".Just give proper error.
Running the environment locally wasn't an option because well it doesn't fucking work locally. So, I have to forcibly test on CI and they have created a site that can show you logs because you can't access or query data directly from server and while debugging you try to log something it randomly works sometimes and sometimes you get output from god knows which deployment. Just create a fucking API for displaying log or build a proper docker so that we test it locally.1 -
Compare and harmonize the web configs
Oh no someone set execution timeouts to 14 days
Fuck fuck fuckity duck
Hey compare all the web configs of all environments and harmonize them all wtf cmon bruh do your job as a developer
Take them and back them up into svn. What do you mean svn isn't a back up system of course it is well its the only thing we have fuck
What do you mean we have shit logging where people will catch an exception and only print the word exception in the log you can figure it out can't you we have live produxtion issues that hace to be solved now what the fuck
How dare you make a. Mistake copying our shitload of a bloated codebase and configuring our 100s of different options all by fukcing hand what the fuck dude do yoh write anyrhing down?
Please catalogue all the exception mails we are getting but we have no db or error reporting system so they all just plop into tue inbox and thats all ypur fuckjng data figure it out kid
This is a rewarding, fulfilling job whwrw you can be both dev ops and a developer and manage all of our fucking environments of which there are about 15 of all your own with no sort of tool or software to aid you because haha what the fuck we wouldn't make your life easy
Whata that you want to spend time to write stuff or change stuff that will nake it easier fot you fuxk that bruh get back to your biklable tasks like holy shit you thjnk this is a charity ofr aomw shit
Live production issues
Live production issues
Produxtion issues. A ghost in the machine. Find it fix if find it fix it find it fix it cmon why can't you fix it I expect you to spend your day hopelessly pretending to try to solve something you fucker
One of the only peopel able to help you sometimes though hes a bit of an old laxky, yeah hea fucking leaving see ya seeya kid and now we're not hirinf anyone to fuckjng help you no no no managing and monitoring the environments its your jov alll fof them every sngle on do you knkw all the xonfiguraiton values for them yet??
Instead we are hiring a new sales person to fucking make us some more money and we don't need naother seceloper to help you infqct lets have you use this mid end retail computer from 2014 to develop on yeah yeah oh but all our shitty code and visual studip will destry your memory but too bad!! Hahahahahdhsj
Go lice is all you, why sare you so slow
How long will it take
How long will it take
How long will it take
How long witll it tqk2
How long will it take holy shit
Give time estimate for sonethign that I don't fucking know how about it will tqke till fuxk you oxloxk4 -
So, do any of your poor fuckers have the opportunity - nay, PRIVILEGE of using the absolute clusterfuck piece of shit known as SQL Server Integration Services?
Why do I keep seeing articles about how "powerful" and "fast" it is? Why do people recommend it? Why do some think it's easy to use - or even useful?
It can't report an error to save its life. It's logging is fucked. It's not just that it swallows all exceptions and gives unhelpful error messages with no debugging information attached, its logging API is also fucked. For example, depending on where you want to log a message - it's a totally different API, with a billion parameters most of which you need to supply "-1" or "null" to just to get it do FUCKING DO SOMETHING. Also - you'll only see those messages if you run the job within the context of SQL FUCKING SERVER - good luck developing on your ACTUAL FUCKING MACHINE.
So apart from shitty logging, it has inherited Microsoft's insane need to make everything STATICALLY GODDAMN TYPED. For EVERY FUCKING COMPONENT you need to define the output fields, types and lengths - like this is 1994. Are you consuming a dynamic data structure, perhaps some EAV thing from a sales system? FUCK YOU. Oh - and you can't use any of the advances in .NET in the last 10 years - mainly, NuGet and modern C# language features.
Using a modern C# language feature REMOVES THE ABILITY TO FUCKING DEBUG ANYTHING. THE FUCKER WILL NOT STOP ON YOUR BREAKPOINTS. In addition - need a JSON parsing library? Want to import a SDK specific to what you're doing? Want to use a 3rd party date library? WELL FUCK YOU. YOU HAVE TO INDEPENDENTLY INSTALL THE ASSEMBLIES INTO THE GAC AND MAKE IT CONSISTENT ACROSS ALL YOUR ENVIRONMENTS.
While i'm at it - need to connect to anything? FUCK YOU, WE ONLY INCLUDE THE MOST BASIC DATABASE CONNECTORS. Need to transform anything? FUCK YOU, WRITE A SCRIPT TASK. Ok, i'd like to write a script task please. FUCK YOU IM GOING TO PAUSE FOR THE NEXT 10 MINUTES WHILE I FIRE UP A WHOLE FUCKING NEW INSTANCE OF VISUAL STUDIO JUST TO EDIT THE FUCKING SCRIPT. Heaven forbid you forget to click the "stop" button after running the package and open the script. Those changes you just made? HAHA FUCK YOU I DISCARDED THEM.
I honestly cant understand why anyone uses this shit. I guess I shouldn't really expect anything less from Microsoft - all of their products are average as fuck.
Why do I use this shit? I work for a bunch of fucks that are so far entrenched in Microsoft technologies that they literally cannot see outside of them (and indeed don't want to - because even a cursory look would force them to conclude that they fucked up, and if you're a manager thats something you can never do).
Ok, rant over. Also fuck you SSIS1 -
Relatively often the OpenLDAP server (slapd) behaves a bit strange.
While it is little bit slow (I didn't do a benchmark but Active Directory seemed to be a bit faster but has other quirks is Windows only) with a small amount of users it's fine. slapd is the reference implementation of the LDAP protocol and I didn't expect it to be much better.
Some years ago slapd migrated to a different configuration style - instead of a configuration file and a required restart after every change made, it now uses an additional database for "live" configuration which also allows the deployment of multiple servers with the same configuration (I guess this is nice for larger setups). Many documentations online do not reflect the new configuration and so using the new configuration style requires some knowledge of LDAP itself.
It is possible to revert to the old file based method but the possibility might be removed by any future version - and restarts may take a little bit longer. So I guess, don't do that?
To access the configuration over the network (only using the command line on the server to edit the configuration is sometimes a bit... annoying) an additional internal user has to be created in the configuration database (while working on the local machine as root you are authenticated over a unix domain socket). I mean, I had to creat an administration user during the installation of the service but apparently this only for the main database...
The password in the configuration can be hashed as usual - but strangely it does only accept hashes of some passwords (a hashed version of "123456" is accepted but not hashes of different password, I mean what the...?) so I have to use a single plaintext password... (secure password hashing works for normal user and normal admin accounts).
But even worse are the default logging options: By default (atleast on Debian) the log level is set to DEBUG. Additionally if slapd detects optimization opportunities it writes them to the logs - at least once per connection, if not per query. Together with an application that did alot of connections and queries (this was not intendet and got fixed later) THIS RESULTED IN 32 GB LOG FILES IN ≤ 24 HOURS! - enough to fill up the disk and to crash other services (lessons learned: add more monitoring, monitoring, and monitoring and /var/log should be an extra partition). I mean logging optimization hints is certainly nice - it runs faster now (again, I did not do any benchmarks) - but ther verbosity was way too high.
The worst parts are the error messages: When entering a query string with a syntax errors, slapd returns the error code 80 without any additional text - the documentation reveals SO MUCH BETTER meaning: "other error", THIS IS SO HELPFULL... In the end I was able to find the reason why the input was rejected but in my experience the most error messages are little bit more precise.2 -
I tried to explain to our Ruby system architect that rescuing Exception (which also catches NoMemoryError) is a bad idea. I'm then told we _want_ to catch it and log who the culprit is and flash an error to the user. There's still a palm print on my face.
-
Converting code to swift 3.
First time I've seen build succeeded in 4 days.
Error on user log in screen.1 -
Algolia says:
"So our price widget doesn't allow decimals, you'll have to create a custom widget"
I do it.
"Hey, It's not working and I verified it's applying the filter correctly. I noticed my price is a string in your index, maybe that's incorrect and causing it to not work?"
They say: "Yep, you'll need to run an update to fix that and change all to floats" (charges an arm and a leg for the thousands of index operations needed to update the data type)
I clear the index and send a single one as a test, verifying it's a float by casting it using (float) then var_dumping. It shows "double(3.99)", but when it gets to Algolia, it's 0.
So I contact support.
"Hi, I'm sending across floats like you say but it's receiving it as 0, am I doing something wrong? Here's my code and the result of the var_dump"
They respond: "Looks like you're doing it right, but our log shows us receiving 3.999399593939, maybe check your PHP.ini for "serialize_precision" and make sure it's set to -1"
I check and it's fine, then I realize that var_dump is probably rounding to 2 decimal points so I change my cast to (float) number_format($row['Price'], 2) and wallah...it works.
Now I've wasted days of paying for their service, a ton of charges for indexing operations, and it was such a simple fix.
if they had thrown an error for the infinite decimal, that would have helped, but instead I had to reach out to find out that was the issue.
#Frustrated. -
I'm having problems understanding ngrx (or simply rxjs...), once again.
I have a feature state called "World".
This state has three Actions: Init, InitSuccess and InitFailure.
Also I have other isolated feature states like "Mountains", "Streets", "Rivers".
They have actions like this and corresponding effects to fetch data: Load, LoadSuccess, LoadFailure.
Now I would like to add an effect to WorldActions.Init, which will dispatch Mountains.Load, Streets.Load, Rivers.Load one after another. So ideally an action log would look like this:
1. World.Init
2. Mountains.Load
3. Streets.Load
4. Rivers.Load
5. Mountains.LoadSuccess
6. Streets.LoadSuccess
7. Rivers.LoadSuccess
8. World.InitSuccess
Or when an error occurs:
1. World.Init
2. Mountains.Load
3. Mountains.LoadFailure
4. World.InitFailure
How could an effect pipeline for that look?
How can I dispatch World.InitSuccess only after all LoadSuccess-Actions have happened?
Or am I still trying to implement ngrx in a wrong/bad way?
PS: The reason I am putting everything into separate feature states is because "Mountains" etc. are standalone features on their own. Only in the context of a "World" they belong together. For this reason I can't create a monstrous effect "World.Load", without producing redundant code.10 -
Sometimes being a developer really sucks. I adopted a heavily customized OXID shop which introduced an ingame currency beside the fiat currency.
It was done by introducing $iPriceChannel and replacing the $dPrice float value with a multidimensional array across all components, controllers and models.
Wait ... not 100% of the code has been "adapted" yet but it's sufficient to get it working at the first glance.
The reality is: The shop has many subtle bugs and piles up huge (error) log files.
Every time when a bug was found,
and every time the shop maintainer is unlocking an OXID feature which hasn't been used yet, I have to fix it.
It's even extra hard to fix issues sometimes because the shop is embed in a game by utilizing a content-aware reverse proxy. My possibilities to navigate through the shop directly is limited because some of the AJAX/CSS/HTML elements doesn't work without loading this game.1 -
Quick Plesk config question...
Been getting open_basedir() notices in the WordPress logs, and frankly it's flooding the log right now. Sample below:
[24-Feb-2019 07:05:19 UTC] PHP Warning: file_exists(): open_basedir restriction in effect. File(/var/www/vhosts/webspacedomain.com/SiteInstallDirectory/wp-content/db.php) is not within the allowed path(s): (/var/www/vhosts/webspacedomain.com/:/tmp/) in /var/www/vhosts/webspacedomain.com/SiteInstallDirectory/wp-includes/load.php on line 397
Checking the settings for open_basedir in the domain's PHP settings, it's currently set to the following default value:
{WEBSPACEROOT}{/}{:}{TMP}{/}
By my read, that **should** be granting permission to the directory. I just checked it against the setting on the dev server (which doesn't report this error), and it's configured in the same manner. Only difference between Dev environment and this one is that the one in Dev is in vhosts/webspacedomain.net/DEV instead of just vhosts/webspacedomain.net
Is there something I'm missing here?4 -
I declared it a Heisenbug!
So, basically I was starting multiple threads...
I was getting a list index out of range on line 268 which was a dict. Strange.
36 hours later, a lot of changes, I was still having the same error whatever I put on line 268, log, try, but when I got it on a comment... I lost it.
Restarted Pycharm.
Reset the branch to remote.
Everything worked fine.
Fuuuuuuuuuuu -
Another great website error code fail (dumped its full error output to the website):
Traceback (most recent call last):
File "/usr/lib/python2.4/site-packages/trac/web/api.py", line 436, in send_error
data, 'text/html')
File "/usr/lib/python2.4/site-packages/trac/web/chrome.py", line 808, in render_template
template = self.load_template(filename, method=method)
File "/usr/lib/python2.4/site-packages/trac/web/chrome.py", line 768, in load_template
self.templates = TemplateLoader(
File "/usr/lib/python2.4/site-packages/trac/web/chrome.py", line 481, in get_all_templates_dirs
for provider in self.template_providers:
File "/usr/lib/python2.4/site-packages/trac/core.py", line 78, in extensions
return filter(None, [component.compmgr[cls] for cls in extensions])
File "/usr/lib/python2.4/site-packages/trac/core.py", line 213, in __getitem__
component = cls(self)
File "/usr/lib/python2.4/site-packages/trac/core.py", line 119, in maybe_init
init(self)
File "/usr/lib/python2.4/site-packages/authopenid/authopenid.py", line 157, in __init__
db = self.env.get_db_cnx()
File "/usr/lib/python2.4/site-packages/trac/env.py", line 335, in get_db_cnx
return get_read_db(self)
File "/usr/lib/python2.4/site-packages/trac/db/api.py", line 90, in get_read_db
return _transaction_local.db or DatabaseManager(env).get_connection()
File "/usr/lib/python2.4/site-packages/trac/db/api.py", line 152, in get_connection
return self._cnx_pool.get_cnx(self.timeout or None)
File "/usr/lib/python2.4/site-packages/trac/db/pool.py", line 172, in get_cnx
return _backend.get_cnx(self._connector, self._kwargs, timeout)
File "/usr/lib/python2.4/site-packages/trac/db/pool.py", line 105, in get_cnx
cnx = connector.get_connection(**kwargs)
File "/usr/lib/python2.4/site-packages/trac/db/sqlite_backend.py", line 180, in get_connection
return SQLiteConnection(path, log, params)
File "/usr/lib/python2.4/site-packages/trac/db/sqlite_backend.py", line 255, in __init__
user=getuser(), path=path))
TracError: The user apache requires read _and_ write permissions to the database file /home/trac/morituri/db/trac.db and the directory it is located in. -
Converting code to swift 3.
First time I've seen build succeeded in 4 days.
Error on user log in screen. This ride isn't over yet. -
Any advice for debugging a 520 error from Cloudflare?
I know this isn’t SO but Ive been having the toughest time finding a decent way to find the cause of a 520 error from Cloudflare.
I have a droplet of Digital Ocean running Apache 2.4X and randomly throughout the day I will get 520 errors in the browser’s Networking log.
Naturally, there’s nothing even noted in the Apache error log or access log. And Cloudflare has no logs on this in the console.
If I retry the request it will go through with no problem.
Anyone experienced something like this?5 -
Guys, I'm refactoring a server code from es5 to es6 and I would like to know how to get es6 errors like when I'm working with React. I have installed babel, and I can compile es6 code but I get errors that target the es5 (compiled) code so it's not easy to find the bug sources5
-
"Validation failed for one or more entities. See 'EntityValidationErrors' property for more details."
That really helps in my error log Entity Framework ❤ -
I'm trying to create log files with the PID or some JVM arg like app name but File appender doesn't parse ${myVar} in the config.
Issue is we have multiple instances of an app running but they can't be all writing to the same file.
I tried creating a custom Appender by pretty much copying the source code of FileAppender and then adding a function to add PID to the filename.
But when I use it, get some error saying "name, and fileName" are invalid parameters.
So wondering if anyone has experience building one that works out maybe there an existing code for such an appender?12 -
NPM version : 10
React-Native Library : react-native-get-music-files
Installation :
npm i --save react-native-get-music-files
rnpm link
Things I Have Already Tried :
rnpm link react-native-get-music-files
react-native link
npm install
react-native run-android
REINSTALLING
MAKING A NEW PROJECT
Details :
Its documentation says add import com.reactlibrary.RNReatNativeGetMusicFilesPackage; but when automatically linking , it adds com.cinder72.musicfiles.RNReactNativeGetMusicFilesPackage;
Manually it is showing com.reactlibrary.RNReatN... is not found.
Automatically everything is working fine.
Error :
In the react-native-get-music-files/index.js
import { NativeModules, Platform } from 'react-native';
const { RNReactNativeGetMusicFiles } = NativeModules;
const MusicFiles = {
getAll(options){
return new Promise((resolve, reject) => {
if(Platform.OS === "android"){
RNReactNativeGetMusicFiles.getAll(options,(tracks) => {
resolve(tracks);
},(error) => {
resolve(error);
});
}else{
RNReactNativeGetMusicFiles.getAll(options, (tracks) => {
if(tracks.length > 0){
resolve(tracks);
}else{
resolve("Error, you don't have any tracks");
}
});
}
});
}
}
export default MusicFiles;
It says RNReactNativeGetMusic files is undefined.
I tried console log NATIVEMODULES and it shows nothing as RNReactNativeGetMusic or anything similar.2 -
Omg why are social cards so hard to debug? Did no one think of such obscure techniques as local debugging? And why doesn't Twitter show me the error message? It's the same code for fuck sake! It works with one article but not with another. There MUST be some very exact problem with one of my images, but Twitter just doesn't fucking give me a proper log.1
-
Had a jira ticket for a cpanel user where the end user creates any database through mysql database ends up with already exists. No matter what string we take though.
Anyone had this error before? Will update log sooner -
So I'm the only tester at my company, and I've had to adapt a lot of my skills to fit in with our in house expectations. So everything was fine when I focused on trying one component (manual and automation).
Slowly over time I've had more components to test with exact same resource of me.
Eventually my automatic breaks as I could no longer maintain that and all the other manual tests and all the other jobs I do ( light level internal it support, jira ticket rangerling, rollbar (error messages) basic investigation).
My boss keeps saying why is x,y,z not tested / missed while I can point to time periods where was focused on v instead so didn't get to others.
I keep wanting to just hit them with a keyboard until they realise 10± devs to one qa in our environment just isn't going to work.
I keep getting promised some dev time to help with qa so I can play catch up but never seems to arrive.
Don't get me wrong I'm not the best I used to be at testing(before joining I was proud of my abilities, maybe all stick and not enough carrot wears you down)
We keep taking on new work flows that make no sense (create a bug ticket, then a task ticket if bug take more than hour to do, then I'm stuck chasing developers to update their task ticket so I cam update the bug ticket (if its a bug then log sodding log time against it).
I've gotten to point now where I'm stopping my suggestions, explaining why something didn't get dome and will see if they can answer their own stupid questions
At what point do you stop ignoring the voices in your head (metaphorically).
Do other people go through this cycle where feel like pushing a boulder up the hill, for them to either push your boulder down the hill, replace it with a bigger boulder, move to a bigger hill, get you to move more rocks at once or all the above.
I know QA has its quite and busy phases but for me it seems to be constantly busy with no respite4















































































































































Top Tags
Weekly Rant
View