
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
If Doctors Were Like Coders
(cross-posted from https://medium.com/@c09b6133a238/...)
Problem: The patient has a broken leg.
Solution:
1. Ask the patient to reproduce the exact scenario that resulted in the broken leg. Watch closely to see if the leg breaks again. Check for consistency by repeating the scenario a few more times.
2. Explain that this isn’t an intended use case for the leg, and besides, it only affects one person. Ask the patient if, all things considered, he really wants to prioritize his broken leg over your other work.
3. Point out that the patient’s other leg performs just fine under the same circumstances. Ask if he can use his other leg instead, at least as a workaround.
4. Attach several accelerometers to the broken leg and break it again. Stare at the data received from the accelerometers, then shrug and declare it useless.
5. Decide that the patient’s problem must be in his spleen. After all, that’s the only part of his body you don’t really understand.
6. Track down the people who created the patient. Ask them if he’s ever had spleen problems before. When they seem confused, explain that he has a broken leg. Ignore them when they tell you that the spleen they created could not possibly cause a broken leg.
7. Ask Google where a person’s spleen is. Spend half an hour reading the Wikipedia article on Splenomegaly.
8. Open the patient and grumble about how tightly-coupled his spleen and circulatory system are. Examine the spleen’s outer surface to see if there are any obvious problems. Inform him that several of his organs are very old and he should consider replacing them with something more modern.
9. Compare the spleen to some pictures of spleens online. If anything looks different, try to make it look the same.
10. Remove the spleen completely. See if the patient’s leg is still broken. If so, put the spleen back in.
11. Tell the patient that you’ve noticed his body is made almost entirely out of cellular tissue, whereas most bodies these days are made out of cardboard. Explain that cardboard is a lot easier for beginners to understand, it’s more forgiving of newbie mistakes, and it’s the tissue franca of the Internet. Ask if he’d like you to rebuild his body with cardboard. It will take you longer, but then his body would be future-proof and dead simple. He could probably even fix it himself the next time it breaks.
12. Spend some time exploring the lymph nodes in the patient’s abdominal cavity. Accidentally discover that if the patient’s leg is held immobile for six weeks, it gets better.
13. Charge the patient for six weeks of work.14 -
Wikipedia says that a nerd/geek lacks social skills. They should see this amazing community, thanks DevRant :)10
-
Interviewer: Who created JavaScript?
Me: ... Seriously?
Interviewer: Completely
WTF? First time I face that kind of question in an interview... For the record, I didn't know the answer, according to Wikipedia Brendan Eich created JS56 -
Welcome to the internet of 2019 after Article 13!
FUCK ARTICLE 13
MOST OF THE MEMBERS OF THE EUROPEAN PARLIAMENT WHO VOTED FOR ARTICLE 13 ARE OLD PEOPLE WHO ARE STILL USING KEY MOBILE PHONES AND HEARD OF THIS THING CALLED "INTERNET" ONCE IN THEIR LIFE.
THIS "INTERNET" ("Neuland") CAN'T BE THAT IMPORTANT, JUST BECAUSE YOU DON'T USE IT IN YOUR FREE TIME?
I literally can imagine what the European parliament members think:
"The people will like it i guess!"
"What, you can chat with other people in the internet? NEVER HEARD OF THAT."
"I don't understand this 'Memes'. It is not funny and i don't like it!"
"My sons always much too long on his computer, this 'Internet' can't be good!"
I am sorry for the rage, but i just can't believe that people, who maybe mostly have never dealt with the internet, are destroying the future of self-fulfillment and free resources for everyone.
YouTube will start deleting channels who are not big enough, who are not sponsored or made by a big company. They will just delete them. And videos from out of the European union won't be able to be watched in Europe. Big companies will gain power over the internet(I know the partly already have much). Educational sites like Wikipedia and YouTube for example will die, but hey, FUCK MY LIFE!!!
FUCK MY FUTURE!!!
FUCK FIRST WORLD DEVELOPMENT!!!
WHY NOT JUST GO BACK TO THE STONE AGE???
FUCK OUR CITIZENS JIIIIHAAA!!!
"Nah i never needed YouTube. Or Facebook" + (we can talk about this one) + " Or Instagram. I never saw someone of my friends using it."
FUCK !!!
https://change.org/p/... 34
34 -
Alright wikipedia, i see that you're in a crisis, but I just send 5€ your way. That should not be the fucking signal to unleash popup hell on me. Fucking 4 out of 5 pages now come with that popup. "if rveryone woukd just send $2..."
BITCH I SEND YOU 5€, STOP DEEPTHROATING ME YOUR UNGRATEFUL COCK10 -
Mistyping one character wrong in a password and hitting backspace until I am sure I’ve deleted the entire Wikipedia.
Then starting all over again.3 -
When you go to a doctor and he starts to google your symptoms in front of you and reads you texts from wikipedia page of the disease he assumes you have, then writes you a prescription for some random meds.
Maybe he was a dev before.5 -
I promised myself to be extra productive today. After an hour of working, I took a small break to read a bit about Elon Musk...
...and somehow I ended up reading about the history of jigsaw puzzles on Wikipedia. Ffs.6 -
So Twitter apparently used http status code "420 - Enhance your calm" to notify the client that it was sending too many requests (basically chill the **** out). Note the status code number as well 😁
Image from wikipedia. 2
2 -
"Microsoft should not need to buy github, the platform itself should be ran by a non profit org like wikipedia or linux."
Add a herp a derp at the end. It will probably make it sound less stupid or hypocritical.
Seriously though, how many of you mecos actually pay for shit? Eh? How many of you donate to your fav Linux distros or web platforms?
Lets say that the entire devrant base did :) pretty sweet eh? There are still 28 million developers on fucking github.....now how many of those contribute to help account for server costs etc? How many actually use private paid repos etc?
And without adds and shit? This ain't Facebook!!
It makes sense. I am glad they did... and fuck you I would too.
I will see what happens before I put on my (disgusting) Richard Stallman Hat.25 -
I read somewhere that you can go to Adolf Hitler Wikipedia page from any other wiki page within 5 clicks!
Here's what I tried.
List of Programming Languages -> Lisp -> Massachusetts Institute of Technology -> World War II -> Adolf Hitler7 -
(Not dev, not rant, although it might become one later on)
So as some of you may know, I am colorblind. I always avoid working with colors because of it. Yesterday I decided to do something I've always wanted, painting. And no I don't mean painting on a canvas but miniatures and other 3D models.
I love catan, I love 3D printing and I thought let's print a catan set and paint it myself, without depending on family to ask for colors.
I've got this German paint tubes and used the wikipedia color descriptions to decide what to paint which color.
The following is the result, its a wheat tile (and in the background a wood tile).
Feel free to give tips and suggestions. If I picked a wrong color please tell me so I can update my tactics.
Finally took this step. Yay 25
25 -
PHP doesn’t scale. Riiiiiight. Wikipedia runs entirely on PHP and is the fifth most visited site on the internet. There’s also this little site called Facebook that uses PHP, ever heard of it?
PHP is slow. Sure, old PHP can be slow. The argument is about as sound is saying that OS X is a terrible OS because my first Apple IIe was slow. PHP 7 is plenty fast, even three time faster than Python.
https://hackernoon.com/php-is-dead-...32 -
Not having finished any education, and writing code during interviews.
I have a pretty nice resume with good references, and I think I'm a reasonably good & experienced dev.
But I'm absolutely unable to write code on paper, and really wonder how some devs can just write out algorithms using a pen and reason about it, without trying/failing/playing/fixing in an IDE.
Education I think.
I can transform the theory on a complex Wikipedia page about math/algorithm into code, I can translate a Haskell library into idiomatic python... but what I haven't done is write out sorting functions or fibonacci generators a million times during Java class.
I don't see the point either... but I still feel utterly worthless during an interview if they ask "So you haven't even finished highschool? Can you at least solve this prime number problem using a marker on this whiteboard? Could you explain in words which sorting algorithm is faster and why?"
"Uh... let me fetch a laptop with an IDE, stackoverflow and Wikipedia?"22 -
Today I learned Slovakia is in fact a version control system, not country.
Things you find on Wikipedia these days.. 🤔 6
6 -
WHAT THE FUCK, AVAST!
You can't just fucking unbind chrome from my taskbar and pin your fucking trash excuse of a browser.
Reading the fucking Wikipedia article:
"It is based on Chromium, but was subsequently found to contain a serious security flaw not present in Chromium itself."
- https://en.wikipedia.org/wiki/...
ARE YOU KIDDING ME?! 39
39 -
Okay so literally the first time I want to donate money to Wikipedia because they've been a great help over the years I click on PayPal and I get a 502 page
Yeah... Thanks3 -
Books and command lines.
I don't like teachers.
I think it's because my learning process is very async and chaotic. When I see a snippet in Golang, I relate it to PHP, Rust and Haskell. I jump to resolving the problem in other languages, trying to find out which approaches work in Go.
Then I read about some computer science concept on Wikipedia and get lost in that while my hunger for knowledge and food increases. After a while I look up a recipe for a pasta salad, and while cutting bell peppers, I see the recipe in terms of typed morphisms, I sprinkle and intersperse ingredients through mapping functions, then decide to write an interpreter for the esoteric "Chef" language in Go so I can interpret my salad recipe while eating it.
Voila, I'm learning Go.
I have no patience for linear mentoring, and others have no patience for mentoring me.
But that's OK.1 -
If you want to fly to the US, you might want to get back to your CS courses first.
https://mobile.twitter.com/cyberomi... 10
10 -
Hello again, everyone. I've been busy with all the paperwork at my ship (will make a post about it later) but for now, I'll bore you with another story (not navy one, fortunately) to justify my slacking off.
And this story... is the story on how I got into ITSec. And it is pretty damn embarrassing. It all began when I was 16. I was hooked on battleknight.gameforge.com, a browser game. My father had just had ADSL installed at our home, and the new opportunities before me were endless. Well...
After I've had my fill with the porn torrents and them opportunities dwindled to just a few dozens, I began searching for free games, and I stumbled on that game. I played a lot, but as a free-to-play game, it was also pay-to-win. I didn't have a credit card, so I paid for a few gems with SMS messages. Fast forward a couple of years, I got into the Naval Academy. A guy came in to advertise something (I think it was an encyclopaedia or something - yes, wikipedia wasn't a thing back then) and to pay for it, we could apply for a credit card. So I applied. And I resisted the temptation for a year.
Note: prepaid wasn't that known where I live, so using credit cards was the only way for online transactions.
So I made 1 transaction. Just one. After a couple of months my monthly report from the bank came, showing a 2.5$ (I think) transaction on Paypal. I paid no mind, thinking that it was some hidden fee. Oh boy, I shit you not, I was THAT much of an idiot. Six months later, BOOM!
600$ transaction to ebay via paypal. You can imagine all those nice things that came to my mind. In any case, the bank accepted my protest that I filed at their central offices and cancelled the transaction. I promptly cancelled my card, destroyed it right there for good measure, and got to thinking... what the fuck just happened?
As many people here, I am afflicted with a deadly virus, called curiosity. I started researching the matter, trying to figure out how. And, because I didn't like black boxes and "it is just like it is" explanations, I tumbled down the rabbit hole of ITSec. I soon found out that, not only it was possible, but also it was sometimes EXTREMELY easy to steal credit card info. There are sites, to this very day, that store user info (along with credit cards info) IN FUCKING CLEARTEXT. Sometimes your personal, financial and even medical info are just an SQLi away.
So, I got very disillusioned on many things. But I never regretted it. It may cause me to age prematurely and will kill me of stroke or heart attack one day, but as I still tumble down the ITSec rabbit hole, I can say with confidence that
I REGRET NOTHING
Plus, my 600$ were returned, so look on the bright side :)1 -
An excerpt from the best rant about whiteboard interviews posted on the internet. Ever.
"Well, maybe your maximum subsequence problem is a truly shitty interview problem. You are putting your interview candidate in a situation where their employment hinges on a trivia question. — Kadane's algorithm! They know it, or they don't. If they do, then congratulations, you just met an engineer that recently studied Kadane's algorithm.
Which any other reasonably competent programmer could do by reading Wikipedia.
And if they don't, well, that just proves how smart the interviewer is. At which point the interviewer will be sure to tell you how many people couldn't answer his trivially simple interview question.
Find a spanning tree across a graph where the edges have minimal weight. Maybe one programmer in ten thousand — and I’m being generous — has ever implemented this algorithm in production code. There are only a few highly specific vertical fields in the industry that have a use for it. Despite the fact that next to no one uses it, the question must be asked during job interviews, and you must write production-quality code without looking it up, because surely you know Kruskal’s algorithm; it’s trivial.
Question: why are manhole covers round? Answer: they’re not just round, if you live in London; they're triangular and rectangular and a bunch of other shapes. Why is your interview question broken? Why did you just crib an interview question without researching whether its internal assumption was correct? Do you think that “round manhole covers are easier to roll" is a good answer? Have you ever tried to roll an iron coin that weighs up to 300 pounds? Did you survive? Do you think that “manhole covers are circular so that they don’t fall into manholes” is a good answer? Do you know what a curve of constant width is? Do you know what a Reuleaux triangle is? Have you ever even been to London?
If the purpose of interviewing was to play stump the candidate, I’d just ask you questions from my area of specialization. “What are the windowing conditions which, during the lapping operation on a modified discrete cosine transform, guarantee that the resynthesis achieves perfect reconstruction?” The answer of course is the Princen-Bradley condition! Everyone knows that’s when your windowing function satisfies the conditions h(k)2+h(k+N)2=1 (the lapping regions of the window, squared, should sum to one) and h(k)=h(2N−1−k) (the window should be symmetric). That’s fundamental computer science. So obvious, even a child should know the answer to that one. It’s trivial. You embarrass your entire extended family with your galactic stupidity, which is so vast that its value can only be stored in a double, because a float has insufficient range:"
Author: John Byrd
Src: https://quora.com/What-is-the-harde...3 -
Official Release of Wikipedia Bot is Here
How to Use: @wiki <Query>
Runs on cron job, every minute.
If there is literally no Wikipedia page for query, still gets a relevant result.
Demo in Comments.281 -
"I'll just fetch the data from Wikipedia, it must be really simple using their API"
I've never been so wrong.2 -
Finally some user facing change on @Wikipedia
#PagePreview
Shouldn't this have come much much earlier? 7
7 -
!rant
So nearly done with the work app and I need these images scaled accurately (it's for comparing pupils) my problem is I'd normally ask my brother to make the images but he is busy with uni for the next few weeks.
I'm just wondering is there a tool I can use that can rescale images (I have images from the iPhone app, and I gotta say I had to add in % changes despite the proper dpi sizing), I'm looking at the Android documentation but what's funny is in the listed resolutions OnePlus 3 wasn't included (along with some other newer resolutions) lol, and also Wikipedia for OnePlus 3 has the width and height switched (for some reason the author imagined the phone is also in landscape lol).
So do you guys know of something I can use? Programming is one thing but designer is another :/4 -
Since fucking when did "bare metal" mean just running on an OS?? At a conference and literally everyone is like "we got kubernetes running on bare metal", got super excited for a bit because just the idea of that sounds amazing but they're using it as slang for "basically not in a container or vm."
Nothing exciting at all. Now we're patting ourselves on the back for getting software working without it being preconfigured as a container or a VM image. No one knows how to do anything any more. MUCH too much abstraction going on.
I guess it keeps me more employable, but the state of the world from a developer standpoint is just sad.
(For reference, this is what the first sentence of "Bare Metal" looks like on wikipedia "In computer science, bare machine (or bare metal) refers to a computer executing instructions directly on logic hardware without an intervening operating system.")3 -
Woohoo!!! I made it to 1000++s :) Now I feel less newbie-like around here :)
So... I don't want to shit-post, so in gratitude to all you guys for this awesome community you've built, specially @trogus and @dfox, I'll post here a list of my ideas/projects for the future, so you guys can have something to talk about or at least laugh at.
Here we go!
Current Project: Ensayador.
It's a webapp that intends to ease and help students write essays. I'm making it with history students in mind, but it should also help in other discipline's essay production. It will store the thesis, arguments, keywords and bibliography so students can create a guideline before the moment of writting. It will also let students catalogue their reads with the same fields they'd use for an essay: that is thesis, arguments, keywords and bibliography, for their further use in other essays. The bibliography field will consist on foreign keys to reads catalogued. The idea is to build upon the models natural/logical relations.
Apps: All the apps that will come next could be integrated in just one big app that I would call "ChatPo" ("Po" is a contextual word we use in my country when we end sentences, I think it derived from "Pues"). But I guess it's better to think about them as different apps, just so I don't find myself lost in a neverending side-project.
A subchat(similar to a subreddit)-based chat app:
An app where people can join/create sub-chats where they can talk about things they are interested in. In my country, this is normally done by facebook groups making a whatsapp group and posting the link in the group, but I think that an integrated app would let people find/create/join groups more easily. I'm not sure if this should work with nicknames or real names and phone numbers, but let's save that for the future.
A slack clone:
Yes, you read it right. I want to make a slack clone. You see, in my country, enterprise communications are shitty as hell: everything consists in emails and informal whatsapp groups. Slack solves all these problems, but nobody even knows what it is over here. I think a more localized solution would be perfect to fill this void, and it would be cool to make it myself (with a team of friends of course), and hopefully profit out of it.
A labour chat-app marketplace:
This is a big hybrid I'd like to make based on the premise of contracting services on a reliable manner and paying through the app. "Are you in need of a plumber, but don't know where to find a reliable one? Maybe you want a new look on your wall, but don't want to paint it yourself? Don't worry, we got you covered. In <Insert app name> you can find a professional perfect to suit your needs. Payment? It's just a tap away!". I guess you get the idea. I think wechat made something like this, I wonder how it worked out.
* Why so many chat apps? Well... I want to learn Erlang, it is something close to mythical to me, and it's perfect for the backend of a comms app. So I want to learn it and put it in practice in any of these ideas.*
Videogames:
Flat-land arena: A top down arena game based on the book "flat land". Different symmetrical shapes will fight on a 2d plane of existence, having different rotating and moving speeds, and attack mechanics. For example, the triangle could have a "lance" on the front, making it agressive but leaving the rest defenseless. The field of view will be small, but there'll be a 2d POV all around the screen, which will consist on a line that fills with the colors of surrounding objects, scaling from dark colors to lighter colors to give a sense of distance.
This read could help understand the concept better:
http://eldritchpress.org/eaa/...
A 2D darksouls-like class based adventure: I've thought very little about this, but it's a project I'm considering to build with my brothers. I hope we can make it.
Imposible/distant future projects:
History-reading AI: History is best teached when you start from a linguistic approach. That is, you first teach both the disciplinar vocabulary and the propper keywords, and from that you build on causality's logic. It would be cool to make an AI recognize keywords and disciplinary vocabulary to make sense of historical texts and maybe reformat them into another text/platform/database. (this is very close to the next idea)
Extensive Historical DB: A database containing the most historical phenomena posible, which is crazy, I know. It would be a neverending iterative software in which, through historical documents, it would store historical process, events, dates, figures, etc. All this would then be presented in a webapp in which you could query historical data and it would return it in a wikipedia like manner, but much more concize and prioritized, with links to documents about the data requested. This could be automated to an extent by History-reading AI.
I'm out of characters, but this was fun. Plus, I don't want this to be any more cringy than it already is.12 -
I really liked this xkcd, so here are the links to the Wikipedia articles mentioned!
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/...
https://en.wikipedia.org/wiki/... 4
4 -
!dev && rant
What's people's problem with Wikipedia.
Earlier this week I told my cleaning lady about how Black Friday was so pointless this year, and apparently it's the first thing she heard about Black Friday (she's in her late 30's and a mother of 2, go figure). Not only that but she believed that it occurred every end of the month because someone else told her so. She said it would make sense because it's close to everyone's payday.
So I go and look up some information about Black Friday for her. All the DDG results somehow shit or cluttered by marketing wank.. your guess is as good as mine. Anyway, appended Wikipedia to get some reasonably good information quick. And that looked for all the world like that was the case. Apparently it's got to do with American Thanksgiving.. who knew?
She still didn't believe it. "But that's Wikipedia..." So she looked it up on her own phone on some random local site.. it confirmed that indeed it occurs once a year. Well, confirmed to the extent that there was "2017", "2018" and "2019" on the page... Yeah.
Finally she believed it. At least she didn't double down on it anymore. But seriously.. you're gonna take the words of one random person over a medium that's constantly being improved under the many eyes principle?
"People can edit Wikipedia so therefore it's bad"
I really don't get people...18 -
the internet was so good before corporate interests took everything over and made it garbage
before you found real people, instead of shills
real hobbies, instead of someone wanting to sell you knockoff shit by pretending to have information on your hobby
real information, instead of stupid politics which pretend information doesn't exist and keep changing Wikipedia pages or brigading forums with spam or reporting websites or servers as violating rules to remove innocent people and ruin their shit
before you could find tools and use them
and there were no ads
even when there were ads they were just banner ads where you got free iPods and maybe a virus
but they didn't subscribe you to their service monthly and then play psychological tricks on you so you couldn't cancel
even when the popups came we had popup blockers, and the web browsers were on our side and made the feature widespread and viewed the popups as malicious, and now the world's biggest ad company serves the most popular "open source" browser and is in a war against usability because they have to display their brain malware ads to you or else
and you'd get excited to get an email, instead of annoyed it's more fucking corporate spam you don't want from a random website that required you to give your email address so you could've bought a trinket for your friend Bob's birthday that one time and now their subscriber list keeps "forgetting" you unsubscribed
phones have a billion sensors but the app stores are so infested with bullshit none of it matters
it's all rot
everything is starving and making your life worse
we used to do so much with so little
and now we have so much and leave it all on the table to throw poop at each other
don't forget that brigade science tells you nostalgia is you remembering something to be better than it was. be gaslit. webpages disappear now, too. they get changed. archive.org has the records, and got DDoSed the other day. I knew this day would happen. everyone who lies would love for there to be no archives, no records. to burn the modern books4 -
Interested in the "If 42 is the answer? What is the question?" diversity. 🤔
*me going to wikipedia*
searching for 42
buncha math stuff whatever
matrix sum... interesting 🤨
(is 42 maybe related to dimensions?)
*sees a lot of programs relations where 42 is considered magical in themselves*
"The ASCII code 42 is for the asterisk symbol, being a wildcard for everything."
*literally speechless* 😮8 -
So one year ago, when I was second year in college and first year doing coding, I took this fun math class called topics in data science, don't ask why it's a math class.
Anyway for this class we needed to do a final project. At the time I teamed up with a freshman, junior and a senior. We talked about our project ideas I was having random thoughts, one of them is to look at one of the myths of wikipedia: if you keep clicking on the first link in the main paragraph, and not the prounounciation, eventually you will get to philosophy page.
The team thought it was a good idea and s o we started working.
The process is hard since noe of us knew web scraping at the time, and the senior and the junior? They basically didn't do shit so it's me and the freshman.
At the end, we had 20000 page links and tested their path to philosophy. The attached picture is a visualization of the project, and every node is a page name and every line means the page is connected.
This is the first open project and the first python project that I have ever done. Idk if it is something good enough that I can out on my resume, but definitely proud of this.
PS: if you recognize the picture, you probably know me. If you were the senior or the junior in the team, I'm not sorry for saying you didn't do shit cuz that's the truth. If you were the freshman, I am very happy to have you as a teamate.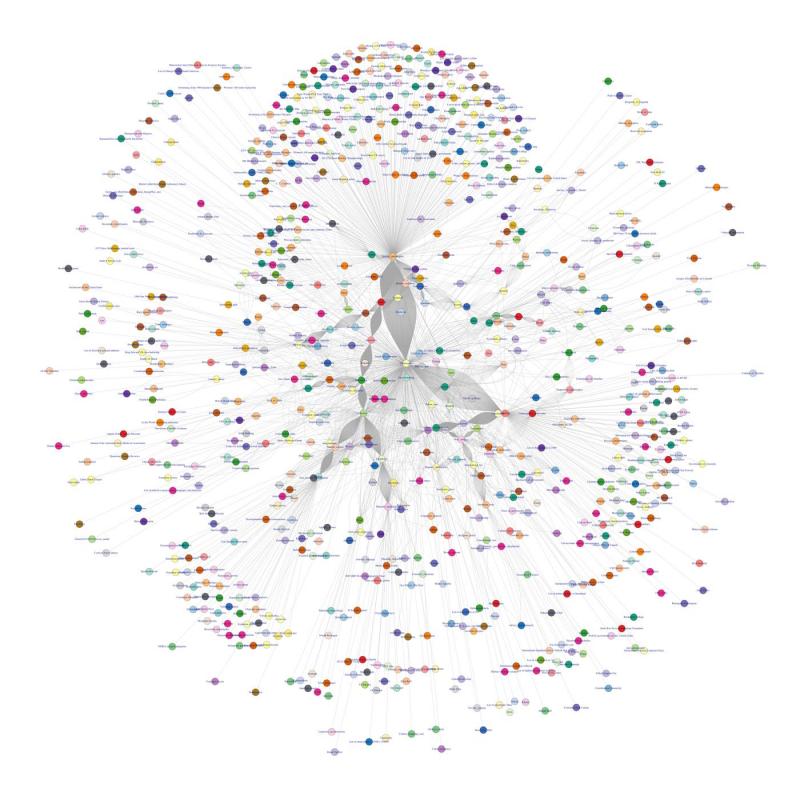 3
3 -
Took client's site live and enthusiastically encouraged them to write original content...
Very first page published was literally a slash and paste of an entire wikipedia entry with inline links still in the text. -
in the past 48 hours my partner must have asked me 50 times to create an "AI" that can get the data we need off of wikipedia.
Background: I am in AP Computer Science AB but I have been programming long enough that this class is a joke. We were assigned to partners with the task of creating a search engine that finds informations on wikipedia("which is dumb because thats what the search tool is for") so I created a Java Web-Scraping program in probably 30 minutes and showed my partner. He told me I am completely wrong because it would be "cool" to incorporate machine learning into the assignment.
Do I even tell his what machine learning is or should I just let his figure it out?7 -
Your CC is safe with us.
Most likely dead code was included in 2013, never modified.
Someone was happy to use Wikipedia
-
According to Wikipedia my sock is a technical standard for accessing information over a mobile wireless network. Such power my feet possess.
(/◕ヮ◕)/ 4
4 -
To long to read. So don’t do it.
I feel disappointed. It’s not about job or stuff. I’m disappointed about world in general. I don’t see my future on this planet anymore.
The world more or less looks like that :
Politics are trying to help you by stealing more money from you. The more you’re lucky the more money you will pay for it.
Media punch you with some family stuff from everywhere, give you young rich and far away, beautiful picture photos of places, people and food that you at most could visit once or twice per year during holidays that are break from work concentration camps.
If you’re lucky you’re rich or got rich or wealthy and infamous so you can walk wherever you want and don’t give a fuck what you wear but again your old friends are not so lucky bastards so you need to find new friends that are probably assholes. At the end most of the days you you’re doing nothing except killing time to meet with people you like during weekends or evenings.
Then there are families and everyone want to tell you that’s important. Family is like herd of assholes, if you’re weak they will sacrifice you and tell that you’re looser behind your back but when you get wealthy they will come back to tell you that when you were young and stupid they played with you so now you have to buy them some stuff or get them a job.
At the end there are people with “I wrote that book” certificate of excellence try to sell you opinions on everything starting from sexual positions ending on how to take a good dump. The problem is that the moment they wrote that book it becomes obsolete. Teachers of useless knowledge from last century that forgot about google or wikipedia.
All of them are playing your emotions, cause impulses and hormones are what makes you weak and people are looking for your weaknesses to take advantage of you. Get your money or get your attention and maybe even both at the same time. Cause views matter you know it. So like and subscribe dumb fucks.
If you’re lucky you find couple of them who aren’t doing that. Who the fuck knows why but this shit happens. It doesn’t matter if they’re family or you met them month ago. Those are only to keep and hardest to find. Unluckily those also can change by other people they meet or when they’re young.
If you can’t find a friend get a dog or cat or whatever animal you like. Their love is unconditional and obvious to read.
Well that’s most of the “I want to be spotted” culture that is all boring as fuck. Personalized ass and glamorous pictures and short movies of everything you don’t need but looks awesome. And as you see it’s still growing with more specialized portals like onlyfans, twitch and tiktok. We all need to look at what everyone else have or want to have cause 99% of time 99% of us are boring and is bored as fuck. Most of us can repeat same small amount set of stories all their life cause we’re not created to entertain.
I don’t feel joy looking at this shit fucked full of shit people arguing who’s dick is bigger. Who can post most dumb thing. I think I need a break but how to break from everything ? How to break from culture of money where to live on your country land you need to pay property tax ?
That’s all fucked up. Life’s fucked up.12 -
Donate to Wikipedia one time and they haunt you for life. They’ll send you email after email and they are all rather ridiculous. On top of that be prepared to be hounded by phone as well. They are the equivalent of a roadside bum that keeps asking you for more, and each time you give he says, “Is that all you got?”. Frack whoever put this strategy in place, they’ve annoyed me to the point where I’d rather not give again.11
-
So today I forgot what FTFY meant, then clicked on some FAQ in Google Search. Then I noticed a strange thing. If you open one of the FAQs (last one works best) then collapse it, a few more appear.
I guess this can be repeated indefinitely. I wasn't patient enough to see if it loops like mobile text predictions but it did give me ~130 lines without any repetitions.
Seems like a lightweight alternative to obsessive Wikipedia link following xD 1
1 -
Rant:
I am at work, some one says to me this system we are working on is multi threaded. I tell the no its not multi threaded and in this context. Things cannot happen concurrently. Its a single core arm 7tdmi. Arguments ensue abot the difference between multithread multitasking an multiprocessing. I proceed to explain this is a multitasking interrupt driven system. With no context switching or memory segmentation so one heap for all tasks cause thats how we have it configured and there is only one core. So there is no way the error he just described could possibly happen. Then he tells me im wrong but refuses to even look at the processor manual and rejects the Wikipedia entry for multithreading. So I plan on calling off so i can just have the next two weeks off while he trys to figure out why two things ar happening at once on this system. He deserves all the frustration that is to follow.1 -
So I just spent the last few hours trying to get an intro of given Wikipedia articles into my Telegram bot. It turns out that Wikipedia does have an API! But unfortunately it's born as a retard.
First I looked at https://www.mediawiki.org/wiki/API and almost thought that that was a Wikipedia article about API's. I almost skipped right over it on the search results (and it turns out that I should've). Upon opening and reading that, I found a shitload of endpoints that frankly I didn't give a shit about. Come on Wikipedia, just give me the fucking data to read out.
Ctrl-F in that page and I find a tiny little link to https://mediawiki.org/wiki/... which is basically what I needed. There's an example that.. gets the data in XML form. Because JSON is clearly too much to ask for. Are you fucking braindead Wikipedia? If my application was able to parse XML/HTML/whatevers, that would be called a browser. With all due respect but I'm not gonna embed a fucking web browser in a bot. I'll leave that to the Electron "devs" that prefer raping my RAM instead.
OK so after that I found on third-party documentation (always a good sign when that's more useful, isn't it) that it does support JSON. Retardpedia just doesn't use it by default. In fact in the example query that was a parameter that wasn't even in there. Not including something crucial like that surely is a good way to let people know the feature is there. Massive kudos to you Wikipedia.. but not really. But a parameter that was in there - for fucking CORS - that was in there by default and broke the whole goddamn thing unless I REMOVED it. Yeah because CORS is so useful in a goddamn fucking API.
So I finally get to a functioning JSON response, now all that's left is parsing it. Again, I only care about the content on the page. So I curl the endpoint and trim off the bits I don't need with jq... I was left with this monstrosity.
curl "https://en.wikipedia.org/w/api.php/...=*" | jq -r '.query.pages[0].revisions[0].slots.main.content'
Just how far can you nest your JSON Wikipedia? Are you trying to find the limits of jq or something here?!
And THEN.. as an icing on the cake, the result doesn't quite look like JSON, nor does it really look like XML, but it has elements of both. I had no idea what to make of this, especially before I had a chance to look at the exact structured output of that command above (if you just pipe into jq without arguments it's much less readable).
Then a friend of mine mentioned Wikitext. Turns out that Wikipedia's API is not only retarded, even the goddamn output is. What the fuck is Wikitext even? It's the Apple of wikis apparently. Only Wikipedia uses it.
And apparently I'm not the only one who found Wikipedia's API.. irritating to say the least. See e.g. https://utcc.utoronto.ca/~cks/...
Needless to say, my bot will not be getting Wikipedia integration at this point. I've seen enough. How about you make your API not retarded first Wikipedia? And hopefully this rant saves someone else the time required to wade through this clusterfuck.12 -
!rant/!story/!question
So, I've been developing a little Chrome Extention for people who usually searches quite a lot on Wiki and Wiktionary.
I mainly developed it for my own laziness to open a new tab and search for a term.
What it does is, when you select a word and triggers the extension, it will show a little dialog with Wikipedia and Wiktionary definitions for the selection.
If anyone is curious or interested in the idea, would be helpful to receive some feedback.
(sorry for the logo on the image, it's the only one that I have here, at the moment.)
https://chrome.google.com/webstore/... 9
9 -
Was an aspiring 2nd grade student then, still a newbie in databases and stuff.
Managed to work with bossy motherfucker who didn't give a flying fuck about proper management, team culture, job roles and everything and treated people like shit.
The big boss wanted me to develop the ecommerce website that integrates with 1c (complete and utterly garbage buggy ass dbms with RUSSIAN SYNTAX, nuff said) and with its own crm to track every employee and even real time chat. He also wanted it to be a kind of online medical wikipedia. And he wanted me to take a professional photo of each and every fucking item for this website, somewhere around 5 thousand photos.
He offered me around 800 bucks for all that job. No, not monthly. He wanted me to do all that shit alone, for 800 bucks and expected it to be up and running in less than two months.
Gently told him to fuck off. Quit that job the same day.2 -
There is a place in Saint-Petersburg, Russia. A very, very weird place. Its name roughly translates to “The Board of Wards of the Russian Ministry of Defense”.
It’s an ultra-modern, beautiful facility situated near two most important (and evil) buildings of the Putin’s epoch — Gazprom Arena (a.k.a. Death Star, left bottom on the map), and Lakhta Center (a.k.a. The Oil Bottle, the tallest skyscraper in Saint-Petersburg), completing the trifecta of evil architecture. Its official governmental website is vague. Its objectives are unclear. You can’t enter it — it’s surrounded by water.
Their official mission is, and I quote: “Gender-based approach in education and gender role socializing of young women.”
It houses roughly 800 girls. It has no English Wikipedia page. Its Russian page says there is nothing quite like it anywhere in the world. It only accepts young girls as its students. Allowed visits from parents are rare. Girls aren’t seen much during “the training”.
They tell this place changes people. Mobile phones are strictly forbidden. They train, eat and sleep on site. They’re not allowed to leave.
Its reviews written on Yandex Maps (the go-to app for maps in Russia) are, again, vague and oddly positive. Mothers tell this facility is the best place to be for a young girl — they teach them “right”. The only extensive negative review tells of a girl that was able to get out because of “medical reasons”, and tells about how the on-site doctor wasn’t really allowed to do such a thing.
The facility is very secretive. Photos of girls published by them are eerie and highly curated. No one truly knows what happens there.
They are wrong, however. There _were_ places quite like it — they were called “Reich Bride Schools”, and they operated in Nazi Germany (https://en.wikipedia.org/wiki/...).
Welcome to the Putin’s harem. 5
5 -
What kind of sick joke is it that the url for camelCase on wikipedia is www.wikipedia.org/wiki/Camel_case2
-
I was talking to my non-tech gf about how a colleague of mine didn't understand priority queue and show led her an example, during explanation fucked up the example and duplicated priorities of 2 values but they came up in the unexpected order. She wanted to find the logic in it and blamed the computer for being dumb, but it has been ~45 minutes, she has Wikipedia about binary trees & linked list open as well as simple graphs visualising both + armed with pen and paper trying to understand how it all all works..
Achievement Earned?
P.S I am either creating a monstrosity (Frankenstein style) or recruiting a fresh mind to our ranks, either way I am proud af 😢😊😍8 -
My First !Experience : Disappointment with a computer
My mum kept tons of floppies but we didnt have a computer at home. Went to my friends house, who had one, and had Encarta 95 (its like a fun wikipedia for kids). When I mentioned I had floppies, he asked for one, since he didnt have one. We copied Encarta to that floppy hoping we would cheat in the next computer science test. We even tested it.
After we were certain that all works (you should know we were surprised that it could fit in one floppy), we got to school, put the disk in and voila
we had copied a shortcut :)4 -
Just finished an assignment yesterday where we had to code a math problem in assembler in under 20 lines
looking at the task: Hey, we already did this in Python
*building own modulo Operation for that cause we cant use it*
*freaking out when realizing it's just not posibble in 20 lines*
Then scrolling up the wikipedia page to see you've spend hours trying to implement the wrong thing3 -
So the group announced a merge of several systems into my platform. Growing it from 5000 sites to 75000. Lead time of a year, time enough to build it properly, finish the split of the current monolith into microservices, make it fast.
Suddenly, they reduced the time to three months, no explanation given. Solution is to keep the current PHP shit pile, but "scale" it using magic hardware or something. Oh and add 258 features, including things like "intuitive navigation" and "progressive web app" which some junior PM wannabe got off wikipedia or something.
And my boss has bent over to these morons and basically said yes, instead of informing them that this is a fool's errand.
Fuck em. I've said that they're nuts, and if they force the issue, I will resign. And my team probably will too.
But first I will take an inconveniently timed holiday.2 -
First wikipedia asks me donation. Then tells me facts 98% Indians do not donate. And when I try to donate, it doesn't let me donate without PAN. I am a student.6
-
Basically everything. Let me explain.
It's now.. okay what time is it? Ooh there's some dust on the clock, I wonder how do they form.. I guess I'll check Wikipedia. Page is loading, might as well scroll fb while waiting. Ooh a video on the home feed! Oh wait it's loading, I wonder what's on YouTube. Ugh, ads, let's just mute it and scroll devRant. Oh cool there's something called Google FooBar challenge, imma try searching Arraylist Java. Nice, lv1 done, let's take a break by getting a drink from the fridge.
*Walks back to room after drinking a sip of orange juice* hmm.. what time is it? Oh it's late, imma go to sleep!
*Shuts down everything and goes to bed* Maybe I'll just browse devRant before sleeping.. Ooh I have an idea for wk51!1 -
The Turbografx 16 (or Turbografx PC-Engine in Japan) has the most amazing fucking expansion port I've ever seen. Every bus is exposed, plus sound out and IN (unused by anything ever made for the thing), composite out (not included on the console itself, but 3rd-party addons allowed it), VGA out (!!!) and CPU HALTING/CLOCK CONTROL were included over this fucking thing.
You can even power the system with 5v in through the expansion port and bypass the power switch with it.
Info and diagram:
https://gamesx.com/misctech/...
Example:
To get composite out, send pin A22 out and ground the ground wire of the composite to any ground.
For VGA, it's a little more complex:
VGA1 to TG-A23, VGA2 to TG-B23, VGA3 to TG-C23, VGA9 to TG-A2, VGA13 (and VGA10 if you want compatibility with older displays) to TG-B11, VGA14 to TG-A10, VGA5-8 (and 10 if not hooked to TG-B11) to TG-C2
(VGA numbering from Wikipedia diagram)
this thing's fucking cool1 -
Udemy is full of crap.
I got some course that had been "discounted" from $200 (I already mentioned it is an ugly trick) and it was over in like 20 minutes. The fuck?!
All the info they gave was either common sense or something you could find on the first paragraph of the Wikipedia article on the given topic (it was a soft skills course, not a technical one).
Just junk.
Maybe there are some gems out there, but I'm not sure I would risk it again.
Udemy feels like the Booking.com of courses in terms of deceitful UX, but it's not nearly as useful.
Maybe you guys have found something good there that you could say is a bargain? If so, please let me know.10 -
QA personal voice assistant that runs locally without cloud, it’s like never ending project. I look at it from time to time and time pass by. Chat bots arrived, some decent voice algorithms appeared. There is less and less stuff to code since people progress in that area a lot.
I want to save notes using voice, search trough them, hear them, find some stuff in public data sources like wikipedia and also hear that stuff without using hands, read news articles and stuff like that.
I want to spend, more time for math and core algorithms related to machine learning and deep learning.
Problem is once I remember how basic network layers, error correction algorithms work or how particular deep learning algorithm is constructed and why is that, it’s already a week passed and I don’t remember where I started.
I did it couple of times already and every time I remember more then before but understanding core requires me sitting down with pen and paper and math problems and I don’t have time for that.
Now when I’m thinking about it - maybe I should write it somewhere in organized way. Get back to blogging and write articles about what I learned. This would require two times the time but maybe it would help to not forget.
I’m mostly interested in nlp, tts, stt. Wavenet, tacotron, bert, roberta, sentiment analysis, graphs and qa stuff. And now crystallography cause crystals are just organized graphs in 3d.
Well maybe if I’m lucky I retire in the next decade or at least take a year or two years off to have plenty of time to finish this project. -
CS Teacher today:
"Transport Layer provides Security and Encryption to the communication" (TCP/IP stack)
me: WTF? Encryption is provided on the *top* of the transport layer (aka Application) ( and below [Network Layer] there is IPsec)
Teacher: no, it's wrong.
me: so Wikipedia it's wrong, RFC 5246 is wrong, and you have right?
Teacher: Yes.
me: Ok. (aka fuck you!)2 -
Here is my idea for a time machine which can only send one bit of information back in time.
@Wisecrack has asked me about it and I didn’t want to write it in comments because of the character limit.
So here we go.
The DCQE (delayed-choice quantum eraser) is an experiment that has been successfully performed by many people in small scale.
You can read about it on wikipedia but I'll try to explain it here.
https://en.wikipedia.org/wiki/...
First I need to quickly explain the double slit experiment because DCQE is based on that.
The double slit experiment shows that a particle, like a photon, seems to go through both slits at the same time and interfere with itself as a wave to finally contribute to an interference pattern when hit on a screen. Many photons will result in a visible interference pattern.
However, if we install a detector somewhere between the particle emitter an the screen, so that we know which path the particle must have taken (which slit it has passed through), then there will be no interference pattern on the screen because the particle will not behave as a wave.
For the time machine, we will interpret the interference pattern as bit 1 and no interference pattern as bit 0.
Now the DCQE:
This device lets us choose if we know the path of the particle or if we want wo erase this knowledge. And we can make this decision after the particle hit the screen (that is the "delayed" part), with the help of quantum entanglement.
How does it work?
Each particle send out by the emitter will pass through a crystal which will split it into an entangled pair of particles. This pair shares the same quantum state in space and time. If we know the path of one of the particle "halves", we also know the path of the other one. Remember the knowledge about the path determines if we will see the interference pattern. Now one of the particle "halves" goes directly into the screen by a short path. The other one takes a longer path.
The longer path has a switch that we can operate (this is the "choice" part). The switch changes the path that the particle takes so that it either goes through a detector or it doesn't, determining if it will contribute to the intererence pattern on the screen or not. And this choice will be done for the short path particle-half because their are entangeld.
The path of the first half particle is short, so it will hit the screen earlier.
After that happened, we still have time to make the choice for the second half, since its path is longer. But making the choice also affects the first half, which has already hit the screen. So we can retroactively change what we will see (or have seen) on the screen.
Remember this has already been tested and verified. It works.
The time machine:
We need enough photons to distinguish the patterns on the screen for one single bit of information.
And the insanely difficult part is to make the path for the second half long enough to have something practical.
Also, those photons need to stay coherent during their journey on that path and are not allowed to interact with each other.
We could use two mirrors, to let the photons bounce between them to extend the path (or the travel duration), but those need to be insanely pricise for reasonable amounts of time.
Just as an example, for 1 second of time travel, we would need a path length about the distance of the moon to the earth. And 1 second isn't very practical. To win the lottery we would need at least many hours.
Also, we would need to build the whole thing multiple times, one for each bit of information.
How to operate the time machine:
Turn on the particle emitter and look at the screen. If you see an interference pattern, write down a 1, otherwise a 0.
This is the information that your future you has sent you.
Repeat this process with the other time machines for more bits of information.
Then wait the time which corresponds to the path length (maybe send in your lottery numbers) and then (this part is very important) make sure to flip the switch corresponsing to the bit that you wrote down, so that your past you receives that info in the past.
I hope that helps :)9 -
TL;DR: Stop. Hating. On. Ads. Here are 5 reasons why:
1. "No one likes ads"
I love seeing *good* ads before I watch a YouTube video. Or I looked up videos that YT recommended because they sounded fun and they were fun:
- Coke - Hey Brother is an amazing and touching short film
- Fressnapf (="food bowl") had an incredibly enjoyable "things you didn't know about cats" video I clicked on purpose and it was good.
- I found JetBrains through ads (free for me, student perks. But tbh I use atom)
and I could name more.
2. What are the alternatives?
I know there are some non-profits and that's cool but you wanna be paid in your job, right? So ads are why Facebook (I know, Facebook isn't enjoyed here but), YouTube, stackoverflow, etc. Wikipedia asks for a few million dollars of donations each year because they don't run ads. Smaller businesses can't do that really. Hell, even codepen has a "sponsored" section. Imagine you would have to pay for all of those services.
3. "Manipulation"
isn't a bad thing unless you abuse it. I manipulate you when I say that I love codepen in the same way an ad does. No one forces you to use a product or watch an ad (you can look away and often times skip).
4. Adblock
What if everyone did that? Adblock blocks happened a while ago and the war between adblock and ad-senders is still ongoing. The moment you see an ad, you are using/watching etc something which the creators thought is worth making money off. If you don't think so, leave the site. I am an adblock user but if the site politely asks me to disable it and I enjoy the content - I will disable it with pleasure.
5. Targeted ads
Yes. The internet is a huge data-crawling piece of shit. But there are many more questionable or even dangerous ways of data-harvesting online. I am glad to see ads I like and not the ones my sister might like. Some services allow you to disable personalized ads. Or use vpn if you really want to.8 -
TIL Wikipedia was funded by revenue from a porn site.
https://en.m.wikipedia.org/wiki/...
Porn is everywhere!
It's so obvious porn is the one thing that can bring popularity to VR and AR technology.
pic: Wikipedia founder with some porn stars 7
7 -
searching 'linux operating system' on Google shows Linux's Wikipedia page as 'operating systems are Linux'
 2
2 -
So my father asked me what I think about filemaker. I researched, while we were waiting for the food (restaurant) bs holy fuck, I've never gotten this bad vibes from a from something I believe to be a scripting language.
> proprietary (Apple)
> only articles I found about it were related to LinkedIn or at least written like they were
> not a single text based tutorial on the first pages of the search result, only videos (didn't watch them, because my mobile data is too scared for that)
> I can't find anything remotely explaining what this shit is about.
wikipedia was the most best resource I could find
> Free ebook about "how to train your junior developer" for filemaker requires me to enter way too much personal information.2 -
tldr: I am a human with dreams and doubt.
At the Univeristy you end your course of study with a thesis, and there are two kind of thesis: compilative and progettual.
Compilative means that you study something and then make a report about it. Usually I see that this kind of thesis is done by people who just want to end the course.
Progettual means that you actually develop something, maybe driven by a professor, doing something new, or try something in a different way to see if it works... This is for the good guys.
but mine does not fit any of those.
I studyed a lot about some topics, I learned to use the existing tools, I learned to decide which tool is better and when. I learned the open problems in the field. And my thesis is an analysis for a solution for some of them. I did not develop a project, but I didn't just study something. And I am giving the base for a much bigger project.
And I did everything on my own, the prof who is supposed to drive my work let me go on, and I never really asked for his help.
Obviously everything is a mess, the thesis describes broadly a large range of things, who are outside my course, and I am just copying from here and there (avoiding wikipedia because I would be ashamed of that) (I mean, I avoid wikipedia and jump directly to the source).
I actually made a little project from the conclusion of my analysis, but it is more of a mistake than other.
And maybe I am writing this to grow my pride, and avoid depression. To tell me I am not a total failure. Or maybe am I really good as I dream to be? (because that is how pride works, doesn't it?)
I intented a new kind of thesis! Ah!
I will see the prof on wednesday and the deadline is on saturday! I will let you know!
and oh!I am writing it in english so you can read it!
Just kidding, I don't give a fuck about anything anymore, I just want to end this mess, and in english is easier to copy.
I learned from this big mistake of a thesis, next time I will make sure that the prof drives me, because I am 20 and cannot do an analysis such complex on my own.
becauuuuseeee yes! There will be a next time! I am graduating in december, but I am following the master courses since september! In january the first exams! I am practically already thinking about the next thesis. Suggestion on other mistake to avoid?
Did you know James Joyce and the stream of consciuosness? Well, here it is.
I may have spelled something wrong, I hope everything is undestandable.
wow, 2500 characters of rant, I am improving writing the thesis in english!
mngr, out.1 -
I got notified that tomorrow I'm gonna start a porting project from a FileNet ecosystem.
Well, I don't know what is FileNet, but at least I've enough time to study its architecture. Let's start from the official IBM page:
The FileNet® P8 platform offers enterprise-level scalability and flexibility to handle the most demanding content challenges, the most complex business processes, and integration to all your existing systems. FileNet P8 is a reliable, scalable, and highly available enterprise platform that enables you to capture, store, manage, secure, and process information to increase operational efficiency and lower total cost of ownership.
Thank you IBM, now I surely know how to use FileNet. Well, I hope that wikipedia explains me what it is:
FileNet is a company acquired by IBM, developed software to help enterprises manage their content and business processes.
Oh my god. I tried searching half an hour so far and everything I found was just advertisements and not a clue about what it is.
Then they wonder why I hate IBM so much4 -
i cant stand these idiots anymore. My instructor needed 12 Minutes to understand Megabyte and Mebibyte. He just used the snipping tool to save an SVG from Wikipedia. My instructor is an Person who wrote small Programs in the past and thought that an instructor license is something useful. It hurts listening to him. he was kept busy for hours because of nothing, so we could only twiddle our thumbs. our first instructor went probably because of the Management.
At the beginning of June I will give my lecture for my final exam.
I am fucked.3 -
Just got access to OpenAI beta. This thing is seriously impressive. The attached image shows it summarizing a paragraph from Friedrich Nietzsche. Apart from that, I have tried summarizing a complex Math Algo which I found on Wikipedia, getting specs for building a new PC, and also improving my Startup Idea. The results were astonishing. I can't imagine what possibilities it can have in the future.
At the same time, I can clearly see why they are not allowing open access to their APIs. The potential for abuse is so high here. Especially when most of our population is full of digital idiots.
-
1. Change Windows to be one of Linux Distros. Merging the two worlds into one.
2. Every open source contributer gets magically paid based on their contribution. Your welcome Wikipedia.
3. Genie Dev, I set you free.6 -
Space age science themed city in Russia. Some of the street names here, top to bottom:
- Constellation avenue
- Andromeda avenue
- Phobos avenue
- Copernicus street
- Laser avenue
- The Milky Way street
- Weightlessness street
- Helios avenue
- Bessel street
- Orion street
- Kepler street
- Curie street
- Galileo Galilei street
- Axis street
- Asteroid street
This place’s Wiki page (translated): https://ru-m-wikipedia-org.translate.goog/... 3
3 -
Imagine a web way ahead of our time where its size goes beyond our imagination...
This is my first rant, and I'll cut to the chase! I don't like how web currently stands. Here's what makes me angry the most altough I know there's a myriad of solutions or workarounds:
- A gazillion credentials/accounts/services in your lifetime.
- Everyone tries to reinvent the wheel.
- There's no single source of truth.
- Why the fuck there's so much design in a vision that started as a network of documents? Why is it that we need to spend time and energy to absorb the page design before we can read what we are after?
- What's up with the JS front end frameworks?! MB's of code I need to download on every page I visit and the worse is the evaluation/parsing of it. Talk about acessibility and the energy bills. I don't freaking need a SPA just give a 20-50ms page load and I'm good to go!
- I understand that there's a whole market based on it but do we really need all that developer tools and services?
- Where's our privacy by the way? Why the fuck do I need ads? Can't I have a clue about what I wan't to buy?
Sticking with this points for now... Got plenty more to discuss though.
What I would like to see:
A unique account where i can subscribe services/forums/whatever. No credentials. Credentials should be on your hardware or OS. Desktop Browser and mobile versions sync everything seemlesly. Something like OpenID.
Each person has his account and a profile associated where I share only what I want with whom I want when I want to.
Sharing stuff individually with someone is easy and secure.
There's no more email system like we know. Email should be just email like it started to be. Why the hell are we allowing companies to send us so much freaking "look at me now, we are awesome", "hey hey buy from me".. Here's an idea, only humans should send emails. Any new email address that sends you an email automatically requests your "permission" to communicate with you. Like a friend request.
Oh by the way did I tell you that static mail is too old for us? What we need is dynamic email. Editing documents on the fly, together, realtime, on the freaking email. Better than mail, slack and google docs combined.
In order for that to work reasonably well, the individual "letter" communication would have to be revamped in a new modern approach.
What about the single source of truth I talked about? Well heres what we should do. Wikipedia (community) and Larry Page (concept) gave us tremendous help. We just need to do better now.
Take the spirit of wikipedia and the discoverability that a good search engine provides us and amp that to a bigger scale. A global encyclopedia about everything known to mankind. Content could be curated from us all just like a true a network.
In this new web, new browser or whatever needed to make this happen I could save whatever I want, notes, files, pictures... and have it as I left it from device to device.
Oh please make web simple again, not easy just simple and bigger.
I'm not old by the way and I don't see a problem with being older btw.
Those are just my stupid rants and ideas. They are worth nothing. What I know for sure is that I'll do something about or fail trying to.12 -
I need to stop treating an OO language as if it were a procedural language.
I have the tendency to turn my code into GOTO spaghetti even though I'm semi-aware that objects exist and that they are distinct.
I still have to get used to this paradigm.
My Java professor always swore by the Plato paradigm, i.e.:
""Platonism" and its theory of Forms (or theory of Ideas) denies the reality of the material world, considering it only an image or copy of the real world.
According to this theory of Forms there are at least two worlds: the apparent world of concrete objects, grasped by the senses, which constantly changes, and an unchanging and unseen world of Forms or abstract objects, grasped by pure reason (λογική). which ground what is apparent." (wikipedia)
Thinking in objects, abstractions and metaphysics is not something I haven't done before (I've practiced it during Sociology and Ethics with the whole Pascal Leibniz, Newton and DesCartes approach) but it's certainly not easy.
Then there was my cool Programming 201 professor who said: "Don't worry man, just read those great UML, Program Design and GOF books and it will all become easy, like a story. It'll all make sense.
I mean, I've graduated, I've passed my Software Engineering I, II and III (hard as hell) but since I haven't focused on those theories and practices anymore, I've lost my touch.
It's definitely not easy for a novice programmer to transition between paradigms..10 -
another true story time:
be me
read about banned pokemon episodes on wikipedia
electric soldier porygon: an episode that red blue flashes caused 685 viewers taken to hospitals by ambulances
😈lets try it
write a simple program that makes same light effects
try it on myself
no kill
try it on roommates
no kill
try to send it as many people i can reach
omg people why don't you die?
gave up after 1 week of unsuccessful attempts3 -
Something which is becoming a big pet bug peeve of mine... Chat bots being classed as AI...
Seriously?? Gives a response of context 2 or 3 levels deep?
Saw a news bulletin of a guy being questioned on the guidelines of putting AI in an app which builds quiz questions from Wikipedia - look out world, the robots know a lot of history!
The Google engineers building proper AI would be wetting themselves... -
You know that moment, when you look for something on wikipedia, and after few hiperlinks you are reading about influence of penguins on Mars' day length or othen nonsense?
Just happened to me like 4th time when reading Django documentation. It is so well written and easy to understand, that I just click and click and want to go deeper, and then realise I have to read what I need, because I never ever got to it in the first place.
Gotta love the people who make such docs. I never could, and prbly will.1 -
The German Wikipedia article about brute force defines it as "decryption method" 🤔🤔😂
https://de.m.wikipedia.org/wiki/... 2
2 -
My friend sent me this as WYSIWYG
/* A simple quine (self-printing program), in standard C. */ /* Note: in designing this quine, we have tried to make the code clear * and readable, not concise and obscure as many quines are, so that * the general principle can be made clear at the expense of length. * In a nutshell: use the same data structure (called "progdata" * below) to output the program code (which it represents) and its own * textual representation. */ #include <stdio.h> void quote(const char *s) /* This function takes a character string s and prints the * textual representation of s as it might appear formatted * in C code. */ { int i; printf(" \""); for (i=0; s[i]; ++i) { /* Certain characters are quoted. */ if (s[i] == '\\') printf("\\\\"); else if (s[i] == '"') printf("\\\""); else if (s[i] == '\n') printf("\\n"); /* Others are just printed as such. */ else printf("%c", s[i]); /* Also insert occasional line breaks. */ if (i % 48 == 47) printf("\"\n \""); } printf("\""); } /* What follows is a string representation of the program code, * from beginning to end (formatted as per the quote() function * above), except that the string _itself_ is coded as two * consecutive '@' characters. */ const char progdata[] = "/* A simple quine (self-printing program), in st" "andard C. */\n\n/* Note: in designing this quine, " "we have tried to make the code clear\n * and read" "able, not concise and obscure as many quines are" ", so that\n * the general principle can be made c" "lear at the expense of length.\n * In a nutshell:" " use the same data structure (called \"progdata\"\n" " * below) to output the program code (which it r" "epresents) and its own\n * textual representation" ". */\n\n#include <stdio.h>\n\nvoid quote(const char " "*s)\n /* This function takes a character stri" "ng s and prints the\n * textual representati" "on of s as it might appear formatted\n * in " "C code. */\n{\n int i;\n\n printf(\" \\\"\");\n " " for (i=0; s[i]; ++i) {\n /* Certain cha" "racters are quoted. */\n if (s[i] == '\\\\')" "\n printf(\"\\\\\\\\\");\n else if (s[" "i] == '\"')\n printf(\"\\\\\\\"\");\n e" "lse if (s[i] == '\\n')\n printf(\"\\\\n\");" "\n /* Others are just printed as such. */\n" " else\n printf(\"%c\", s[i]);\n " " /* Also insert occasional line breaks. */\n " " if (i % 48 == 47)\n printf(\"\\\"\\" "n \\\"\");\n }\n printf(\"\\\"\");\n}\n\n/* What fo" "llows is a string representation of the program " "code,\n * from beginning to end (formatted as per" " the quote() function\n * above), except that the" " string _itself_ is coded as two\n * consecutive " "'@' characters. */\nconst char progdata[] =\n@@;\n\n" "int main(void)\n /* The program itself... */\n" "{\n int i;\n\n /* Print the program code, cha" "racter by character. */\n for (i=0; progdata[i" "]; ++i) {\n if (progdata[i] == '@' && prog" "data[i+1] == '@')\n /* We encounter tw" "o '@' signs, so we must print the quoted\n " " * form of the program code. */\n {\n " " quote(progdata); /* Quote all. */\n" " i++; /* Skip second '" "@'. */\n } else\n printf(\"%c\", p" "rogdata[i]); /* Print character. */\n }\n r" "eturn 0;\n}\n"; int main(void) /* The program itself... */ { int i; /* Print the program code, character by character. */ for (i=0; progdata[i]; ++i) { if (progdata[i] == '@' && progdata[i+1] == '@') /* We encounter two '@' signs, so we must print the quoted * form of the program code. */ { quote(progdata); /* Quote all. */ i++; /* Skip second '@'. */ } else printf("%c", progdata[i]); /* Print character. */ } return 0; }6 -
Where do you go to figure out new jargon/terms?
I found
The Jargon File
Beej's Guide to Network Programming
Hackterms.com
Sidewaysdictionary.com
But they seem to have low traffic
Is Wikipedia the king?4 -
OK it's three AM in the morning and I've gone from the Wikipedia page for dead man's switch to the Wikipedia page for the Sistine chapel roof.2
-
I'm a proud man, but I'm not such a fan of my own farts that I can't admit when I maybe should have listened to other people's advice earlier.
After having been convinced of the scope of impact of AI by someone I respect, I started playing with the Jetbrains AI tools. I am impressed at its ability to process my code and give actually helpful input and to consolidate documentation into a form that is concise and helpful.
I finally get what people mean when they say it saves time.
A couple things that truly warmed me up to it is, one:
I wanted to know if I could return a string, float array, whatever, from c++ to a python script. I was assured the answer was yes, but I just COULD NOT get it to work, so I gave up on it. I asked the question to the Jetbrains AI (4o in this case) and it gave me what I needed, and now I can return a string from c++ to python no problem. There are a lot of little questions like this that I gave up on that I now have to explore again, which is both exciting and annoying, because I already have a thousand hobbies.
And two:
I am working on an html email. It's a mess of tables and text and inline styles. Compared to the markup I'm used to writing, it's tedious to trudge through to make even simple changes. I was able to successfully instruct it to make a specific copy change, while respecting the document's indenting, all on the first try.
I will forever maintain that it will enable a generation of drones that don't understand how to do simple things and will atrophy the skills of otherwise capable people that use it as a crutch.
I will also always maintain that its foundation is built on mass theft and is a monument to the uneven application of intellectual property protection laws. But with DeepSeek coming out and having done the same thing to them, I find myself enjoying the turnabout. I'm also amused that I coincidentally jumped into the pool right as things got interesting.
All that said, as a reference tool, like Google and Wikipedia used to be, it's not the force of pure evil I held it as. It is actually very useful and if used responsibly on an individual level, can be an amazing productivity tool and can even teach its users new things. -
Found this gem a while ago that made my day
if ( $this->isExternal() ) {
// This probably shouldn't even happen. ohh man, oh yuck.
// But for interwiki transclusion it sometimes does.
// Shit. Shit shit shit.
//
// Use the canonical namespaces if possible to try to
// resolve a foreign namespace.
if ( MWNamespace::exists( $this->mNamespace ) ) {
return MWNamespace::getCanonicalName( $this->mNamespace );
}
In a not too old version for mediawiki, the codebase for Wikipedia.
https://phabricator.wikimedia.org/s... -
Well... I was in a room, my computer was in a room. I was bored, so I just browsed around wikipedia. Then, baaam, suddenly i was at the page for programming. I read about and i was in love. It was love at first sight.
-
Margaret Hamilton.
She was the director of the Software Engineering Division which developed the onboard flight software for NASA's Apollo space program.
(Here Wikipedia)
https://en.wikipedia.org/wiki/... -
I have battled with really crappy car diagnosis, testing and installation software and hardware in few years back to this day. So it's finally time for me to try and make my own library and applications for OBD II.
A COPY of ONE part of the specification (ISO-9141-2) costs around 90€. WHAT! Oh my word... I guess I'll be using info found from Wikipedia instead 😒9 -
Me, reading random wikipedia:
A boutonnière (French: [bu.tɔ.njɛʁ]) or butthole (British English) is a floral decoration, typically a single flower or bud, worn on the lapel of a tuxedo or suit jacket.
Wait, that can't be right
butthole.
buttonhole.
OOOOOH -
I recently came to the realization that my knowledge of APIs is very basic. The idea I have right now is based on the "waiter" analogy. I want to dive deeper into the topic. Does anyone know any sites with decent information on them, other than Wikipedia?1
-
Now, I didn't even really know Employee Appreciation Day was a thing until an article appeared on the company intranet about it coming up.
From Wikipedia:
"It is a day for companies to thank their employees for their hard work and effort throughout the year. This day was created for the purpose of strengthening the bond between employer and employee."
I thought, "Oh, cool. I wonder what they're doing for it."
You know what they did?
They encouraged us to use the internal eCard system to send each other notes of appreciation. "Let's break a record," they said. "Most eCards sent in one day!"
And that's it. That's how my employer showed their appreciation for me.
I feel so... appreciated?
¯\_(ツ)_/¯
P.S. Yes, we broke the record.
P.P.S. No, I didn't get any eCards.2 -
Data wrangling is messy
I'm doing the vegetation maps for the game today, maybe rivers if it all goes smoothly.
I could probably do it by hand, but theres something like 60-70 ecoregions to chart,
each with their own species, both fauna and flora. And each has an elevation range its
found at in real life, so I want to use the heightmap to dictate that. Who has time for that? It's a lot of manual work.
And the night prior I'm thinking "oh this will be easy."
yeah, no.
(Also why does Devrant have to mangle my line breaks? -_-)
Laid out the requirements, how I could go about it, and the more I look the more involved
it gets.
So what I think I'll do is automate it. I already automated some of the map extraction, so
I don't see why I shouldn't just go the distance.
Also it means, later on, when I have access to better, higher resolution geographic data, updating it will be a smoother process. And even though I'm only interested in flora at the moment, theres no reason I can't reuse the same system to extract fauna information.
Of course in-game design there are some things you'll want to fudge. When the players are exploring outside the rockies in a mountainous area, maybe I still want to spawn the occasional mountain lion as a mid-tier enemy, even though our survivor might be outside the cats natural habitat. This could even be the prelude to a task you have to do, go take care of a dangerous
creature outside its normal hunting range. And who knows why it is there? Wild fire? Hunted by something *more* dangerous? Poaching? Maybe a nuke plant exploded and drove all the wildlife from an adjoining region?
who knows.
Having the extraction mostly automated goes a long way to updating those lists down the road.
But for now, flora.
For deciding plants and other features of the terrain what I can do is:
* rewrite pixeltile to take file names as input,
* along with a series of colors as a key (which are put into a SET to check each pixel against)
* input each region, one at a time, as the key, and the heightmap as the source image
* output only the region in the heightmap that corresponds to the ecoregion in the key.
* write a function to extract the palette from the outputted heightmap. (is this really needed?)
* arrange colors on the bottom or side of the image by hand, along with (in text) the elevation in feet for reference.
For automating this entire process I can go one step further:
* Do this entire process with the key colors I already snagged by hand, outputting region IDs as the file names.
* setup selenium
* selenium opens a link related to each elevation-map of a specific biome, and saves the text links
(so I dont have to hand-open them)
* I'll save the species and text by hand (assuming elevation data isn't listed)
* once I have a list of species and other details, to save them to csv, or json, or another format
* I save the list of species as csv or json or another format.
* then selenium opens this list, opens wikipedia for each, one at a time, and searches the text for elevation
* selenium saves out the species name (or an "unknown") for the species, and elevation, to a text file, along with the biome ID, and maybe the elevation code (from the heightmap) as a number or a color (probably a number, simplifies changing the heightmap later on)
Having done all this, I can start to assign species types, specific world tiles. The outputs for each region act as reference.
The only problem with the existing biome map (you can see it below, its ugly) is that it has a lot of "inbetween" colors. Theres a few things I can do here. I can treat those as a "mixing" between regions, dictating the chance of one biome's plants or the other's spawning. This seems a little complicated and dependent on a scraped together standard rather than actual data. So I'm thinking instead what I'll do is I'll implement biome transitions in code, which makes more sense, and decouples it from relying on the underlaying data. also prevents species and terrain from generating in say, towns on the borders of region, where certain plants or terrain features would be unnatural. Part of what makes an ecoregion unique is that geography has lead to relative isolation and evolutionary development of each region (usually thanks to mountains, rivers, and large impassible expanses like deserts).
Maybe I'll stuff it all into a giant bson file or maybe sqlite. Don't know yet.
As an entry level programmer I may not know what I'm doing, and I may be supposed to be looking for a job, but that won't stop me from procrastinating.
Data wrangling is fun. 1
1 -
So, what's your IT trivia?
One of my favourites is sosumi.
When Apple Computers started up they were sent a "cease and desist" notice by Apple Music (The Beatles).
They reached a settlement that Apple Computers would never publish music and Apple Music would never sell computers.
So when the Mac came out and played a tune on startup, the filename was sosumi.
Wikipedia now appears to dispute this, saying that sosumi wasn't the startup sound, but some other sound - any Mac experts care to comment?1 -
I’m broke you assholes thanks to what people did to the system !
Click maybe later on Wikipedia to see the most obnoxious web design snippet to date ! 12
12 -
$this->newTab->devRant->postRant();
When you use CMD+Space on your Mac to open an application, and it looks it up on Wikipedia instead.
Literally just did this. I went to open Synergy(While typing a different post on dev rant) and instead it opened the wiki link for "Synergy" 2
2 -
I'm studying atm and I survived Haskell, SKI, ... now, in the second semester we started with Python (yeay ♡) and Java (that's fine).
One of the first exercises is about installing Jython ('cause it's good, right? /sarcasm off), using the lecturer's module and write some code for it. It's about painting some shitty graphics *gasp*...
I use PyCharm (not really necessary for these crappy exercises) and programming on Windows and/or Linux.
Downloaded Jython, installed it, set it as interpreter - works fine (win10, pycharm).
Some students got weird errors using linux - for me it's the same but meh Idc.
Today I tried using Jython on my notebook, too (win10, pycharm). Downloaded it from the Jython Project website. Can't update pip, can't run modules - error is about fckin charsets...
Some other student figured out - wrong version of Jython. The newer version has some bug fixes.
2.7.1 is the one and only - the download section of their website offers 2.7.0 as latest release...
So - how to know there is a version 2.7.1?
#1 version control website = Wikipedia
So... there is a blog, guy's writing about this release - this installer is hosted at maven central. Yeay. Obvious. Thanks.
Can't describe such stupidity - maybe it's the user again 😂 -
I wrote a simple Python script to split a Wikipedia page into manageable chunks. But it took a while to load, so I decided to add a loading indicator. Just a few dots appearing and disappearing. How hard could it be?
"Okay, so I just need a few dots as a loading thing."
"Right, so I suppose I'll need a separate thread for this... Better look up Python's threading again"
"So the thread is working, but it keeps printing it out on separate lines"
"Right, that should fix it ... nope."
"I should probably fix the horrible mess here"
"Hmm... maybe if I replace the weird print() calls with all those extra parameters with sys.stdout.write()..."
"Right, that kind of works, but now there's just a permanent row of dots"
"Okay, that's fixed... Ish."
Well, it works now, but there's a weird mess of two \r's and a somewhat odd loop. Oh, and there's more code for the loading indicator than for the actual functionality. This is CLI by the way.7 -
I just recently realised that an old favourite has a deeper meaning and made this to serve as an extra warning!
"A renegade is a person who abandons and betrays an organization, country, or set of principles." —Wikipedia 3
3 -
Did anyone here ever play with Wikipedia API? I'm trying to get data about some cities, but I don't know how to pick the city if there are different meanings for the same name (city, river, etc).1
-
Craziest prep for interview :
Step 1 : Given sufficient time for the scheduled interview by any company, start by searching "How to prepare for Google interviews". Awe at the information before you and get all pumped up to jump in.
Step 2 : Starting with Algorithms, study each one and try not to mix any of them in confusion. In case you are stuck in whiteboard coding, close your eyes, take deep breath and visualize Don Kunth. If that doesn't help, well you are ruined anyway.
Step 3: Practice coding without internet connection, till you are able to write code while you talk about how the weather is really great today. Libraries and methods should flow like poetry. SO is sin.
Step 4: The X programming language which you added to your resume because you can write Hello World, head over to Wikipedia and read more about it just in case.
Step 5: Read some xkcd comics so you can impress the interviewer with some humor. You can try Dilbert too. -
Microsoft bought GitHub.
2 Ways it will go:
0. They will welcome it
They will make it bigger
And then kill it
1. They will welcome it
They will keep it running
It will be as good as before2 -
Yeah, I'll probably have a google, Facebook or wikipedia account instead of a Gmail one. What's wrong with you Samsung?

-
Lets help Google out here. Even wikipedia did them no justice and that isn't fair. (https://en.wikipedia.org/wiki/...)
I will propose Quince Jam. 2
2 -
while researching age of consent by country to respond to a comment under another rant, I decided that going to wikipedia and sorting countries by age of consent ascending is probably the quickest way to get on a list.
-
Little poll:
I am building a cooperative website for something that I care. I don't want anything to be more expensive than free, but I still have to pay for the servers. I don't intend to make gains with it.
What is better: a single add on the front page, not intrusive, or a Wikipedia-like campain every year to get the money to pay the servers?
I am opposed to any kind of publicity in my case: for me, internet was created and has to be keept with the spirit of sharing. I give money to wikipedia when I can, I support projects on kickstarters, etc. Adds are the oposite: they don't mean to share, but to sell, hence completely destroying the spirit of internet. But I also need to know that my site may not be visited by people with my point of view: olders wouldn't pay as easily as youngers, and my project targets a very large group of people.
Please help me making a decision, I think I will have a lot of different opinions!3 -
My company has an default user for external people and two wifi networks, on for the company itself and on for the employees. both wifis have an shit of an firewall(more than once were wikipedia blocked). I found out that the internal wifi allowed the default user and had some outgoing ports open, i set up an vpn and now i can use what i want without being blocked.
-
!dev
I fucking hate with all the strength in my body this meme format:
nobody:
someone: wacky unpredictible quote
fuck that bitch ass, lazy, unfunny, uncreative format. It fucking sucks dick. It's not funny!
Jesus fucking christ, it was funny the first month.
But month after month after month, this fucking thing won't die. It's way way below the average meme format, and that's saying a lot considering what the average is.
I check youtube comments and for every funny and thoughtful comment there's one from these fucking idiots that shouldn't be alive parrotting this unfunny shit.
Just include the goddamn fucking quote, that's it.
Even less points to the motherfuckers that write:
nobody
not one on person on earth
not even a single person on the universe
person: <quote>
those deserve the worst type of cancers or torture forms described in wikipedia.
This is a stuxnet level post, I need to get a life.4 -
CS students: Everyone knows that filling slides with flowing text is bad practice. BUT. Does anyone else just HATE this when lecturers just copy the entire Slide from an article that is the first google search result OR WIKIPEDIA, not even trying to rephrase it, or quote professionally, but just copying, not trying to adapt to the audience at all. AND, what's worse - We have to learn this stuff for an exam tomorrow - AND - I can't find other peoples explanations on the web for each topic in time, if everything is just copied from the web's first results, i have to scan twice as many pages to find one different from the slides, that helps me understand the topics >.<
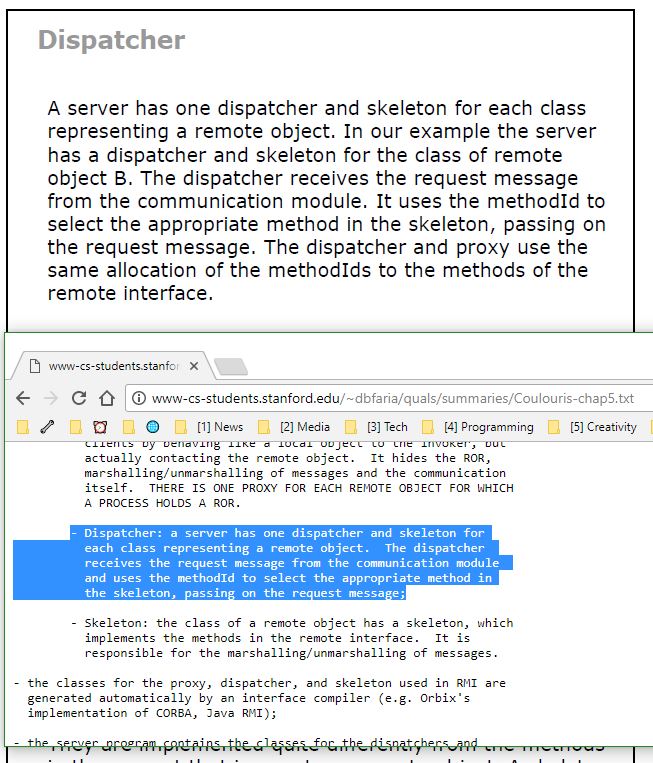 2
2 -
Apparently Wikipedia now wants money. Suddenly they have become like a homeless person.
Talk about being desperate. 8
8 -
Hi, I am using a Wikipedia scrapper in one of my Open Source project. The data extracted from it is the stored in Elasticsearch... Now I have decided to create library out of it so that other people can use it too... My question is should also include the Elasticsearch storing module in library or just add the scrapper... Please let me know your thoughts.8
-
About to start writing a report for my programming languages course, I’m writing it over GoLang, If anybody has any good resources for any information on Go, let me know!
The report extends into the history, paradigms, features, memory management system, and anything else I can possibly find on this language. I can find some pretty decent references on the footer of Wikipedia, but I wanted to see if anybody who actually used Go had anything they’d like to share.
Thanks :)1 -
So I'm having this return to the 70s mood. Not for the 70s themselves but for the pack of tech in everyday life.
Like besides email or worldwide message exchange and wikipedia, what have been the last true innovations?
Media streaming just killed and monopolized other industries. Sure, everything is cheaper, but let's be honest, how much music do we consume? Pretty sure like 80% of people listen to the same 100 songs in their whole lifetime. Do we need limitless streaming? Did it help us somehow beyond giving some dopamine shots?
Social media are and have always been crap for posers, advertising and bots. Small communities make sense, when properly taken care of. The actual issue with social media is the replacement of the so called "Third place". The place you go after work that is not your home. We don't know each other anymore, loneliness is apparently becoming pandemic and people are struggling with this. How is this innovative? For the real time news that are making people freak out?
And then, as I ranted before, AI. It's just... Statistics. Well applied statistics. Is it an actual innovation? No. Serves nothing beyond taking someone's job.
And before some retarded dickhead starts no, it will never create the same amount of jobs as a factory would've done 100 years ago, and prompt engineering is a lie told by the very guys who SELL those products to convince you that their crap is harmless.
Maybe it's about time to hit the brakes for a second and think if the simpler things (NOT the times!) were better, if maybe if we're getting lonely is actually our fault, it's our fault for not calling that old friend for a drink, it's our fault if we keep getting some dopamine shot every minute and are barely able to look people in the eyes, it's our fault for not behaving like human beings?
I hope any engineer will understand how this rant is about consumer-oriented tech and not tech in general.3 -
Third day of working on my recruitment task, and I'm starting to get pissed. I'm applying for Junior JS developer (suprised that they even picked me, I had 1 JS project in my resume, rest was Java). The task seemed simple, create website with autocomplete field which gets 10 cities with most polluted air from given country and get cities deacription from Wikipedia. But hell no. First, the air quality API that they told me to use sucks horse dick. Like seriousy, you can get a fucking timeout while fetching data, because as author explained, someone decided to make 2 fucking queries per request, one to count all possible results, and then the second one for actual data. Like, WTF, why would you do that. After I got that shit to work from time to time, it was time to Wikipedia API. And the shitshow starts again. Because it turns out that you can't filter the results based on the category. Which means that if the city has the same name as river or some fucking guy doing sports, I won't get the fucking description, because it will simply return info, that there are more more that 1 result. At this point, I'm so fucking pissed, I am barely keeping it together. I want to work at this company, because the pay is great, there are a lot of opportunities and shot, but god dammit, if I finish this task, I'm getting drunk for 3 days straight.
EDIT: even author of the air quality API says that it is not a good fit for given task...4 -
According to wikipedia they currently own 74 micro satellites, hope they will be selling them on some auction, people will gather and buy one for community I could give some money to be partial owner of the satellite.
https://en.m.wikipedia.org/wiki/...
-
Guys. Seriously. Get a grip. I get it. The new laws are not perfect. Some will even say that they suck. But you cannot tell me that the current laws were okay and covered all bases on copyright. Getting it under control is a process and it will require us as citizens to make meaningful choices with our votes. But simply repealing the law outright is not necessarily the best choice. We need to get a good idea on what is right and just, what is legitimate and then criticize the law. Being against it because it's a trending topic is not cool. It's moronic. E.g. Wikipedia won't die over this. Public content won't die over this. Some content will be more restricted because the copyright owner wants it to be. The implementation will be difficult but this does not mea that it will hurt liberties of the citizen. If anything quite the opposite. It's kind of amusing seeing people call privacy i to this. Privacy laws are unchanged. I'm all in favor of activism (and hacktivism) but let's do it right.17
-
What I just had to learn again, if you are the one who brings in (quality) standards in group tasks (like everybody does his stuff until day x, specify image sources, not only Wikipedia Copy & Paste), you are with a 95% probability also the one who more or less works alone on it at the end.
(Works the same with group coding projects where the one person in your group that's able to code relies on you doing most of the work because that person is lazy playing games) -
Is it just I or Wikipedia is a bad / shitty source of information and by bad I mean unreliable.....3
-
I'm dreaming about an assistant system, which is omnipresent.
Popping up on screens in public, sitting in many ear listening to my speech, with my personal feed off contextbased information.
Like a juxtaposition of Wikipedia, Facebook, Twitter, etc...
I don't want to pick my device from my pocket to type in a search or to push a button and say "ok buddy".
It just have to be omnipresent and focused on my requests.1 -
I was working on CakePHP as part of class project. I had to demonstrate AJAX. So I created some text files filled with random Wikipedia articles. On drop down item change, my AJAX handler would fetch the content of corresponding file and return it back.
But the problem was, it wasn't returning just the file content, but the whole HTML document. So the calling page would get another set of header, menu, footer and all! There was no time to fix layout for AJAX calls as it was added at last minute before the presentation. So, I just hid the duplicate menu etc using CSS and went for the presentation. It passed with flying colours.
So, if you can't fix something, just hide it! 😂 -
Hi friends!
I'm I'll since Sunday and my imagination is starting to fade. So far I've read/watched movies on deep learning and CNN, had a long session on Wikipedia on common fallacies, as well as a lot of other things. But now I can't think of what to do.
What is your favourite go to thing when you need to kill time using nothing but eyes and ears?
I'm too tired to code or play games...3 -
I know this is too late to ask this question, but am a final year computer science student, average in all core subjects with 0 knowledge of web development (except a few html tags, but not enough to make a wikipedia like website) or other professional streams.
I know java and python enough to make oop classes and understand code written in them.
Should i
A)study more about web dev/ml-ai/testing/other "professional" stuff
B) learn more and strengthen my core subjects , like operating system, algorithms, data structures, etc or
C) learn another core language like C/c++/assembly?24 -
If we can transform the search space or properties of a product into a graph problem
we could possibly use Kirchhoff's theorem to reveal products which are 'low complexity'
in particular search spaces, yeah?
Now according to
https://en.wikipedia.org/wiki/...
"n Cycle Space, A family of sets closed under the symmetric difference operation can be described algebraically as a vector space over the two-element finite field Z 2 {\displaystyle \mathbb {Z} _{2}} \mathbb{Z } _{2}.[4] This field has two elements, 0 and 1, and its addition and multiplication operations can be described as the familiar addition and multiplication of integers, taken modulo 2"
Wouldn't this relate to pollards algorithm, because it involves looking for factors of coprimes modulo N or am I mistaken?
Now, according to wikipedia, "in a group, the additive identity is the identity element of the group, is often denoted 0, and is unique."
If we make the multiplicative identity of our ring or field a tuple of the ratio of a/b for some product p, or a (and a/w, where w is the square root of p), or any other set such that n*m allows us to derive a or b, we could reduce the additive identity to the multiplicative identity, making the ring trivial. Solving for p would then mean finding a function from R to R, mapping every number to 0, i.e. finding the additive identity.
Now in a system with a multiplication operation the distributes over addition, the "additive
identity annihilates ring elements", so naturally, the function that maps to 0, gives us
our additive identity, we need only find the subset, no?
Forgive me if I'm wrong, but shouldn't this be convertible to a graph search?
I'm WAY out of my depth here so if anyone is familiar and can enlighten me I'd be grateful.
It's all unknown unknowns to me. -
I looked up well-reputed NGO on Google. And then navigated to their Wikipedia page to learn more about them. And this is what I found—
“Sorry, this page was recently deleted (within the last 24 hours). The deletion, protection, and move log for the page are provided below for reference.”
Why was it deleted? fraudulent claims? Plagiarism?6 -
I'm thinking on working something with Godot Engine and React to form a platform that allow people to register, categorize and explain exercises
like Wikipedia but for fitness, but with data to use for free7 -
I am looking some tool to systemize large amounts of data and then be able to search across it fast. Something like my personal google+wikipedia in one. Can you guys recommend me something?10
-
Searching dev/null on wikipedia, learning about a alt.flame, searching alt.flame on google, finding a site called nigger.mania and OP asking for a way to reach alt.flame.niggers. WTF men ?!
-
Wow. Wikipedia lists Aaron Swartz among diseased Wikipedians, with the usual condolences page. It's updated to this day.
https://en.wikipedia.org/wiki/... -
Buy Trustpilot Positive Reviews
Review of Buy Trustpilot by Buy SMM Services. We have successfully provided this service for a considerable amount of time. Additionally, customers are pleased with my services. Additionally, we have a large team. so that we can provide you with a Trustpilot review that has not been dropped in any way. Each review comes from a different device for us. Our review does not disappear if we use a different device. TrustPilot. com is a consumer review website established in Denmark in 2007 and hosts reviews of global businesses.
The site is free for customers because we all use real IP addresses. Additionally, it offers businesses free services. Wikipedia. Customers share their preferences and warn or encourage one another on this website. so that we can provide you with high-quality testimonials on our Trustpilot Business Page. so that they can have a positive experience with your service.
Individuals from the Assembled Realm, the US, France, Germany, and a lot more nations use Trustpilot. TrustPilot is also used by 20.1 million people. Customer feedback on Trustpilot can be either positive or negative for your website and business. It's critical for customers because you could lose them if they see something negative here.
Customers can use these reviews to select high-quality services. If you go to the TrustPilot website and look at customer feedback, reviews, or ratings, and if they are of poor quality, then the buyer will be suspicious and go to another seller. As a result, you will choose which service is best. For example, you are a replacement buyer, customer, or member. Reviews on Trustpilot are crucial for improving the customer experience, expanding the number of search engines, increasing site sales, conversions, and reputation, as well as expanding the customer base.
#Trustpilot Reviews #Reviews #Positive Reviews #advertising #Marketimg
-
confession: before today i had no idea what rust was. i read a wikipedia article and i'm still not sure, but i think i'm obligated to love it
https://insights.stackoverflow.com/...









































































































































Top Tags
Weekly Rant
View